編者按:5 月 11 日,在加州聖何塞舉辦的的 2017 年度 GPU 技術大會上,英偉達發佈了 Tesla V100,號稱史上最強的 GPU 加速器。發佈之後,英偉達第一時間在官方開發者博客放出一篇博文,詳細剖析了包括 Tesla V100,GV100 GPU,Tensor Core,以及 Volta 架構等在內的各項新特性/新產品的技術內涵,我們編譯如下。

衆所周知,目前無論是語音識別,還是虛擬個人助理的訓練;路線探測,還是自動駕駛系統的研發,在這些人工智能領域,數據科學家們正在面對越來越複雜的 AI 挑戰。而爲了更好地實現這些頗具未來感的強大功能,就必須在實踐中引入一些指數級的更加複雜的深度學習模型。
另一方面,HPC(高性能計算)在現代科學研究中一直起着至關重要的作用。無論是預測天氣,新葯物的研究,或是探索未來能源,科研人員每天都需要利用大型計算系統對現實世界做各種各樣的仿真和預測。而通過引入 AI 技術,HPC 就可以顯著提升科研人員進行大數據分析的效率,並得到一些此前通過傳統的仿真和預測方法無法得到新結論。
爲了進一步推動 HPC 和 AI 領域的相關發展,英偉達近期發佈了新一代 Tesla V100 GPU 加速器。它基於最新的 NVIDIA Volta GV100 GPU 平臺和各種突破性技術創新,可以爲各種超級計算系統提供一個強大的運算平臺,不論在以科學仿真爲主要手段的計算科學領域,還是在以洞悉數據奧祕爲目標的數據科學領域,Tesla V100 都能爲相關應用提供強大的算力支持。
下面,我們會通過這篇博客對 Tesla V100 的核心:Volta 架構做一個深度剖析,同時幫助開發者瞭解它在實際開發中具體帶來了哪些優勢。
Tesla V100:AI 計算和 HPC 的源動力
NVIDIA Tesla V100 是目前世界上最高性能的並行處理器,專門用於處理需要強大計算能力支持的密集型 HPC、AI、和圖形處理任務。
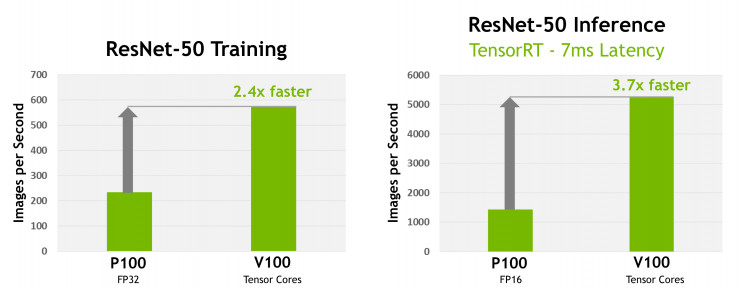
Tesla V100 加速器的核心是 GV100 GPU 處理器。基於臺積電專門爲 NVIDIA 設計的最新 12nm FFN 高精度製程封裝技術,GV100 在 815 平方毫米的芯片尺寸中,內部集成了高達 211 億個晶體管結構。相較於上一代產品,也就是 Pascal 系列 GPU,GV100 不但在計算性能上有了長足的進步,同時還增加了許多令人眼前一亮的新特性。包括進一步精簡的 GPU 編程和應用部署流程,以及針對 GPU 資源利用情況的深度優化。其結果是,GV100 在提供強大計算性能的同時還非常省電,下圖顯示了 Tesla V100 加速器和上代產品 Tesla P100 加速器在 ResNet-50 模型訓練和推理中的性能對比,可以看到最新的 V100 要遠超上一代 P100。
Tesla V100 的關鍵特性總結如下:
