在多智能體環境(Multiagent environments)中,智能體之間對資源的惡性競爭現象無疑是通往通用人工智能(Artificial general intelligence, AGI)路上的一塊絆腳石。多智能體環境具有兩大實用的特性:首先,它提供了一個原生的課程(Natural curriculum)——這裏環境的困難程度取決於競爭對手的能力(而如果你是與自身的克隆進行競爭,則該環境與你的能力等級是相當匹配的);其次,多智能體環境不具有穩定的平衡:因爲無論智能體多麼聰明,總是存在着更大壓力使得它更加聰明。這些環境與傳統環境有着非常大的不同,因此還有更多的研究有待進行。
據瞭解,來自OpenAI的研究員發明了一種新算法——MADDPG。該算法適用於多智能體環境下的集中式學習(Centralized learning)和分散式執行(Decentralized execution),並且允許智能體之間學會協作與競爭。

四個紅色智能體通過MADDPG算法進行訓練,它們的目標任務是追逐圖中的兩個綠色智能體。其中四個紅色智能體爲了獲得更高的回報,學會了互相配合,共同去追捕其中一個綠色智能體。而與此同時,兩個綠色智能體也學會了分開行動,其中一個智能體負責將四個紅色智能體吸引開,然後另一個綠色智能體則乘機去接近水源(由藍色圓圈表示)。
事實上,MADDPG算法並非完全原創,它擴展自一個被稱爲DDPG的增強學習(Reinforcement learning)算法,靈感則來源於基於Actor-Critic的增強學習技術。另外據我們瞭解,還有許多其它團隊也正在探索這些算法的變種以及並行化實現。
該算法將模擬中的每個智能體視爲一個「Actor」,並且每個Actor將從「Critic」那兒獲得建議,這些建議可以幫助Actor在訓練過程中決定哪些行爲是需要加強的。通常而言,Critic試圖預測在某一特定狀態下的行動所帶來的價值(比如,我們期望能夠獲得的獎勵),而這一價值將被智能體(Actor)用於更新它的行動策略。這麼做比起直接使用獎勵來的更加穩定,因爲直接使用獎勵可能出現較大的差異變動。另外,爲了使訓練按全局協調方式行動的多個智能體(Multiple agents that can act in a globally-coordinated way)變得可行,OpenAI的研究員還增強了Critic的級別,以便於它們可以獲取所有智能體的行爲和觀察,如下圖所示。

據悉,MADDPG中的智能體在測試期間不需要訪問中央的Critic,智能體們將根據自己的觀察和對其它代理行爲的預測而行動。由於每個智能體都有各自獨立的集中式Critic,該方法能被用於模擬智能體之間任意的獎勵結構,包括獎勵衝突的對抗性案例。
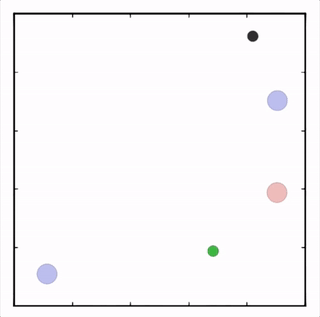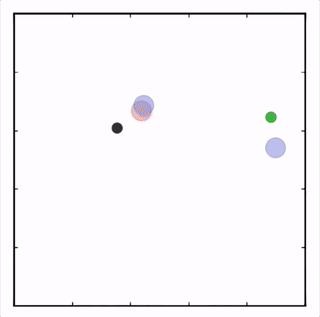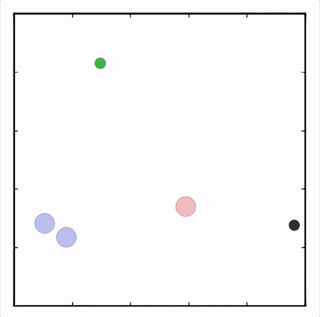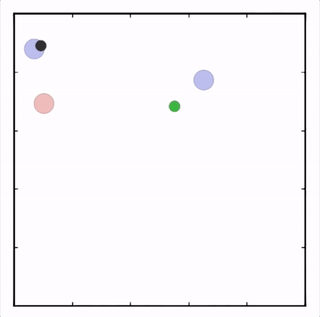
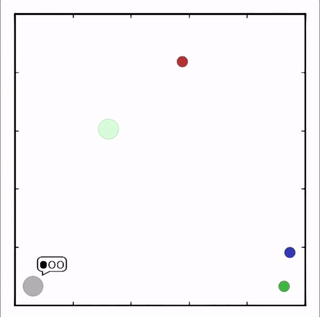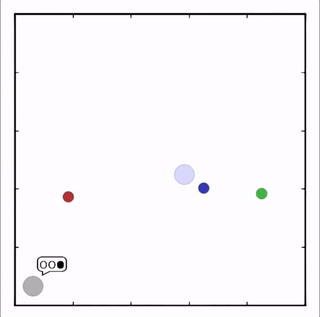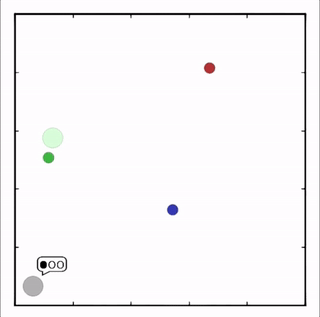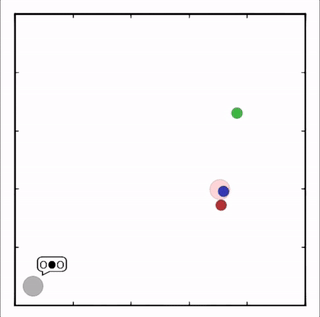
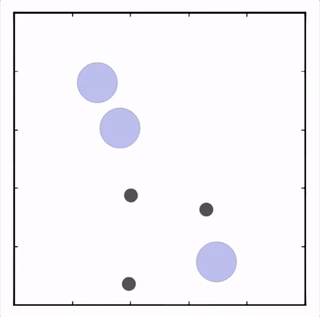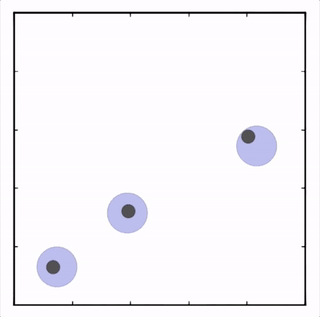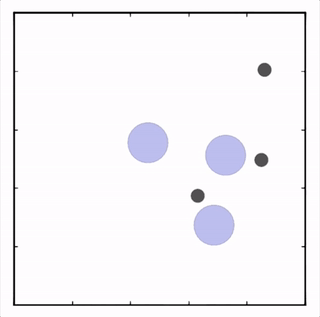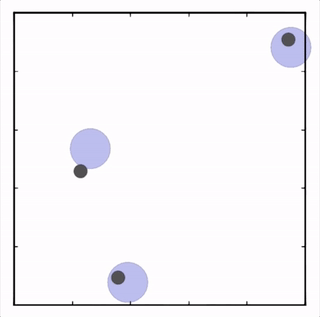
OpenAI的研究員已經在多項任務中測試了該方法,並且實驗結果表明,MADDPG在所有任務中的表現均優於DDPG。上邊的動圖自左向右依次展示了:兩個AI智能體(藍色圈)嘗試前往指定地點,並且它們學會分開行動,以便於向反對智能體(紅色圈)隱藏自己的目標地點;其中一個智能體將地標傳達給另一個智能體;最後是三個智能體通過協調共同到達各自的地標,並且途中沒有發生碰撞。


