選自GitHub
訓練一個非常深度的神經網絡需要大量內存。通過由 OpenAI 研究員 Tim Salimans 和 Yaroslav Bulatov 聯合開發的工具包,你可以權衡計算力和內存的使用,從而使你的模型更合理地佔用內存。對於前饋模型,我們能夠藉助該工具把大 10 多倍的模型放在我們的 GPU 上,而計算時間只增加 20%。
項目鏈接:https://github.com/openai/gradient-checkpointing
通過梯度檢查節約內存
深度神經網絡訓練的內存密集部分是通過反向傳播計算損失的梯度。通過查看由你的模型定義的計算圖,並在反向傳播中重計算這些結點,有可能在減少內存成本的同時計算對應結點的梯度。當訓練的深度前饋神經網絡包含 n 個層時,你可以這種方式把內存消耗降至 O(sqrt(n)),這需要執行一個額外的前饋傳遞作爲代價(可參見 Training Deep Nets with Sublinear Memory Cost, by Chen et al. (2016))。通過使用 TensorFlow graph editor 自動重寫反向傳遞的計算圖,該庫提供了 TensorFlow 的一個功能實現。
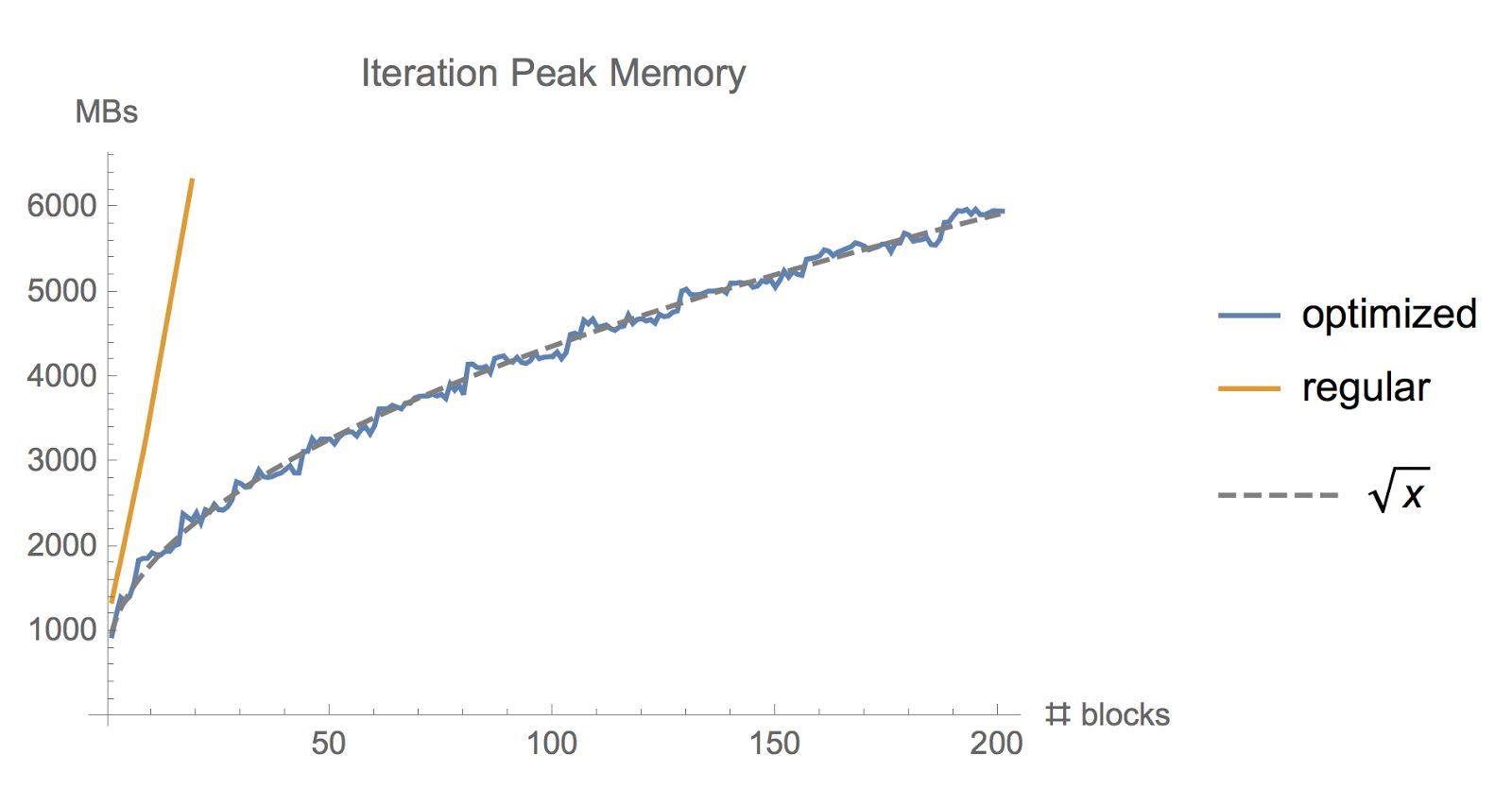
使用一般 tf.gradient 函數和我們的內存優化的梯度實現訓練一個大批量的 ResNet 模型時佔用的內存比。
工作原理
對一個簡單的 n 層前饋神經網絡,獲取梯度的計算圖如下所示:
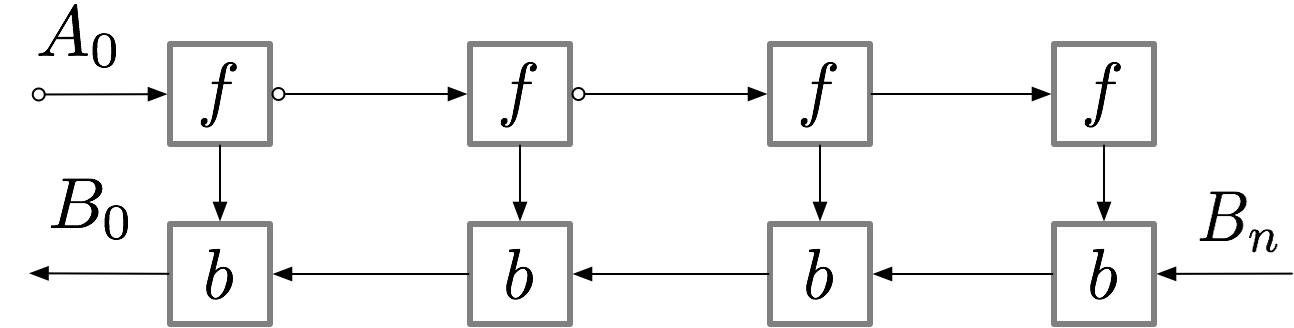
神經網絡的層級激活值對應於 f 標記的結點,且在正向傳播過程中,所有這些結點需要按順序計算。損失函數對激活值和這些層級參數的梯度使用 b 結點標記,且在反向傳播過程中,所有這些結點需要按逆序計算。計算 f 結點的激活值是進一步計算 b 結點梯度的前提要求,因此 f 結點在前向傳播後會保留在內存中。只有當反向傳播執行地足夠遠以令計算對應的梯度不再需要使用後面層級的激活值或 f 的子結點時(如下圖所示),這些激活值才能從內存中清除。這意味着簡單的反向傳播要求內存與神經網絡的層級數成線性增長關係。下面我們展示了這些結點的計算順序,紫色的結點表示在給定的時間內需要儲存在內存中。