● 針對深度學習優化的流式多處理器(SM)架構。作爲 GPU 處理器的核心組件,在 Volta 架構中 NVIDIA 重新設計了 SM,相比之前的 Pascal 架構而言,這一代 SM 提高了約 50% 的能效,在同樣的功率範圍內可以大幅提升 FP32(單精度浮點)和 FP64(雙精度浮點)的運算性能。專爲深度學習設計的全新 Tensor Core 在模型訓練場景中,最高可以達到 12 倍速的 TFLOP(每秒萬億次浮點運算)。另外,由於全新的 SM 架構對整型和浮點型數據採取了相互獨立且並行的數據通路,因此在一般計算和尋址計算等混合場景下也能輸出不錯的效率。Volta 架構新的獨立線程調度功能還可以實現並行線程之間的細粒度同步和協作。最後,一個新組合的 L1 高速數據緩存和共享內存子系統也顯著提高了性能,同時大大簡化了開發者的編程步驟。
● 第二代 NVLink。第二代 NVIDIA NVLink 高速互連技術爲多 GPU 和多 GPU/CPU系統配置提供了更高的帶寬,更多的連接和更強的可擴展性。GV100 GPU 最多支持 6 個 NVLink 鏈路,每個 25 GB/s,總共 300 GB/s。NVLink 還支持基於 IBM Power 9 CPU 服務器的 CPU 控制和高速緩存一致性功能。另外,新發布的 NVIDIA DGX-1V 超級 AI 計算機也使用了 NVLink 技術爲超快速的深度學習模型訓練提供了更強的擴展性。
● HBM2 內存:更快,更高效。Volta 高度優化的 16GB HBM2 內存子系統可提供高達 900 GB/s 的峯值內存帶寬。相比上一代 Pascal GP100,來自三星的新一代 HBM2 內存與 Volta 的新一代內存控制器相結合,帶寬提升 1.5 倍,並且在性能表現上也超過了 95% 的工作負載。
● Volta 多處理器服務(Multi-Process Service,MPS)。Volta MPS 是 Volta GV100 架構的一項新特性,可以提供 CUDA MPS 服務器關鍵組件的硬件加速功能,從而在共享 GPU 的多計算任務場景中顯著提升計算性能、隔離性和服務質量(QoS)。Volta MPS 還將 MPS 支持的客戶端最大數量從 Pascal 時代的 16 個增加到 48 個。
● 增強的統一內存和地址轉換服務。Volta GV100 中的 GV100 統一內存技術實現了一個新的訪問計數器,該計數器可以根據每個處理器的訪問頻率精確調整內存頁的尋址,從而大大提升了處理器之間共享內存的使用效率。另外,在 IBM Power 平臺上,新的地址轉換服務(Address Translation Services,ATS)還允許 GPU 直接訪問 CPU 的存儲頁表。
