雷鋒網按:本文由圖普科技編譯自《Summary of Unintuitive Properties of Neural Networks》,雷鋒網(公衆號:雷鋒網)獨家首發。
神經網絡對解決很多問題都十分有效,包括語言識別、語音識別和圖像識別等。然而要理解神經網絡是如何解決這些問題卻有一定的難度。本文將對神經網絡的特殊和「非直觀屬性」進行總結整理。
神經網絡是強大的學習模型,特別是用於解決視覺識別和語音識別問題的深度學習網絡。之所以這麼說,是因爲它們具有表達任意計算的能力。但是我們現在仍然很難完全理解神經網絡的屬性,因此,我們不知道它們是如何在一個動態的環境下作出一個又一個決策的。受到Hugo Larochelle的啓發,我們在本文總結了神經網絡的「非直觀」屬性。
這是一個「黑箱子」問題
網絡的決策過程非常複雜,而且涉及到了許多的層,因此我們很難搞清楚其中的思路。爲了一步步弄清神經網絡是如何進行訓練的,我們做出了很大的努力(比如,一個研究人員開發了一個「深度可視化工具包」)。儘管如此,這些層的內部對我們來說還是相當的複雜。
深度可視化工具包的截圖
它們也會犯一些低級錯誤
一個由「谷歌研究所」和紐約大學的研究人員組成的團隊最近發現,一些具有對抗性的示例似乎會與網絡的高度泛化性(也稱「概括性」)產生矛盾。我們現在急需弄清網絡是否能夠很好地進行泛化,以及它是如何被這些對抗性例子所迷惑的。

神經網絡的對抗性示例
很奇怪,他們是非凸函數
在對神經網絡進行優化時,損失函數可以有一些局部最大值和最小值,這就表示它一般既不是凸面也不是凹面。針對這個問題,一個研究小組提出了一種方法,這種方法能夠識別和解決高維度非凸優化的鞍點問題。然而,谷歌和斯坦福大學的附屬研究小組引入了一個簡單的方案來尋找神經網絡正克服局部優化難題的證據。他們發現,從初始化到最終的解決方案,各種各樣的現代神經網絡從未遇到過任何大的障礙。他們的實驗是爲了回答這些問題的:神經網絡會進入和避開一些列局部最小值嗎?在靠近和通過各種鞍點時,神經網絡會以不同的速度移動嗎?他們所找到的證據有力地證明了答案是否定的。
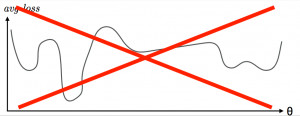
神經網絡的損失函數是非凸函數
他們在訓練不佳時的工作表現最佳
一個「平底最小值」相當於低期望的過度擬合,它是承重空間內的一個大型連接區域,在此區域內的失誤都會大致保持不變。在適用於股票市場預測的應用程序中,帶有平底最小值搜索算法的網絡表現要勝於傳統的反向傳播和重量衰減。然而,最近一篇關於深度學習大批量培訓的報告發現,使用較大批量進行培訓通常會找到較精確的最小值,並且泛化或概括表現比較差。換句話來說,如果我們將訓練算法考慮在內,那麼泛化就會完成得更出色。
它們可以輕鬆地記住一些事情,也能輕易地被壓縮
在2017年ICLR的一項研究中,一個簡單的實驗性框架被用於定義學習模型的高效率能力。這項工作暗示了幾個先進的神經網絡架構的高效率能力,足以對訓練數據造成破壞,因此,這個模型有足夠的能力記住這些訓練數據。對於一個被Android語音搜索所使用的深度原聲模型,一個谷歌研究團隊表示,幾乎所有通過深度神經網絡訓練得到的改進都能被濃縮至一個相同大小的神經網絡,這樣一來,我們就比較容易部署這些網絡了。
它們會受到初始化的影響
在視覺和語言數據集上,「深度信念網絡」包含了普通的有監督學習模式之前的一個非監督學習階段(預訓練的組成部分)。一個關於預訓練的實驗,從模型能力、訓練示例數量和網絡架構深度等方面對預訓練進行了實證分析。
它們會忘記曾經學過什麼
如果學習能夠以一種循序漸進的方式進行,那麼這將是非常重要和有意義的。然而,目前來說,神經網絡還沒有能力達到這一種循序漸進的屬性。它們一般只會在一次性得到所有數據的情況下,完成多個任務的學習。在學習完一項任務之後,它們所獲得的知識將會被改寫,以適應一項新的培訓任務。在「認知科學」中,這被稱爲「災難性遺忘」,這也是神經網絡衆所周知的一個短板。
以上這些都是神經網絡「非直觀屬性」的典型例子。如果我們拿到了結果,但完全不理解爲何模型會作出這樣的決策,那麼我們就很難在科學研究中取得進步,特別是在模型正變得越來越龐大和複雜的情況下,弄清楚模型工作原理和思路是非常必要且緊迫的。