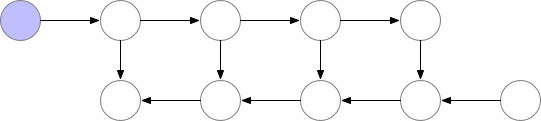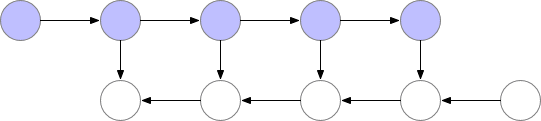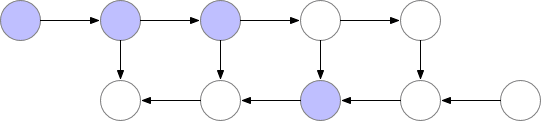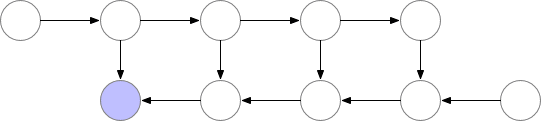
圖 1:原版的反向傳播
如上所述,簡單的反向傳播已經是計算最優的了,因爲每個結點只需要計算一次。然而,如果我們願意重新計算結點,那麼我們可以節省大量的內存。當我們需要結點的激活值時,我們可以簡單地重計算前向傳播的結點激活值。我們可以按順序執行計算,直到計算出需要使用激活值進行反向傳播的結點。
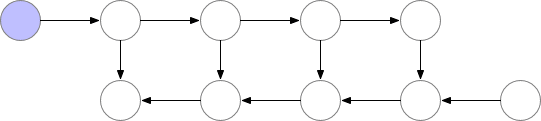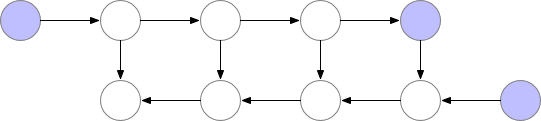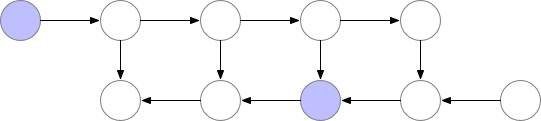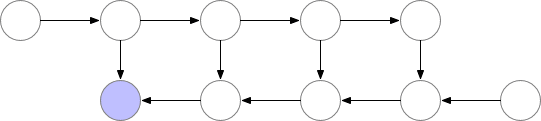
圖 2:佔用內存少的反向傳播
使用這一策略,需要令計算梯度的內存在神經網絡層的數量 n 上是穩定的,且 n 在內存方面是最優的。但是要注意,結點的計算數量現在擴展了 n^2,相比於之前的 n。n 個結點中的每一個被再計算 n 次。因此計算圖變得很慢以計算深度網絡,使得這一方法不適用於深度學習。
爲了在內存與計算之間取得平衡,我們需要一個策略允許結點被再計算,但是不太經常。這裏我們使用的策略是把神經網絡激活的一個子集標記爲一個結點。
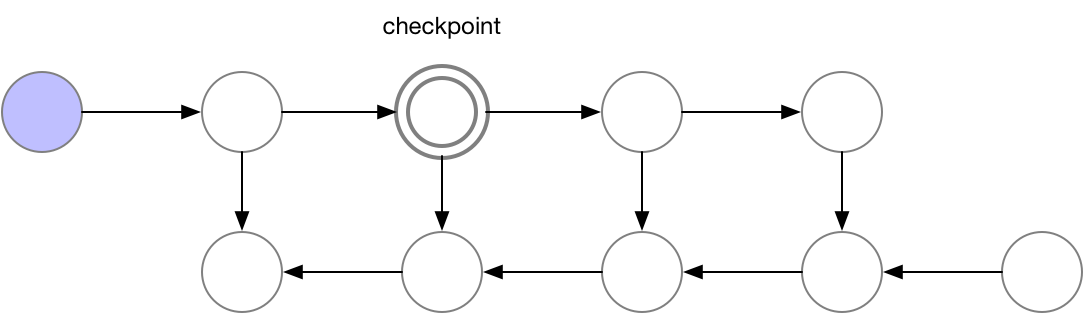
我們選擇的檢查點結點
這些檢查點結點在前向傳播後保留在內存中,而其餘結點最多隻會重新計算一次。在重新計算後,非檢查點結點將保留在內存中,直到不再需要它們來執行反向傳播。對於簡單的前饋神經網絡,所有神經元的激活結點都是由正向傳播定義的連接點或圖的分離點。這意味着我們在反向傳播過程中只需要重計算 b 結點和最後檢查點之間的結點,當反向傳播達到了我們保存的檢查點結點,那麼所有從該結點開始重計算的結點在內存中都能夠移除。計算和內存使用的順序如下所示:
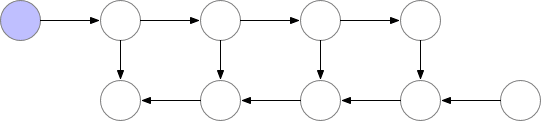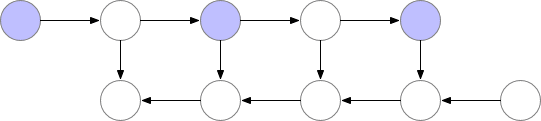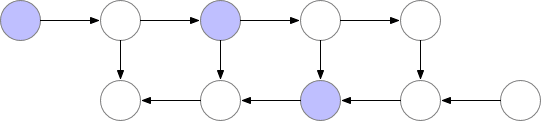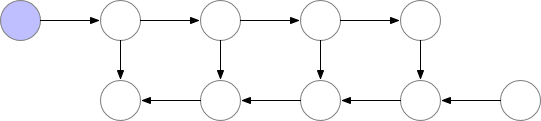
圖 3:Checkpointed backprop
