雷鋒網按:本文作者魏秀參,謝晨偉南京大學計算機系機器學習與數據挖掘所(LAMDA),研究方向爲計算機視覺和機器學習。
說起特斯拉,大家可能立馬會想到今年 5 月份發生在特斯拉 Model S 自動駕駛上的一宗奪命車禍。初步的調查表明,在強烈的日照條件下,駕駛員和自動駕駛系統都未能注意到牽引式掛車的白色車身,因此未能及時啓動剎車系統。而由於牽引式掛車正在橫穿公路,且車身較高,這一特殊情況導致 Model S 從掛車底部通過時,其前擋風玻璃與掛車底部發生撞擊,導致駕駛員不幸遇難。
無獨有偶,8 月 8 日美國密蘇里州的一名男子、特斯拉 Model X 車主約書亞•尼利(Joshua Neally)在上班途中突發肺栓塞。在 Model X 的 Autopilot 自動駕駛功能的幫助下,他安全抵達了醫院。這「一抑一揚」着實讓人回味無窮,略有些「敗也蕭何,成也蕭何」之意。

好奇的讀者一定會有疑問:這「一成一敗」背後的原理到底是什麼?是自動駕駛系統中的哪個部分發生了失誤而造成車禍?又是哪部分技術支撐了自動駕駛過程呢?
今天,我們就來談談自動駕駛系統中的一項重要核心技術——圖像語義分割(semantic image segmentation)。圖像語義分割作爲計算機視覺(computer vision)中圖像理解(image understanding)的重要一環,不僅在工業界的需求日益凸顯,同時語義分割也是當下學術界的研究熱點之一。
什麼是圖像語義分割?
圖像語義分割可以說是圖像理解的基石性技術,在自動駕駛系統(具體爲街景識別與理解)、無人機應用(着陸點判斷)以及穿戴式設備應用中舉足輕重。
我們都知道,圖像是由許多像素(pixel)組成,而「語義分割」顧名思義就是將像素按照圖像中表達語義含義的不同進行分組(grouping)/分割(segmentation)。下圖取自圖像分割領域的標準數據集之一 PASCAL VOC。其中,左圖爲原始圖像,右圖爲分割任務的真實標記(ground truth):紅色區域表示語義爲「person」的圖像像素區域,藍綠色代表「motorbike」語義區域,黑色表示「background」,白色(邊)則表示未標記區域。
顯然,在圖像語義分割任務中,其輸入爲一張 H×W×3 的三通道彩色圖像,輸出則是對應的一個 H × W 矩陣,矩陣的每一個元素表明了原圖中對應位置像素所表示的語義類別(semantic label)。因此,圖像語義分割也稱爲「圖像語義標註」(image semantic labeling)、「像素語義標註」(semantic pixel labeling)或「像素語義分組」(semantic pixel grouping)。

從上圖和題圖中,大家可以明顯看出圖像語義分割任務的難點便在於這「語義」二字。在真實圖像中,表達某一語義的同一物體常由不同部件組成(如,building,motorbike,person 等),同時這些部分往往有着不同的顏色、紋理甚至亮度(如building),這給圖像語義的精確分割帶來了困難和挑戰。
前 DL 時代的語義分割
