近日,MIT 與 Facebook 共同提出了用於動作分類和定位的大規模視頻數據集的標註方法,新的框架平均只需 8.8 秒就能標註一個剪輯,相比於傳統的標註過程節省了超過 95% 的標註時間,繼而證明了該數據集可以有效預訓練動作識別模型,經過微調後能顯著提高在較小規模數據集上的最終評估度量。
數據集鏈接:http://slac.csail.mit.edu/
圖像分類和目標檢測領域近年來取得了重大的平行進展。可以認爲,這些進展歸功於數據集的質量提高和數量增長,進而逐步成功地應用到了更復雜的學習模型中。在圖像分類中,我們有從 Caltech101(2004,只有 9146 個樣本)到 ImageNet(2011,包含 120 萬個樣本)這樣的數據集。在目標檢測中,儘管收集邊界框信息所需的額外人類標註成本提高了,但也出現了訓練集規模逐漸擴展的相似趨勢。Pascal VOC(2007)只包含 1578 個樣本,而最近提出的 COCO 數據集包含超過 20 萬張圖像和 50 萬個目標實例標註。
在視頻領域,動作分類和動作定位的數據集的規模差距有逐漸擴大的趨勢。幾年前提出的動作分類數據集包含幾千個樣本(HMDB51 有 6849 部視頻,UCF101 有 13000 部視頻,Hollywood2 有 3669 部視頻),而最近的基準將數據集規模提高了兩個量級(Sports1M 包含超過 100 萬部視頻,Kinetics 包含 30 萬 6 千部視頻)。但是動作定位的數據集並沒有同等的增長速度。THUMOS 在 2014 年提出,包含 2700 部修整過的(trimmed)視頻和 1000 部未修整的視頻,以及定位標註。而如今最大規模的動作定位數據集相比 THUMOS 僅擴大了一點。例如,ActivityNet 包含 2 萬部視頻和 3 萬個標註,AVA 包含 5 萬 8 千個剪輯,Charade 包含 6 萬 7 千個視頻片段。我們在表 1 中給出了不同視頻數據集的細節對比。
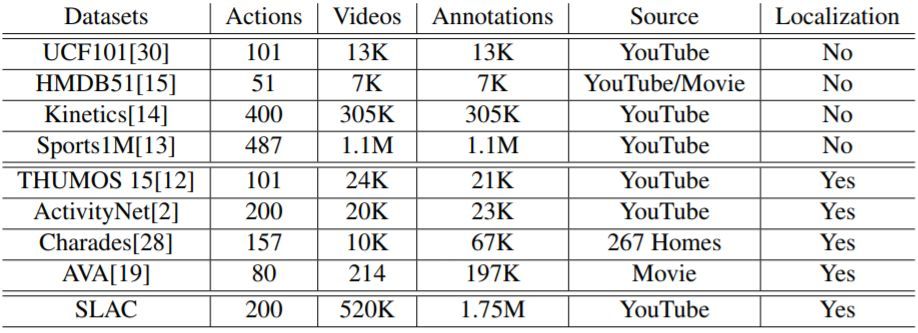
表 1:SLAC 和其它視頻數據集的對比。注意,Sports1M 的標註通過分析和視頻相關的文本元數據自動地生成,因此是不準確的。
爲什麼動作定位數據集的規模會比目標檢測數據集小得多?爲什麼動作定位數據集的規模仍然比動作分類數據集小一個量級?在本文中,作者提出了兩個猜想。首先,在視頻上構建時間標註是很費時的。根據我們在專業標註員上做的實驗,在視頻中手工標註動作的起始和結束需要花費視頻長度的 4 倍時間。爲了給出準確的時間標註,標註員不僅需要觀看整個視頻序列,還需要來回重播視頻的幾個部分以尋找確定的邊界。其次,動作標註的時間邊界通常是模棱兩可的。雖然目標邊界由其物理延展所定義,但由於人類運動的平滑連續性以及動作構成定義的缺乏,動作的時間變化邊界通常是模糊的。
在本文中,作者提出將時間標註任務改成更高效和更低模糊性的形式。即從每個視頻中採樣少量的短時剪輯提供給標註員。他們使用了一種主動學習(active learning)算法,以選擇一個簡單剪輯和幾個硬剪輯用於標註。然後標註員需要確定這些剪輯中是否包含假定的動作。實驗表明提供二值的「是/否」回答對於標註員來說更快更簡單。該方法相比傳統的觀看整個視頻並手工標註動作邊界的方法節省了超過 95% 的時間。極少的人類干預允許他們構建包含高質量連續標註的大規模數據集。雖然他們的方法僅僅提高了標註剪輯的稀疏集合的質量,作者表明由這樣的標註監督的模型在動作分類和動作定位任務中都獲得了優越的泛化性能。