對於例子中的簡單前饋網絡,最好的選擇是將每 qrt(n)-th 個結點作爲 checkpoint。這樣,checkpoint 結點的數量和 checkpoint 之間的結點數目都是 sqrt(n)的倍數,這意味着所需的內存現在也與我們網絡中層數的平方根成比例。由於每個結點最多隻能重算一次,因此該策略所需的額外算力相當於整個網絡的單次正向傳遞。
OpenAI 的工具包實現了 checkpointed backprop,如圖 3 所示。這是通過標準反向傳播(圖 1 所示)和 TensorFlow 圖編輯器的自動重寫實現的。對於包含關結點的圖(單結點圖分隔符),我們選擇自動選擇 checkpoints 的策略,使用 sqrt(n),提供 sqrt(n) 給前饋網絡。對於只包含多結點分割的一般計算圖,我們的 checkpointed backprop 實現仍然有效,但目前仍需使用者手動選擇 checkpoint。
更多的計算圖、內存用量和梯度計算策略說明可以在這篇文章中找到:https://medium.com/@yaroslavvb/fitting-larger-networks-into-memory-583e3c758ff9。
設置需求
pip install tf-nightly-gpu
pip install toposort networkx pytest
在運行測試的時候,保證能建立 CUDA Profiling Tool Interface(CUPTI),例如,通過運行 export LD_LIBRARY_PATH="${LD_LIBRARY_PATH}:/usr/local/cuda/extras/CUPTI/lib64"。
使用
本項目提供了一個 TensorFlow 中 tf.gradients 的插入式替換。載入此函數需要:
frommemory_saving_gradients importgradients
隨後使用 gradients 函數,就像你正常使用 tf.gradients 來計算梯度損失參數一樣。(這裏假設你明確地調用 tf.gradients,而不是將其隱藏在 tf.train.Optimizer 中。)
除了 tf.gradients 的常規參數以外,OpenAI 的 gradients 函數還有一個額外的參數 checkpoints。Checkpoints 參數告訴 gradients 函數計算圖中的哪個結點在前向傳播中需要檢查。檢查點之間的結點會在反向傳播時計算。你可以爲 checkpoint 提供一個張量列表,gradients(ys,xs,checkpoints=[tensor1,tensor2]),或使用以下關鍵詞:
