按,北京時間10月19日凌晨,DeepMind在Nature上發佈論文《Mastering the game of Go without human knowledge》(不使用人類知識掌握圍棋),在這篇論文中,DeepMind展示了他們更強大的新版本圍棋程序「AlphaGo Zero」,掀起了人們對AI的大討論。而在10月28日,Geoffrey Hinton發表最新的膠囊論文,徹底推翻了他三十年來所堅持的算法,又一次掀起學界大討論。
究竟什麼是人工智能?深度學習的發展歷程如何?日前,我們邀請到UC Berkeley機器人與工程實驗室講座教授王強博士,他爲大家深入淺出講解了何爲人工智能,深度學習的發展歷程,如何從機器感知向機器認知演進,並解析了AlphaGo與AlphaGo Zero的原理、學習過程、區別等。
嘉賓簡介:王強博士,本科畢業於西安交通大學計算機科學與技術專業,後獲得卡內基梅隆大學軟件工程專業碩士學位、機器人博士學位。美國貨幣監理署(OCC)審計專家庫成員、IBM商業價值研究院院士及紐約Thomas J. Watson研究院主任研究員。IEEE高級會員,並擔任了2008、2009、2013及未來2018年CVPR的論文評委,同時是PAMI和TIP兩個全球頂級期刊的編委。王強博士在國際頂級期刊發表了90多篇論文,並多次在ICCV,CVPR等大會做論文分享。其主要研究領域圖像理解、機器學習、智能交易、金融反欺詐及風險預測等。
以下爲他的分享內容,本文爲下篇,主要內容是對AlphaGo和AlphaGo Zero詳細的解釋說明。上篇請參見:UC Berkeley 機器人與工程實驗室講座教授王強:Deep Learning 及 AlphaGo Zero(上) | 分享總結
今年9月19號,DeepMind在Nature上發表了一篇論文,這篇論文是在人工智能、深度學習上具有顛覆性的文章。
