
YouTube stories 中的神經網絡視頻分割(加特效)
雷鋒網(公衆號:雷鋒網) AI 科技評論按:視頻分割是一項用途廣泛的技術,把視頻的前景和背景分離之後,導演們、視頻製作者們就可以把兩者作爲兩個不同的視覺層,便於後續的處理或者替換。對背景的修改可以傳遞不同的情緒、可以讓前景的主人公顯得去了另一個地方,又或者增強這條視頻消息的影響力。不過,這項工作傳統上都是由人工完成的,非常費時(比如需要逐幀把裏面的人描選出來);省時的辦法則需要一個專門的電影工作室,佈置綠幕作爲拍攝背景,從而實時替換成別的需要的內容。
不過,以往復雜的背景分割工作,現在僅僅靠一臺手機就可以完成了!谷歌今天在 YouTube app 中的 stories 裏集成了一個新的視頻分割功能,在手機上就可以準確、實時地分割視頻的前景背景。這個功能是專門爲 YouTube 視頻作者們設計的,在目前的 beta 版中 stories 作爲新的輕量級視頻格式,可以讓視頻作者們替換以及更改視頻背景,不需要專門的設備就可以輕鬆增加視頻的創作價值。谷歌也發佈了一篇博客對其中的技術細節作了介紹,雷鋒網 AI 科技評論編譯如下。
任務目標
谷歌的研究人員們藉助了機器學習的力量,把這個任務作爲一個語義分割問題來考慮,並設計了卷積神經網絡來達到目標。具體來說,他們針對手機的特點設計了適用的網絡架構和訓練過程,遵循着這幾個要求和限制:
作爲在手機上運行的解決方案,它需要足夠輕量,運行速度需要比目前最先進的照片分割模型快 10 倍到 30 倍。對於實時推理任務,所需的模型計算結果的速度至少需要達到每秒 30 幀。
作爲視頻模型,它應當利用視頻的時間冗餘性(相鄰的幀內容相似),自己展現出時間持續性(相鄰的輸出結果相似)
作爲基本規律,高質量的結果也需要高質量的標註訓練數據
數據集
爲了給機器學習流水線提供高質量的訓練數據,谷歌標註了上萬張照片,其中包含了各種各樣豐富的前景(人物)姿勢和背景內容。標註內容裏包括了精確到像素的前景人物的圖像結構,比如頭髮、眼鏡、脖子、皮膚、嘴脣等等,各類背景則統一標註爲「背景」,標註質量在人類標註員的交叉驗證測試中取得了 98% 的 IOU。

一張仔細標註爲 9 個類別的訓練樣本示例;前景元素的標註區域直接覆蓋在圖像上
網絡輸入
這個視頻分割任務的具體定義是對視頻輸入的每一幀(RGB 三個通道)計算出一張二值掩蔽圖。這裏需要解決的關鍵問題是讓計算出的不同幀的掩蔽圖之間達到時間持續性。現有的使用 LSTM 和 GRU 的方法雖然有效,但對於要在手機上實時運行的應用來說,需要的計算能力太高了。所以谷歌研究人員們想到的替代方案是把前一幀計算出的掩蔽圖作爲第四個通道,和新一幀本來的 RGB 三個通道一起作爲網絡輸入,從而實現時間持續性。如下圖
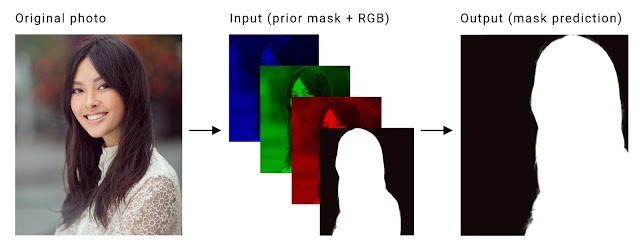
一幀原始圖像(左圖)會分離爲三色通道,然後再加上前一幀圖像算出的掩蔽圖(中)。這些會一起作爲神經網絡的輸入,用來預測當前幀的掩蔽圖(右圖)。
訓練過程
對於視頻分割任務,我們希望達到幀與幀之間的時間連續性,同時也要照顧到圖像中內容的突然變化,比如人突然出現在攝像頭視野中。爲了訓練模型能夠魯棒地處理這些使用狀況,谷歌的研究人員們對每張圖像的真實背景分割結果做了各種不同的處理後再作爲來自前一幀的掩蔽圖:
空的前一幀掩蔽:這種情況用來訓練網絡正確分割視頻的第一幀,以及正確分割視野中新出現的物體。這模擬了某人突然出現在攝像頭視野內的狀況。
仿射變換過的真實背景掩蔽:輕微的變換可以訓練網絡據此進行調整,向前一幀的掩蔽適配。大幅度的變換就訓練網絡判斷出掩蔽不適合並拋棄這個結果。
變換過的圖像:對視頻的原始圖像做薄板樣條平滑,模擬攝像頭快速移動和轉動時拍攝出的畫面

