選自Medium
這篇文章基於 GitHub 中探索音頻數據集的項目。本文列舉並對比了一些有趣的算法,例如 Wavenet、UMAP、t-SNE、MFCCs 以及 PCA。此外,本文還展示瞭如何在 Python 中使用 Librosa 和 Tensorflow 來實現它們,並用 HTML、Java 和 CCS 展示可視化結果。
Jupyter Notebook:https://gist.github.com/fedden/52d903bcb45777f816746f16817698a0
瀏覽器可視化代碼:https://github.com/fedden/umap_tsne_embedding_visualiser
作者希望能和我們分享兩個代碼庫。第一個是用來製作這篇文章的 notebook,它不像我通常喜歡的那樣精美,但是花了很長時間,讀者可以隨意使用並擴展它。
此外,作者也上傳了瀏覽器中的這些可視化代碼到 github 上。他使用 Material Design Lite 庫以相對簡潔的方式創建用戶界面,用 THREE.js 庫來快速繪製數據並進行優化,還使用 webaudiox.js 可以讓音頻生成得更容易。
這個可視化方法允許以交互的形式從兩個維度探索音頻數據集,還可以畫出參數化的圖形,就像下面展示的一樣:
結果以一個小型網頁應用的形式放在我們學校的服務器上,讀者將鼠標放在紫色點上邊,就能聽到與這個二維點向量相關聯的聲音了。
你可以自由的選擇音頻特徵的提取方式(MFCCs 或者 Wavenet 提取到的隱變量),以及降維的方法(UMAP、t-SNE 或者 PCA)。其中 UMAP 和 t-SNE 還可以調整一些參數,例如步長或者困惑度(perplexity)。
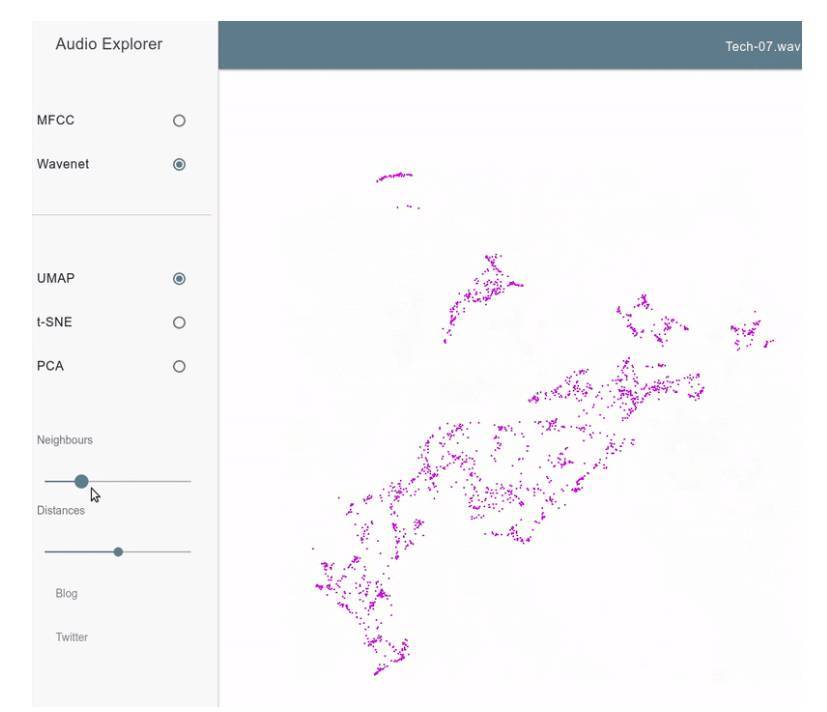
這是最終產品的一段演示
關於維度
那麼我們說的維度大小是什麼呢?它是機器學習和數據科學中的一個重要話題,用來描述數據集的潛在複雜度。一個數據集由好多數據點組成,每個數據點都有一些固定數量的特徵,或者維度。例如,我可能是一個酷愛觀察鳥類的人,我用自己在旅途中遇到的鳥組建了一個數據集。如果每個數據點存儲了喙長、翼展以及羽毛顏色這些信息,那麼就可以說我的數據集的維度是 3。
那麼我們爲什麼要如此關心維度的大小呢?拿以下比喻來說:
你在一條筆直的道路上丟失了一筆現金。你想找到這筆錢,所以你沿着這條線走,然後在相對較短的一段搜索之後就找到了錢。