從最簡單的像素級別「閾值法」(thresholding methods)、基於像素聚類的分割方法(clustering-based segmentation methods)到「圖劃分」的分割方法(graph partitioning segmentation methods),在深度學習(deep learning, DL)「一統江湖」之前,圖像語義分割方面的工作可謂「百花齊放」。在此,我們僅以「normalized cut」[1]和「grab cut」 [2]這兩個基於圖劃分的經典分割方法爲例,介紹一下前 DL 時代語義分割方面的研究。
Normalized cut (N-cut)方法是基於圖劃分(graph partitioning)的語義分割方法中最著名的方法之一,於 2000 年 Jianbo Shi 和 Jitendra Malik 發表於相關領域頂級期刊 TPAMI。通常,傳統基於圖劃分的語義分割方法都是將圖像抽象爲圖(graph)的形式 G=(V,E) (V 爲圖節點,E 爲圖的邊),然後藉助圖理論(graph theory)中的理論和算法進行圖像的語義分割。
常用的方法爲經典的最小割算法(min-cut algorithm)。不過,在邊的權重計算時,經典 min-cut 算法只考慮了局部信息。如下圖所示,以二分圖爲例(將 G 分爲不相交的 , 兩部分),若只考慮局部信息,那麼分離出一個點顯然是一個 min-cut,因此圖劃分的結果便是類似 或 這樣離羣點,而從全局來看,實際想分成的組卻是左右兩大部分。
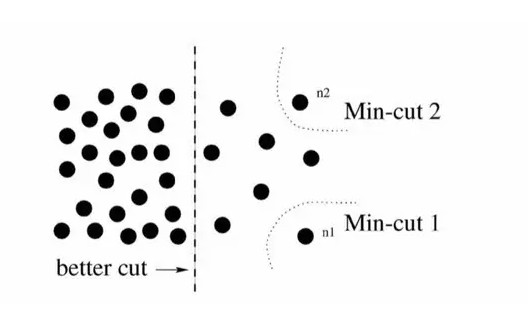
針對這一情形,N-cut 則提出了一種考慮全局信息的方法來進行圖劃分(graph partitioning),即,將兩個分割部分 A,B , 與全圖節點的連接權重(assoc(A,V) 和 assoc(B,V))考慮進去:
如此一來,在離羣點劃分中,中的某一項會接近 1,而這樣的圖劃分顯然不能使得是一個較小的值,故達到考慮全局信息而摒棄劃分離羣點的目的。這樣的操作類似於機器學習中特徵的規範化(normalization)操作,故稱爲normalized cut。N-cut不僅可以處理二類語義分割,而且將二分圖擴展爲 K 路( -way)圖劃分即可完成多語義的圖像語義分割,如下圖例。

Grab cut 是微軟劍橋研究院於 2004 年提出的著名交互式圖像語義分割方法。與 N-cut 一樣,grab cut 同樣也是基於圖劃分,不過 grab cut 是其改進版本,可以看作迭代式的語義分割算法。Grab cut 利用了圖像中的紋理(顏色)信息和邊界(反差)信息,只要少量的用戶交互操作即可得到比較好的前後背景分割結果。
在 grab cut 中,RGB 圖像的前景和背景分別用一個高斯混合模型(gaussian mixture model, GMM)來建模。兩個 GMM 分別用以刻畫某像素屬於前景或背景的概率,每個 GMM 高斯部件(gaussian component)個數一般設爲 。
接下來,利用吉布斯能量方程(gibbs energy function)對整張圖像進行全局刻畫,而後迭代求取使得能量方程達到最優值的參數作爲兩個 GMM 的最優參數。GMM 確定後,某像素屬於前景或背景的概率就隨之確定下來。
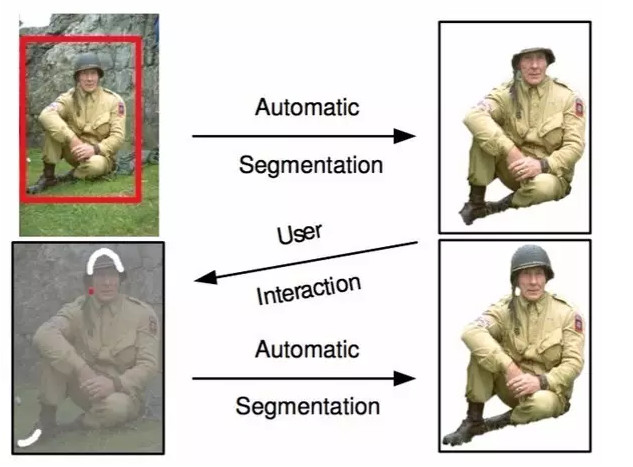