演示實時視頻分割
網絡架構
根據修改過的輸入/輸出格式,谷歌的研究人員們以標準的沙漏型分割網絡架構爲基礎,做了如下改進:
使用大卷積核、4 或者更大的大步距在高分辨率的 RGB 輸入幀內檢測物體特徵。對通道數不多的層做卷積的計算開銷相對較小(在這種情況下就是 RGB 三個通道的輸入),所以在這裏用大的卷積核幾乎對計算需求沒有影響。
爲了提高運行速度,模型中結合大步距和 U-Net 類似的跳躍連接,激進地進行下采樣,同時也在上採樣時保留低層次的特徵。對於谷歌的這個分割模型,有跳躍連接的模型的 IOU 要比沒有跳躍連接的大幅提高 5%。
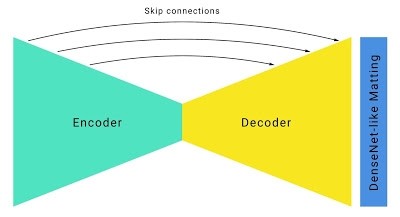
帶有跳躍連接的沙漏型分割網絡
爲了進一步提高速度,谷歌研究人員們優化了默認的殘差網絡瓶頸。在學術論文中,研究者們通常喜歡在網絡中部把通道數縮減爲 1/4 (比如,通過使用 64 個不同的卷積核把 256 個通道縮減爲 64 個通道)。不過,谷歌的研究人員們認爲他們可以更加激進地縮減通道,可以縮減爲 1/16 甚至 1/32,而且並不會帶來性能的大幅下降。
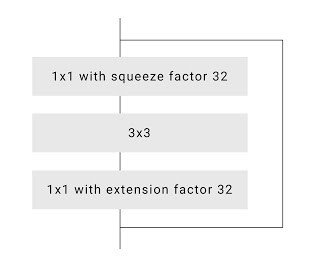
大比例壓縮的 ResNet 瓶頸
爲了美化圖像邊緣、提高圖像邊緣分割的準確率,在整個分割網絡之上增加了幾層全分辨率的密集連接 DenseNet 層,這種做法和神經網絡匹配很相似。這種技巧帶來的模型總體數值表現提升並不大,僅有 0.5% IOU,但是人類視覺感知上的分割質量提升很明顯。
經過這些修改之後,網絡在移動設備上的運行速度非常塊,不僅在 iPhone 7 上有超過 100 幀每秒、Pixel 2 上超過 40幀每秒的速度,而且還有很高的準確率(根據谷歌的驗證數據集達到了 94.8%),爲 YouTube stories 功能提供了各種豐富流暢的實時響應效果。

視頻分割團隊的近期目標是在 YouTube stories 功能的小規模開放期間進行更多測試。隨着分割技術改善、拓展到更多標籤的識別分割,谷歌的 AR 服務中未來也有可能會把它集成進去。
via GoogleBlog,雷鋒網 AI 科技評論編譯