大家知道,原來有AlphaGo,現在又出了AlphaGo Zero,那麼AlphaGo和AlphaGo Zero之間到底有什麼樣的區別。
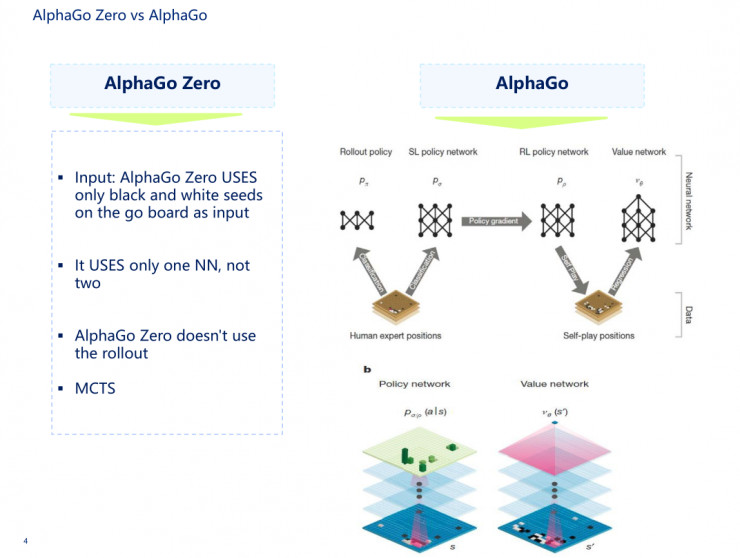
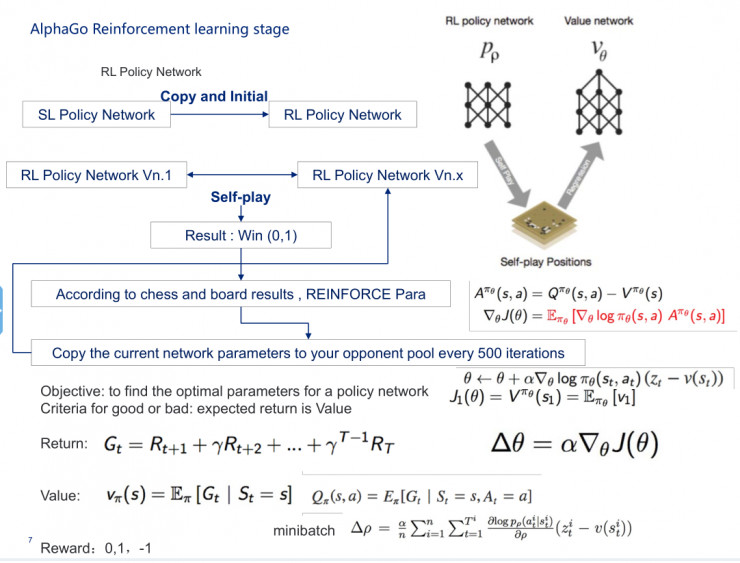
我先說AlphaGo,AlphaGo其實是由兩個網絡組成的,第一個是人類的經驗,第二個是雙手互搏、自學習。第一部分是監督策略網絡,第二部分是強化策略網絡,還有一個價值網絡,再加上rollout網絡,即快速走棋的網絡,這四個網絡再加上MCTS,就組成AlphaGo。
在AlphaGo裏面輸入了將近48種規則,但在AlphaGo Zero中,它的神經網絡裏面的輸入只有黑子和白子,而且輸入進的是一個網絡,不是兩套網絡。這裏所說的兩套網絡就是指價值網絡和策略網絡。AlphaGo和AlphaGo Zero的共同點是都用了MCTS。
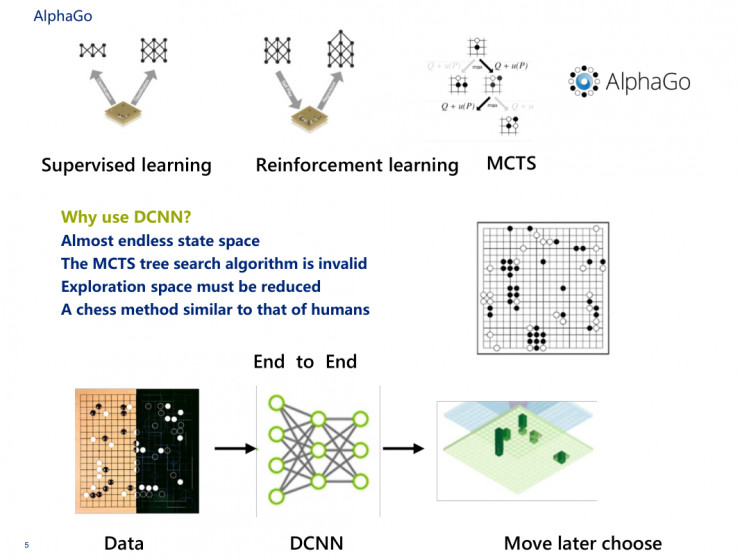
在這裏會想到一個問題,爲什麼AlphaGo和AlphaGo Zero都會用到DCNN神經網絡。
第一,大家都知道解決圍棋問題是比較有意思的,圍棋是19個格,19×19,361個落子的可能性,這時候落子可能存在的向量空間就是361乘以N,這個向量的狀態空間幾乎是無窮無盡的,大概計算量是10的171次方,用100萬個GPU去運算100年也是算不完的。
第二,在這裏MCTS的搜索方法是無效的。MCTS的搜索方式在這裏我通俗地講解下,隨機拿一個蘋果,和下一個蘋果進行對比,發覺到哪個蘋果比較大,我就會把小蘋果扔掉,然後再拿這個大的和隨機拿的下一個蘋果去對比。對比到最後,我一定會挑出一個最大的蘋果。
第三是我們希望走棋的時候的探索空間必須要縮小,要看這個子落下之後另一個子有幾種可能性,不要說別人下了一個子之後還有360個空間,那這360個空間裏頭都有可能性。DeepMind比較厲害的地方是做了一個隨機過程,而不是說在三百多個裏選哪個是最好的,這個用計算機是算不出來的。