這一次不太巧,你在運動的時候又一次將這筆現金丟失了,而且丟在了運動場。現在要找到這筆錢就相對比較困難了,因爲每一個位置都有一個交叉口。所以找到丟失的錢就會花費更多的時間。
最後,你魔法般地成了世界上最笨拙的宇航員。在太空行走的時候你的現金從口袋中滑落。你很惱怒,花了接下來的一整天去尋找丟失的現金。現在你是在真空的三維空間去尋找丟失的現金。相比之前的情景,這需要更多的時間和資源,可以理解,休斯頓的傢伙不太樂意做這事。
幸運的是,有一個事實很明確:隨着維度的增加(通常會超過三維),尋找方案和相關的區域(也就是說現金在什麼地方)需要更多的時間和資源。這一點在人和計算機上都是適用的。另一個重要的問題是,你需要更多的數據來對高維空間進行建模;隨着維度數量的增加,空間的體積會呈指數增長,以至於有效的數據會變得稀疏,所獲的數據很難支撐起一個具有統計意義的模型,因爲所有的數據點在很多維度中以及在很多方式下都是不相似的。
對於進行機器學習實踐的人而言,降維是一個重要的話題,因爲高維度會導致較高的計算成本,以及數據過擬合的傾向。瞭解了這一點之後,我們開始解釋這個命名適當的主題——維度詛咒,它指的是以某種方式計算高維度數據集的時候出現的現象。
降維是什麼呢?
在降維的時候,我們希望減少數據集的維度。維度數量越大,就越難進行可視化,這些特徵都是有關聯的,所以高維數據也增加了數據集中的信息冗餘。
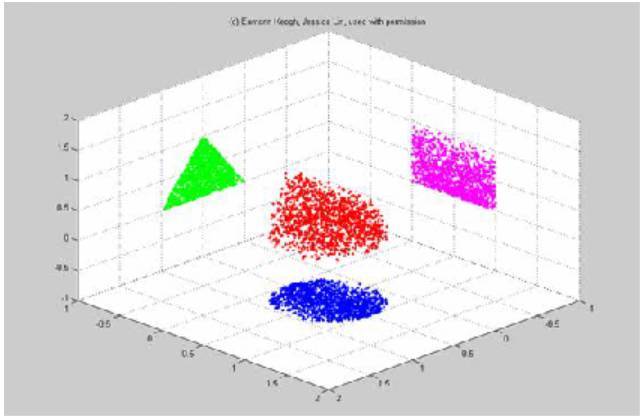
圖中哪個是將三維的紅色數據降維到二維的最好方式呢(綠色、紫色或者藍色)?進行特徵選擇之後,所有的軸都形成了不同的形狀,丟棄了與其他形狀相關的信息。
最簡單的降維方法也許就是去選擇一個能夠最好描述數據的特徵子集,丟棄掉數據集中的其它維度,這被稱作特徵選擇。很不幸的是,這貌似是在丟棄信息。
一個稍微好一些的解決方案是將數據集轉換爲一個較低維度的數據集。這個方法被稱作特徵提取,它是這篇文章的重點內容。
數據
作爲一個音頻控,我覺得嘗試給音頻文件(每個音頻文件都可能具有任意長度)降維是比較合適的,將它降到一些數值,以便它們可以用二維圖畫出來。這使我們能夠去探索一個音頻庫,並有希望快速地找到相似的聲音。在 Python 中,我們可以使用 librosa 庫得到音頻 PCM 數據。下面我們循環遍歷了一個文件夾中的樣本,將所有 wav 格式文件中的音頻數據加載進來。
importos
importlibrosa
directory = './path/to/my/audio/folder/'
