深度學習八大開源框架
導讀:深度學習(Deep Learning)是機器學習中一種基於對數據進行表徵學習的方法,深度學習的好處是用非監督式或半監督式的特徵學習、分層特徵提取高效算法來替代手工獲取特徵(feature)。作爲當下最熱門的話題,Google、Facebook、Microsoft等巨頭都圍繞深度學習重點投資了一系列新興項目,他們也一直在支持一些開源深度學習框架。
目前研究人員正在使用的深度學習框架不盡相同,有 TensorFlow、Torch 、Caffe、Theano、Deeplearning4j等,這些深度學習框架被應用於計算機視覺、語音識別、自然語言處理與生物信息學等領域,並獲取了極好的效果。
下面讓我們一起來認識目前深度學習中最常使用的八大開源框架:
一.TensorFlow

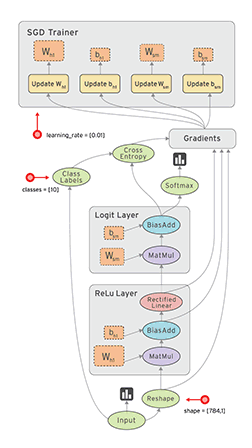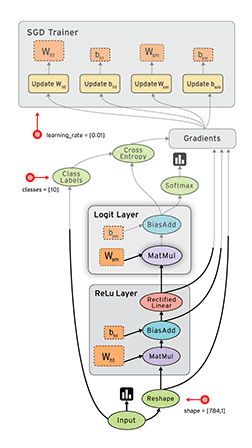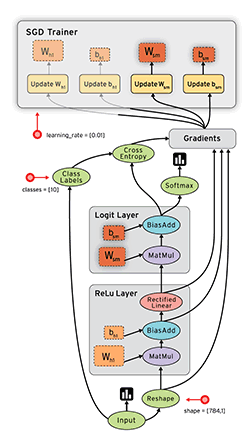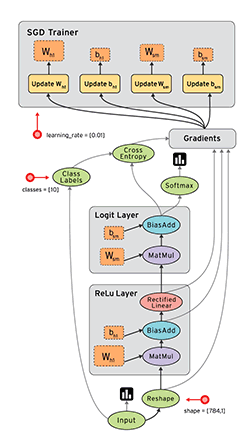
TensorFlow是一款開源的數學計算軟件,使用數據流圖(Data Flow Graph)的形式進行計算。圖中的節點代表數學運算,而圖中的線條表示多維數據數組(tensor)之間的交互。TensorFlow靈活的架構可以部署在一個或多個CPU、GPU的臺式以及服務器中,或者使用單一的API應用在移動設備中。TensorFlow最初是由研究人員和Google Brain團隊針對機器學習和深度神經網絡進行研究所開發的,目前開源之後可以在幾乎各種領域適用。
Data Flow Graph: 使用有向圖的節點和邊共同描述數學計算。graph中的nodes代表數學操作,也可以表示數據輸入輸出的端點。邊表示節點之間的關係,傳遞操作之間互相使用的多位數組(tensors),tensor在graph中流動——這也就是TensorFlow名字的由來。一旦節點相連的邊傳來了數據流,節點就被分配到計算設備上異步的(節點間)、並行的(節點內)執行。
TensorFlow的特點:
機動性: TensorFlow並不只是一個規則的neural network庫,事實上如果你可以將你的計算表示成data flow graph的形式,就可以使用TensorFlow。用戶構建graph,寫內層循環代碼驅動計算,TensorFlow可以幫助裝配子圖。定義新的操作只需要寫一個Python函數,如果缺少底層的數據操作,需要寫一些C++代碼定義操作。
可適性強: 可以應用在不同設備上,cpus,gpu,移動設備,雲平臺等
自動差分: TensorFlow的自動差分能力對很多基於Graph的機器學習算法有益
多種編程語言可選: TensorFlow很容易使用,有python接口和C++接口。其他語言可以使用SWIG工具使用接口。(SWIG—Simplified Wrapper and Interface Generator, 是一個非常優秀的開源工具,支持將 C/C++ 代碼與任何主流腳本語言相集成。)
最優化表現: 充分利用硬件資源,TensorFlow可以將graph的不同計算單元分配到不同設備執行,使用TensorFlow處理副本。
二.Torch

Torch是一個有大量機器學習算法支持的科學計算框架,其誕生已經有十年之久,但是真正起勢得益於Facebook開源了大量Torch的深度學習模塊和擴展。Torch另外一個特殊之處是採用了編程語言Lua(該語言曾被用來開發視頻遊戲)。
Torch的優勢:
構建模型簡單
高度模塊化
快速高效的GPU支持
通過LuaJIT接入C
數值優化程序等
可嵌入到iOS、Android和FPGA後端的接口
三.Caffe