第四個問題,它必須要做一種類似於人類下棋的方法。那麼剛纔有朋友問到什麼是端到端,端到端在AlphaGo裏邊表現得非常明確。我把數據扔給神經網絡,然後神經網絡馬上給出我一個狀態,這個狀態有兩個,包括目前狀態和目前狀態的價值,這非常有效,表示棋子落在哪裏,以及贏的概率到底有多大。
在這裏我先給大家講一下AlphaGo的原理。一般的棋盤比如圍棋、象棋等,我們第一步先做一件事,把棋盤的狀態向量標記成s,圍棋的棋盤是19*19,它一共有361個交叉點,每個交叉點有三個狀態,1表示黑子,-1表示白子,0表示沒有子,考慮到每個位置還可能有落子的時間等信息,我們可以用361乘以N維的向量表示棋盤的狀態。
我們把棋盤的狀態向量變成s,從0開始,s0表示的棋盤裏的所有狀態,沒有任何子,s1落的是第一個子,s2是第二個子,第二步加入落子的狀態a,在當前的狀態s下,我們暫時不考慮無法落子的情況。下第一個子的時候,可供下一步落子的空間是361個,我們把下一步落子的行動也用361維的向量表示,變成a。第三步我們來設計一個圍棋的人工智能程序,給定s狀態,然後尋找最好的策略a,讓程序按照這個策略去走。有四個條件,先是棋盤的狀態s,尋找下棋最好的策略a,然後讓程序按照這個策略a走棋,獲得棋盤上最大的地盤,這是圍棋人工智能程序的基本原理和思路。
DeepMind以及我們之前在沃森那邊做的,主要流程如下:
第一步先找一個訓練樣本,然後在觀察棋局的時候,發現在每一個狀態s裏都會有落子a,那麼這時候就會有一個天然的訓練樣本。
第二步,我們做一個網絡,拿了一個3000萬的樣本,我們把s看成一個19×19的二維圖像,然後乘以N,N指的是48種圍棋的各種下贏的特徵,落子向量a不斷訓練網絡,這樣就得到了一個模擬人下圍棋的神經網絡。