● Cooperative Groups(協作組)和新的 Cooperative Launch API(協作啓動 API)。Cooperative Groups 是在 CUDA 9 中引入的一種新的編程模型,用於組織通信線程組。Cooperative Groups 允許開發人員表達線程之間的溝通粒度,幫助他們更豐富、更有效地進行並行分解(decompositions)。Kepler 系列以來,所有的 NVIDIA GPU 都支持基本 Cooperative Groups 特性。Pascal 和 Volta 系列還支持新的 Cooperative Launch API,通過該 API 可以實現 CUDA 線程塊之間的同步。另外 Volta 還增加了對新的同步模式的支持。
● 最大性能和最高效率兩種模式。顧名思義,在最高性能模式下,Tesla V100 極速器將無限制地運行,達到 300W 的 TDP(熱設計功率)級別,以滿足那些需要最快計算速度和最高數據吞吐量的應用需求。而最高效率模式則允許數據中心管理員調整 Tesla V100 的功耗水平,以每瓦特最佳的能耗表現輸出算力。而且,Tesla V100 還支持在所有 GPU 中設置上限功率,在大大降低功耗的同時,最大限度地滿足機架的性能要求。
● 針對 Volta 優化的軟件。各種新版本的深度學習框架(包括 Caffe2,MXNet,CNTK,TensorFlow 等)都可以利用 Volta 大大縮短模型訓練時間,同時提升多節點訓練的性能。各種 Volta 優化版本的 GPU 加速庫(包括 cuDNN,cuBLAS 和 TensorRT 等)也都可以在 Volta GV100 各項新特性的支持下,爲深度學習和 HPC 應用提供更好的性能支持。此外,NVIDIA CUDA Toolkit 9.0 版也加入了新的 API 和對 Volta 新特性的支持,以幫助開發者更方便地針對這些新特性編程。
GV100 GPU 硬件架構
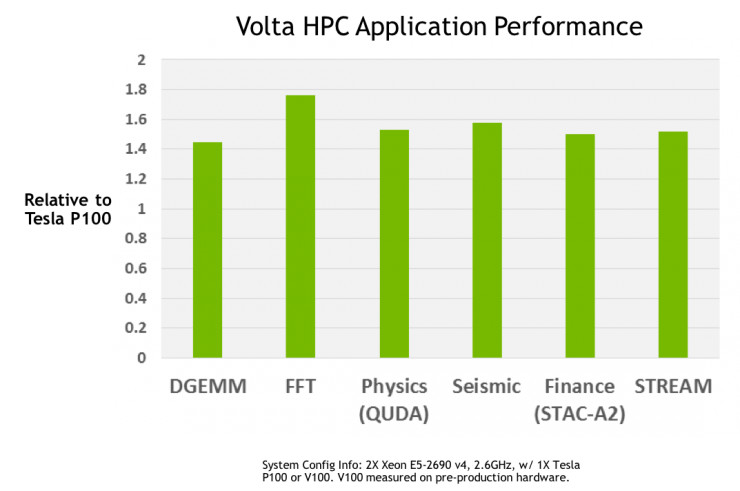
搭載 Volta GV100 GPU 的 NVIDIA Tesla V100 加速器是當今世界上性能最強的並行計算處理器。其中,GV100 GPU 具有一系列的硬件創新,爲深度學習算法和框架、HPC 系統和應用程序,均提供了強大的算力支持。其中在 HPC 領域的性能表現如下圖所示,在各種 HPC 任務中,Tesla V100 平均比 Tesla P100 快 1.5 倍(基於 Tesla V100 原型卡)。
Tesla V100擁有業界領先的浮點和整型運算性能,峯值運算性能如下(基於 GPU Boost 時鐘頻率):
● 雙精度浮點(FP64)運算性能:7.5 TFLOP/s;
● 單精度(FP32)運算性能:15 TFLOP/s;
● 混合精度矩陣乘法和累加:120 Tensor TFLOP/s。
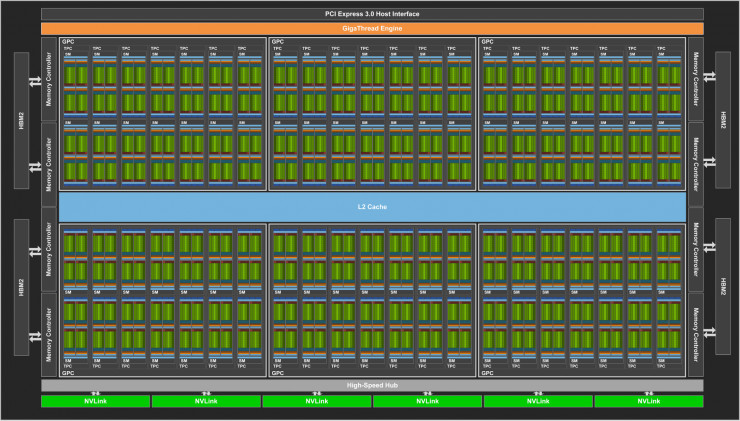
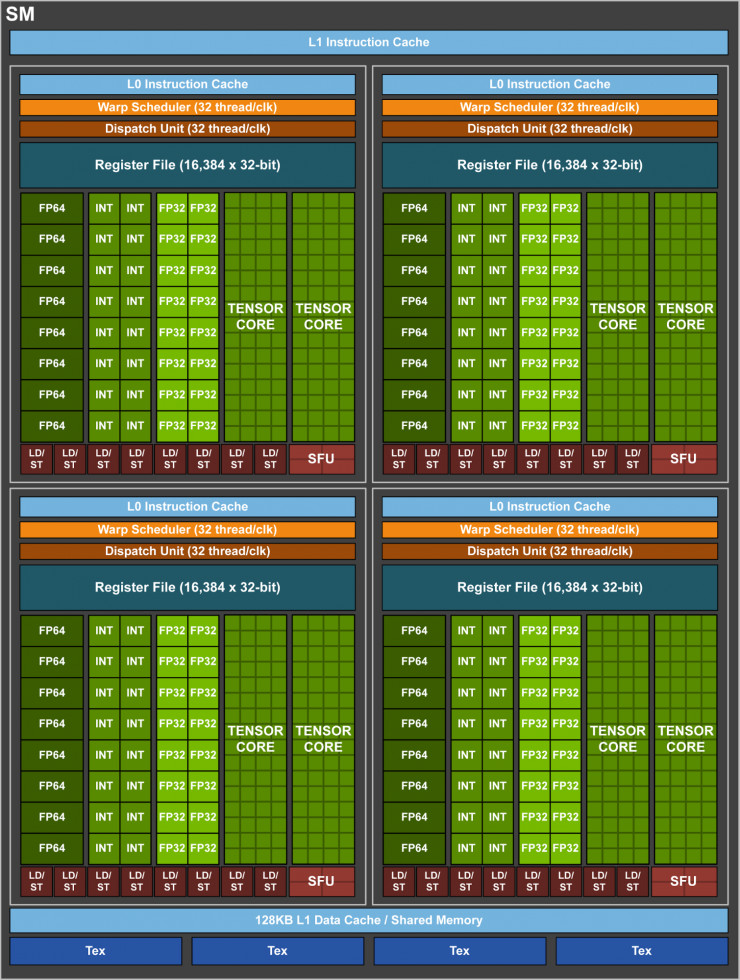
