機器之心原創
作者:彭君韜(Tony)
在網絡視頻對話裏,一個有些靦腆的男生正面對着攝像頭做一場網絡工作面試的培訓,攝像頭的另一端則是一個模擬系統。這個系統觀察着男生的舉止、面部表情和聲音變化,並對他進行有關工作上的提問。
在回答某個問題時,這個男生眼睛朝左下看,音量放低,回答非常簡短。系統馬上意識到,「他走神兒了。」男生的這種反應在工作面試中往往是大忌,而這個系統能夠實時地觀察到這種行爲舉止的變化,幫助他不會在以後的面試中再出現這樣的問題。
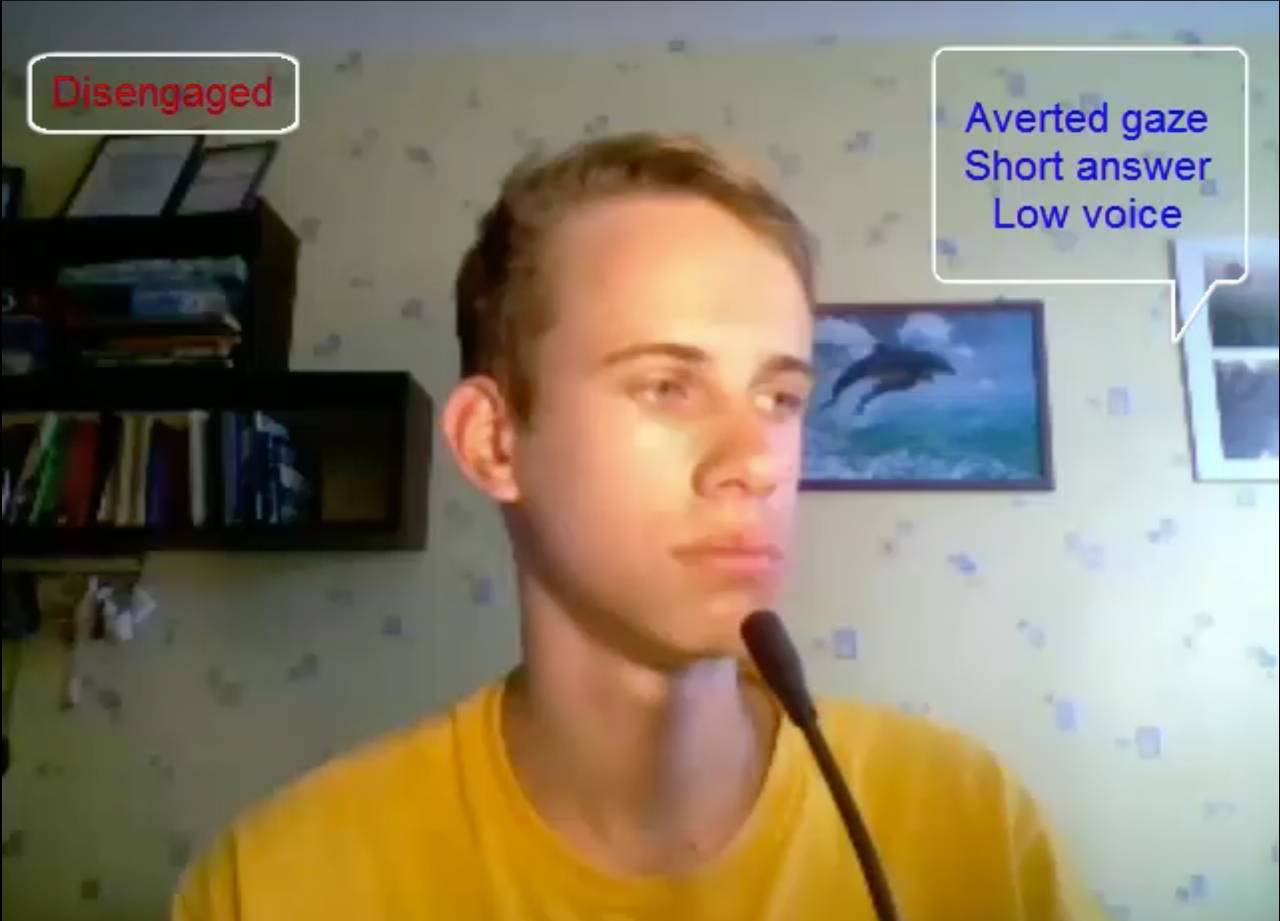
這個系統叫做 HALEF,基於實時的多模態對話系統,能通過接受不同模態的信息實現更好的人機交互。這套系統的發明者是加州大學戴維斯分校(UC Davis)的助理教授俞舟,也是該校的語言、多模態和交互實驗室(the Language, Multimodal and Interaction Lab)的主管。就在 11 月,俞博士剛剛入選了 Forbes 30 Under 30 in Science,這是福布斯爲了表彰年輕人的一個重要榜單,入選率一般不超過 5%。
在俞博士獲獎之後,機器之心第一時間聯繫到了她,並對其進行了獨家專訪。在本次採訪中,我們談到了俞博士求學期間的心路歷程、在卡內基梅隆大學讀博士期間就進行的多模態對話系統的研究,以及她對於未來事業的展望。
機器之心:先恭喜您入選 Forbes 30 Under 30 in Science,入選後對您最近的工作和生活有帶來什麼變化嗎?
俞舟:因爲我剛剛從卡內基梅隆(CMU)畢業,1 月份才入職 UC Davis,所以從某種意義上來說,這給我帶來了很多合作的機會。比如說其他公司的人知道我以後,就會邀請我去講座、包括進一步的合作。別的系的老師知道我以後,比如像傳媒系的老師也會非常感興趣這些計算模型,與我交流。還有,這對於我招聘學生有帶來一些好處,其實也是增加一些就是宣傳,讓大家知道我的一些工作。
