雷鋒網按:本文作者牛建偉,地平線語音算法工程師。碩士畢業於西北工業大學,曾任百度語音技術部資深工程師。主要工作方向是語音識別中聲學模型的算法開發和優化,負責深度學習技術在聲學模型上的應用和產品優化。參與了百度最早的深度學習系統研發,負責優化語音搜索、語音輸入法等產品;後負責百度嵌入式語音開發,其負責的離線語音識別性能超越競品。現任地平線機器人語音識別算法工程師,深度參與地平線「安徒生」智能家居平臺的研發。
聲學模型
語音技術在近年來開始改變我們的生活和工作方式。對於某些嵌入式設備來說,語音成爲了人機交互的主要方式。出現這種趨勢的原因,首先是計算能力的不斷提升,通用GPU等高計算能力設備的發展,使得訓練更復雜、更強大的聲學模型(Acoustic Model, AM)變得可能,高性能的嵌入式處理器的出現,使語音識別的終端應用變得可能。
聲學模型是人工智能領域的幾大基本模型之一,基於深度學習的聲學模型發展對於人工智能的拓展和交互方式的延伸都有着十分重要的意義。本期的大牛講堂,我們邀請到地平線的語音算法工程師牛建偉爲大家重磅科普何爲聲學模型。
自動語音識別
自動語音識別(Automatic Speech Recognition, ASR)作爲一個研究領域已經發展了五十多年。這項技術的目標是將語音識別作爲可以使得人與人、人與機器更順暢交流的橋樑。然而,語音識別技術在過去並沒有真正成爲一種重要的人機交流形式,一部分原因是源於當時技術的落後,語音技術在大多數實際用戶使用場景下還不大可用;另一部分原因是很多情況下使用鍵盤、鼠標這樣的形式交流比語音更有效、更準確,約束更小。
語音技術在近年來開始改變我們的生活和工作方式。對於某些嵌入式設備來說,語音成爲了人機交互的主要方式。出現這種趨勢的原因:
首先是計算能力的不斷提升,通用GPU等高計算能力設備的發展,使得訓練更復雜、更強大的聲學模型(Acoustic Model, AM)變得可能,高性能的嵌入式處理器的出現,使得語音識別的終端應用變得可能;
其次,藉助近乎無處不在的互聯網和不斷髮展的雲計算,我們可以得到海量的語音數據資源,真實場景的數據使得語音識別系統變得更加魯棒;
最後,移動設備、可穿戴設備、智能家居設備、車載信息娛樂系統正變得越來越流行,在這些設備上,語音交互變成了一個無法避免的交互方式。
語音識別基本組成
語音識別系統主要有四部分組成:信號處理和特徵提取、聲學模型、語言模型(Language Model, LM)和解碼器(Decoder)。
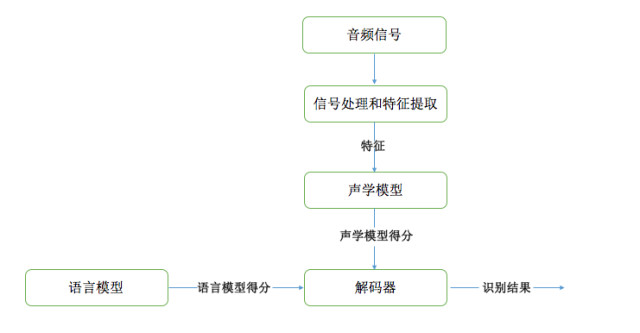
信號處理和特徵提取部分以音頻信號爲輸入,通過消除噪音、信道失真等對語音進行增強,將語音信號從時域轉化到頻域,併爲後面的聲學模型提取合適的特徵。聲學模型將聲學和發音學的知識進行整合,以特徵提取模塊提取的特徵爲輸入,生成聲學模型得分。
語言模型估計通過重訓練語料學習詞之間的相互概率,來估計假設詞序列的可能性,也即語言模型得分。如果瞭解領域或者任務相關的先驗知識,語言模型得分通常可以估計得更準確。解碼器對給定的特徵向量序列和若干假設詞序列計算聲學模型得分和語言模型得分,將總體輸出分數最高的詞序列作爲識別結果。