和之前的 Pascal GP100 一樣,GV100 也由許多圖形處理集羣(Graphics Processing Cluster,GPC)、紋理處理集羣(Texture Processing Cluster,TPC)、流式多處理器(Streaming Multiprocessor,SM)以及內存控制器組成。一個完整的 GV100 GPU 由 6 個 GPC、84 個 Volta SM、42 個 TPC(每個 TPC 包含 2 個 SM)和 8 個 512 位的內存控制器(共 4096 位)。其中,每個 SM 有 64 個 FP32 核、64 個 INT32 核、32 個 FP64 核與 8 個全新的 Tensor Core。同時,每個 SM 也包含了 4 個紋理處理單元(texture units)。
更具體地說,一個完整版 Volta GV100 中總共包含了 5376 個 FP32 核、5376 個 INT32 核、2688 個 FP64 核、672 個 Tensor Core 以及 336 個紋理單元。每個內存控制器都鏈接一個 768 KB 的 2 級緩存,每個 HBM2 DRAM 堆棧都由一對內存控制器控制。整體上,GV100 總共包含 6144KB 的二級緩存。下圖展示了帶有 84 個 SM 單元的完整版 Volta GV100,需要注意的是,不同的產品可能具有不同的配置,比如Tesla V100 就只有 80 個 SM。
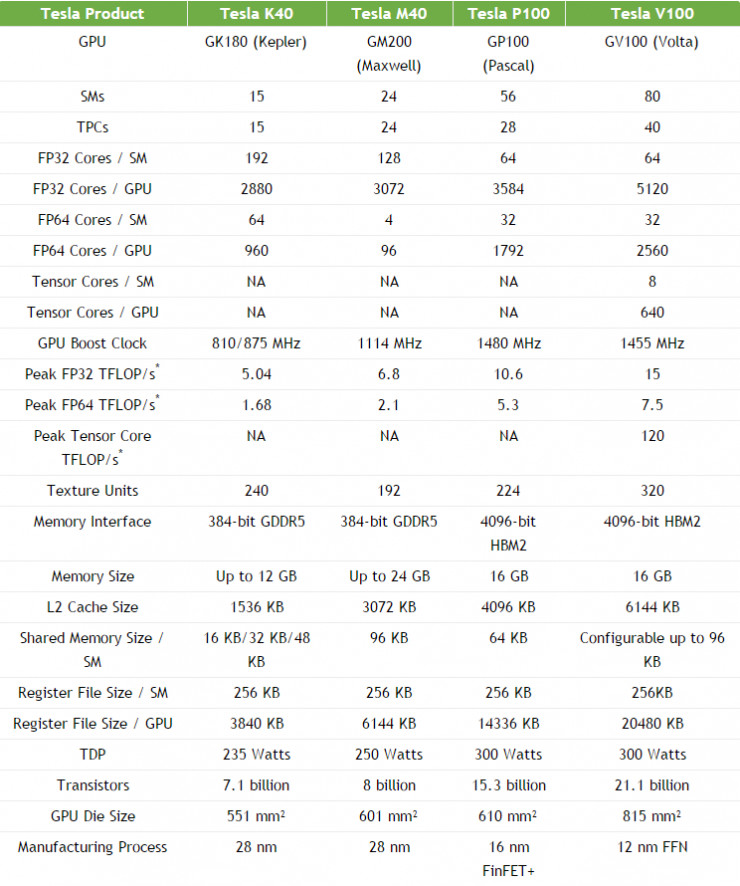
下表展示了 Tesla V100 與過去五年曆代 Tesla 系列加速器的參數對比。
Volta SM(流式多處理器)
爲了提供更高的性能,Volta SM 具有比舊版 SM 更低的指令和緩存延遲,並且針對深度學習應用做了特殊優化。其主要特性如下:
● 爲深度學習矩陣計算建立的新型混合精度 FP16/FP32 Tensor Core;
● 爲更高性能、更低延遲而強化的 L1 高速數據緩存;
● 爲簡化解碼和縮短指令延遲而改進的指令集;
● 更高的時鐘頻率和能效。
下圖顯示了 Volta GV100 SM 單元的基本結構。
Tensor Core:既是運算指令也是數據格式
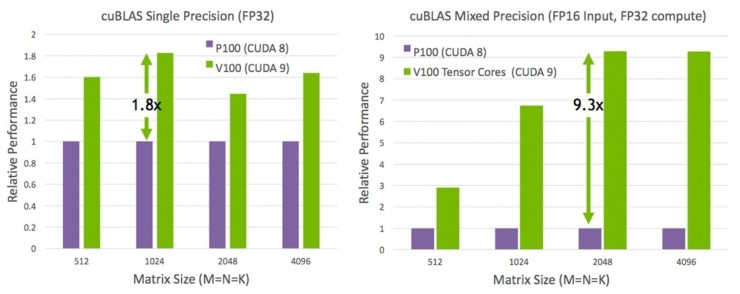
全新的 Tensor Core 是 Volta GV100 架構中最重要的一項新特性,在訓練超大型神經網絡模型時,它可以爲系統提供強勁的運算性能。Tesla V100 的 Tensor Core 可以爲深度學習相關的模型訓練和推斷應用提供高達 120 TFLOPS 的浮點張量計算。具體來說,在深度學習的模型訓練方面,相比於 P100 上的 FP32 操作,全新的 Tensor Core 可以在 Tesla V100 上實現最高 12 倍速的峯值 TFLOPS。而在深度學習的推斷方面,相比於 P100 上的 FP16 操作,則可以實現最高 6 倍速的峯值 TFLOPS。Tesla V100 GPU 一共包含 640 個 Tensor Core,每個流式多處理器(SM)包含 8 個。