機器之心:入選這個榜單的機率可能只有 5% 都不到,那整個評選過程是什麼樣的嗎?
俞舟:別人可以提名你,會發一個調查表到你郵件,讓你填一下自己的成就和背景。收集了以後,內部有一個委員會然後作出評價,最後確定。
機器之心:您現在是 UC Davis 語言、多模態和交互實驗室的主管,能否介紹一下您最近研究的項目?
俞舟:我一直在研究多模態對話系統。對話系統中有不同種的模態,從輸入模型的不同中,系統可以是簡單的基於文字的聊天機器人,可以是 Amazon Alexa 這樣有語音的,或者是加入更多模態(例如視覺方面)的系統,比如機器人。而輸出模型可以只是文字,也可以是語音,也可以是多模態的形式。比如說虛擬人類,在遊戲裏也會有由計算模型驅動的這種交互。虛擬角色可以做各種各樣的事情,比如教小孩子英語啊。輸出模式也可以是實體交互,就是機器人。人和機器人交流的話也可以通過自然語言完成更多的任務,實體的協作能帶來更多的實用性,就比如人可以指揮機器人去哪裏,通過交流機器人可以更好地完成它的任務,比如抓東西、運輸等。
我的主要的工作就是做交互,但這個交互有多模態在其中,可以是自然語言,可以是語音,或者是基於視覺。比如我們以前做過工作面試的場景,我們就是很看重會話能力。其中,投入/參與度(engagement)非常重要,我們通過多模態的效果來預測這種參與度,比如說看看他有沒有經常看你;他說話的聲音有沒有抑揚頓挫(prosidy, such as pitch changes),根據參與度的高低或者有沒有參與,我們的系統可以不斷地實時調整目標的行動規劃(action planning)。比如你某部分做的不夠投入,我們會給你一些鼓勵,每個人的對話都會不一樣。所以說我的工作很多就是去針對不同的用戶,對每個人會有一個獨特的交互規劃。我的會話模型很多也用到了強化學習。
機器之心:我瞭解到您在浙江大學本科時期修的是雙學位——計算機科學和語言學,爲什麼這麼選擇?
