選自Medium
作者:DeviceHive
本文介紹了一種使用 TensorFlow 將音頻進行分類(包括種類、場景等)的實現方案,包括備選模型、備選數據集、數據集準備、模型訓練、結果提取等都有詳細的引導,特別是作者還介紹瞭如何實現 web 接口並集成 IoT。
簡介
有很多不同的項目和服務能夠識別人類的語音,例如 Pocketsphinx、Google』s Speech API,等等。這些應用和服務能夠以相當好的性能將人類的語音識別成文本,但是其中卻沒有一個能夠分得清麥克風捕捉到的是哪一種聲音:人聲、動物聲音或者音樂演奏聲。
我們面臨這個任務的時候,就決定去調研一下,並開發一個能夠使用機器學習算法來區分聲音的示例項目。這篇文章具體描述了我們選擇哪款工具、我們面臨的挑戰是什麼、我們如何用 TensorFlow 訓練模型,以及如何運行我們的開源項目。爲了把它們用在給第三方應用提供的雲服務上,我們還在 DeviceHive 和 IoT 平臺上提供了識別結果。
選擇工具和分類模型
首先我們需要選擇一些能夠運行神經網絡的軟件。我們發現的第一個合適的解決方案是 Python Audio Analysis。
機器學習中的主要問題是要有一個好的訓練數據集。對於音樂分類和語音識別而言,有很多數據集,但是並沒有多少數據集是用來做隨機聲音分類的。經過調查,我們發現了 urban sound dataset(https://serv.cusp.nyu.edu/projects/urbansounddataset/)這個數據集。
經過一些測試之後,我們面臨着以下問題:
pyAudioAnalysis 不夠靈活。它的參數種類參數太少,並且一些參數的計算是不受控制的,例如,訓練實驗的數量是基於樣本數量的,你不能通過 pyAudioAnalysis 改變它。
這個數據集只有 10 個種類,而且它們都是「urban」類型。
我們發現的另一個解決方案是 Google AudioSet,它是基於有標籤的 YouTube 視頻片段,可以以兩種格式下載:
每一個視頻片段都有 CSV 文件描述,包括 YouTube 視頻 ID、起始時間和結束時間、以及一個或多個標籤。
提取出的音頻特徵以 TensorFlow Record 文件的形式被存儲。
這些特徵和 YouTube-8M 模型是兼容的。這個解決方案也提供了 TensorFlow VGGish 模型作爲特徵提取器。它滿足了我們的大部分需求,因此也就成爲了我們的最佳選擇。
訓練模型
下一個任務就是了解 YouTube-8M 接口是如何運行的。它是被設計來處理視頻的,但是幸運的是它也能夠處理音頻。這個庫是相當方便的,但是它有固定的樣本類別數。所以我們對它進行了小小的修改,以將類別數作爲參數傳入。
YouTube-8M 能夠處理兩種類型的數據:總體特徵和幀特徵。Google AudioSet 能夠將我們之前提到的數據作爲特徵。通過研究之後我們發現那些特徵是以幀的格式給出的。接下來,我們需要選擇要被訓練的模型。