在與用戶交互的過程中,grab cut 提供兩種交互方式:一種以包圍框(bounding box)爲輔助信息;另一種以塗寫的線條(scribbled line)作爲輔助信息。以下圖爲例,用戶在開始時提供一個包圍框,grab cut 默認的認爲框中像素中包含主要物體/前景,此後經過迭代圖劃分求解,即可返回扣出的前景結果,可以發現即使是對於背景稍微複雜一些的圖像,grab cut 仍有不俗表現。

不過,在處理下圖時,grab cut 的分割效果則不能令人滿意。此時,需要額外人爲的提供更強的輔助信息:用紅色線條/點標明背景區域,同時用白色線條標明前景區域。在此基礎上,再次運行 grab cut 算法求取最優解即可得到較爲滿意的語義分割結果。grab cut 雖效果優良,但缺點也非常明顯,一是僅能處理二類語義分割問題,二是需要人爲干預而不能做到完全自動化。
DL 時代的語義分割
其實大家不難看出,前 DL 時代的語義分割工作多是根據圖像像素自身的低階視覺信息(low-level visual cues)來進行圖像分割。由於這樣的方法沒有算法訓練階段,因此往往計算複雜度不高,但是在較困難的分割任務上(如果不提供人爲的輔助信息),其分割效果並不能令人滿意。
在計算機視覺步入深度學習時代之後,語義分割同樣也進入了全新的發展階段,以全卷積神經網絡(fully convolutional networks,FCN)爲代表的一系列基於卷積神經網絡「訓練」的語義分割方法相繼提出,屢屢刷新圖像語義分割精度。下面就介紹三種在 DL時代語義分割領域的代表性做法。
全卷積神經網絡 [3]
全卷積神經網絡 FCN 可以說是深度學習在圖像語義分割任務上的開創性工作,出自 UC Berkeley 的 Trevor Darrell 組,發表於計算機視覺領域頂級會議 CVPR 2015,並榮獲best paper honorable mention。
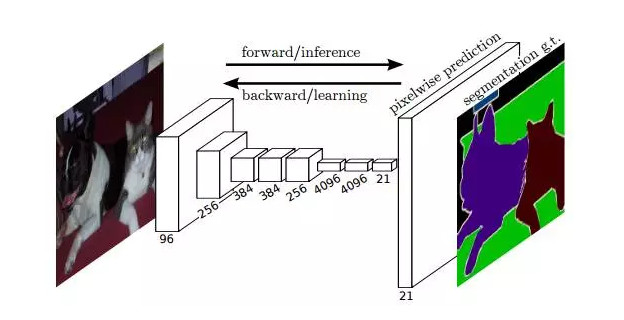
FCN 的思想很直觀,即直接進行像素級別端到端(end-to-end)的語義分割,它可以基於主流的深度卷積神經網絡模型(CNN)來實現。正所謂「全卷積神經網絡」,在FCN中,傳統的全連接層 fc6 和 fc7 均是由卷積層實現,而最後的 fc8 層則被替代爲一個 21 通道(channel)的 1x1 卷積層,作爲網絡的最終輸出。之所以有 21 個通道是因爲 PASCAL VOC 的數據中包含 21 個類別(20個object類別和一個「background」類別)。
下圖爲 FCN 的網絡結構,若原圖爲 H×W×3,在經過若干堆疊的卷積和池化層操作後可以得到原圖對應的響應張量(activation tensor) ,其中, 爲第i層的通道數。可以發現,由於池化層的下采樣作用,使得響應張量的長和寬遠小於原圖的長和寬,這便給像素級別的直接訓練帶來問題。
爲了解決下采樣帶來的問題,FCN 利用雙線性插值將響應張亮的長寬上採樣到原圖大小,另外爲了更好的預測圖像中的細節部分,FCN 還將網絡中淺層的響應也考慮進來。具體來說,就是將 Pool4 和 Pool3 的響應也拿來,分別作爲模型 FCN-16s 和 FCN-8s 的輸出,與原來 FCN-32s 的輸出結合在一起做最終的語義分割預測(如下圖所示)。
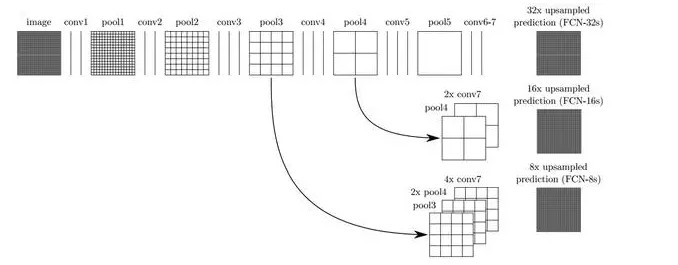
下圖是不同層作爲輸出的語義分割結果,可以明顯看出,由於池化層的下采樣倍數的不同導致不同的語義分割精細程度。如 FCN-32s,由於是 FCN 的最後一層卷積和池化的輸出,該模型的下采樣倍數最高,其對應的語義分割結果最爲粗略;而 FCN-8s 則因下采樣倍數較小可以取得較爲精細的分割結果。