俞舟:其實是這樣子的,我是 07 年讀的本科,在浙江大學竺可楨學院就讀。當時我修了外語學院的一些課程,我本身對語言也很感興趣,而竺可楨學院也正好開了一個叫英語雙學位的班,我是我們這一屆唯一一個選計算機和英語(我選擇的方向是語言學。浙大沒有單獨的語言學,它是英語專業下面的一個分支)雙學位的。
機器之心:那您從什麼時候開始有計算機科學方面的的這個興趣?
俞舟:我小學的時候就喜歡這個,所以我很早就開始有編程的經驗。
機器之心:來到 CMU 讀博士之後,是什麼啓發了您開始研究多模態對話系統?
俞舟:我在本科大三進實驗室的時候,跟着何曉飛和蔡登兩位老師,他們一直做機器學習(machine learning)和計算機視覺(computer vision),還有數據挖掘(data mining),所以我很早就接觸 ML 和 CV。之後,我在雙學位英語系的時候,我選擇做機器翻譯(machine translation),和外語系的瞿雲華老師做中文轉英文的翻譯,我也對這個非常感興趣。
我申請博士的時候,CMU 有個特別的學院叫語言技術學院(Language Technology Institute),這屬於計算機科學大類,主要是做計算語言學(computational linguistics)和自然語言處理(natural language processing),應該是最大的、也是最好的做 NLP 的小組,有二十幾個教授。我當時申請了,但也沒有報太大希望,因爲覺得自己當時還只是本科生,雖然有一個發表的論文。不過,CMU 最後錄取我了,包括我的本科導師何曉飛老師,也挺驚訝我會被錄取。
我來到 CMU 後,才發現我這個背景是非常獨特的,沒什麼人除了計算機外會選擇讀語言學,這兩者本身在學科上的差異也比較大。後來我發現這個背景對做 nlp 是非常有用的,因爲我既懂語言學,也懂計算機科學的東西,我可以把語言學應用到各種各樣的計算模型中。因爲以前做過 CV,也有 NLP 的經驗,所以我就想把這些結合在一起。
CMU 是你去了之後才找導師的,找導師時我就找到了 Alan W Black 教授和 Alexander I. Rudnicky 教授。他們之前沒有做過 CV,但是它們做很多語音對話系統(Spoken Language Dialogue System)。去了以後,我們就開始做多模態對話系統,慢慢地就做成了一個我的論文選題。這在當時也是一個契機,我去 CMU 的時候蘋果 Siri 還沒有出來,公衆並不理解這個對話系統是個什麼樣的東西,然後慢慢的到現在纔有所瞭解,而且當時就是深度學習還沒有起來(Pre-Deep Learning)的時候我們很多自動語音識別(Automatic Speech Recognition)也不準。所以,這是一個非常好的契機,底層的技術偏向成熟的過程中,然後這種比較上層的東西就有更多可以做的空間。
在隨後對 Alan W Black 的採訪中,這位CMU的著名教授告訴機器之心:俞舟一開始致力於研究視覺和基於語音對話方面的工作,但她後來着重研究在「非任務導向」對話(non-task oriented dialog,通常稱爲chatbots)的用戶參與度(engagement)。過去,「非任務導向」對話並不是真的一個研究領域,只是一個有趣的方面,但她有興趣追求這一領域,我們也幫助她找到了資金來完成這方面的研究。 現在,這塊研究已經慢慢成爲主流,很多人也投身其中,但她是最早定義這個研究領域的一批人之一,並且已經發表了很多論文。
機器之心:那就像您所說的,13 年的時候大家意識到深度學習的效果很好,那這種轉變就是對你本身的研究會帶來一些影響嗎?
俞舟:說不上正面,也說不上負面,對於我們而言深度學習只是一種模型,而且它沒有什麼特別的。神經網絡現在被應用到不同的領域中,但是從機器學習的角度看,本質上沒有任何區別。現在是深度學習的工具做的更好了,門檻變的更低了。當然我們在這個轉型的過程中,有人更早地接受深度學習,有些人更晚。在 CMU 的話,我們比較早就接受深度學習,並不存在一個大的(轉型上)障礙。
機器之心:那麼,多模態對話系統這個領域有沒有一個相對主流的、成型的前沿系統?
