
在 Google I/O 大會上,谷歌公佈了最新的機器學習算法——AutoML,隨即,Quoc Le 與 Barret Aoph 大神在 Google Research Blog 上發佈了一篇名爲《採用機器學習探索神經網絡架構》的文章。進行了編譯,並做了不改動原意的編輯和修改。
「在谷歌團隊,我們成功地將深度學習模型應用於非常多的領域,從圖像識別、語音識別到機器翻譯等等。自然,這些工作離不開一整支工程師與科學家團隊的努力。人工設計機器學習模型的過程實際上絕非坦途,因爲所有可能組合模型背後的搜索空間非常龐大——一個典型的十層神經網絡可能有~1010 種可能的神經網絡組合。問題也接踵而至,爲了應對這樣龐大的數量級,神經網絡的設計不僅耗時,而且需要機器學習專家們累積大量的經驗。」
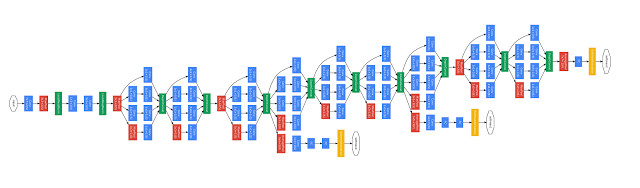
如圖是 GoogleNet 的架構。神經網絡的設計需要從最初的卷積架構開始,進行多年的細心調試
爲了讓機器學習模型的設計變得更加簡單,谷歌團隊一直希望能讓這一過程自動化。此前谷歌也有做不少嘗試,包括 evolutionary algorithms 與 reinforcement learning algorithms 等算法已經呈現了比較好的結果。而 Quoc Le 與 Barret Zoph 在此文中所展現的,是谷歌大腦團隊目前在強化學習上得到的一些嘗試與早期結果。
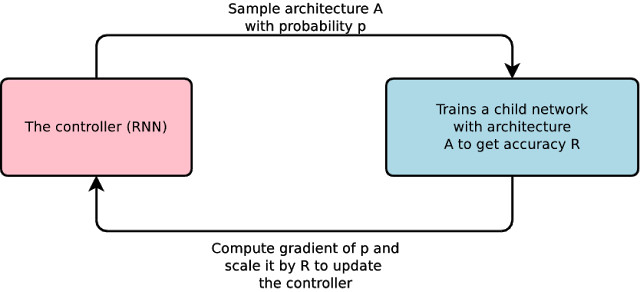
在團隊一個名爲「AutoML」的項目中(如圖所示),左邊有一個名爲「控制器」(the controller)的 RNN,它設計出一個「child」的模型架構(我們覺得可以稱之爲「雛形/子架構」),而後者能夠通過某些特定任務進行訓練與評估。隨後,反饋的結果(feedback)得以返回到控制器中,並在下一次循環中提升它的訓練設定。這一過程重複上千次——生成新的架構、測試、再把反饋輸送給控制器再次學習。最終,控制器會傾向於設計那些在數據集中能獲得更高準確性的架構,而反之亦然。
谷歌團隊將這一方法應用於深度學習的兩大數據集中,專注圖像識別的 CIFAR-10 與語言建模的 Penn Treebank。在兩個數據集上,系統自行設計的模型性能表現與目前機器學習專家所設計的領先模型不相上下(有些模型甚至還是谷歌成員自己設計的!)。
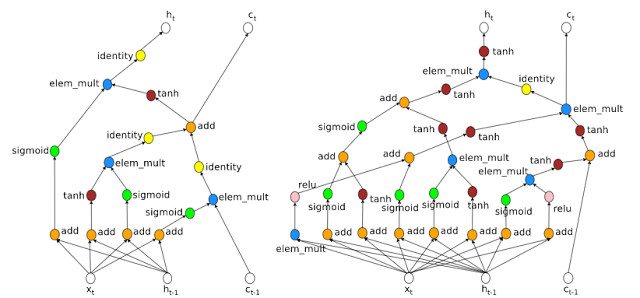
猜猜哪個是人類設計的神經網絡架構,哪個是機器設計的?
讓機器自行選擇架構(machine-chosen architecture),與人類在設計神經網絡的時候有一些共通之處,比如都採用了合併輸入,並借鑑了此前的隱藏層。但其中也有一些亮點,比如機器選擇的架構包含乘法組合 ( multiplicative combination),如右圖最左邊(機器設計)的藍色標籤爲「elem_mult」。對於循環神經網絡而言,出現組合的情況並不多見,可能因爲人類研究者並沒有發現明顯的優勢。有意思的地方在於,此前人類設計者也提議過機器採用的乘法組合,認爲這種方法能夠有效緩解梯度消失/爆炸問題。這也就意味着,機器選擇的架構能夠對發現新的神經架構大有裨益。
此外,機器還能教會人類爲何某些神經網絡的運行效果比較好。上圖右邊的架構有非常多的渠道,梯度可以向後流動,這也解釋了爲何 LSTM RNNs 的表現比標準 RNN 的性能要好。
「從長遠看來,我們對於機器所設計的架構進行深入的分析和測試,這能夠幫助我們重新定義原本自身對架構的看法。如果我們成功,這意味着將會啓發新的神經網絡的誕生,也能讓一些非專家研究人員根據自己的需要創造神經網絡,讓機器學習造福每一個人。」
參考文獻:
[1] Large-Scale Evolution of Image Classifiers, Esteban Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Yutaka Leon Suematsu, Quoc Le, Alex Kurakin. International Conference on Machine Learning, 2017.
[2] Neural Architecture Search with Reinforcement Learning, Barret Zoph, Quoc V. Le. International Conference on Learning Representations, 2017.
via research.googleblog,