第三步我們設計一個策略函數和一個概率分佈,我們拿到一個模擬人類棋手的策略函數跟某個棋局的狀態s,可計算出人類選手可能在棋盤落子的概率分佈,每一步選擇概率最高的落子,對方對子後重新再算一遍,多次進行迭代,那就是一個和人類相似的圍棋程序,這是最開始的設計思維和方式,策略函數和概率分佈。
其實DeepMind還不是很滿意,他們設計好這個神經網絡之後,可以和六段左右過招,互有勝負,但還是下不過之前從沃森中做出來的一個電腦程序。這時候,DeepMind把他們的函數與從沃森中衍生出來的程序的函數算法結合在一塊,對原來的算法重新做了一個完整詳細的修正。
DeepMind最初對圍棋一概不知,先假設所有落子的分值,這個大家一定要記住,在做任何科學研究的時候,當你發現你一無所知的時候,一定先要設定一個值,這個值千萬不能是零。然後第二部分就簡單了,就像扔骰子一樣,從361種方法裏隨機選一個走法,落第一個子a0,那麼棋盤狀態就由s0變爲s1,對方再走一步,這時候棋盤狀態就變成s2,這兩個人一直走到狀態sN,N也許是360,也許是361,最後一定能分出勝負,計算機贏的時候把R值記爲1。
從s0、a0開始再模擬一次,接下來如PPT中卷積所示,做激活函數。在下到10萬盤次之後,這時候AlphaGo得到了非常完整的落子方案,比如說第一個子落在哪裏贏的可能性比較大。
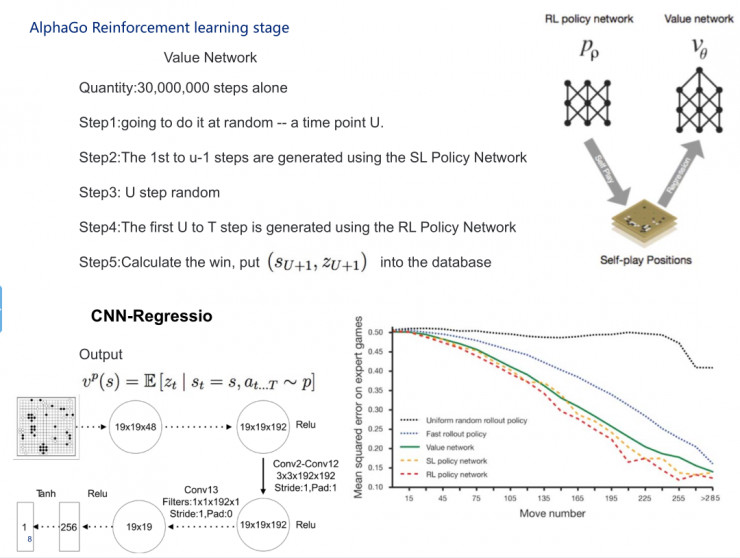
MCTS在這裏起的作用是什麼呢?MCTS能保證計算機可以連續思考對策,在比較的過程中發現最好的落子方式。在這之後,DeepMind發現用MCTS還不是非常好,他們就開始設計了一個比較有意思的東西,就是評價函數,我在這裏就不太多講評價函數。
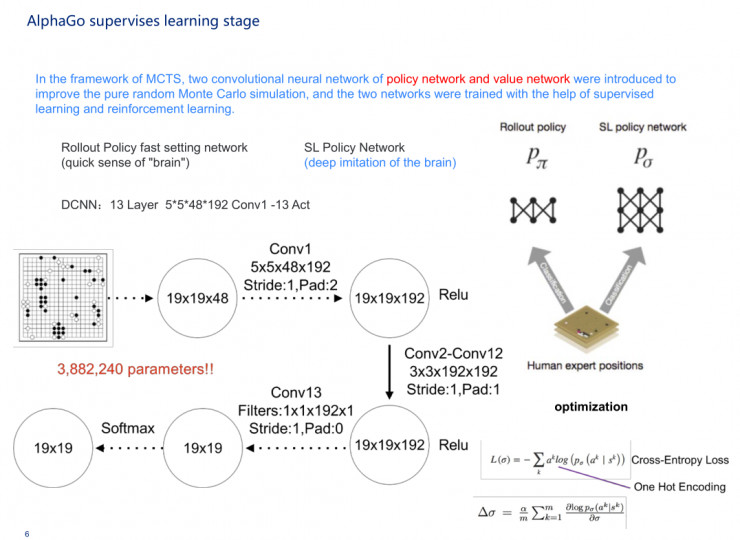
AlphaGo的監督學習過程其實由兩個網絡組成,一個是從其他人中獲得的學習經驗,先是做了一個softmax,即快速落子,它的神經網絡比較窄,第二部分是深度監督式神經網絡。