Caffe由加州大學伯克利的PHD賈揚清開發,全稱Convolutional Architecture for Fast Feature Embedding,是一個清晰而高效的開源深度學習框架,目前由伯克利視覺學中心(Berkeley Vision and Learning Center,BVLC)進行維護。(賈揚清曾就職於MSRA、NEC、Google Brain,他也是TensorFlow的作者之一,目前任職於Facebook FAIR實驗室。)
Caffe基本流程:Caffe遵循了神經網絡的一個簡單假設——所有的計算都是以layer的形式表示的,layer做的事情就是獲得一些數據,然後輸出一些計算以後的結果。比如說卷積——就是輸入一個圖像,然後和這一層的參數(filter)做卷積,然後輸出卷積的結果。每一個層級(layer)需要做兩個計算:前向forward是從輸入計算輸出,然後反向backward是從上面給的gradient來計算相對於輸入的gradient,只要這兩個函數實現了以後,我們就可以把很多層連接成一個網絡,這個網絡做的事情就是輸入我們的數據(圖像或者語音等),然後來計算我們需要的輸出(比如說識別的標籤),在訓練的時候,我們可以根據已有的標籤來計算損失和gradient,然後用gradient來更新網絡的參數。
Caffe的優勢:
上手快:模型與相應優化都是以文本形式而非代碼形式給出
速度快:能夠運行最棒的模型與海量的數據
模塊化:方便擴展到新的任務和設置上
開放性:公開的代碼和參考模型用於再現
社區好:可以通過BSD-2參與開發與討論
四.Theano

2008年誕生於蒙特利爾理工學院,Theano派生出了大量深度學習Python軟件包,最著名的包括Blocks和Keras。Theano的核心是一個數學表達式的編譯器,它知道如何獲取你的結構。並使之成爲一個使用numpy、高效本地庫的高效代碼,如BLAS和本地代碼(C++)在CPU或GPU上儘可能快地運行。它是爲深度學習中處理大型神經網絡算法所需的計算而專門設計的,是這類庫的首創之一(發展始於2007年),被認爲是深度學習研究和開發的行業標準。
Theano的優勢:
集成NumPy-使用numpy.ndarray
使用GPU加速計算-比CPU快140倍(只針對32位float類型)
有效的符號微分-計算一元或多元函數的導數
速度和穩定性優化-比如能計算很小的x的函數log(1+x)的值
動態地生成C代碼-更快地進行計算
廣泛地單元測試和自我驗證-檢測和診斷多種錯誤
靈活性好
五.Deeplearning4j

顧名思義,Deeplearning4j是「for Java」的深度學習框架,也是首個商用級別的深度學習開源庫。Deeplearning4j由創業公司Skymind於2014年6月發佈,使用 Deeplearning4j的不乏埃森哲、雪弗蘭、博斯諮詢和IBM等明星企業。DeepLearning4j是一個面向生產環境和商業應用的高成熟度深度學習開源庫,可與Hadoop和Spark集成,即插即用,方便開發者在APP中快速集成深度學習功能,可應用於以下深度學習領域:
人臉/圖像識別
語音搜索
語音轉文字(Speech to text)
垃圾信息過濾(異常偵測)
電商欺詐偵測
除了以上幾個比較成熟知名的項目,還有很多有特色的深度學習開源框架也值得關注:
六.ConvNetJS

這是斯坦福大學博士生Andrej Karpathy開發的瀏覽器插件,基於萬能的JavaScript可以在你的遊覽器中訓練深度神經模型。不需要安裝軟件,也不需要GPU。
七.MXNet

出自CXXNet、Minerva、Purine 等項目的開發者之手,主要用C++ 編寫。MXNet 強調提高內存使用的效率,甚至能在智能手機上運行諸如圖像識別等任務。
MXNet的系統架構如下圖所示:
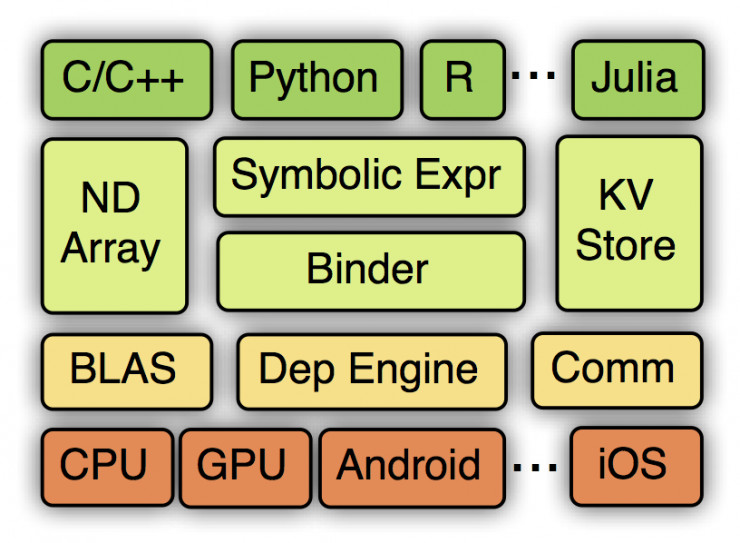
從上到下分別爲各種主語言的嵌入,編程接口(矩陣運算,符號表達式,分佈式通訊),兩種編程模式的統一系統實現,以及各硬件的支持。
八.Chainer

來自一個日本的深度學習創業公司Preferred Networks,今年6月發佈的一個Python框架。Chainer 的設計基於 define by run原則,也就是說該網絡在運行中動態定義,而不是在啓動時定義。
PS : 本文由雷鋒網(公衆號:雷鋒網)獨家編譯,未經許可拒絕轉載!
via KDnuggets等