俞舟:其實對話系統本身沒有這樣的系統,因爲還存在很多問題。在我們的這個對話系統中,對話本身是有一個內容,每一個事件是不一樣的。比如說你訂機票,和找飯店就不一樣,教小朋友英語和教小朋友數學都不一樣。我們也有自己不同的工具和傳遞途徑。做對話系統的基本上每一個研究小組都會主張自己的系統。如果要我遵照你的系統,有非常大的壁壘,你要給我一個很大的理由來說服,爲什麼你們要比我好,或者互相併不能說服彼此。
多模態對話系統在全世界來說,做得好的並不多,就是五六個研究小組,然後每個系統都有不同的約束,比如說之前已經有遺留系統(legacy system),這個小組不願意更新或者遷移到到其他系統。我們這個受衆又比較小,沒有那麼多人做,系統本身在工程方面有挺大的壁壘。不像深度學習,現在很多公司都有做這些工具,比如說 Amazon Alexa,他們也有出技能工具包(Skill Kits)。這個就完全沒有達到學術界要求的靈活性,甚至連 ASR 都不會給你,這都是各種各樣的問題。所以包括現在有很多人創業,就是想要做這些工具包,但是這其實也有很大的問題。我們本身這個領域有很多,就是任務之間有很大的變化,每個部分的技術更新也比較快,做到比較好的可維護性還挺難的。我們要做很多的多模態的感知和分析,這些東西要組合在一起,最後才能完成一個策略。雖然說現在我們也可以做端到端的訓練(end-to-end training),但很多情況下,根據數據的不同,很多系統都要重新調整。
機器之心:一般相比於基於語音或者文字的對話系統,這種多模態對話系統在結構上最大的區別是什麼?
俞舟:比如說語音只有一個模態,那採樣時就是一種頻率。你有視覺圖像以後,有視頻了以後,採樣頻率跟語音就不同了,而且視頻計算就比較大,你怎麼把這些不同的模態信息實時地結合在一起,要做很多融合的工作,在技術難度上就會多, 比如說你的系統要做到很好的信息傳輸(message passing),否則根本就做不起來。
同時,多模態對話系統可以基於情況提供更多的信息,比如說它可以得到更多的用戶信息,用戶笑還是沒有笑,多加一個模態,效果會好很多,包括瞭解到這個情況,比如一個人兩個人,三個人之間是什麼關係,這些都可以用到。
機器之心:那您認爲目前多模態對話最大的研究挑戰是什麼?
俞舟:三點吧,因爲我們的對話是一個動態的交互,需要和人交互,而卻這種交互是不可再重複的,因爲每個人的交互是不一樣的,所以從某種意義上講,我們的實驗是不可重複的,而且你不能在已有的數據集上訓練,否則就變成了簡單的模擬。所以說我們很多情況下要做真實的用戶研究,就是我們做了系統後要有真的人做交互。但是,在招募人的時候就會有很大的問題,比如說我們做深度學習有一千個數據點,我們要僱一千個人來做嗎?這個就非常不高效,所以我們用強化學習做很多模擬去減少這個數據的成本。
另外一點是,怎麼能把多模態對話系統的數據收集和模型評估的難度降到最低。我們做的一個系統里加入了視頻會議,比如說 Skype,我們的系統可以實時記錄對話,注意視頻和音頻兩端,在實時的過程中我們在雲端做處理。這樣的話就是我們收集數據(現在都在 Amazon Mechanical Turk 上收集,Amazon 下的一個網絡衆包平臺)就減少了一些人力成本。這是我們最近系統做的一些提升。
最後的就是私密性的問題,人臉是可辨認的,你必須要得到用戶的許可。還有就是用戶的意圖。比如我們在做教育方面,那測試的人羣真的願意學這方面的知識。但我在 AMT 上找到的人不一定真的要學習,所以這裏還存在着不匹配。
機器之心:那麼強化學習具體能夠做什麼?
