日前,NIPS 2017 線上分享邀請到了杜克大學溫偉。溫偉博士分享了兩種不同的方法 TernGrad 與 SSL。這篇文章對溫偉博士的分享做了回顧,同時也編譯介紹了這兩篇相關論文。
溫偉博士線上分享視頻回顧
TernGrad
TernGrad[1] 是一種梯度量化方法,將浮點梯度隨機量化到 {-1,0,+1},在保證識別率的情況下,大大降低梯度通信量。這篇論文是 NIPS 2017 Deep Learning track 裏的 4 篇 orals 之一。
目前,論文已經可以從 arXiv 下載,源代碼也在溫偉的個人 GitHub 上公開。
論文鏈接:https://arxiv.org/pdf/1705.07878.pdf
代碼地址:https://github.com/wenwei202/terngrad
隨着深度學習神經網絡規模越來越大,訓練一個深度神經網絡(Deep Neural Networks, DNNs)往往需要幾天甚至幾周的時間。爲了加快學習速度,經常需要分佈式的 CPU/GPU 集羣來完成整個訓練。如圖 1,在主流的基於數據並行(data parallelism)的分佈式深度學習中,各個計算單元(worker)併發地訓練同一個 DNN,只不過各個單元用到的訓練數據不一樣,每一次迭代結束後,各個計算單元裏的 DNN 參數或梯度 會通過網絡(如以太網,InfiniBand 等)發送到參數服務器(Parameter Server)進行同步再下發。訓練時間主要包括計算時間(computation time)和通信時間(communication time)。計算時間可以通過增加 workers 減少,然而,通信時間卻隨着 workers 的增加而增加。因此,在大規模分佈式訓練中,通信時間成爲了新的瓶頸,如何降低通信時間成爲很重要的研究課題。理論上,TernGrad 可以把通信量至少減少到 1/20;實際應用中,即使對 0 和±1 採用簡單的 2 比特編碼(浪費掉一個可用值),相對於傳統的 32 比特的浮點型梯度,通信量也可以減少到 1/16。這可以大大克服通信瓶頸的約束,提升分佈式訓練的可擴展性。
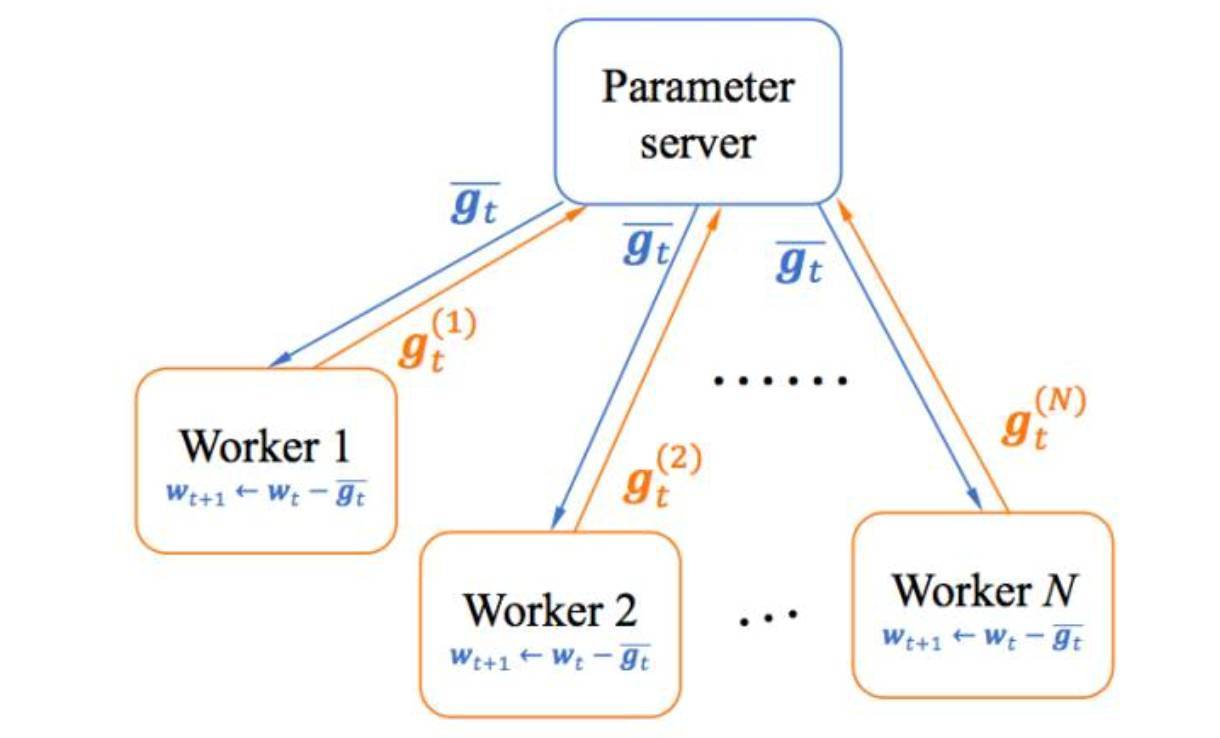
圖 1. 基於數據並行的分佈式訓練
溫偉介紹說,「大大降低梯度的精度,會嚴重影響 DNN 訓練效果。在基於量化的深度模型壓縮算法中,即使可以將網絡權重量化到低精度,但是訓練過程仍然需要浮點精度的梯度,以保證訓練的收斂性。那麼我們是怎麼將梯度量化到只有三個值,卻不影響最後識別率的呢?我們的方法其實很簡單,在普遍採樣的隨機梯度下降(Stochastic Gradient Descent,SGD)訓練方法中,梯度是隨機的,而且這種隨機性甚至可以有助於 DNNs 跳出很差的局部最小值。既然梯度本來就是隨機的,那爲什麼我們不把它們進一步隨機地量化到 0 和±1 呢?在隨機量化時,我們只需要保證新梯度的均值還跟原來一樣即可。
在訓練過程中,因爲學習率往往較小,在梯度形成的優化路徑上,即使 TernGrad 偶爾偏離了原來的路徑,由於均值是一樣的,後續的隨機過程能夠將偏離彌補回來。我們基於伯努利分佈,類似於扔硬幣的形式,把梯度隨機量化到 0 或±1。在合理假設下,我們理論上證明了 TernGrad 以趨近於 1 的概率收斂到最優點。相對於標準 SGD 對梯度的上界約束,TernGrad 對梯度有更強的上界約束,但是我們提出了逐層三元化(layer-wise ternarizing)和梯度修剪(gradient clipping)技術,使得 TernGrad 的梯度上界約束接近標準 SGD 的上界約束,從而大大改善了 TernGrad 的收斂性。實驗結果表明,在分佈式訓練 AlexNet 時,TernGrad 有時甚至會提高最後的識別率;在 GoogleNet 上,識別率損失也小於 2%。(圖 2 爲分佈式訓練 AlexNet 的結果,相對於標準 SGD 基線,TernGrad 具有同樣的收斂速度和最終識別率。)」
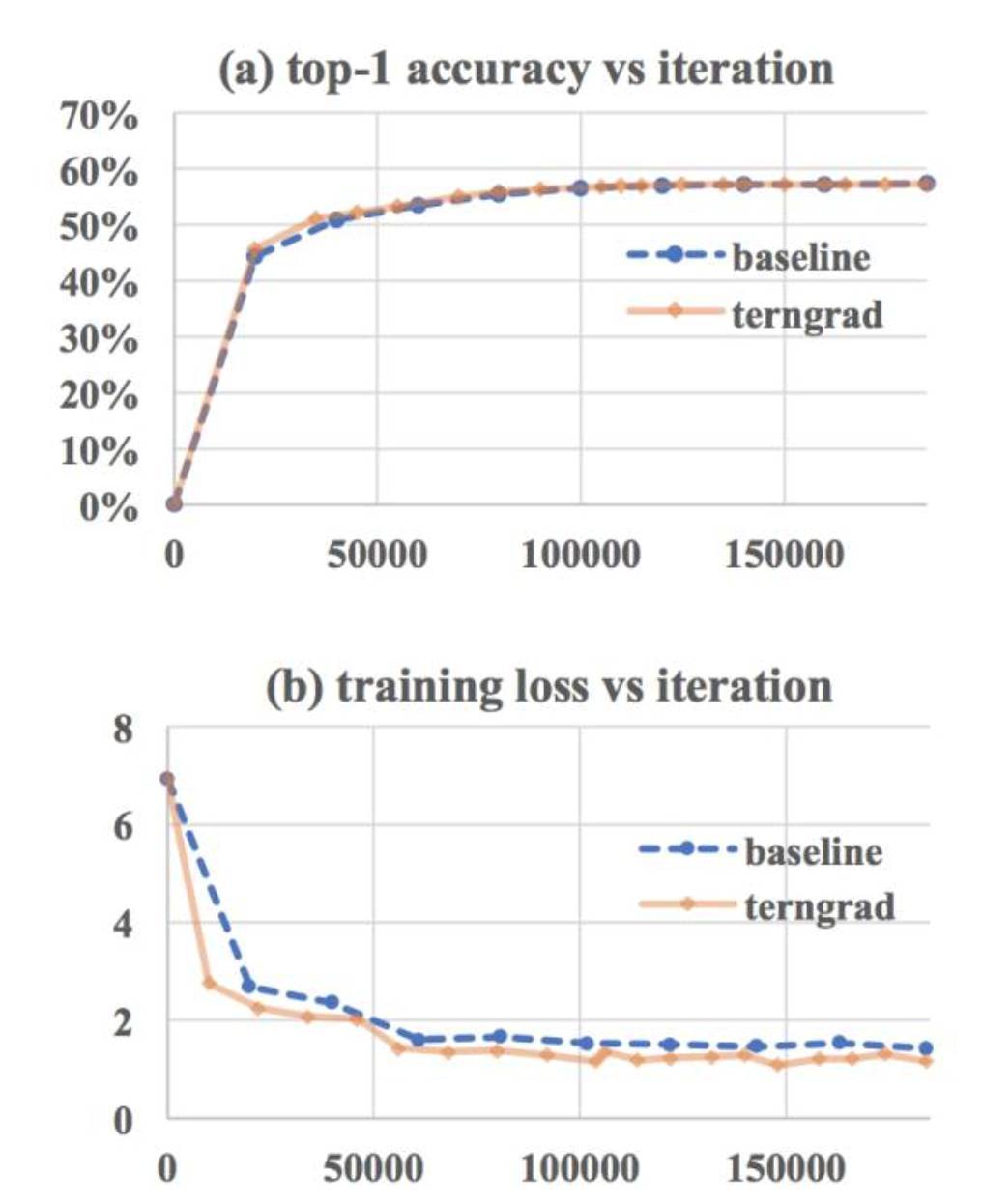
圖 2:基於 TernGrad 訓練 AlexNet 的收斂性
更多詳細內容,請參見文章:學界 | 杜克大學 NIPS 2017 Oral 論文:分佈式深度學習訓練算法 TernGrad
SSL
本次分享的第二個主題是 SSL[2]。相對於連接剪枝 (Connection Pruning),SSL 可以直接控制稀疏模式,避免稀疏權重隨機分佈導致的計算效率低的問題。SSL 是一個通用方法:在 CNNs 中,SSL 可以去掉 filters,channels,neurons,ResNets 裏的 layers,學到非矩形的 filter 形狀,以及去掉權重矩陣裏面的行和列。
該論文發表在 NIPS 2016,並與微軟研究院-雷德蒙德合作,擴展到 LSTMs 並提交在某會議 [3]。在 LSTMs 中,SSL 可以有效地去掉 hidden states,cells,gates 和 outputs,從而直接學到一個 hidden size 更小的 LSTMs 並不改變 LSTMs 內部固有的結構。
以下是對該論文的編譯介紹:
深度學習對計算資源的巨量需求嚴重阻礙了我們在有限計算力的設備中部署大規模深度神經網絡(DNN)。在本研究中,我們提出了一種結構化稀疏學習(Structured Sparsity Learning /SSL)方法對 DNN 的結構(即卷積核、通道、卷積核尺寸和層級深度)進行正則化。SSL 可以:(1)從大的 DNN 學習到更緊湊的結構以減少計算開銷;(2)獲得有利於硬件加速的 DNN 結構化稀疏,以加快部署後的 DNN 的計算速度。實驗結果表明,在 AlexNet 卷積網絡上,即使採用現成的軟件庫,SSL 在 CPU 和 GPU 上分別實現了 5.1 倍和 3.1 倍加速。這些加速是非結構化稀疏的兩倍。(3)正則化 DNN 的結構以提高分類準確度。結果表明在 CIFAR-10 中,SSL 對網絡層級深度的正則化可以將 20 層的深度殘差網絡(ResNet)減少到 18 層,且準確度由原來的 91.25% 提高到 92.60%,這仍然比 32 層原版 ResNet 的準確度略高。對於 AlexNet 來說,SSL 提供的結構正則化可以提高約 1% 的分類精度。
我們的源代碼地址爲:https://github.com/wenwei202/caffe/tree/scnn
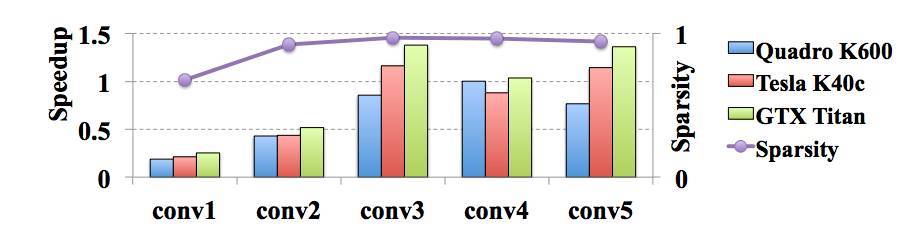
圖 1:AlexNet 在 GPU 平臺上的非結構化稀疏和加速。其中 conv1 爲第一個卷積層,以此類推。基線是由 cuBLAS GEMM 的計算速度。非結構化稀疏加速通過 cuSPARSE 加速庫實現,稀疏矩陣以 Compressed Sparse Row(CSR)的格式儲存(可以看到非結構化稀疏要麼沒有加速要麼加速很小)。
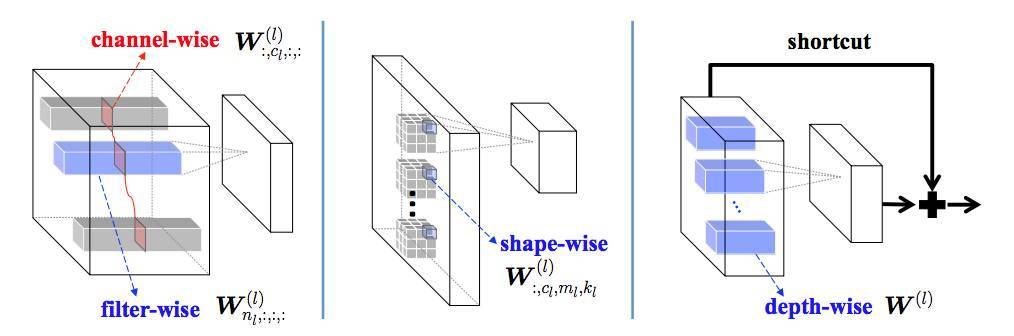
圖 2:本論文提出的 DNN 結構化稀疏學習(SSL)。想學什麼樣的結構化稀疏,取決於怎麼對權重分組。通過 Group Lasso 對每組權重正則化,我們可以由移除一些組以獲得結構化稀疏的 DNN。上圖展示了本研究中的 filter-wise、channel-wise、shape-wise 和 depth-wise 的結構化稀疏。
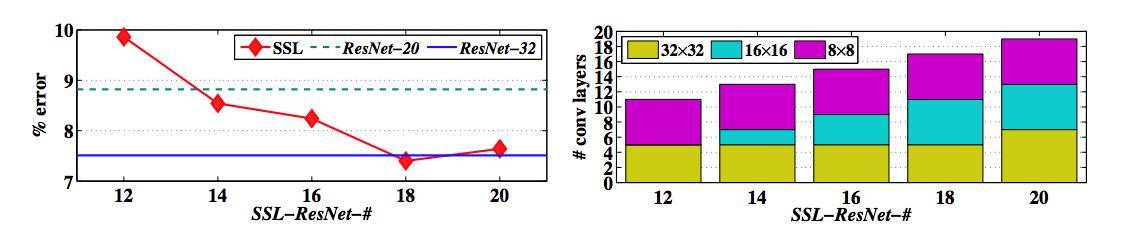
圖 6:在使用 SSL 進行層級深度正則化後的誤差 vs. 層級數量曲線圖。ResNet-# 爲 # 層的原版 ResNet[5],SSL-ResNet-# 爲經 SSL 層級深度正則化後的 # 層 ResNet。32*32 表示輸出特徵圖大小爲 32×32 的卷積層,以此類推。
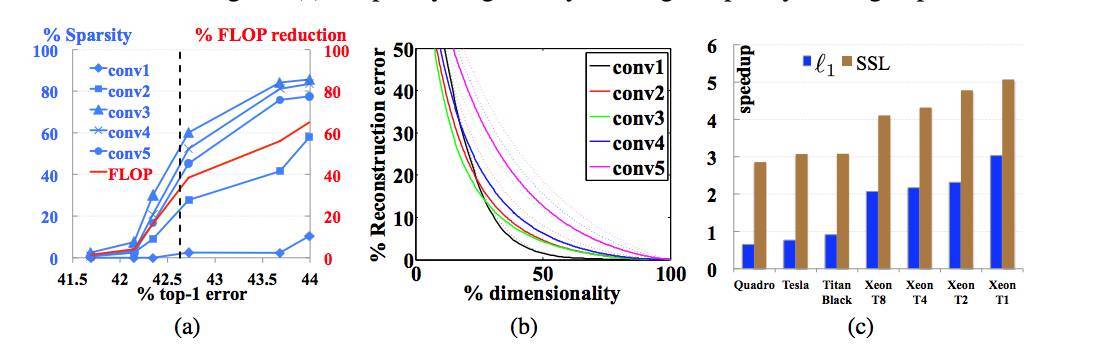
圖 7:(a)2D-filter-wise 結構化稀疏(sparsity)和 FLOP 縮減(reduction)vs. top-1 誤差的曲線圖。垂直虛線表示原版 AlexNet 的誤差。(b)權重降維重構誤差 vs. 維數的曲線圖。利用主成分分析(Principal Component Analysis,PCA)進行降維以充分削減卷積核冗餘。選擇了擁有最大特徵值的特徵向量作爲低維空間的基。虛線表示基線結果,實線表示表 4 中的 AlexNet 5 中的卷積層。(c)L1-norm 和 SSL 在不同的 CPU 和 GPU 平臺(由 x 軸上的標記表示,其中 T# 是 Xeon CPU 並採用了最大 # 個物理線程)上的加速。圖爲表 4 中 AlexNet 1 和 AlexNet 2 的比較結果。
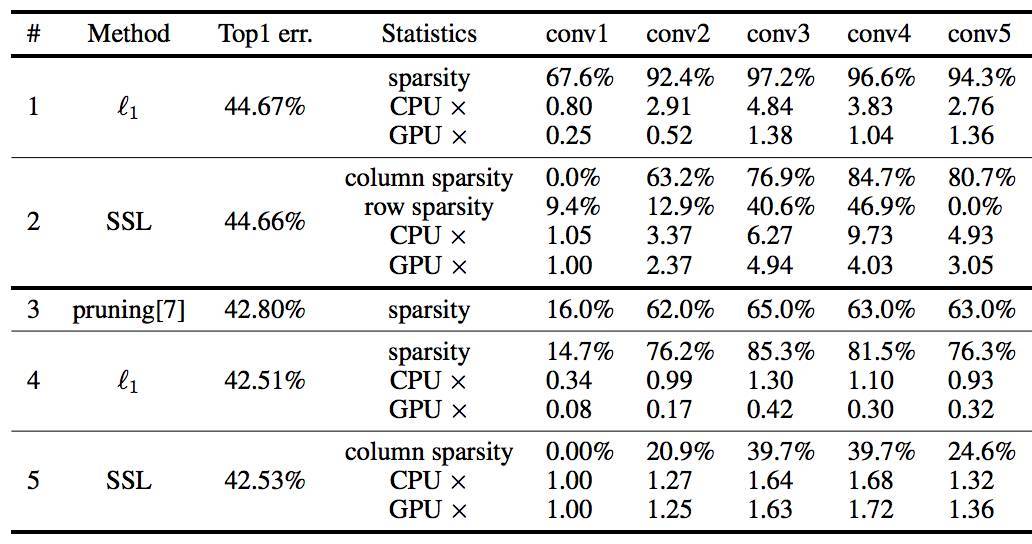
表 4:AlexNet 在 ILSVRC 2012 上的結構化稀疏和加速