到了做強化學習的時候,它會把原來通過機器學習過來的監督神經網絡copy到強化神經網絡裏,然後進行初始化,讓強化神經網絡作爲對手和另一個強化神經網絡進行互相學習,來選擇一個最優的結果。具體細節如PPT所示,500次做一次迭代,在這裏會用到一些梯度下降的方式。
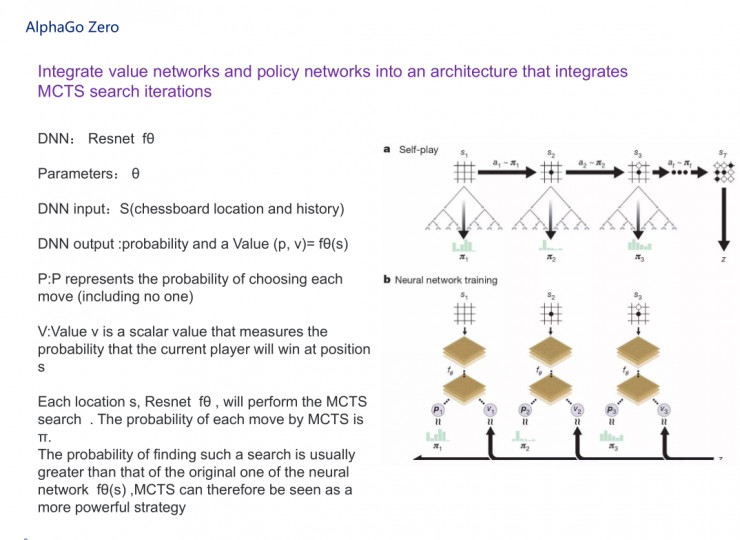
前面是我們看到的AlphaGo,接下來看AlphaGo Zero,它對原來的過程做了完整的簡化,集成了價值網絡和策略網絡,放到一個架構裏頭,即將MCTS和兩個神經網絡放在一塊。這兩個神經網絡其實用了一個比較有意思的神經網絡,叫Resnet,Resnet的深度大家也知道,曾經做到過151層,我在這裏就不講得特別詳細了。如PPT所示,它的參數是θ,深度神經網絡的輸入是s,輸出落子概率(p, v)。
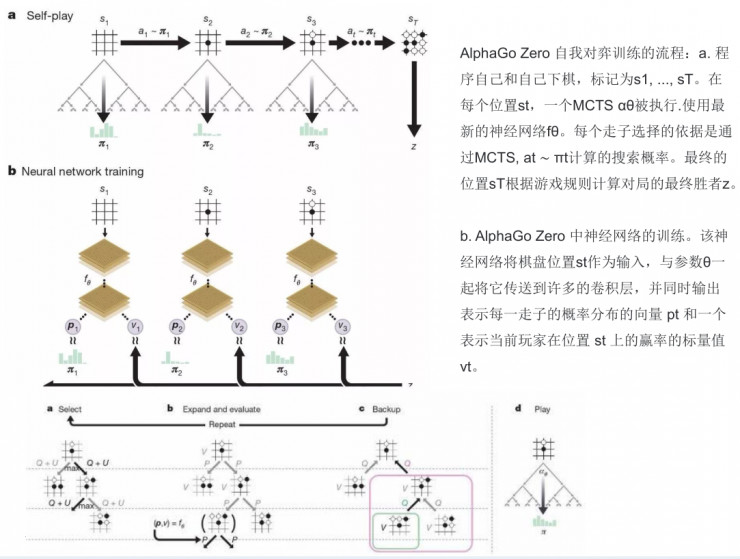
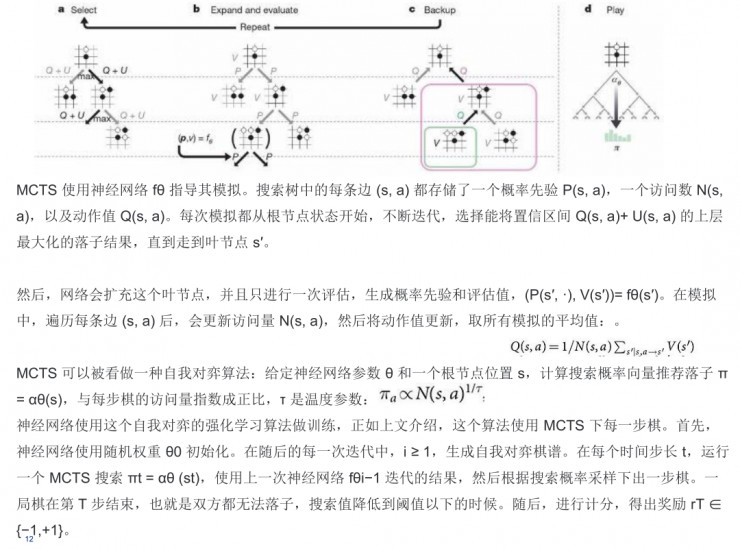
在這裏我給大家大概說說AlphaGo Zero自我對弈訓練的流程。
第一步是程序自己和自己下棋,標記爲s1, ..., sT。在每個位置st,一個MCTS αθ被執行。每個走子選擇的依據是通過MCTS(選擇最好的θ參數)、at ∼ πt計算的搜索概率。最終的位置sT根據遊戲規則計算對局的最終勝者z。
第二步是AlphaGo Zero中神經網絡的訓練。該神經網絡將棋盤位置st作爲輸入,與參數θ一起將它傳送到許多的卷積層,並同時輸出表示每一走子的概率分佈的向量pt和一個表示當前玩家在位置st上的贏率的標量值vt。同時MCTS 使用神經網絡 fθ 指導其模擬。
搜索樹中的每條邊 (s, a) 都存儲了一個概率先驗 P(s, a)(概率先驗是在CNN裏非常關鍵的問題)、一個訪問數 N(s, a)以及動作值 Q(s, a)。每次模擬都從根節點狀態開始,不斷迭代,選擇能將置信區間 Q(s, a)+ U(s, a) 的上層最大化的落子結果,直到走到葉節點s′。 然後,網絡會擴充這個葉節點,並且再進行一次評估,生成概率先驗和評估值。在模擬中,遍歷每條邊(s, a) 後,會更新訪問量N(s, a),然後將動作值更新,取得所有模擬的平均值。