資源、時間和精度
GPU 比 CPU 更適合做機器學習。你可以在這裏看到更多的相關信息(https://docs.devicehive.com/blog/using-gpus-for-training-tensorflow-models)。所以我們跳過這個過程直接開始實驗設置。我們在實驗中使用的是一臺裝有 4GB 顯存的 NVIDIA GTX 970 的 PC。
在我們的案例中,訓練時間並不十分重要。只需要 1 到 2 小時就足以做出關於模型選擇和準確率的初步決定。
當然,我們想盡可能得到更好的準確率。但是,爲了訓練出一個更復雜的模型(有潛力得到更高的準確率),你需要更大的 RAM(當然對於 GPU 而言就是顯存了)。
選擇模型
這裏是具有細節描述的 YouTube-8M 模型完整列表(https://github.com/google/youtube-8m#overview-of-models)。因爲我們的訓練數據是幀格式的,所以必須使用幀級別的模型。Google AudioSet 數據集爲我們提供的數據被分成了三部分:均衡的訓練集、不均衡的訓練集以及評估集。
還有一個修正版的用於訓練和評估的 YouTube-8M 模型。可以在這裏獲得:(https://github.com/igor-panteleev/youtube-8m)
均衡的訓練集
訓練命令如下:
python train.py –train_data_pattern=/path_to_data/audioset_v1_embeddings/bal_train/*.tfrecord –num_epochs=100–learning_rate_decay_examples=400000–feature_names=audio_embedding –feature_sizes=128–frame_features –batch_size=512–num_classes=527–train_dir=/path_to_logs –model=ModelName
按照文檔的建議,我們將 LSTM 模型的基礎學習率改爲 0.001。此外,我們還將 LSTM 單元的默認大小改爲 256,因爲我們沒有足夠大的 RAM。
現在我們看一下訓練結果:
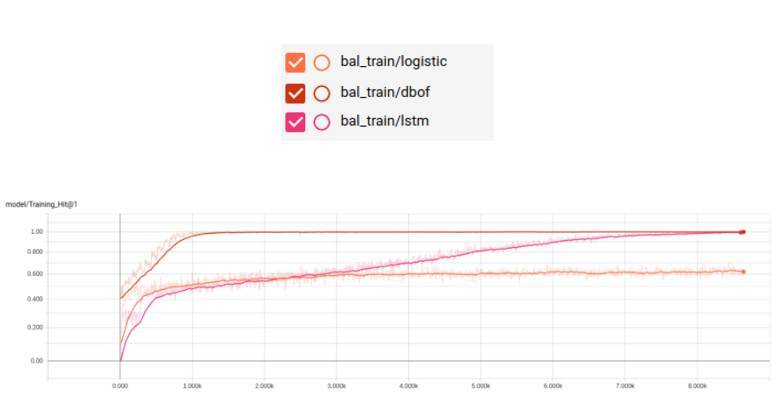
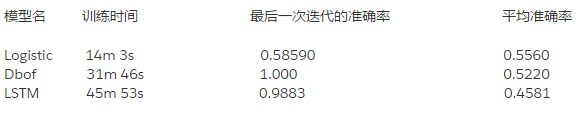
如上所示,我們在訓練階段得到了較好的結果,但是並不意味着在測試的時候也能得到同樣好的結果。
不均衡訓練
讓我們來試試不均衡的數據集吧。它有更多的樣本,所以我們將 epochs 的數目改爲 10(最小應該改成 5,因爲訓練會耗費很多的時間)。
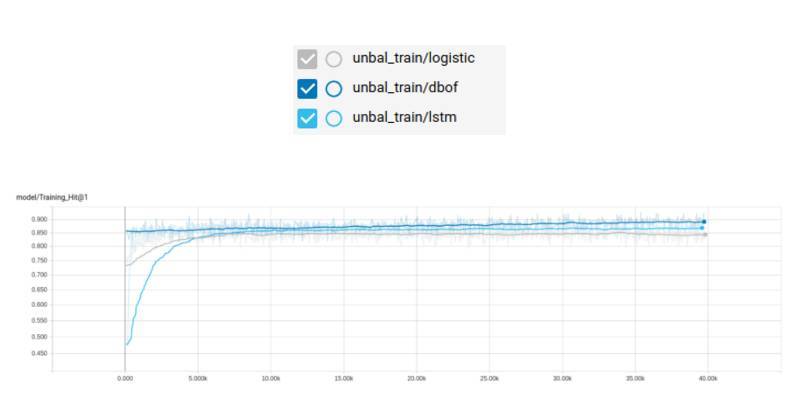