Dilated Convolutions [4]
FCN 的一個不足之處在於,由於池化層的存在,響應張量的大小(長和寬)越來越小,但是FCN的設計初衷則需要和輸入大小一致的輸出,因此 FCN 做了上採樣。但是上採樣並不能將丟失的信息全部無損地找回來。
對此,dilated convolution 是一種很好的解決方案——既然池化的下采樣操作會帶來信息損失,那麼就把池化層去掉。但是池化層去掉隨之帶來的是網絡各層的感受野(receptive field)變小,這樣會降低整個模型的預測精度。Dilated convolution 的主要貢獻就是,如何在去掉池化下采樣操作的同時,而不降低網絡的感受野。
以 3×3 的卷積核爲例,傳統卷積核在做卷積操作時,是將卷積核與輸入張量中「連續」的 3×3 的 patch 逐點相乘再求和(如下圖a,紅色圓點爲卷積覈對應的輸入「像素」,綠色爲其在原輸入中的感知野)。而 dilated convolution 中的卷積核則是將輸入張量的 3×3 patch 隔一定的像素進行卷積運算。
如下圖 b 所示,在去掉一層池化層後,需要在去掉的池化層後將傳統卷積層換做一個「dilation=2」的 dilated convolution 層,此時卷積核將輸入張量每隔一個「像素」的位置作爲輸入 patch 進行卷積計算,可以發現這時對應到原輸入的感知野已經擴大(dilate)爲 ;同理,如果再去掉一個池化層,就要將其之後的卷積層換成「dilation=4」的 dilated convolution 層,如圖 c 所示。這樣一來,即使去掉池化層也能保證網絡的感受野,從而確保圖像語義分割的精度。
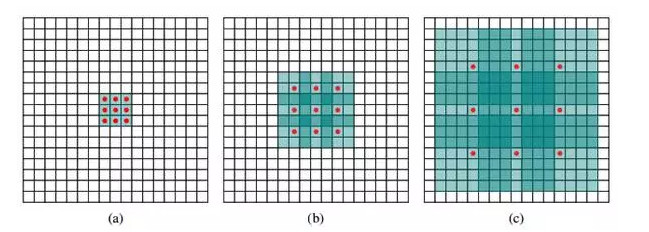
從下面的幾個圖像語義分割效果圖可以看出,在使用了 dilated convolution 這一技術後可以大幅提高語義類別的辨識度以及分割細節的精細度。

以條件隨機場爲代表的後處理操作
當下許多以深度學習爲框架的圖像語義分割工作都是用了條件隨機場(conditional random field,CRF)作爲最後的後處理操作來對語義預測結果進行優化。
一般來講,CRF 將圖像中每個像素點所屬的類別都看作一個變量 ,然後考慮任意兩個變量之間的關係,建立一個完全圖(如下圖所示)。
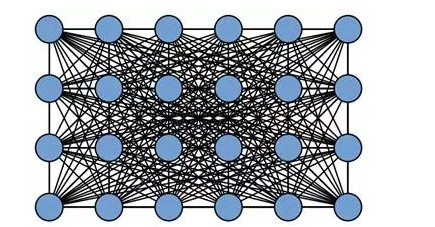
在全鏈接的 CRF 模型中,對應的能量函數爲:
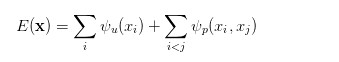
其中是一元項,表示像素對應的語義類別,其類別可以由 FCN 或者其他語義分割模型的預測結果得到;而第二項爲二元項,二元項可將像素之間的語義聯繫/關係考慮進去。例如,「天空」和「鳥」這樣的像素在物理空間是相鄰的概率,應該要比「天空」和「魚」這樣像素的相鄰概率大。最後通過對 CRF 能量函數的優化求解,得到對 FCN 的圖像語義預測結果進行優化,得到最終的語義分割結果。
值得一提的是,已經有工作[5]將原本與深度模型訓練割裂開的 CRF 過程嵌入到神經網絡內部,即,將 FCN+CRF 的過程整合到一個端到端的系統中,這樣做的好處是 CRF 最後預測結果的能量函數可以直接用來指導 FCN 模型參數的訓練,而取得更好的圖像語義分割結果。

