十幾個小時前,一位 機器學習工程師在 reddit 上發帖求助:ML 領域浮躁、門檻低、產品差,無法專心做東西,該不該換個領域?帖子一經發布,立刻引起了大量討論。

該工程師如此描述他的問題:
在目前機器學習和深度學習炒作的背景下,大家對從事機器學習方面的工作(業界或學界)有何建議?
我在一家大型非技術公司做應用研究工程師。但最近幾年 ML 在我心中逐漸失去了光芒——圍繞着它的炒作給這個領域帶來了大量噪音,對於真正關心科學的人來說這種狀況太糟了。
我認爲自己嚴謹應用機器學習的努力被浪費了,這讓我的競爭力也變弱:管理層想要「深度學習」解決方案,當有人讀了一篇博客、拋出一些不完備的訓練數據和 Keras model.fit() 後,就聲稱問題解決了,可他們竟然很滿意。我認爲在這樣的環境中我沒法做機器學習,並且我們很難對抗深度學習「廉價、簡單」這樣的炒作(諷刺的是,簡單的隨機森林更簡單而且效果也很好,但那不「性感」。我就曾遇到過明明用其它方法更簡單有效,但非要用神經網絡的情況)。我熱愛機器學習,也希望看到大家都學習機器學習,但是低門檻導致將不好的模型賣給外行人的行爲增加。
你們享受自己的機器學習生涯嗎?我在考慮轉行回到軟件工程行業,或者換一家公司。可能我太暴躁或太追求完美了吧……有人有類似的想法嗎?
(背景:計算機科學碩士學位,研究重點:機器學習。畢業後從事應用研究職位,軟件工程和機器學習的工作內容各佔一半。我不是特別優秀,但是我所在的公司沒有 AI/ML 專家,因此我被當作這方面的專家。)
reddit 網友紛紛迴應。
有很多人贊同帖主的看法:
@gerry_mandering_50
「管理層想要「深度學習」解決方案,當有人讀了一篇博客、拋出一些不完備的訓練數據和 Keras model.fit() 後,就聲稱問題解決了,可他們竟然很滿意。」
這部分說得太對了。我經常看到有博主整個複製網上的教程代碼,只有少量原創文字,而且不寫出處(通常是生產軟件的技術公司將這些原創教程發在軟件網站上,這些教程常常過分簡單化)。這些博主認爲自己是數據科學和機器學習領域的專家,好像這些代碼是自己寫的似的。
管理層無法分辨,在他們看來所有事情似乎都很簡單而且已經得到解決,那麼爲什麼我們不可以這麼做呢?因爲這就是生產軟件的科技公司設計教程的目的啊……
@thetall0ne1
網友 thetall0ne1 表示,「我在一家技術公司使用、售賣機器學習應用好多年了,有時也會感到厭倦。不過,我倒支持使用深度學習模型解決問題。因爲我發現結果很好。上週,我測試了一個 logo 檢測器,這是一個簡單的計算機視覺掩碼,非常好用。看一下 Gartner 的機器學習技術成熟度曲線,你就會發現到達穩定期就好了。」
而有網友針對技術成熟度曲線迴應說,「我確信我們還沒到達幻滅期。我認識的很多人(一些連計算機都不怎麼會用)都開始討論機器學習了。」
也有網友持反對意見,從企業和職業發展的角度展開了論述:
@Scortius
我的看法完全不同。
帖主在非技術公司工作,他們支付給你的是固定薪水。發工資的錢來自於售賣的產品。作爲員工,你有責任爲公司提供價值。除非你在研究機構工作,那你的主要工作將是通過提供增加利潤的方式來掙工資。
「用正確的方式」做事是很重要,但我也在琢磨,一個未受培訓的員工如何能進入公司,還僅使用 model.fit() 就爲公司提供了更多價值。
你沒有了解如何用正常的方法獲取工資,公司只是想要投資有所回報。我的研究所也有你這樣的人,大家都不願意跟他們合作,因爲工作最終要求的還是簡單且富有成效的結果啊。你需要將對公司的回報展現出來,進而獲取更多時間和自由度去更深入地解決問題。你不在技術公司工作的話,尤其應該如此。
如果你想有更多時間探索如何使用現代方法或更正式的方法,你要麼通過按照我建議的方式提供價值進而獲得這種自由,要麼利用你在這家公司的經驗去支持探索性或深入研究的公司或研究機構工作。工作就在那裏,但是即使是在那些工作崗位上,你也必須展現出價值,才能掙得深入研究的權利。
在帖子中,很多網友對這波 AI 浪潮炒作進行了討論,其中多次提到了 Gartner 技術成熟度曲線。