衆所周知,矩陣乘法運算是神經網絡訓練的核心,在深度神經網絡的每個連接層中,輸入矩陣都要乘以權重以獲得下一層的輸入。如下圖所示,相比於上一代 Pascal 架構的 GP100,Tesla V100 中的 Tensor Core 把矩陣乘法運算的性能提升了至少 9 倍。
如本節小標題所述,Tensor Core 不僅是一個全新的高效指令集,還是一種數據運算格式。
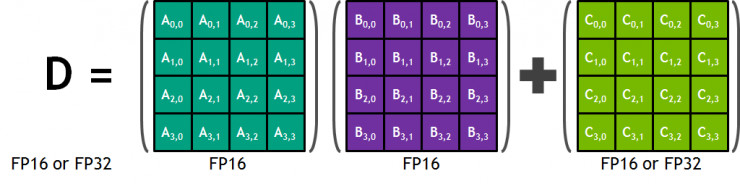
在剛發佈的 Volta 架構中,每個 Tensor Core 都包含一個 4x4x4 的矩陣處理隊列,來完成神經網絡結構中最常見的 D=AxB+C 運算。其中 A、B、C、D 是 4 個 4×4 的矩陣,因此被稱爲 4x4x4。如下圖所示,輸入 A、B 是指 FP16 的矩陣,而矩陣 C 和 D 可以是 FP16,也可以是 FP32。
按照設計,Tensor Core 在每個時鐘頻率可以執行高達 64 次 FMA 混合精度浮點操作,也就是兩個 FP16 輸入的乘積,再加上一個 FP32。而因爲每個 SM 單元都包含 8 個 Tensor Core,因此總體上每個時鐘可以執行 1024 次浮點運算。這使得在 Volta 架構中,每個 SM 單元的深度學習應用吞吐量相比標準 FP32 操作的 Pascal GP100 大幅提升了 8 倍,與Pascal P100 GPU相比,Volta V100 GPU的吞吐量總共提高了 12 倍。下圖展示了一個標準的 Volta GV100 Tensor Core 流程。
在程序執行期間,多個 Tensor Cores 通過 warp 單元協同工作。warp 中的線程同時還提供了可以由 Tensor Cores 處理的更大的 16x16x16 矩陣運算。CUDA 將這些操作作爲 Warp-Level 級的矩陣運算在 CUDA C++ API 中公開。通過 CUDA C++ 編程,開發者可以靈活運用這些開放 API 實現基於 Tensor Cores 的乘法、加法和存儲等矩陣操作。
增強的 L1 高速數據緩存和共享內存
Volta SM 的 L1 高速數據緩存和共享內存子系統相互結合,顯着提高了性能,同時也大大簡化了開發者的編程步驟、以及達到或接近最優系統性能的系統調試成本。
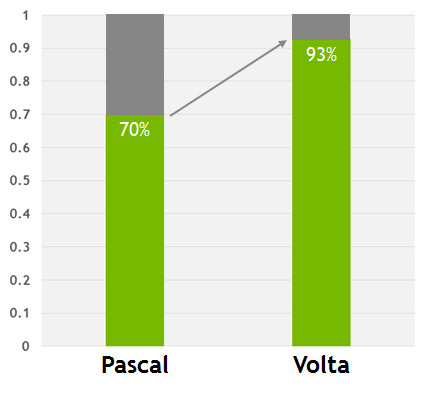
值得強調的是,Volta 架構將數據高速緩存和共享內存功能組合到單個內存塊中的做法,在整體上爲兩種類型的內存訪問均提供了最佳的性能。組合後的內存容量達到了 128 KB/SM,比老版的 GP100 高速緩存大 7 倍以上,並且所有這些都可以配置爲不共享的獨享 cache 塊。另外,紋理處理單元也可以使用這些 cache。例如,如果共享內存被設置爲 64KB,則紋理和加載/存儲操作就可以使用 L1 中剩餘的 64 KB 容量。
總體上,通過和共享內存相互組合的獨創性方式,使得 Volta GV100 L1 高速緩存具有比過去 NVIDIA GPU 的 L1 高速緩存更低的延遲和更高的帶寬。一方面作爲流數據的高吞吐量管道發揮作用,另一方面也可以爲複用度很高的數據提供高帶寬和低延遲的精準訪問。