展望
俗話說,「沒有免費的午餐」(no free lunch)。基於深度學習的圖像語義分割技術雖然可以取得相比傳統方法突飛猛進的分割效果,但是其對數據標註的要求過高:不僅需要海量圖像數據,同時這些圖像還需提供精確到像素級別的標記信息(semantic labels)。因此,越來越多的研究者開始將注意力轉移到弱監督(weakly-supervised)條件下的圖像語義分割問題上。在這類問題中,圖像僅需提供圖像級別標註(如,有「人」,有「車」,無「電視」)而不需要昂貴的像素級別信息即可取得與現有方法可比的語義分割精度。
另外,示例級別(instance level)的圖像語義分割問題也同樣熱門。該類問題不僅需要對不同語義物體進行圖像分割,同時還要求對同一語義的不同個體進行分割(例如需要對圖中出現的九把椅子的像素用不同顏色分別標示出來)。
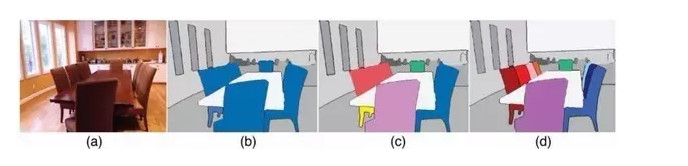
最後,基於視頻的前景/物體分割(video segmentation)也是今後計算機視覺語義分割領域的新熱點之一,這一設定其實更加貼合自動駕駛系統的真實應用環境。
References:
[1] Jianbo Shi and Jitendra Malik. Normalized Cuts and Image Segmentation, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22, No. 8, 2000.
[2] Carsten Rother, Vladimir Kolmogorov and Andrew Blake. "GrabCut"--Interactive Foreground Extraction using Iterated Graph Cuts, ACM Transactions on Graphics, 2004.
[3] Jonathan Long, Evan Shelhamer and Trevor Darrell. Fully Convolutional Networks for Semantic Segmentation. IEEE Conference on Computer Vision and Pattern Recognition, 2015.
[4] Fisher Yu and Vladlen Koltun. Multi-scale Context Aggregation by Dilated Convolutions. International Conference on Representation Learning, 2016.
[5] Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang and Philip H. S. Torr. Conditional Random Fields as Recurrent Neural Networks. International Conference on Computer Vision, 2015.
雷鋒網注:本文首發機器之心,由作者授權雷鋒網(公衆號:雷鋒網)發佈。轉載請聯繫作者,並註明出處不得刪減內容。