上圖展示了,通過MADDPG訓練的紅色智能體比起通過DDPG訓練的紅色智能體表現出了更加複雜的行爲。在上圖的動畫中,通過MADDPG(左圖)和DDPG(右圖)訓練的紅色智能體試圖追逐綠色智能體,這期間它們可能需要通過綠色的森林或者躲避黑色的障礙物。
傳統增強學習
傳統的分散式增強學習(Descentralized reinforcement learning)方法,比如DDPG,actor-critic learning,deep Q-learning等等,在多智能體環境下的學習總是顯得很掙扎,這是因爲在每個步驟中,每個智能體都將嘗試學習預測其它智能體的行動,並且同時還要採取自己的行動,這在競爭的情況下尤爲如此。MADDPG啓用了一個集中式Critic來向智能體提供同類代理的觀察和潛在行爲的信息,從而將一個不可預測的環境轉換成可以預測的環境。
當前,梯度策略方法(Policy gradient methods)面臨着更多的挑戰。因爲當獎勵不一致的時候,這些方法很難得到正確的策略,並且表現出了高度的差異。另外研究員還發現,加入了Critic之後雖然提高了穩定性,但是依然無法解決多個環境之間諸如交流合作的問題。並且對於學習合作策略問題,在訓練過程中綜合考慮其它智能體的行爲似乎是非常重要的。
初步研究
據我們瞭解,在開發MADDPG之前,OpenAI研究員採用分散技術(Decentralized techniques)的時候,他們注意到,如果 Speaker發送不一致的消息,Listener通常會忽略掉髮言智能體。然後,後者會將所有與Speaker的消息有關的權重設置爲0,從而高效地忽略掉這些信息。
然而,一旦出現了這種情況,訓練過程將難以恢復,因爲缺乏了有效的反饋,Speaker永遠也無法知道自己是否正確。爲了解決這個問題,研究員發現了一個最近提出的分層強化學習(Hierarchical Reinforcement Learning)技術,該技術強制Listener將Speaker的消息納入其決策過程。但是這個方案沒有起到作用,因爲儘管它強制Listener獲取Speaker的消息,但這並不能幫助後者弄清哪些是相關的。最終,OpenAI提出的集中式Critic方法幫助解決了這些挑戰,它幫助 Speaker瞭解哪些信息可能與其它智能體的行爲是有關的。如果想獲取更多的結果,可以觀看原文鏈接裏的視頻。
下一步
智能體建模在人工智能研究中具有豐富的歷史,並且其中許多的場景已經被廣泛研究過了。以前的許多研究只在擁有很短的時長和很少的狀態空間的遊戲中進行。但是深度學習使得研究員們可以處理複雜的視覺輸入,另外增強學習爲學習長時間行爲提供了工具。現在,研究員可以使用這些功能來一次性訓練多個智能體,而不需要了解環境的動態變化(環境在每個時間步驟中是如何變化的),並且可以在學習來自環境的高維度信息的同時,解決涉及溝通和語言的更廣泛的問題。
最後是OpenAI的一則小廣告,如果你對探索不同的方法來推進AI智能體的發展感興趣的話,不妨考慮加入OpenAI吧!
Via Learning to Cooperate, Compete, and Communicate