下圖顯示了 Volta 和 Pascal 的 L1 緩存性能對比。
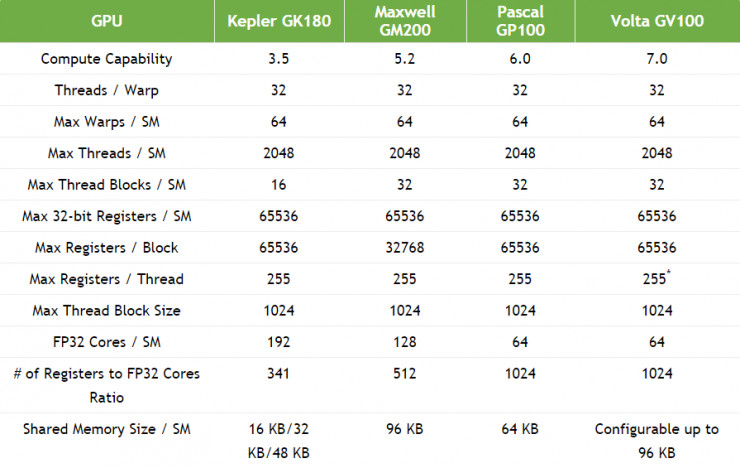
計算能力
GV100 GPU 支持英偉達全新的 Compute Capability 7.0。下表顯示了 NVIDIA GPU 不同架構之間的計算能力對比。
獨立的線程調度
Volta 架構相較之前的 NVIDIA GPU 顯著降低了編程難度,用戶可以更專注於將各種多樣的應用產品化。Volta GV100 是第一個支持獨立線程調度的 GPU,也就是說,在程序中的不同線程可以更精細地同步和協作。Volta 的一個主要設計目標就是降低程序在 GPU 上運行所需的開發成本,以及線程之間靈活的共享機制,最終使得並行計算更爲高效。
此前的單指令多線程模式(SIMT MODELS)
在 Pascal 和之前的 GPU 中,可以執行由 32 個線程組成的 group,在 SIMT 術語裏也被稱爲 warps。在 Pascal 的 warp 裏,這 32 個線程使用同一個程序計數器,然後由一個激活掩碼(active mask)標明 warp 裏的哪些線程是有效的。這意味着不同的執行路徑裏有些線程是「非激活態」的,下圖給出了一個 warp 裏不同分支的順序執行過程。在程序中,原始的掩碼會先被保存起來,直到 warps 執行結束,線程再度收斂,掩碼會被恢復,程序再接着執行。
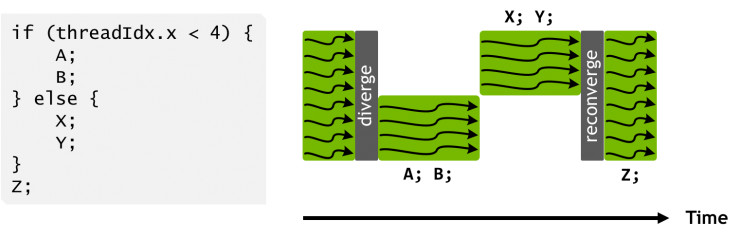
從本質上來說,Pascal 的 SIMT 模式通過減少跟蹤線程狀態所需的資源和積極地恢復線程將並行效率最大化。這種對整個 warps 進行線程狀態跟蹤的模式,其實意味着當程序出現並行分支時,warps 內部實際上是順序執行的,這裏已經喪失了並行的意義,直到並行分支的結束。也就是說,不同 warp 裏的線程的確在並行執行,但同一 warp 裏的分支線程卻在未恢復之前順序執行,它們之間無法交互信息和共享數據。
舉個例子來說,要求數據精準共享的那些算法,在不同的線程訪問被鎖和互斥機制保護的數據塊時,因爲不確定遇到的線程是來自哪個 warp,所以很容易導致死鎖。因此,在 Pascal 和之前的 GPU 裏,開發者們不得不避免細粒度同步,或者使用那些不依賴鎖,或明確區分 warp 的算法。
Volta 架構的單指令多線程模式
Volta 通過在所有線程間(不管是哪個 warp 的)實施同等級別的併發性解決了這一問題,對每個線程,包括程序計數器和調用棧,Volta 都維護同一個執行狀態,如下圖所示。
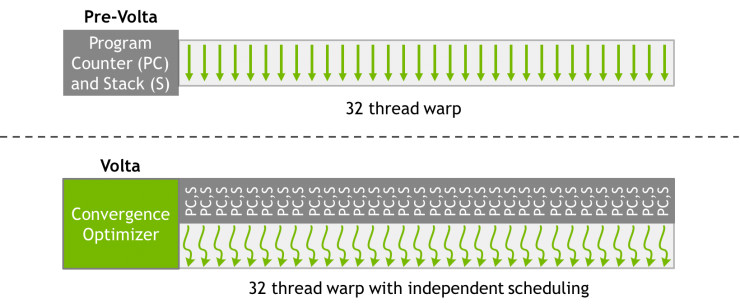