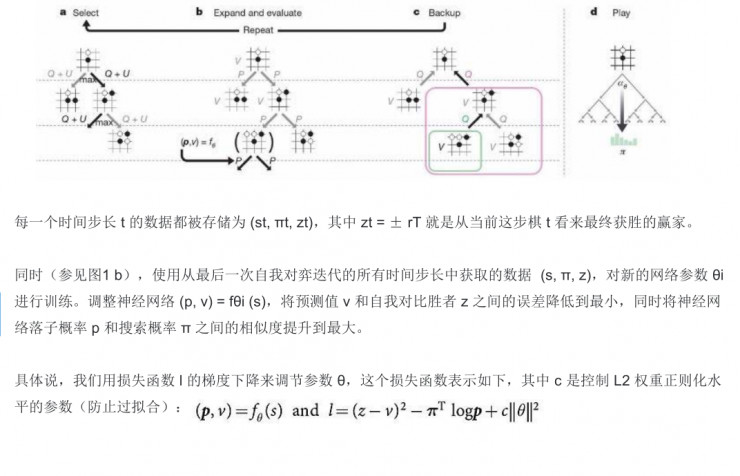
此外還要做時間步長的計算,還有L2 權重正則化水平參數(防止過擬合)的覆蓋,包括用損失函數的梯度下降來進行調節。
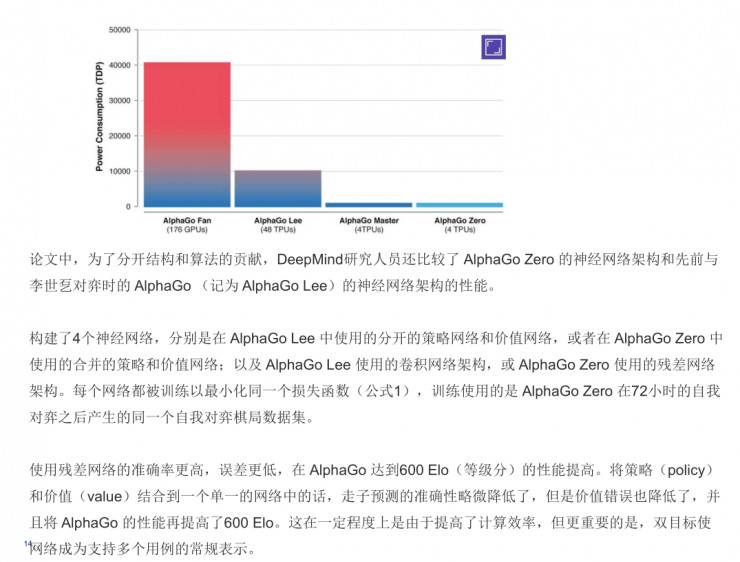
在這裏還有一件非常好玩的事情,他們用了張量處理單元(TPU),同時還做了一系列的說明,在訓練網絡時完全用了分佈式的訓練方式,用了176個GPU,48個TPU,其實AlphaGo Zero比較厲害的地方的是隻用了四個TPU去做。DeepMind還比較了AlphaGo Zero的神經網絡架構和AlphaGo的神經網絡架構的性能,在性能上我就不多說了。
 AlphaGo Zero比較厲害的地方在哪裏呢?一是它發現了五個人類的定式(常見的角落的序列),二是自我對弈中愛用的5個定式,三是在不同訓練階段進行的3次自我對弈的前80步棋,每次搜索使用1,600 次模擬(約0.4s)。
AlphaGo Zero比較厲害的地方在哪裏呢?一是它發現了五個人類的定式(常見的角落的序列),二是自我對弈中愛用的5個定式,三是在不同訓練階段進行的3次自我對弈的前80步棋,每次搜索使用1,600 次模擬(約0.4s)。
最開始,系統關注奪子,很像人類初學者,這是非常厲害的,白板+非監督學習方式完全模擬到人類初學者。後面,關注勢和地,這是圍棋的根本。最後,整場比賽體現出了很好的平衡,涉及多次戰鬥和一場複雜的戰鬥,最終以白棋多半子獲勝。其實這種方式是在不停的參數優化過程中做出的一系列工作。

接下來大概說說AlphaGo和AlphaGo Zero的一些比較。
第一,神經網絡權值完全隨機初始化。不利用任何人類專家的經驗或數據,神經網絡的權值完全從隨機初始化開始,進行隨機策略選擇,使用強化學習進行自我博弈和提升。