‘collection(默認)’:這個 checkpoint 的所有張量返回 tf.get_collection('checkpoints')。你隨後需要確認自己在定義自己的模型時是使用 tf.add_to_collection('checkpoints', tensor) 來加入張量的。
‘memory’:它使用啓發式機制來自動選擇 checkpoint 的結點,從而達到我們需要的內存用量 O(sqrt(n))。啓發式方法是通過自動識別圖中的「關結點」來實現的,即移除時將計算圖分成兩個斷開的張量,然後對這些張量進行檢查點確定,找到一個合適的數量。這種方式目前在很多模型上運行良好(但不是所有)。
‘speed’:這個選項試圖通過檢查所有操作的輸出來最大化運行速度,這通常非常耗費算力,特別是在卷積和矩陣乘法上。
覆蓋 TF.GRADIENTS
直接使用 gradients 新函數的另一個方法是直接覆蓋 Python 上註冊的 tf.gradients 函數名。就像這樣:
importtensorflow astf
importmemory_saving_gradients
# monkey patch tf.gradients to point to our custom version, with automatic checkpoint selection
defgradients_memory(ys,xs,grad_ys=None,**kwargs):
returnmemory_saving_gradients.gradients(ys,xs,grad_ys,checkpoints='memory',**kwargs)
tf.__dict__["gradients"]=gradients_memory
這樣,所有 tf.gradients 的調用就會使用節約內存的版本作爲代替了。
測試
在 GitHub 資源的測試文件夾中包含用於測試代碼準確性,並分析各類模型內存使用情況的腳本。修改代碼後,你可以從該文件夾運行./run_all_tests.sh 來進行測試。
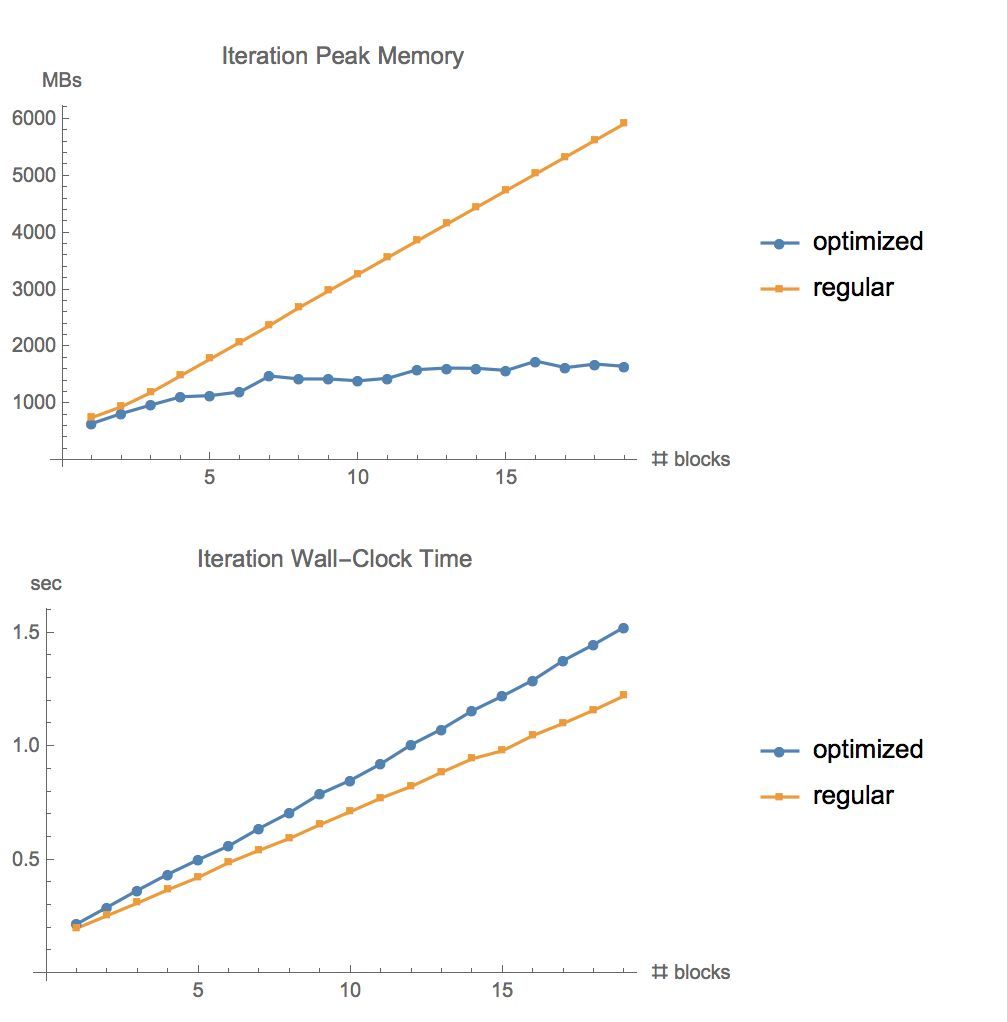
