選自arXiv
爲應對新型 AI 應用不斷提高的性能需求,近日 Michael Jordan 等人提出了一個新型的分佈式框架 Ray,主要針對當前集羣計算框架無法滿足高吞吐量和低延遲需求的問題,以及很多模擬框架侷限於靜態計算圖的缺點,並指出強化學習範式可以自然地結合該框架。
人工智能在一些現實世界應用中正逐漸發展爲主力技術。然而,到目前爲止,這些應用大部分都是基於相當受限的監督學習範式,其中模型是離線學習的,然後提供在線預測。隨着人工智能領域的成熟,使用比標準的監督學習設置更寬泛的設置成爲必需。和僅僅做出並提供單個預測不同,機器學習應用必須越來越多地在動態環境中運行,對環境變化做出反應,執行一系列動作以達到目標。這些更加寬泛的需求實際上可以自然地在強化學習(RL)的範式內構造,強化學習可以在不確定的環境中持續學習。一些基於 RL 的應用已經達到了引人注目的結果,例如谷歌的 AlphaGo 打敗圍棋人類世界冠軍,這些應用也正在探索自動駕駛汽車、UAV 和自動化操作領域。
把 RL 應用和傳統的監督學習應用區分開來的特徵有三個。首先,RL 通常高度依賴模擬來探索狀態、發現動作的後果。模擬器可以編碼計算機遊戲的規則、物理系統的牛頓動力學(如機器人),或虛擬環境的混合動力學。這通常需要消耗大量的算力,例如構建一個現實的應用可能需要經過幾億次模擬。其次,RL 應用的計算圖是異質、動態演化的。一次模擬可能需要幾毫秒到幾分鐘不等,並且模擬的結果還會影響未來模擬中使用的參數。最後,很多 RL 應用,如機器人控制或自動駕駛,需要快速採取行動以應對不斷變化的環境。此外,爲了選擇最優動作,這些應用需要實時地執行更多的模擬。總之,我們需要一個支持異質和動態計算圖的計算框架,同時可以在毫秒延遲下每秒執行百萬量級的任務。
已有的集羣計算框架並不能充分地滿足這些需求。MapReduce [18]、Apache Spark [50]、Dryad [25]、Dask [38] 和 CIEL [32] 不支持通用 RL 應用的高吞吐量和低延遲需求,而 TensorFlow [5]、Naiad [31]、MPI [21] 和 Canary [37] 通常假定計算圖是靜態的。
這篇論文做出瞭如下貢獻:
指出了新興 AI 應用的系統需求:支持(a)異質、並行計算,(b)動態任務圖,(c)高吞吐量和低延遲的調度,以及(d)透明的容錯性。
除了任務並行的編程抽象之外,還提供了 actor 抽象(基於動態任務圖計算模型)。
提出了一個可水平伸縮的架構以滿足以上需求,並建立了實現該架構的集羣計算系統 Ray。
論文:Ray: A Distributed Framework for Emerging AI Applications

論文地址:https://arxiv.org/abs/1712.05889
下一代的 AI 應用將具備持續和環境進行交互以及在交互中學習的能力。這些應用對系統有新的高要求(無論是性能還是靈活性)。在這篇論文中,我們考慮了這些需求並提出了 Ray,一個滿足上述需求的分佈式系統。Ray 實現了一個動態任務圖計算模型(dynamic task graph computation model),該模型支持任務並行化和 actor 編程模型。爲了滿足 AI 應用的性能需求,我們提出了一個架構,該架構使用共享存儲系統(sharded storage system)和新型自下而上的分佈式調度程序實現系統控制狀態的邏輯集中。我們的實驗展示了亞毫秒級的遠程任務延遲,以及每秒可擴展至超過 180 萬任務的線性吞吐量。實驗證明 Ray 可以加速難度高的基準測試,而且是新興強化學習應用和算法的自然、高效選擇。