俞舟:強化學習就是一個範式(paradigm),來優化這個交互。從某種意義上來講的話,我的系統和你對話,是一個序貫判定(sequential decision),我的每一步的下一步決定都是基於你之前的對話的歷史來做。這樣我才能做到最優,這就是強化學習爲什麼在交互中這麼重要。
還有,如果我在這個點做了決定 A,原來的打算做了決定 B,那我之後的數據是不是不能用了,因爲我續發事件一旦選了另外一個決定,完全就不一樣了。但是我們可以做一些用戶模擬,假設如果他是在決定 B 的時候大概會是怎麼樣,就是從某種意義上也是減少數據的成本,很多情況下,兩方面都有。
機器之心:那您在研究當中是如何去匹配這個技術研究和應用場景的?未來什麼樣的應用場景會廣泛的應用到多模態對話系統?
俞舟:我覺得這個多模態對話系統的應用非常多的,包括現在的 Amazon Alexa,它現在能做的很多事情都只是一個回合,比如放音樂。如果它可以做多回合的東西,比如推薦電影或者推薦產品,這就會取代銷售人員和客服。我們現在在做的就是可以將你的用戶情緒包含在這個對話系統中做重新規劃。例如,我知道你不開心了,我會選擇安撫你或者馬上轉到人工,用多模態對話系統更好地完善系統。
比如教育領域,你看一個網絡教育課程,它可以向你實時提問。培訓這方面就更多了,可以訓練銷售技能、駕駛技能。我們之前做工作面試培訓的系統甚至可以幫助初步篩選面試的人,收集到更多信息,給你的面試打分。
在醫療方面,我們做一個虛擬人物,它可以跟用戶通過一個半預先設定的對話(semi-constructive dialogue plan),看你有沒有心理問題,有沒有抑鬱、創傷後應激障礙(PTSD)等等。也可以做虛擬人類和有自閉症的小孩的交互,讓他們可以通過跟這些虛擬角色交流,提高社交技能;對於老年人的關懷,我們可以讓虛擬人類來監控他們的健康狀況,問他們吃藥了沒,跟他們閒聊,看看精神狀況如何。
還有就是路徑規劃,最近和 CMU 的一位老師合作將操作員和機器人合作搜救(search and rescue),人可以有一些先驗知識,機器人可以問問題,然後通過合作一起完成不同的任務。
我們之前還做指路機器人(direction-giving robot)。爲什麼要做這個機器人?就是因爲過去的交互界面特別讓人困惑,如果有一個手勢的話就很清楚了,左邊就是左邊。
機器之心:您在研究多模態對話系統,做了很多用戶參與度(user engagement)的研究,那我想知道您是如何研究並量化這個問題?
俞舟:我們之所以關注這個問題是因爲我們的定義就是你們願不願意繼續這個對話,所有的對話都需要參與度。
具體量化就是我們會讓專家來做註解,我們設置各種各樣的調查和標註方案,我們也會叫人自己寫報告,完成了交互之後自己看視頻,說自己當時有沒有非常的投入。根據這些標註來訓練計算模型。
機器之心:我瞭解到您在做這個對模態對話系統的時候,分別創建了TickTock,Direction-giving Robot,HALEF,這是您讀博士時候的主要成果,能否分別介紹一下這些系統?
俞舟:第一個系統是一個社交聊天機器人,我們把它部署到了 Amazon Alexa 上。從任務上說,現在我們把它擴展到可以和目標指向性的系統(task-oriented system)結合在一起,做前沿的任務,比如電影推薦之類的(詳見 Yu et al., IJCAI 2017)。
第二個是人和機器人交互,這個用到很多注意力機制,就看用戶是不是有注意。因爲在這種指導性任務中沒有注意力就不會有認知變化。我們獲得注意力的方法就比如說用一些繪畫策略,說「excuse me」,「restart」,「can you tell me」,效果就比較好。
第三個就是之前提到工作面試系統,幫助人提高他的對話能力。比如這個人是非母語對話者,需要訓練自己的會話能力,通過這個機器人交互來做到。比如說我發現他參與度差的時候就缺乏信心,我就可以做一些鼓勵,「I think you are doing great.」,他可以更好地訓練自己的會話能力。
機器之心:您到目前爲止您最滿意的你的一篇論文研究是什麼?