第二,無需先驗知識。不再需要人爲手工設計特徵,而是僅利用棋盤上的黑白棋子的擺放情況,作爲原始輸入數據,將其輸入到神經網絡中,以此得到結果。
第三,神經網絡結構的複雜性降低。原先兩個結構獨立的策略網絡和價值網絡合爲一體,合併成一個神經網絡。在該神經網絡中,從輸入層到中間層是完全共享的,到最後的輸出層部分被分離成了策略函數輸出和價值函數輸出。
第四,捨棄快速走子網絡。不再使用快速走子網絡進行隨機模擬,而是完全將神經網絡得到的結果替換隨機模擬,從而在提升學習速率的同時,增強了神經網絡估值的準確性。
第五,神經網絡引入Resnet。神經網絡採用基於殘差網絡結構的模塊進行搭建,用了更深的神經網絡進行特徵表徵提取。從而能在更加複雜的棋盤局面中進行學習。
第六,硬件資源需求更少。AlphaGo Zero只需4塊TPU便能完成訓練任務。
第七,學習時間更短。AlphaGo Zero僅用3天的時間便能達到AlphaGo Lee的水平,21天后達到AlphaGo Master的水平。
今天講這麼多,大家在聽我講這個科普類的東西時,可能會需要有一些比較好的基礎知識,包括MCTS、CNN、DNN、RNN、Relu、白板學習、Resnet、BP、RBM等,我希望大家對我講的這些神經網絡有一個比較詳細的瞭解。
第一是瞭解它的基本網絡架構,第二是去了解優點和缺點在哪裏。第三個是它的應用,是用在語言處理還是圖像上,用的時候它有哪些貢獻。到了第四步的時候,當你瞭解這些深度學習的過程之後,你可以考慮在工程上應用這些算法,再建立你的數據模型和算法。到第五步可以開始用MATLAB或Python去做復現,然後最後再去看深度學習算法對自己所做的工作有什麼樣的回報。

然後特別是做一些微調的工作,這時候你很有可能就能發表論文了。在這種情況下,我給大家提供一個比較好的思維方式,如果大家去用深度學習,怎麼能保證從目前簡單的AI的應用工作變成複雜的應用工作。其實,這是從機器感知到機器認知的轉變過程。
