近日,DeepMind 發佈博客,提出一種結合了對抗訓練和強化學習的智能體 SPIRAL。該智能體可與繪圖程序互動,在數位畫布上畫畫、改變筆觸的大小、用力和顏色,並像街頭藝人一樣畫畫。也就是說,通過向 SPIRAL 提供人類用於描繪周圍世界的工具,它們也可以生成類似的表徵。
人類眼中的世界不只是角膜映射出的圖像。比如,當我們看一幢建築,讚美其設計精巧複雜時,我們能夠欣賞到它的精巧工藝。通過創造事物的工具來解讀事物是幫助我們理解世界的一項重要能力,也是人類智能的重要組成部分。
DeepMind 希望其系統能夠按類似的方式構建對世界的豐富表徵。例如,當系統觀察一幅畫的圖像時,它們能夠理解畫家使用的筆觸,而不只是看到屏幕上呈現的像素。
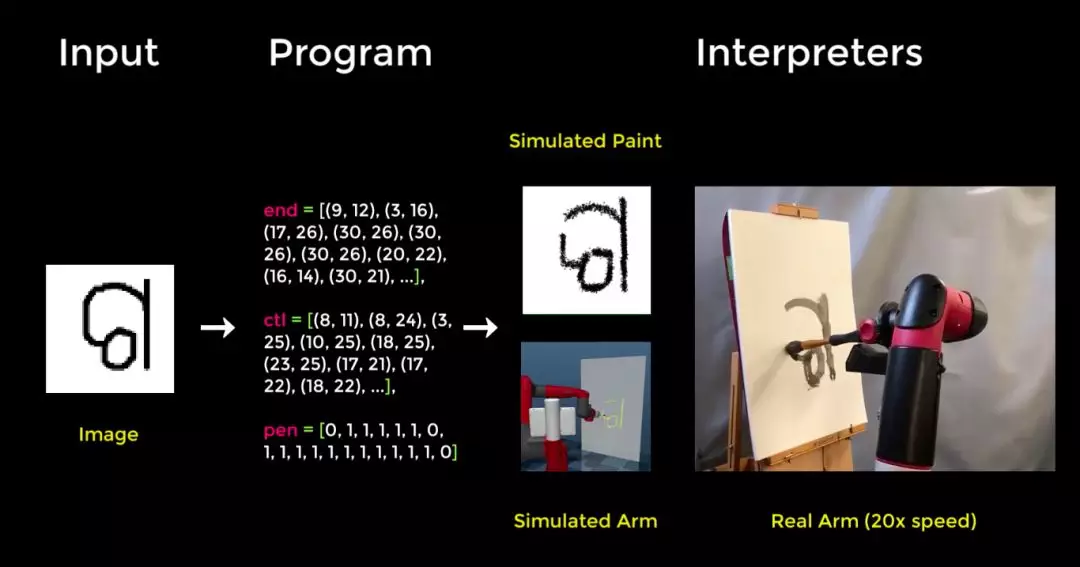
在《Synthesizing Programs for Images using Reinforced Adversarial Learning》研究中,DeepMind 給人工智能體配備了用於生成圖像的工具,並展示了智能體可以推斷出數字、字符和畫像被創造出來的過程。關鍵是,它們學會這麼做完全是出於自覺,沒有使用人類標註的數據集。這與最近的研究《A Neural Representation of Sketch Drawings》恰恰相反,後者目前仍依賴於從人類演示中學習,是一個時間密集型的過程。

DeepMind 設計了一種深度強化學習智能體,該智能體可與計算機繪圖程序(http://mypaint.org/)互動,在數位畫布上畫畫、改變筆觸的大小、用力和顏色。最初,這一未經訓練的智能體下筆隨意,其塗鴉沒有明顯的內容或結構。爲了解決這個問題,DeepMind 不得不提出一種方式來獎勵智能體,鼓勵它生成有意義的塗鴉。
爲此,DeepMind 訓練出第二個神經網絡,叫作判別器(discriminator),旨在預測特定畫作是智能體生成的,還是來自現實照片數據集。繪畫智能體所接受的獎勵決定於它多大程度上能夠「欺騙」判別器,使之認爲其畫作是真的。換言之,智能體的獎勵信號是由自己學習而來。這和生成對抗網絡使用的方法類似,但也有不同,因爲 GAN 中的生成器通常是一個可以直接輸出像素的神經網絡。而 DeepMind 的智能體通過寫圖形程序與繪畫環境互動,來生成圖像。
在第一組實驗中,智能體被訓練來生成類似 MNIST 數字的圖像,只對智能體顯示數字,而沒有數字生成的過程。通過嘗試生成欺騙判別器的圖像,智能體學會控制筆觸,並繪製適合不同數字的風格,這種技術叫作視覺程序合成(visual program syhthesis)。
DeepMind 還訓練它來重現特定圖像。這裏,判別器要確定重現出的圖像是目標圖像的複製,還是由智能體生成的。判別器判斷二者的難度越大,智能體得到的獎勵就越多。
關鍵是,該框架具備可解釋性,因爲它能生成一系列控制模擬畫刷的動作。這意味着該模型可以將其學得的東西應用到模擬繪圖程序上,以在其他類似環境中重新創建字符,如在模擬或真實的機械臂上。
也可以將該框架擴展到真實數據集上。在訓練智能體繪製名人人臉時,它能夠捕捉人臉、色調、髮型的主要特徵,就像一個寥寥幾筆繪製人像的街頭畫家一樣。

從原始感知中找到結構化表徵是人類擁有且經常使用的能力。該研究顯示通過向智能體提供人類用於描繪周圍世界的工具,它們也可以生成類似的表徵。這樣,它們學會生成可簡練表達因果關係的視覺程序。
儘管該研究只能代表朝靈活程序合成邁進的一小步,但 DeepMind 期望類似的技術可以賦予人工智能體類人感知、生成和交流的能力。
來看SPIRAL如何畫出手寫數字和名人肖像:
論文:Synthesizing Programs for Images using Reinforced Adversarial Learning

論文鏈接:https://deepmind.com/documents/183/SPIRAL.pdf
摘要:近年來,深度生成網絡的進展帶來了令人矚目的成績。但是,此類模型通常把精力浪費在數據集細節上,可能是因爲其解碼器的歸納偏置較弱。這樣圖形引擎就有了用武之地,因爲圖形引擎將低級別細節抽象化,並將圖像表示爲高級別程序。當前結合了深度學習和渲染器的方法受限於手動製作的相似度或距離函數、對大量監督信息的需求,或者將推斷算法擴展至更豐富數據集的難度。爲了緩解這些問題,我們提出了 SPIRAL,一種對抗訓練的智能體,可以生成由圖形引擎來執行的程序,以解釋和採樣圖像。該智能體的目標是欺騙判別器網絡(分辨真實數據和渲染數據),該智能體在分佈式強化學習環境中進行訓練,且訓練過程無需任何監督。令人驚訝的是,使用判別器的輸出作爲獎勵信號是使智能體獲得期望輸出渲染的關鍵。目前,這是在難度較高的現實世界數據集(MNIST、OMNIGLOT、CELEBA)和合成 3D 數據集上的第一次端到端、無監督和對抗逆圖形(adversarial inverse graphics)智能體演示。
原文鏈接:https://deepmind.com/blog/learning-to-generate-images/