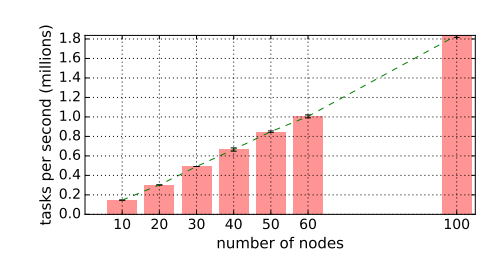
圖 7:該系統利用 GCS 和自下而上的分佈式調度程序,以線性方式實現的端到端可擴展性。Ray 用 60 個 m4.16xlarge 節點可以達到每秒 100 萬任務的吞吐量,在 1 分鐘內處理 1 億任務。鑑於代價,我們忽略 x ∈ {70,80,90}。
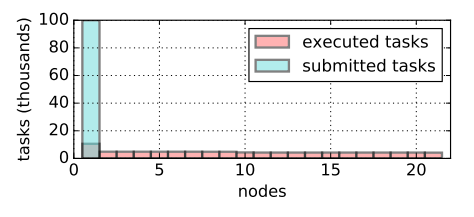
圖 8:Ray 保持平衡負載。第一個節點的驅動程序提交 10 萬個任務,全局調度程序在 21 個可用節點中平衡這些任務。
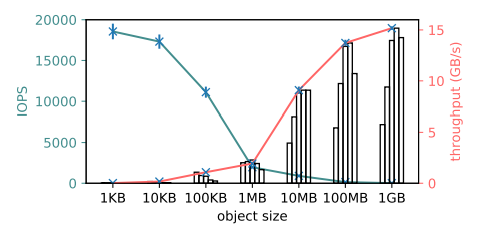
圖 9:對象存儲寫入的吞吐量和輸出操作(IOPS)。對於單個客戶端,在 16 覈實例(m4.4xlarge)上大型對象的吞吐量超過 15GB/s(紅色),小型對象的吞吐量超過 18K IOPS(藍綠色)。它使用 8 個線程複製超過 0.5MB 的對象,用 1 個線程複製其他小型對象。條形圖代表 1、2、4、8、16 個線程的吞吐量。以上結果是 5 次運行的平均值。
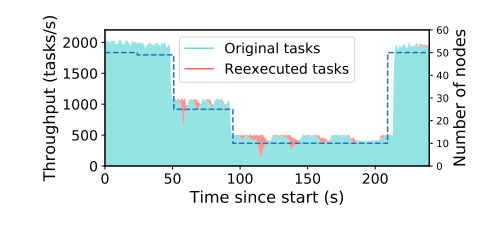
圖 10:分佈式任務的全透明容錯性。虛線代表集羣中節點的數量。曲線表示新任務(藍綠色)和重新執行的任務(紅色)的吞吐量。驅動程序持續提交和檢索 10000 個任務。每個任務耗時 100ms,依賴於前一個回合的一個任務。每個任務的輸入和輸出大小爲 100KB。
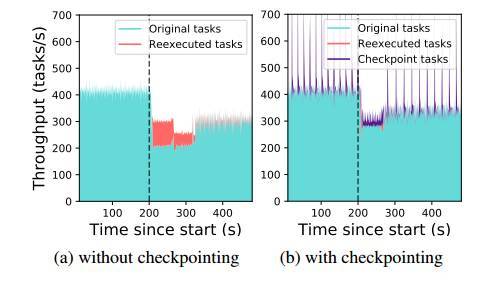
圖 11:actor 方法的全透明容錯性。驅動程序持續向集羣中的 actor 提交任務。在 t = 200s 時,我們刪除了 10 個節點中的 2 個,使集羣的 2000 個 actor 中的 400 個在剩餘節點中恢復。
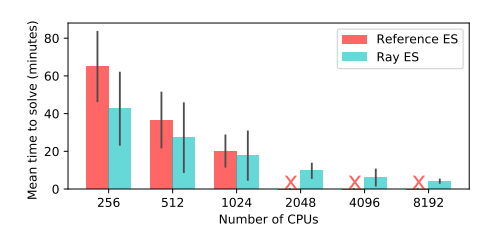
圖 12:Reference ES 和 Ray ES 系統在 Humanoid-v1 任務中得到 6000 分的時間 [13]。Ray ES 實現可以擴展到 8192 個核。而 Reference ES 系統無法運行超過 1024 個核。我們使用 8192 個核獲得了 3.7 分鐘的中位耗時,比之前公佈的最佳結果快一倍。在此基準上,ES 比 PPO 快,但是運行時間方差較大。
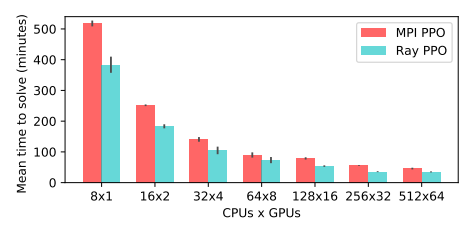
圖 13:MPI PPO 和 Ray PPO 在 Humanoid-v1 任務中得到 6000 分的時間 [13]。Ray PPO 實現優於專用的 MPI 實現 [3],前者使用的 GPU 更少,代價也只是後者的一小部分。MPI 實現中每 8 個 CPU 就需要 1 個 GPU,而 Ray 至多需要 8 個 GPU,每 8 個 CPU 所需的 GPU 不超過 1 個。
表 3:低延遲機器人模擬結果