機器感知在這裏要做一個總結,機器感知是指從環境中獲取目標觀測信息,這是第一步。到了機器認知就比較有意思了,是將當前的狀態映射到相應操作,比如說旁邊的車要發動了,可能會撞到你,這時候你戴的手錶可能會智能提醒你,看你的動作是否有改變,從而判斷提醒是否有效,再進一步提高報警級別。
其實在機器認知的過程中,可能會用到大批量的深度學習和NLP技術、圖像理解技術、語音識別技術,多模態圖像識別技術,在這些領域去做一些組合的時候,可能對大家的研究比較有意義。
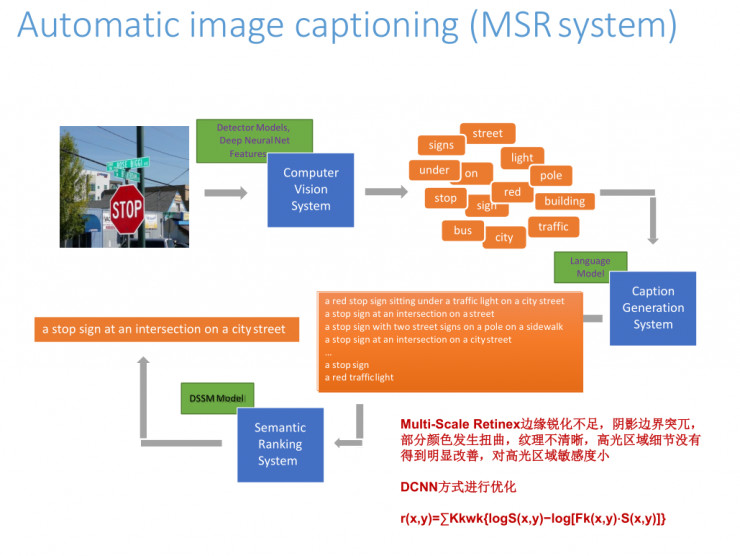
說說我們最近做的一些工作,這是一個MSR系統,我們在用DCNN的方法做優化,用image captioning來做這個系統的時候會面臨一些問題。在這裏用Multi-Scale Retinex技術會存在一些問題,比如邊緣銳化不足,陰影邊界突兀比較大, 部分顏色發生扭曲等。我們試過了很多方法,也做了很多參數的優化處理,發現效果都不是很好,Hinton出了capsule之後,我們立馬開始去對物體座標性的點進行描述處理,而不用BP的反向處理方式,現在我們正在做一些算法的猜想證明。

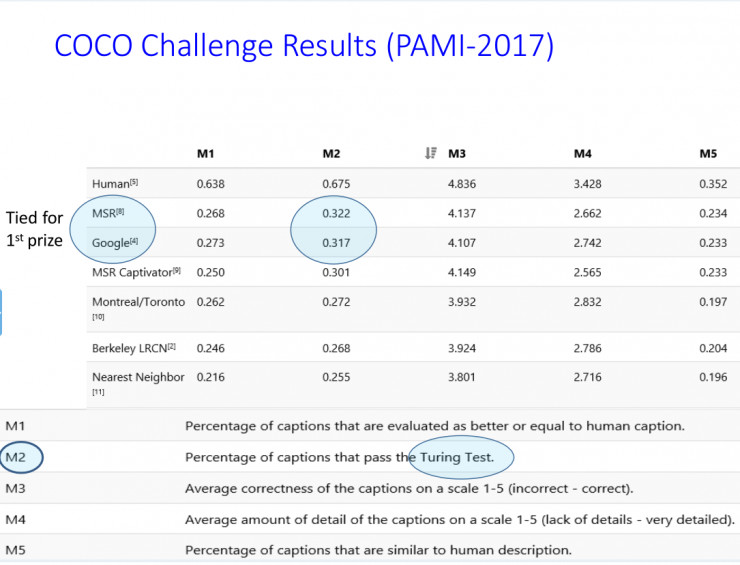
最後的結果如下:我們在訓練圖片的時候,它越來越能夠認識到人在做什麼事。圖中是人和機器所看到的,機器會認爲這個人在準備食物,但其實人會認爲她在做更實際的東西,會把所有的圖片都認出來,我們現在已經做到跟人的匹配率達到97.8%,也是通過反覆Resnet學習去做出來的。
下面是在COCO上的結果。
今天公開課就結束了,我希望大家去看下AlphaGo Zero最新的論文,然後去看看Hinton的膠囊計劃,如果大家在這裏有什麼想法可以和我來探討。還有一個論壇大家可以進來去看一下,地址是mooc.ai,大家可以看這裏邊有什麼需要去討論的東西。
視頻: