本研究旨在回答「神經語言模型如何利用上下文信息」的問題。通過控制變量法,斯坦福的研究者實驗探究了神經語言模型使用的上下文信息量、近距離和遠距離的上下文的表徵差異,以及複製機制對模型使用上下文的作用這三個議題。
語言模型是諸如機器翻譯和總結等自然語言生成任務中的一個重要組成部分。這些任務會利用上下文(詞序列)信息估計待預測單詞的概率分佈。近年來,一系列神經語言模型(NLM)(Graves, 2013; Jozefowicz et al., 2016; Grave et al., 2017a; Dauphin et al., 2017; Melis et al., 2018; Yang et al., 2018)都已經取得了超過經典的 n-gram 模型的性能,這一提升往往歸功於它們在距離較遠的上下文中對長距離依賴進行建模的能力。然而,目前仍然缺乏對「這些神經語言模型如何利用上下文信息」這一問題的解釋。
最近的研究已經開始轉向解釋由長短期記憶(LSTM)網絡編碼的信息。它們可以記住句子的長度、詞性以及詞序(Adi et al., 2017),能夠捕獲一些像「主謂一致」(Linzen et al., 2016)這樣的句法結構,還可以對某些特定的諸如「否定」和「強調」(Li et al., 2016)這樣的語義組合進行建模。
然而,之前對 LSTM 的研究都停留在句子層面上,儘管這樣做確實可能對更長的上下文進行編碼。本文的目標是對前人的工作進行補充,提供一個對上下文的作用更加豐富的理解。具體而言,本研究對比句子更長的上下文文本進行編碼。本文的工作旨在回答以下 3 個問題:(1)就單詞個數而言,神經語言模型使用了多少上下文信息?(2)在這個範圍內,近距離和遠距離的上下文是否有不同的表徵?(3)複製機制如何幫助模型使用上下文的不同區域?
本文通過對標準的 LSTM 語言模型(Merity et al., 2018)進行控制變量來研究這些問題,使用兩個語言模型數據集(Penn Treebank 和 WikiText-2)作爲對比基準。給定一個預訓練好的語言模型,在測試時以多種方式擾動先驗的上下文,探究經過擾動之後的信息對於模型的性能有多大的影響。具體而言,研究者通過改變上下文的長度來學習有多少單詞被使用,通過重新排列單詞去測試 LSTM 的性能是否與局部和全局的上下文都有關係,通過刪除和替換目標單詞測試帶/不帶外部複製機制(例如,Grave 等人在 2017 年提出的神經緩存(neural cache))的 LSTM 的複製能力。這種緩存首先記錄歷史數據中出現的目標單詞和它們的上下文表徵,接着在當前的上下文表徵與該單詞存儲在緩存中的上下文向量相匹配時,會鼓勵模型複製一個過去的單詞。
通過實驗,本研究發現: LSTM 平均能夠利用大約 200 個單詞的上下文,並且在更改超參數的設置時沒有顯著的改變。在這個上下文的範圍內,詞序僅僅與 20 個最鄰近的單詞或者大約一個句子長度的單詞相關。在長距離上下文中,詞序對性能幾乎沒有影響,這表明模型保存了遠距離單詞的高層次的、有模糊語義的表徵。最後,本研究發現 LSTM 能夠重新生成鄰近的上下文中的一些單詞,但是這高度依賴於緩存幫助它們從長距離上下文中複製單詞。
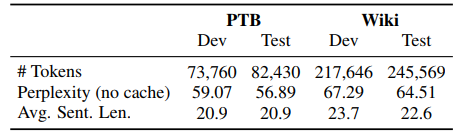 表 1:數據集的統計信息以及與本研究實驗相關的性能。
表 1:數據集的統計信息以及與本研究實驗相關的性能。
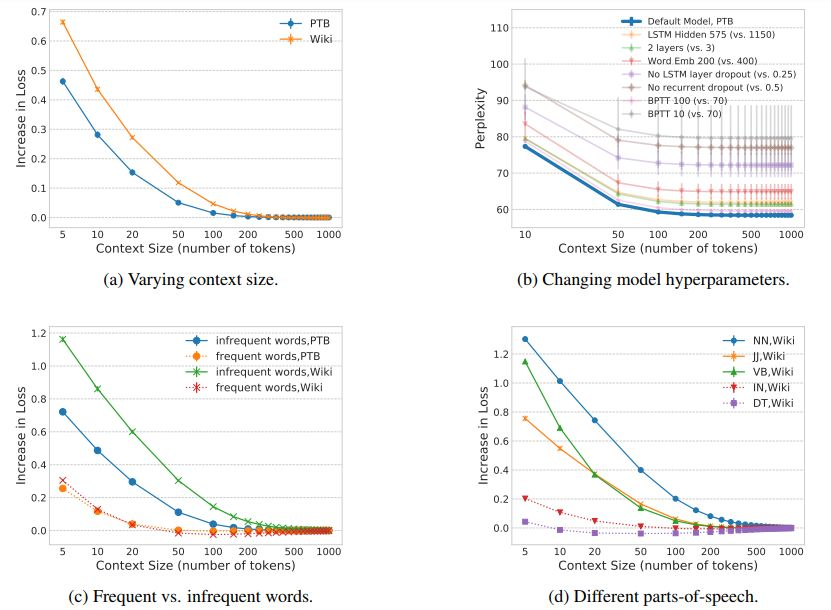 圖 1:改變上下文中包含的單詞數的影響,與在相同的模型上使用無限制的上下文進行對比。損失的增長表示由於上下文限制,損失在整個語料庫上的負對數似然的絕對增長。所有的曲線都是由三個隨機種子生成的實驗結果的平均,誤差條表示標準差。(a)模型在 PTB 數據集上的有效上下文的大小爲 150 個單詞,在 Wiki 數據集上的有效上下文的大小爲 250 個單詞。(b)改變模型的超參數不會改變模型對上下文使用的趨勢,但是確實會影響模型性能。本文展示了這種誤差,強調這種一致的使用趨勢。(c)非頻繁出現的單詞需要比頻繁出現的單詞更多的上下文。(d)實詞比功能詞需要更多的上下文。
圖 1:改變上下文中包含的單詞數的影響,與在相同的模型上使用無限制的上下文進行對比。損失的增長表示由於上下文限制,損失在整個語料庫上的負對數似然的絕對增長。所有的曲線都是由三個隨機種子生成的實驗結果的平均,誤差條表示標準差。(a)模型在 PTB 數據集上的有效上下文的大小爲 150 個單詞,在 Wiki 數據集上的有效上下文的大小爲 250 個單詞。(b)改變模型的超參數不會改變模型對上下文使用的趨勢,但是確實會影響模型性能。本文展示了這種誤差,強調這種一致的使用趨勢。(c)非頻繁出現的單詞需要比頻繁出現的單詞更多的上下文。(d)實詞比功能詞需要更多的上下文。
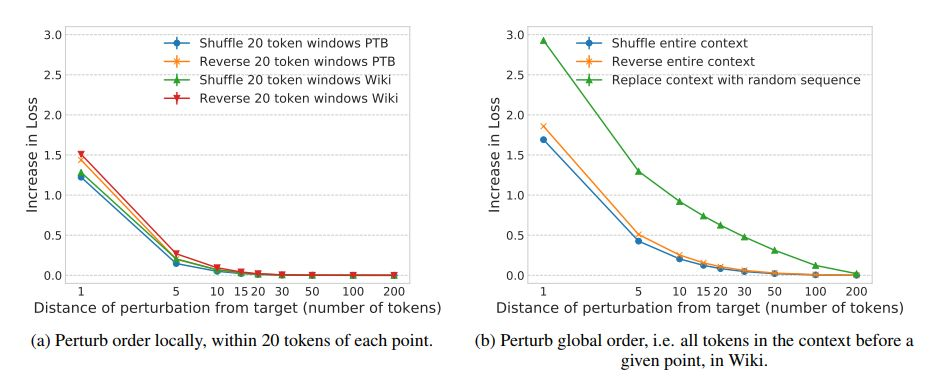 圖 2:與未擾動的基線相比,在由 300 個單詞組成的上下文中,對單詞的順序進行調整和顛倒單詞順序的影響。所有的曲線都是由三個隨機種子生成的平均值,其中誤差條表示標準差。(a)在與目標單詞相距超過 20 個單詞的上下文中,如果在一個由 20 個單詞組成的窗口中改變詞序,對損失的影響可以忽略不計。(b)在與目標單詞相距超過 50 個單詞的上下文中,改變全局的詞序對損失沒有影響。
圖 2:與未擾動的基線相比,在由 300 個單詞組成的上下文中,對單詞的順序進行調整和顛倒單詞順序的影響。所有的曲線都是由三個隨機種子生成的平均值,其中誤差條表示標準差。(a)在與目標單詞相距超過 20 個單詞的上下文中,如果在一個由 20 個單詞組成的窗口中改變詞序,對損失的影響可以忽略不計。(b)在與目標單詞相距超過 50 個單詞的上下文中,改變全局的詞序對損失沒有影響。
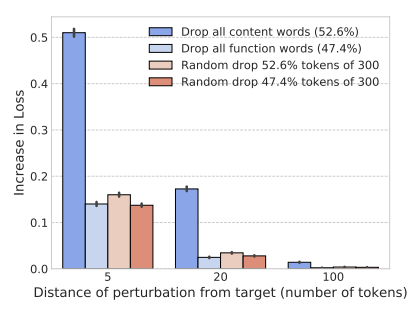 圖 3:在 PTB 數據集上,將實詞和功能詞從上下文的 300 個單詞中刪除的影響,並與基線進行對比。誤差條表示 95% 的置信區間。刪除距離目標單詞 5 個單詞的上下文中的實詞和功能詞會導致很大的損失提升,而當上下文與目標單詞距離超過 20 個單詞時,只有實詞與性能的改變有關。
圖 3:在 PTB 數據集上,將實詞和功能詞從上下文的 300 個單詞中刪除的影響,並與基線進行對比。誤差條表示 95% 的置信區間。刪除距離目標單詞 5 個單詞的上下文中的實詞和功能詞會導致很大的損失提升,而當上下文與目標單詞距離超過 20 個單詞時,只有實詞與性能的改變有關。
 圖 4:在 PTB 數據集上,對上下文中的目標詞進行擾動的影響與完全刪除長距離上下文的影響的對比。誤差條表示 95% 的置信區間。(a)只能從長距離上下文中複製的單詞對於刪除所有長距離單詞比對於刪除目標單詞更加敏感。對那些可以從鄰近的上下文中複製的單詞來說,只刪除目標單詞對於損失的影響比刪除所有的長距離上下文的影響大得多。(b)對於可以從鄰近的上下文中複製的單詞來說,使用詞彙表中的其它單詞替換目標單詞,比將其從上下文中刪除更損害模型性能。而這對於只能從遠距離上下文中複製的單詞沒有影響。
圖 4:在 PTB 數據集上,對上下文中的目標詞進行擾動的影響與完全刪除長距離上下文的影響的對比。誤差條表示 95% 的置信區間。(a)只能從長距離上下文中複製的單詞對於刪除所有長距離單詞比對於刪除目標單詞更加敏感。對那些可以從鄰近的上下文中複製的單詞來說,只刪除目標單詞對於損失的影響比刪除所有的長距離上下文的影響大得多。(b)對於可以從鄰近的上下文中複製的單詞來說,使用詞彙表中的其它單詞替換目標單詞,比將其從上下文中刪除更損害模型性能。而這對於只能從遠距離上下文中複製的單詞沒有影響。
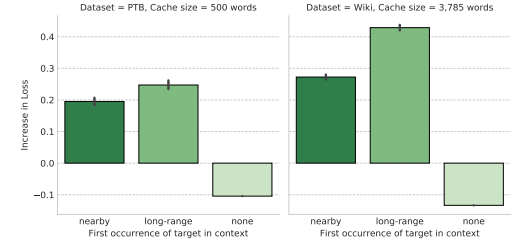 圖 7:使用神經記憶緩存的模型性能。誤差條表示 95% 的置信區間。使用緩存僅僅從長距離上下文中複製單詞對性能提升貢獻最大。
圖 7:使用神經記憶緩存的模型性能。誤差條表示 95% 的置信區間。使用緩存僅僅從長距離上下文中複製單詞對性能提升貢獻最大。
論文:Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context

論文地址:https://arxiv.org/abs/1805.04623
摘要:我們對神經語言模型(LM)如何利用先驗的語言上下文知之甚少。本文通過控制變量研究探討了上下文在 LSTM 語言模型中的作用。具體而言,本文分析了當先驗的上下文中的單詞被調序、替換或刪除時模型困惑度的增加。在兩個標準的數據集(Penn Treebank 和 WikiText-2)上,我們發現模型能夠平均利用大約 200 個單詞組成的上下文,但是能明顯地將近鄰的上下文(最近的 50 個單詞)和過去的長距離上下文區分開來。模型對最近鄰的句子中的詞序變化十分敏感,但是長距離上下文(超過 50 個單詞)的詞序變化可以忽略不計,這說明長距離上下文中過去的單詞僅僅被建模爲一個模糊的語義場或主題。我們進一步發現神經緩存模型(Grave et al., 2017b)特別地有助於 LSTM 從這種長距離上下文中複製單詞。綜上所述,本文的分析提供了一個對「語言模型如何利用它們的上下文」這一問題的更好理解,也啓發了基於緩存的模型在近期取得成功的原因解釋。