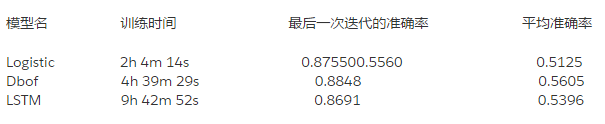
訓練日誌
如果你想覈查我們的訓練日誌,可以在這裏下載 (https://s3.amazonaws.com/audioanalysis/train_logs.tar.gz),然後運行:
tensorboard –logdir /path_to_train_logs/
然後在瀏覽器中打開主機 6006 端口就可以看到了。
關於訓練的更多內容
YouTube-8M 採用了很多參數,大部分都會影響訓練過程。例如:你可以調節學習率或者 epochs 的數量,這兩個參數能夠很明顯的改變訓練過程。還有 3 個用來計算損失的函數,以及很多其他有用的變量,你可以改變它們來提升結果。
現在我們已經有了一些訓練好的模型,是時候添加一些代碼與它們交互了。我們需要從麥克風採集音頻。這裏我們使用 PyAudio,它提供了可以在很多平臺上運行的簡單接口。
音頻準備
正如我們之前所提及的,我們要使用 TensorFlow 的 VGGish 模型作爲特徵提取器。這裏是轉換過程的一個簡短解釋:
用 UrbanSound 數據集中「犬吠」聲音樣例來作爲可視化的例子。
將音頻重採樣爲 16kHz 單聲道。
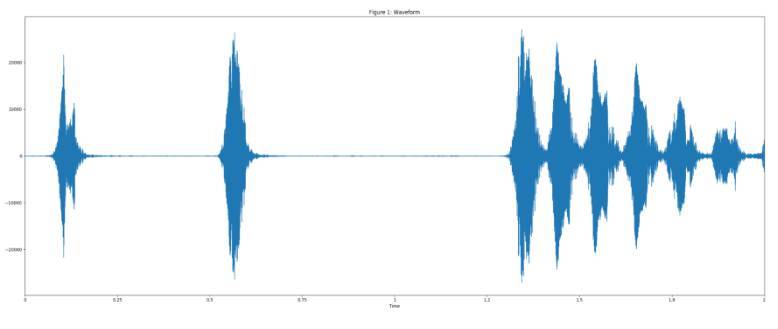
使用 25ms 的幀長、10ms 的幀移,以及週期性的 Hann 窗口對語音進行分幀,對每一幀做短時傅里葉變換,然後利用信號幅值計算聲譜圖。
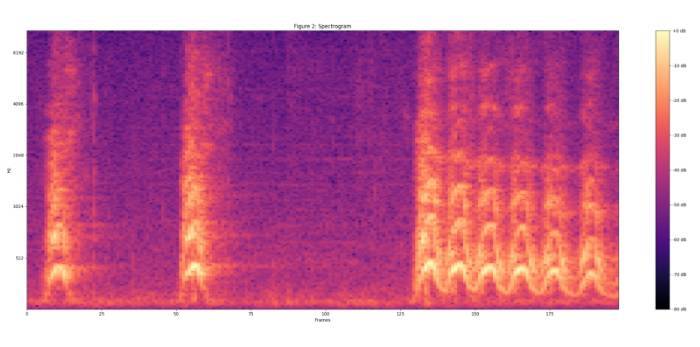
通過將聲譜映射到 64 階 mel 濾波器組中計算 mel 聲譜。
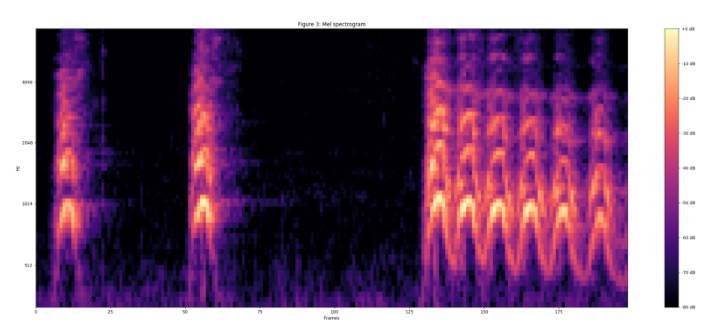
計算 log(mel-spectrum + 0.01),得到穩定的 mel 聲譜,所加的 0.01 的偏置是爲了避免對 0 取對數。
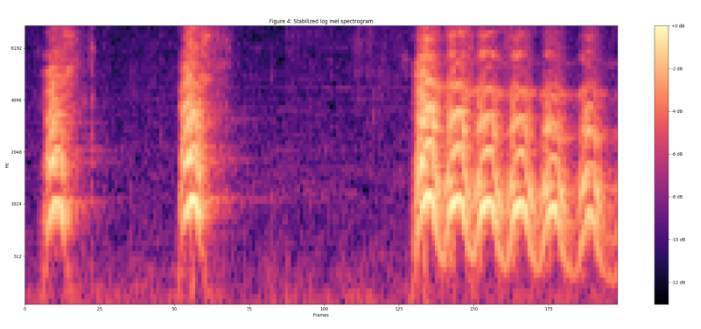
然後這些特徵被以 0.96s(這段「犬吠」聲的總時長)的時長被組幀,並且沒有幀的重疊,每一幀都包含 64 個 mel 頻帶,時長 10ms(即總共 96 幀)。
然後這些樣本被輸入到 VGGish 模型中以提取特徵向量。
分類
最後我們需要一個能夠把數據輸入到神經網絡的接口,以得到分類結果。
我們使用 YouTube-8M 作爲一個例子,但是會做一些修改,去掉序列化/反序列化(serialization/deserialization)步驟。
可以在這裏看到我們的結果(https://github.com/devicehive/devicehive-audio-analysis)。
安裝
PyAudio 使用 libportaudio2 和 portaudio19-dev,所以在安裝 PyAudio 之前需要先安裝這兩個工具。