Volta 的獨立線程調配機制允許 GPU 將執行權限讓步於任何一個線程,這樣做使線程的執行效率更高,同時也讓線程間的數據共享更合理。爲了最大化並行效率,Volta 有一個調度優化器,可以決定如何對同一個 warp 裏的有效線程進行分組,並一起送到 SIMT 單元。這不僅保持了在 NVIDIA 之前的 GPU 裏較高的 SIMT 吞吐量,而且靈活性更高:現在,線程可以在 sub-warp 級別上分支和恢復,並且,Volta 仍將那些執行相同代碼的線程分組在一起,讓他們並行運行。
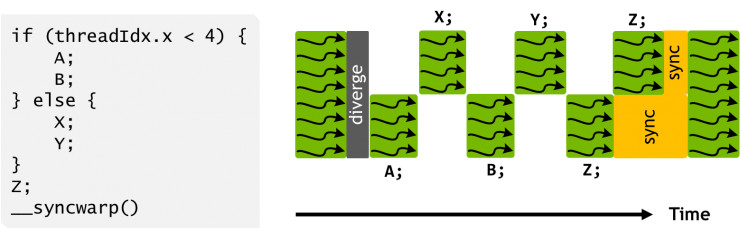
下圖展示了 Volta 多線程模式的一個樣例。這個程序裏的 if/else 分支現在可以按照時序被間隔開來,如圖12所示。可以看到,執行過程依然是 SIMT 的,在任意一個時鐘週期,和之前一樣,同一個 warp 裏的所有有效線程,CUDA 核執行的是同樣的指令,這樣依然可以保持之前架構中的執行效率。重點是,Volta 的這種獨立調度能力,可以讓程序員有機會用更加自然的方式開發出複雜且精細的算法和數據結構。雖然調度器支持線程執行的獨立性,但它依然會優化那些非同步的代碼段,在確保線程收斂的同時,最大限度地提升 SIMT 的高效性。
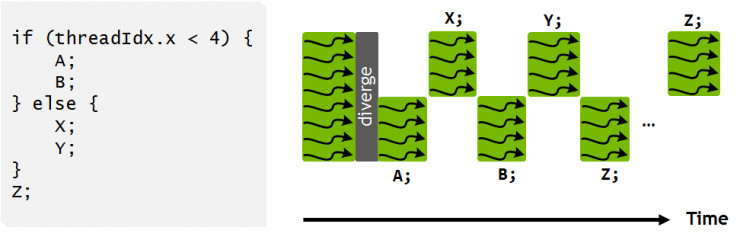
另外,上圖中還有一個有趣的現象:Z 在所有的線程中都不是同一時刻執行的。這是因爲 Z 可能會輸出其它分支進程需要的數據,在這種情況下,強制進行收斂並不安全。但在之前的架構中,一般認爲 A,B,X,Y 並不包含同步性操作,因此調度器會認定在 Z 上收斂是安全的。
在這種情況下,程序可以調用新的 CUDA 9 中的 warp 同步函數 __syncwarp() 來強制進行線程收斂,如下圖所示。這時分支線程可能並不會同步執行 Z,但是通過調用 __syncwarp() 函數,同一個 warp 裏的這些線程的所有執行路徑將會在執行到 Z 語句之前完備。類似的,在執行 Z 之前,如果調用一下 __syncwarp() 函數,則程序將會在執行 Z 之前強制收斂。如果開發者能提前確保這種操作的安全性,無疑這會在一定程度上提升 SIMT 的執行效率。
Starvation-Free 算法
Starvation-free 算法是獨立線程調度機制的一個重要模式,具體是指:在併發計算中,只要系統確保所有線程具有對競爭性資源的恰當訪問權,就可以保證其正確執行。例如,如果嘗試獲取互斥鎖(mutex)的線程最終成功獲得了該鎖,就可以在 starvation-free 算法中使用互斥鎖(或普通鎖)。在不支持 starvation-free 算法的系統中,可能會出現一個或多個線程重複獲取和釋放互斥鎖的情況,這就有可能造成其他線程始終無法成功獲取互斥鎖的問題。
下面看一個關於 Volta 獨立線程調度的實例:在多線程應用程序中將節點插入雙向鏈表。
__device__ void insert_after(Node *a, Node *b)
{
Node *c;
lock(a); lock(a->next);
c = a->next;
a->next = b;
b->prev = a;