俞舟:這個還挺難講的(笑),應該還是我最近的一個研究,總是最新的那個是最滿意。
機器之心:那多模態對話系統會是您的 lifelong 的研究目標嗎?
俞舟:那肯定是 lifelong 的,其實就是解決用不同模態的信息做更好的交互,這就是要解決的這個問題。
機器之心:像現在基於文字的和基於語音的這種對話系統其實已經已經大量的進入到了現在工業界的應用範疇,那您認爲像多模態這樣的對話系統,它將會在什麼時候會大批量的進入到工業界?
俞舟:五到十年吧。就比如說 Amazon Alexa 出現的時機,因爲他還是個音箱,比如說人家買個音箱也是這麼多錢,還不如買一個 Amazon Alexa。市場和研究是兩回事,你需要找一個非常好的切入口。
機器之心:我瞭解到 Amazon 最近給您 100,000 萬美元用於開發 Echo 平臺的社交聊天機器人,能否說說這個項目背後的整個經過?
俞舟:這個項目我去年 11 月份的時候拿到的,是我還在 CMU 的時候的一個團隊。今年就是我在 Davis,它是每年可以續約研究的。
機器之心:那麼你大概會開發一款什麼樣的社交聊天機器人?
俞舟:它其實就是一個非常綜合的系統,可以跟你聊任何東西,它的唯一的目標,就是要讓對話者待在這個對話中。我的論文的很大一部分是開放式社交聊天(open-domain social chatting),比較偏 NLP 的部分,比如說怎麼利用知識庫來做更好的自然語言理解(natural language understanding),用計算語言學做落地來加強會話的效果。
最近我們發表在 IJCAI 2017 的一個研究就是把社交聊天和任務結合在一起,可以讓這個任務更好地完成。因爲這個帶有社交屬性的任務有很大的靈活性,可以幫助人更好地理解和適應這個對話,同時加一個社交的部分更容易影響對話者,增加更多的技能。
機器之心:語音識別的錯誤率其實已經降到大概 5% 的水平,但是依然還有不少挑戰,比如包括說在分離噪音和人聲以及分辨多個人聲,像雞尾酒派對這樣問題,那在對模態對話系統中有沒有一些關於語音識別方面獨有的挑戰?
俞舟:在交互中語音識別是非常難的。人說話並不是就是一句話就說到底了,它裏面有很多就是不流暢的地方,比如說錯了以後還得重說,很多都不是符合文法的。這會帶給語音識別帶來很多的挑戰。我也做一些語音的工作,但主要是做逐漸增加的語音識別(incremental speech recognition)。爲什麼這個很重要呢?因爲在對話系統中人和機器交互,你希望機器越早回來回答你越好,你這個語音識別是需要時間的,我們就想要儘快地解碼,你說幾個詞我們就解碼一下。
就我們而言,我們也會想要研究聲音事件(sound event),瞭解你的環境,比如學校,派對,火車的聲音,我可以把這些東西在語音識別以前就降噪。包括聲紋識別(speaker identification),也是我們研究的方向。
機器之心:關於自然語言理解中的非語法問題呢?
俞舟:我們在做很多語法分析上的拆解。NLU 在對話中非常重要,比如說意圖識別,只需要知道幾個單詞就可以知道用戶的意圖。你如果做開放領域的話,這也是非常需要這一點,這也是我的未來研究方向:怎麼做到語義分析、意圖分析。比如說「我有隻貓,我很喜歡它」,這個它是這個貓對不對;還有比如說「我有隻貓,我可喜歡了」我沒有會所賓語是什麼,可是上下文我可以理解我指的就是那個貓。第一種是指代(co-reference),第二種是省略(ellipsis)的問題,這個語法分析就很難。
機器之心:提高對話系統的回合數,讓機器和人類能夠進行多回合長時間的溝通是一件非常困難的事情。這方面的研究,挑戰在哪兒?