關於聲學模型,主要有兩個問題,分別是特徵向量序列的可變長和音頻信號的豐富變化性。可變長特徵向量序列問題在學術上通常有動態時間規劃(Dynamic Time Warping, DTW)和隱馬爾科夫模型(Hidden Markov Model, HMM)方法來解決。
而音頻信號的豐富變化性是由說話人的各種複雜特性或者說話風格與語速、環境噪聲、信道干擾、方言差異等因素引起的。聲學模型需要足夠的魯棒性來處理以上的情況。
在過去,主流的語音識別系統通常使用梅爾倒譜系數(Mel-Frequency Cepstral Coefficient, MFCC)或者線性感知預測(Perceptual Linear Prediction, PLP)作爲特徵,使用混合高斯模型-隱馬爾科夫模型(GMM-HMM)作爲聲學模型。在近些年,區分性模型,比如深度神經網絡(Deep Neural Network, DNN)在對聲學特徵建模上表現出更好的效果。基於深度神經網絡的聲學模型,比如上下文相關的深度神經網絡-隱馬爾科夫模型(CD-DNN-HMM)在語音識別領域已經大幅度超越了過去的GMM-HMM模型。
我們首先介紹傳統的GMM-HMM聲學模型,然後介紹基於深度神經網絡的聲學模型。
傳統聲學模型(GMM-HMM)
HMM模型對時序信息進行建模,在給定HMM的一個狀態後,GMM對屬於該狀態的語音特徵向量的概率分佈進行建模。
1.混合高斯模型
如果一個連續隨機變量服從混合高斯分佈,則它的概率密度函數爲:
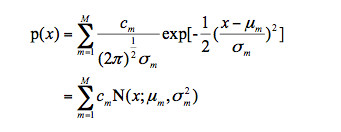
混合高斯模型分佈最明顯的性質是它的多模態,這使得混合高斯模型可以描述很多顯示出多模態性質的屋裏數據,比如語音數據,而單高斯分佈則不合適。數據中的多模態性質可能來自多種潛在因素,每一個因素決定分佈中特定的混合成分。如果因素被識別出來,那麼混合分佈就可以被分解成有多個因素獨立分佈的集合。
那麼將上面公式推廣到多變量的多元混合高斯分佈,就是語音識別上使用的混合高斯模型,其聯合概率密度函數的形式如下:
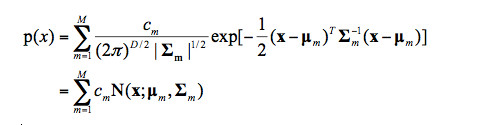
在得到混合高斯模型的形式後,需要估計混合高斯模型的一系列參數變量: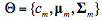 ,我們主要採用最大期望值算法(Expectation Maximization, EM)進行參數估計,公式如下:
,我們主要採用最大期望值算法(Expectation Maximization, EM)進行參數估計,公式如下:
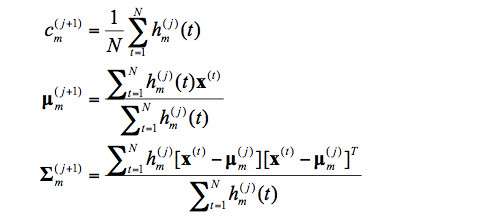
其中,j是當前迭代輪數,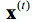 爲t時刻的特徵向量。GMM參數通過EM算法進行估計,可以使其在訓練數據上生成語音觀察特徵的概率最大化。此外,GMM模型只要混合的高斯分佈數目足夠多,GMM可以擬合任意精度的概率分佈。