b->next = c;
c->prev = b;
unlock(c); unlock(a);
}
在這個例子中,每個雙向鏈表的元素至少含有 3 個部分:一個後向指針,一個前向指針,以及一個 lock(只有 owner 纔有權限更新結點)。下圖展示了在 A 和 C 之間插入 B 結點的過程。

Volta 這種獨立線程調度機制可以確保即使線程 T0 目前鎖住了結點 A,同一個 warp 裏的另一個線程 T1 依然可以成功地等到其解鎖,而不影響 T0 的執行。不過,值得注意的一點是,因爲同一個 warp 下的有效線程是一起執行的,所以等解鎖的線程可能會讓鎖住的線程性能降低。
同樣需要重視的是,如此例中這種針對每個結點上鎖的用法對 GPU 的性能影響至關重要。傳統上,雙向鏈接表的創建可能會用粗粒度 lock(對應前面提到的細粒度 lock),粗粒度 lock 會獨佔整個結構(全部上鎖),而不是對每一個結點分別予以保護。由於線程間對 lock 的爭奪,因此這種方法可能會導致多線程代碼的性能下降(Volta 架構最多允許高達 163,840 個併發線程)。這時可以嘗試在每個節點採用細粒度 lock 的辦法,這樣除了在某些特定節點的插入操作之外,大型列表中平均每個節點的 lock 競爭效應就會大大降低。
上述這種具備細粒度 lock 的雙向鏈接表只是個非常簡單的例子,我們想通過這個例子傳達的信息是:通過獨立的線程調度機制,開發者們可以用最自然的方式在 NVIDIA GPU 上實現熟悉的算法和數據結構。
總結
NVIDIA Tesla V100 無疑是目前世界上最先進的數據中心 GPU,專門用於處理需要強大計算能力支持的密集型 HPC、AI、和圖形處理任務。憑藉最先進的 NVIDIA Volta 架構支持,Tesla V100 可以在單片 GPU 中提供 100 個 CPU 的運算性能,這使得數據科學家、研究人員和工程師們得以應對曾經被認爲是不可能的挑戰。
搭載 640 個 Tensor cores,使得 Tesla V100 成爲了目前世界上第一款突破 100 TFLOPS 算力大關的深度學習 GPU 產品。再加上新一代 NVIDIA NVLink 技術高達 300 GB/s 的連接能力,現實場景中用戶完全可以將多個 V100 GPU 組合起來搭建一個強大的深度學習運算中心。這樣,曾經需要數週時間的 AI 模型現在可以在幾天之內訓練完成。而隨着訓練時間的大幅度縮短,未來所有的現實問題或許都將被 AI 解決。
來源:英偉達開發者博客
相關閱讀:
2小時、5大AI 新品、英偉達股價暴漲17%,GTC大會上黃仁勳都講了些啥?(內附PPT) | GTC 2017
GTC大會第二日亮點:NVIDIA將推出多用戶VR系統,計劃培養100000名開發人員 | GTC 2017
開發者專場 | 英偉達深度學習學院現場授課
英偉達 DLI 高級工程師現場指導,理論結合實踐,一舉入門深度學習!
課程鏈接:http://www.mooc.ai/course/90