事實上,自 2015 年以來,機器學習/深度學習就一直處於巔峯狀態,那一年也被標記爲距離生產力高峯 2 - 5 年。
如果你看過 Gartner 2015 年技術成熟度曲線,準備等興奮「不可避免地」消退時進入機器學習,那你今天可能還需要等待——再多等三年。
或許這個「永久巔峯」顯示了技術成熟度曲線的侷限性。但是這也表明機器學習/深度學習將繼續存在處於熱潮之中。
更多的證據來自我最近寫的一份 HFS 研究報告,其中,根據福布斯發佈的全球企業 2000 強(Global 2000),71 % 的數據科學決策者表示機器學習沒有被誇大。
以下是四年的完整歷史:
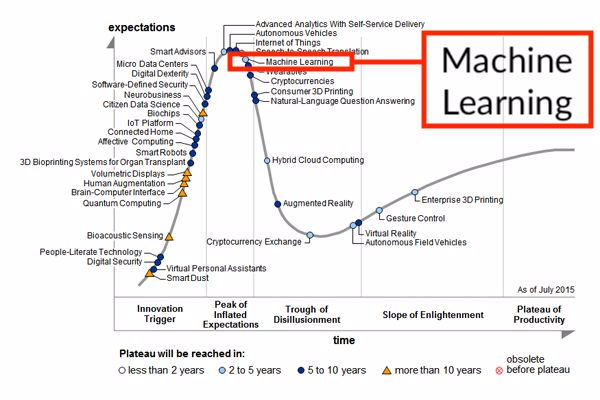
2015 Gartner 技術成熟度曲線
機器學習的技術成熟度曲線首次亮相略超過了期望膨脹頂峯期(Peak of Inflated Expectations)。它是否已經走向幻滅期(Trough of Disillusionment)?
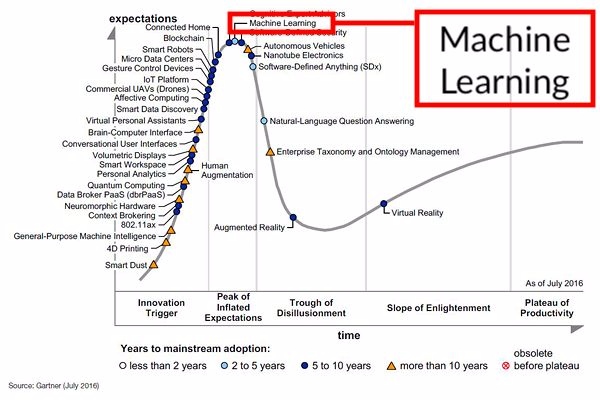
2016 Gartner 技術成熟度曲線
機器學習稍微向後移至頂峯,這絕不是走向低潮的跡象。
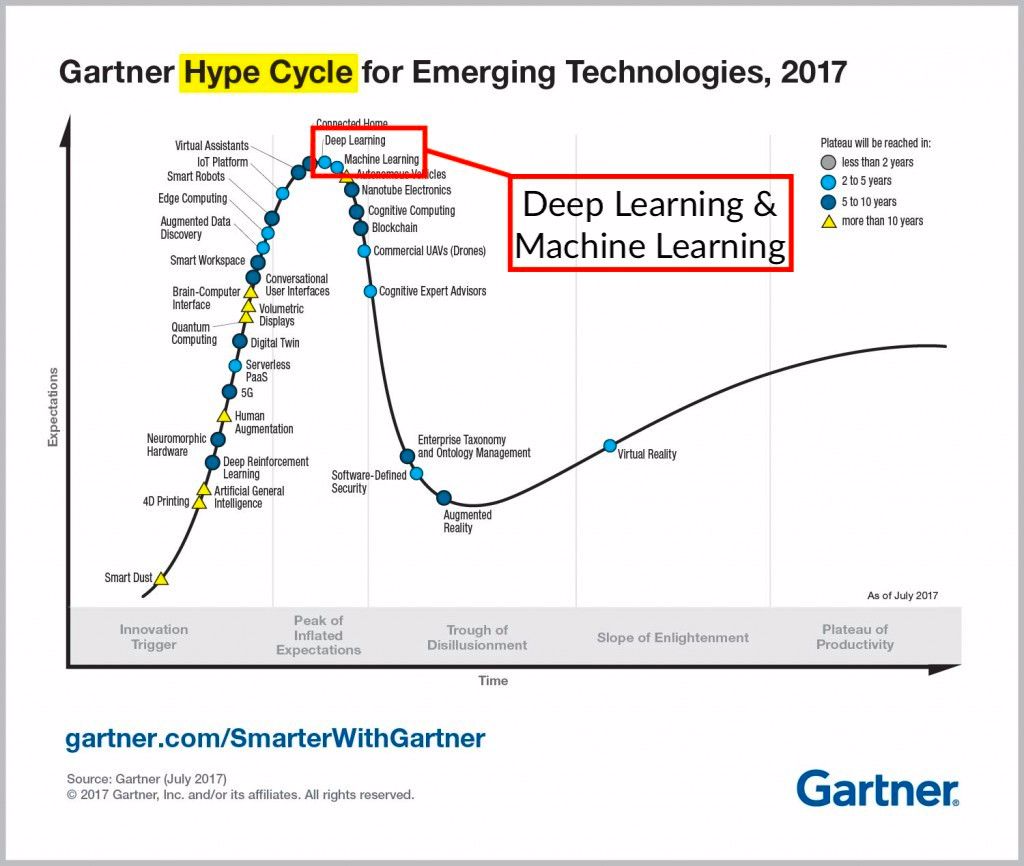
2017 Gartner 技術成熟度曲線
深度學習到達頂峯,加入機器學習。
2018 Gartner 技術成熟度曲線
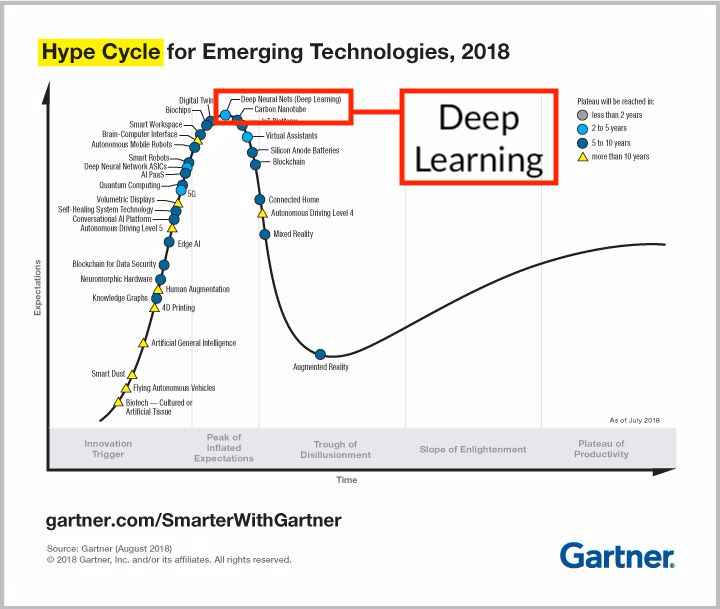
機器學習可能下滑了,但深度學習仍然位居頂峯。
深度學習還會面臨技術成熟度曲線所暗示的那種強烈的預期修正嗎?考慮到整個機器學習的應用狀況,這似乎很難。HFS 研究調查中,86 % 的受訪者認爲這項技術正在對他們的行業產生影響。
其實,關於深度學習炒作的問題,從谷歌 AlphaGo 之後就從未斷絕過,如今這種過度炒作對整個領域的影響已經顯現出來:無論是學術研究還是在產業應用中。
而僅對工程師或者研究員來說,如何在 AI 泡破破裂時站穩腳跟是不得不考慮的問題。(推薦閱讀:當 AI 泡沫破裂時……)