forfile inos.listdir(directory):
iffile.endswith('.wav'):
file_path = os.path.join(directory, file)
audio_data, _ = librosa.load(file_path)
使用 Librosa 從一個路徑中加載音頻。
在這個項目中,主要思想就是將樣本加載到內存中,並從音頻中創建特徵序列。這些特徵就會以下面所示的方式進行處理,所以我們並不用在意特徵序列有多長。隨後,特徵可以用某種方法被降維,例如 PCA。
我們可以用很多方法將一個 PCM 數據的數組轉換成可以更好描述聲音的形式。我們可以將聲音轉換成隨時間變化的頻率信息,例如頻譜中心頻率或者過零率這些參數。但是接下來我們要剖析一個在語音識別系統中使用最廣泛的具有很好魯棒性的特徵--MFCC(梅爾頻率倒譜系數)。
MFCCs
MFCC 實際上也可以被視爲一種降維的形式;在典型的 MFCC 計算過程中,你需要傳遞一段段的 512 個音頻樣本(這裏指的是離散的數字音頻序列中的 512 個採樣點),然後得到用來描述聲音的 13 個倒譜系數。儘管 MFCC 最初是被用來表徵由人類聲道所發出的聲音的,但是結果證明這是一種在不同音質、基音下相當穩定的一種特徵,除了自動語音識別之外,它還有很多其他應用。
在提取 MFCCs 的時候,第一步就是從我們的音頻數據中計算傅里葉變換,傅里葉變換將時域信號轉換成頻域信號。在實際過程中是通過快速傅里葉變換來實現的,這是我們這個時代的一個很偉大的算法。
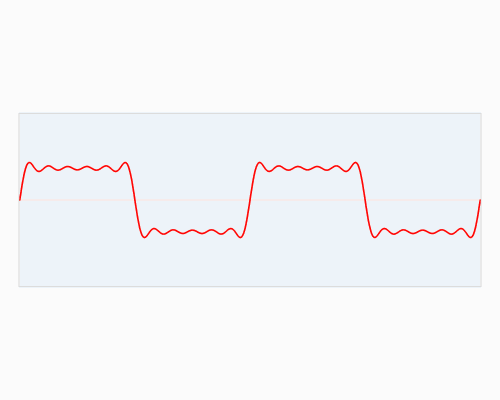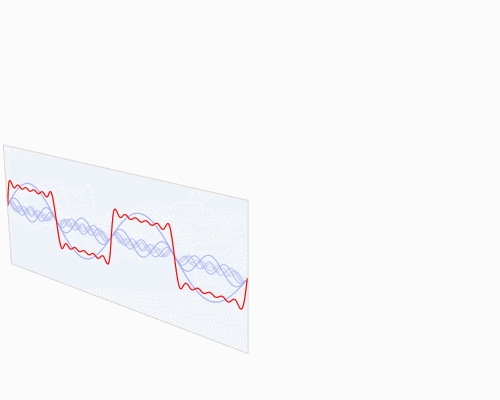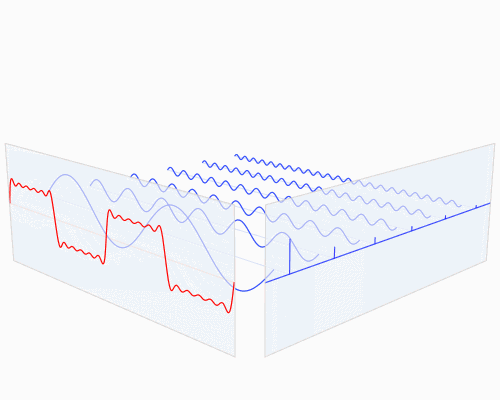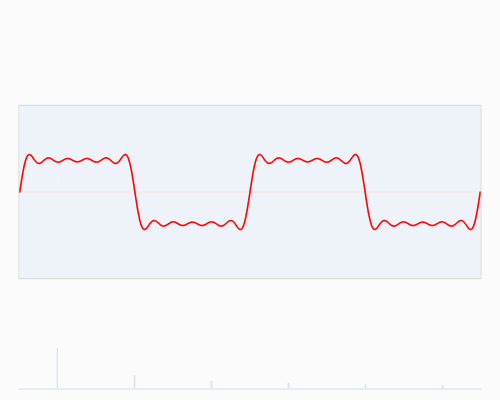
將時域信號轉變成頻域信號
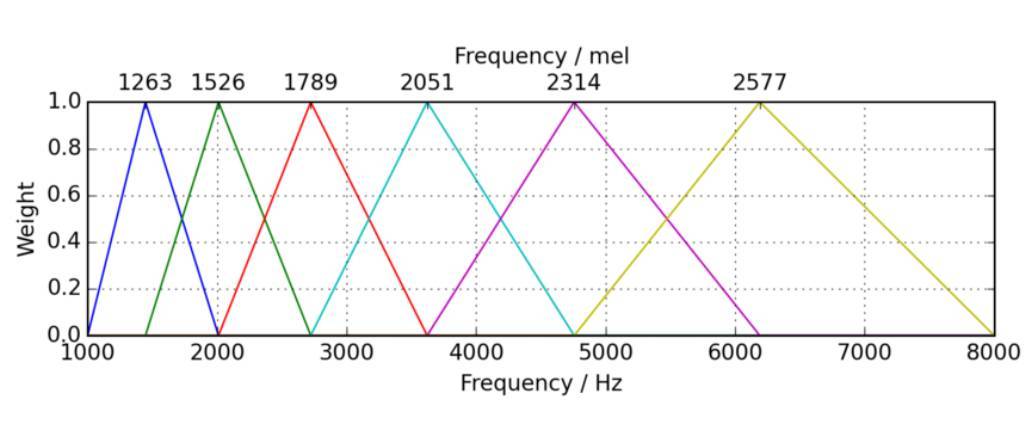
現在我們取剛剛計算得到的頻率信號的能譜,然後在能譜上應用梅爾濾波器組。這很簡單,就像將每個濾波器中的能量求和一樣。與待測音調的實際音高(通常意義上的 Hz 頻率)相比,梅爾頻率與預調的感知頻率更加相關;我們對低頻聲音的微小變化比高頻聲音信號更加敏感。對能譜使用這種 Mel 濾波器組,更接近於人類的實際的聽覺感知。