下圖展示了在 CIFAR10 上運行不同層數 ResNet 的內存用量和時間,Batch-size 爲 1280,GPU 爲 GeForce GTX 1080:
限制
目前提供的代碼在運行模型之前全部使用 Python 進行圖操作,這會導致大型圖處理速度緩慢。當前用於自動選擇 checkpoint 的算法是純啓發式的,預計在已有測試之外的一些模型上可能會失敗。在這種情況下,我們應該使用手動選擇 checkpoint 的方式。
參考內容
Academic papers describing checkpointed backpropagation: Training Deep Nets with Sublinear Memory Cost, by Chen et al. (2016) (https://arxiv.org/pdf/1604.06174.pdf), Memory-Efficient Backpropagation Through Time, by Gruslys et al. (2016) (https://arxiv.org/abs/1606.03401v1)
Explanation of using graph_editor to implement checkpointing on TensorFlow graphs: https://github.com/tensorflow/tensorflow/issues/4359#issuecomment-269241038, https://github.com/yaroslavvb/stuff/blob/master/simple_rewiring.ipynb
Experiment code/details: https://medium.com/@yaroslavvb/testing-memory-saving-on-v100-8aa716bbdf00
TensorFlow memory tracking package: https://github.com/yaroslavvb/chain_constant_memory/blob/master/mem_util_test.py
Implementation of "memory-poor" backprop strategy in TensorFlow for a simple feed-forward net: https://github.com/yaroslavvb/chain_constant_memory/