爲t時刻的特徵向量。GMM參數通過EM算法進行估計,可以使其在訓練數據上生成語音觀察特徵的概率最大化。此外,GMM模型只要混合的高斯分佈數目足夠多,GMM可以擬合任意精度的概率分佈。
2.隱馬爾可夫模型
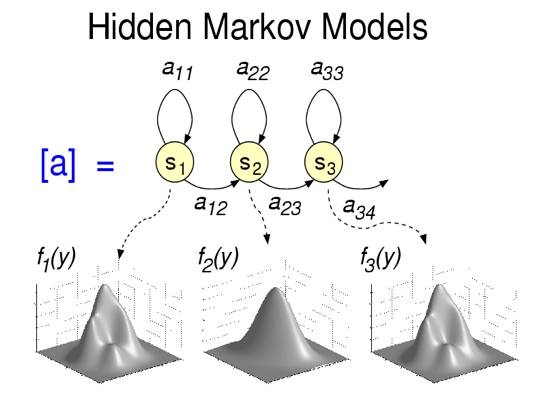
爲了描述語音數據,在馬爾可夫鏈的基礎上進行了擴展,用一個觀測的概率分佈與馬爾可夫鏈上的每個狀態進行對應,這樣引入雙重隨機性,使得馬爾可夫鏈不能被直接觀察,故稱爲隱馬爾可夫模型。隱馬爾可夫模型能夠描述語音信號中不平穩但有規律可學習的空間變量。具體的來說,隱馬爾可夫模型具有順序排列的馬爾可夫狀態,使得模型能夠分段的處理短時平穩的語音特徵,並以此來逼近全局非平穩的語音特徵序列。
隱馬爾可夫模型主要有三部分組成。對於狀態序列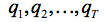
(1)轉移概率矩陣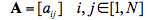 ,描述馬爾可夫鏈狀態間的跳轉概率:
,描述馬爾可夫鏈狀態間的跳轉概率:
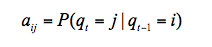
(2)馬爾可夫鏈的初始概率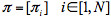 ,其中
,其中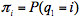 ;
;
(3)每個狀態的觀察概率分佈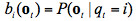 ,按照上一節的介紹,我們會採用GMM模型來描述狀態的觀察概率分佈。在這種情況下,公式可以表述爲:
,按照上一節的介紹,我們會採用GMM模型來描述狀態的觀察概率分佈。在這種情況下,公式可以表述爲:
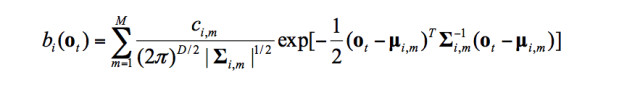
隱馬爾可夫模型的參數通過Baum-Welch算法(在HMM上EM算法的推廣)進行估計。
CD-DNN-HMM
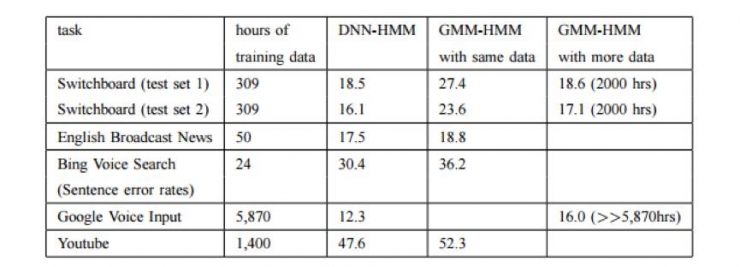
雖然GMM-HMM在以往取得了很多成功,但是隨着深度學習的發展,DNN模型展現出了明顯超越GMM模型的性能,替代了GMM進行HMM狀態建模。不同於GMM模型,DNN模型爲了獲得更好的性能提升,引入了上下文信息(也即前後特徵幀信息),所以被稱爲CD-DNN-HMM(Context-Dependent DNN-HMM)模型。在很多測試集上CD-DNN-HMM模型都大幅度超越了GMM-HMM模型。
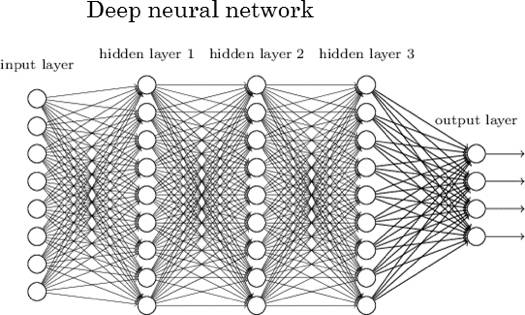
首先簡單介紹一下DNN模型,DNN模型是有一個有很多隱層的多層感知機,下圖就是具有5層的DNN,模型結構上包括輸入層、隱層和輸出層。對於第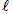 層,有公式:
層,有公式:
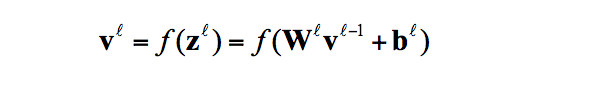
其中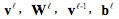 分別表示,L層的輸出向量,權重矩陣,輸入向量以及偏差向量(bias);
分別表示,L層的輸出向量,權重矩陣,輸入向量以及偏差向量(bias);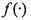 一般稱爲激活函數,常用的激活函數有sigmoid函數
一般稱爲激活函數,常用的激活函數有sigmoid函數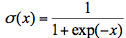 或者整流線性單元(Rectifier Linear Unit)
或者整流線性單元(Rectifier Linear Unit)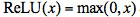 。在語音識別上應用的DNN模型一般採用softmax將模型輸出向量進行歸一化,假設模型有L層,在特徵向量爲
。在語音識別上應用的DNN模型一般採用softmax將模型輸出向量進行歸一化,假設模型有L層,在特徵向量爲 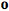 ,輸出分類數爲
,輸出分類數爲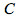 的情況下,則第
的情況下,則第 類的輸出概率爲:
類的輸出概率爲:
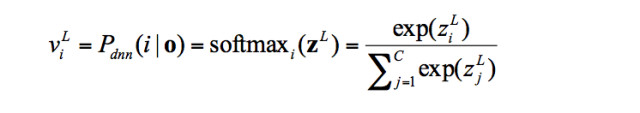
相比於GMM模型,DNN模型具有一些明顯的優勢:
首先,DNN是一種判別模型,自身便帶有區分性,可以更好區分標註類別;
其次,DNN在大數據上有非常優異的表現,伴隨着數據量的不斷增加,GMM模型在2000小時左右便會出現性能的飽和,而DNN模型在數據量增加到1萬小時以上時還能有性能的提升;
另外,DNN模型有更強的對環境噪聲的魯棒性,通過加噪訓練等方式,DNN模型在複雜環境下的識別性能甚至可以超過使用語音增強算法處理的GMM模型。
除此之外,DNN還有一些有趣的性質,比如,在一定程度上,隨着DNN網絡深度的增加,模型的性能會持續提升,說明DNN伴隨模型深度的增加,可以提取更有表達性、更利於分類的特徵;人們利用這一性質,提取DNN模型的Bottle-neck特徵,然後在訓練GMM-HMM模型,可以取得和DNN模型相當的語音識別效果。
DNN應用到語音識別領域後取得了非常明顯的效果,DNN技術的成功,鼓舞着業內人員不斷將新的深度學習工具應用到語音識別上,從CNN到RNN再到RNN與CTC的結合等等,伴隨着這個過程,語音識別的性能也在持續提升,未來我們可以期望將可以和機器進行無障礙的對話。
雷鋒網(公衆號:雷鋒網)注:本文由大牛講堂授權雷鋒網發佈,如需轉載請聯繫原作者,並註明作者和出處,不得刪減內容。有興趣可以關注公號地平線機器人技術,瞭解最新消息。