對於動作分類,可以利用該數據集的大規模特性預訓練視頻模型。作者表明通過在公認的動作分類基準數據集(UCF101、HMDB51 和 Kinetics)上微調這些預訓練模型,得到的結果顯著優於從零開始訓練。在 Kinetics、UCF101 和 HMDB51 基準數據集上,他們分別將基於 ResNet 的 3D 卷積網絡基線結果提高了 2.0%、20.1% 和 35.4%。作者還證明在 SLAC 上預訓練相比在 Sports1M 或 Kinetics 上預訓練更加有效。Sports-1M 的標註由一個標籤預測算法生成,不可避免會引入顯著的噪聲。此外,Sports1M 的視頻長度平均超過 5 分鐘,而標籤預測的動作可能僅在整個視頻的很小一部分時間中發生。這爲學習良好的視頻表徵以進行動作分類帶來了大量的困難。和 Kinetics 相比,SLAC 包含了近 6 倍的剪輯標註(175 萬 vs 30 萬 5 千),這可能是在該基準數據集上訓練的深度學習模型擁有優越泛化性能的原因。
最後,作者表明 SLAC 中的稀疏剪輯標註也可以用於預訓練動作定位模型,並可以在每一幀給出密集型的預測。在 THUMOS 挑戰賽和 ActivityNet-v1.3 數據集上,他們分別將基線模型的 mAP 值提升了 8.6% 和 2.5%。
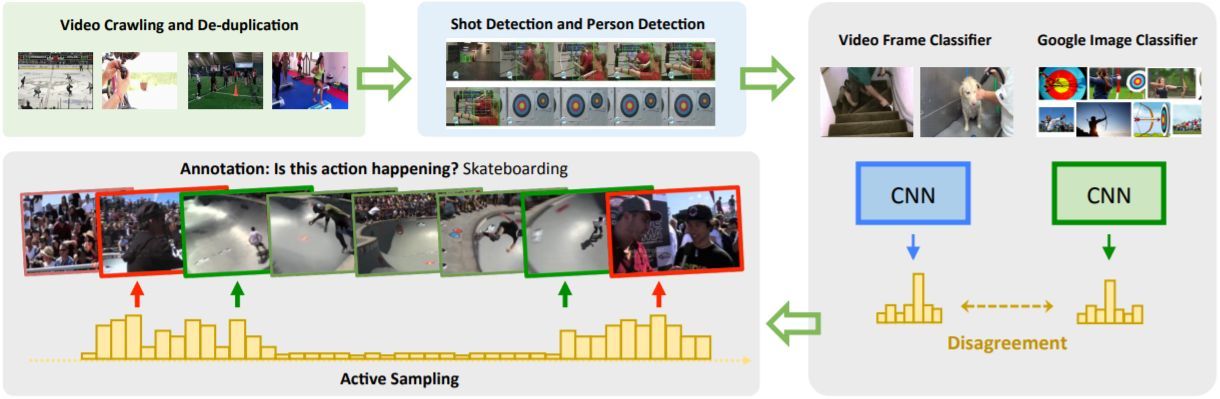
圖 1:獲得 SLAC 數據的收集過程。

表 7:在 SLAC 上預訓練的 Res3D-34 模型與在 UCF101、HMDB51 和 Kinetics 上訓練的當前最佳模型的對比。
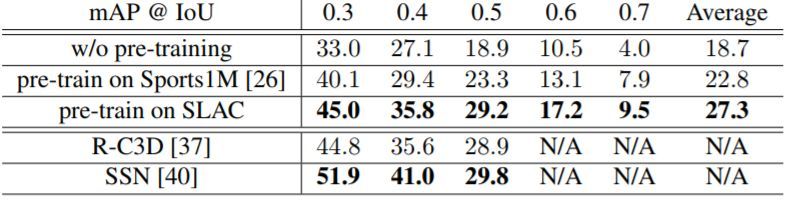
表 8:在不同數據集上預訓練的模型以及當前最佳的模型,在 THUMOS14 測試集上的動作定位性能對比。
論文:SLAC: A Sparsely Labeled Dataset for Action Classification and Localization
論文鏈接:https://arxiv.org/abs/1712.09374
摘要:本文提出了一種從不受限的、真實的網絡數據中創建用於動作分類和定位的大規模視頻數據集的過程。我們創建了一個新的視頻基準數據集 SLAC(Sparsely Labeled ACtions),該基準數據集由超過 52 萬個未修整的視頻和包含 200 種動作的 175 萬個剪輯標註構成,進而證明了該過程的可擴展性。使用我們提出的框架平均只需要 8.8 秒就可以標註一個剪輯。這相比於傳統的手工修整和定位動作的過程節省了超過 95% 的標註時間。我們的方法通過自動識別硬剪輯(即包含一致的動作,但不同的動作分類器會得到不同的預測結果)可以顯著地減少人類標註數。人類標註者可以在幾秒內辨別出這樣的剪輯是否真正包含假定的動作,從而可以用很小的代價爲信息豐富的樣本生成標籤。本文證明了我們的大規模數據集可以有效地預訓練動作識別模型,經過微調後可以顯著提高在較小規模基準數據集上的最終評估度量。在 Kinetics、UCF-101 和 HMDB-51 上使用 SLAC 數據集預訓練的模型可以超越從零開始訓練的基線模型,在使用 RGB 圖像作爲輸入時,這三個預訓練模型的 top-1 準確率分別提高了 2.0%、20.1% 和 35.4%。此外,我們還提出了一種簡單的過程,它通過利用 SLAC 中的稀疏標籤預訓練動作定位模型。在 THUMOS14 和 ActivityNet-v1.3 基準上,我們的定位模型分別提高了 8.6% 和 2.5% 的基線模型 mAP 值。