俞舟:回合的長短和對話系統好壞還是兩回事情,這要看設計過程中的目標。比如我們通常稱爲的回報函數(reward function),我的目的是讓你和機器人講話越講越久,那我就建議優化目標是回合數越多越好;那我如果是完成一個簡單的任務對,其實你的目標是越有效越好。
機器之心:多模態對話系統是一個非常跨專業的領域,對於想要學習多模態對話系統的學生,你有什麼好的建議嗎?
俞舟:我的建議就是說,先要學習這個對話,先從單模態裏開始學習。我們這個領域科學和工程學是並重的,有非常好的實施的場景。而且你要做好準備,這個專業裏面有很多的內容,你不僅僅要做設計和算法,你也要測試這個算法,在和人類做真實對話的時候有沒有效果。
俞舟:這是一個非常鬱悶的事情,就是這個領域一直沒有一個很好的教科書,因爲發展太快了。我其實想寫一本書,但是也是沒有時間,可能要過兩年。但是你可以從最基本的學習,你可以從 NLP 開始學起。書的話比如就是 Daniel Jurafsky 和 James H. Martin 的《Speech and Language Processing》,網上有第三版的 draft。
機器之心:有哪些機構和大學在這一方面在這個領域是佼佼者?
俞舟:比如 Microsoft Research,我曾經在那兒做過實習;南加大的 Institute for Creative Technologies,歐洲的 KTH, Bielefeld 等等。
機器之心:在學術圈這麼多年,有沒有想過在未來投身工業界?
俞舟:現在有很多機會,但是最重要的還是做我覺得有意思的事兒。
機器之心:就您個人的話,因爲做多模態對話系統可能需要你很關注社交、交流、和別人打交道,你是一個喜歡社交的人嗎?
俞舟:(笑)我應該還 ok 吧哈哈,我並不是一個非常外向的人,但是我覺得我也是可以在與人交流中得到很多的信息,並且從中感覺到快樂的。
機器之心:在學術圈做研究項目中,尋求資金支持是一個很重要的話題,那麼你覺得在這個方面是一個比較簡單的事情,還是一個比較困難的事情?
俞舟:我不太清楚別人是怎樣的,但是我自己來說我覺得可以,並不是說我非常超過這個範圍的事情,工業界都很支持,包括 NSF、DARPA,他們也看到這個是未來,這個交互會在未來有很大的影響力。
機器之心:除了學術之外的興趣愛好是什麼?
俞舟:我看 Youtube 視頻,喜歡看小動物視頻(笑)。因爲我覺得看這個小動物視頻非常的減壓,很可愛的小動物。我非常希望能夠養一個小動物,但是我經常出差,也也沒有辦法。還有就是看書。
機器之心:希望招募什麼樣的學生?
首先我來講講你爲什麼要來我的組念 Postdoc 或者 PhD. 我們這個領域非常有前景,我也花很多的時間來帶學生做項目。我的組還在成長中,現在有兩個博士生,還有四個碩士生。工業界也非常支持多模態對話系統的推進,所以我很希望有能力的學生能夠進入這個領域。我希望能有博士後能加入我的團隊,可以是一年或者兩年。我的組現在就有一個名額。在這個過程中可以一直接觸到前沿的研究,而且這兩年之後會有非常好的學術界的或者創業的機會。對於學生的背景,我會希望他會有機器學習、自然語言處理、語音識別等相關專業的基礎,同時也有很好的工程能力。
機器之心:最後一個問題,您怎麼評價自己的工作?
我覺得我們這個工作,包括我和我的 Ph.D,就是在努力的把這個方向往前推一點,希望做更多有意義的研究。因爲我們這個是一個非常跨領域工作,也是在慢慢希望推進我們的研究。我也經常辦學術會議,把不同領域的人拉進來一起合作,就是希望可以通過我們的一些努力可以把這個領域往前推一點。
本文爲機器之心原創,轉載請聯繫本公衆號獲得授權。