還需要一些 python 庫,你可以使用 pip 來安裝它們。
pip install -r requirements.txt
你還需要下載並提取具有保存好的模型的項目主目錄,可以在這裏找到(https://s3.amazonaws.com/audioanalysis/models.tar.gz)。
運行
我們的項目提供了 3 個可供使用的接口。
1. 處理錄製好的音頻文件
只需要運行下面的命令就可以:
python parse_file.py path_to_your_file.wav
然後你就會在終端中看到以下信息:語音:0.75;音樂:0.12;在大廳裏面:0.03。
這個結果由輸入的文件決定。這些值是神經網絡做出的預測。數值越大,則說明輸入文件中的音頻屬於該類別的概率比較大。
2. 從麥克風中捕捉並處理數據
運行 python capture.py 開始從麥克風中無限制地採集數據。默認配置下,它會每 5-7s 將數據輸入到神經網絡。可以在其中看到之前例子的結果。
在這個案例中,你可以使用–save_path=/path_to_samples_dir/運行上面的命令,然後所有采集到的數據都會以 wav 文件的格式存儲在你提供的路徑中。當你想用同樣的樣本嘗試不同的模型時,這個函數是很有用的。可以使用-help 來獲取更多的信息。
3.web 接口
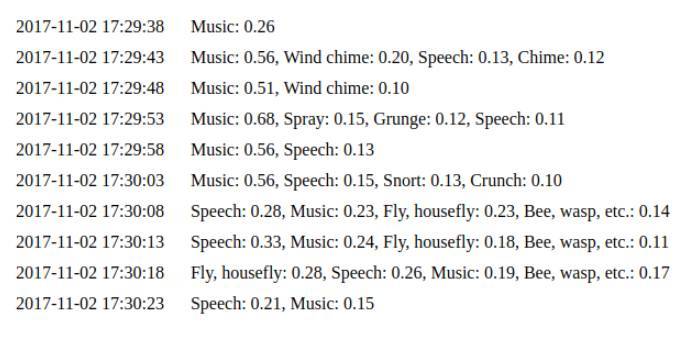
python daemon.py 實現了一個簡單的 web 接口,默認配置下在本地的 8000 端口(http://127.0.0.1:8000/)。然後我們使用之前例子中提到的同樣的代碼。你可以看到對聲音時間的最後 10 次預測(http://127.0.0.1:8000/events):
IoT 服務集成
最後但是也是比較重要的一個:集成在 IoT 基礎設施中。如果你運行了我們前面提到的 web 接口,你可以在索引頁面上看到 DeviceHive 客戶狀態和配置。只要客戶端已經連接成功了,預測結果會以通知的形式發送到特定的設備上。

結論
正如你所看到的,TensorFlow 是一款非常靈活的工具,在很多機器學習應用中都很有用,例如圖像處理和語音識別。將這個方法和物聯網平臺結合起來可以讓你在很多領域建立智能解決方案。
智慧城市可以將這個解決方案用於安全目的,可以持續地監聽玻璃破碎聲、槍聲以及其他與犯罪相關的聲音。甚至在雨林中,可以用這個方法通過分析它們的聲音來跟蹤動物和鳥類。
物聯網設備可以收到所有這類通知。這個解決方案可以安裝在本地設備上以最小化通信和雲成本(儘管也可以部署在雲端作爲一種雲服務),並且可被定製成只接收除包含原始音頻之外的信息。別忘了,這是一個開源的項目,隨意使用吧。
原文地址:https://medium.com/iotforall/sound-classification-with-tensorflow-8209bdb03dfb