然後我們對每一個濾波器得到的能量求對數,這是由於人類對響度的聽覺感知並不是線性的。意味着,如果一段聲音剛開始就很響,那麼之後音量上的大的變化聽起來也不會那麼不同。
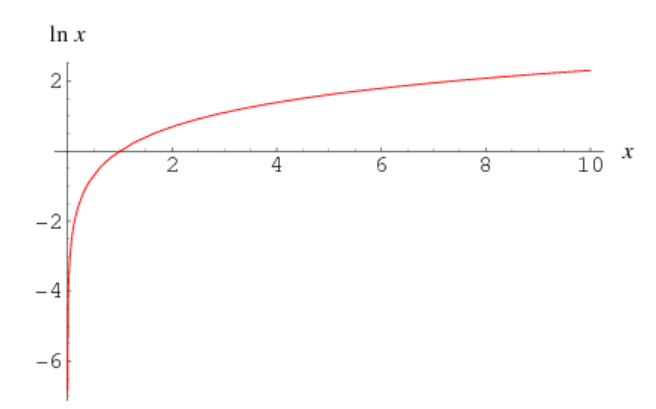
自然對數函數圖像
最後一步就是計算一個被稱爲倒譜的量。倒譜就是譜的譜。就是給梅爾濾波器組處理過的能譜的對數進行離散餘弦變換(DCT),這爲我們給出了能譜的週期性規律,可以從中看到頻率本身是如何快速變化的。離散餘弦變換(DCT)和離散傅里葉變換 (DFT) 類似,只是它返回的是實數(浮點類型)而不是具有虛部的複數。
雖然對 MFCC 做一個概述也是很好的,所幸 Python 中的 libora 庫允許我們只用一行代碼就能計算出特徵,這要比本文的作者描述的過程稍微簡潔一些。
importlibrosa
sample_rate = 44100
mfcc_size = 13
# Load the audio
pcm_data, _ = librosa.load(file_path)
# Compute a vector of n * 13 mfccs
mfccs = librosa.feature.mfcc(pcm_data,
sample_rate,
n_mfcc=mfcc_size)
使用 Librosa 計算 MFCC。
Wavnet 和神經音頻合成(NSynth)
Google 的 Magenta 項目是一個針對這個問題的小組:機器學習能夠被用來創造引人注目的藝術和音樂嗎?巧妙地避開了可計算的創新性中的未定義、空洞的問題之後,他們設計出了一些很酷的生成工具,可以生成多種形式的媒體,例如圖像和音樂。

圖爲 Wavenet 的擴張一維卷積(dilated one dimensional convolutions)
Deepmind(Google 的另一個子公司)創建了一個令人印象深刻的神經網絡,它叫做 Wavenet。Magenta 將這個生成模型轉變成了一個自動編碼器,創建了新的網絡即 NSynth。
你可能之前沒有接觸過自動編碼器,它們只是一種簡單的神經網絡,經常被用在無監督學習中。自動編碼器的通常目標是學習到對某個數據的高效編碼,通常是爲了降維,而且越來越多地用在生成模型中。自動編碼器的共同特徵是它的結構;它由兩部分組成—編碼器和解碼器。通常(但不是全部),解碼器的權重和偏置是編碼器的相關參數的轉置。
正如我所提到的,自動編碼器的目標經常是將輸入壓縮到一個更小的隱變量。然而,這裏的 Z 是一個低維向量,即輸入音頻的一個函數。
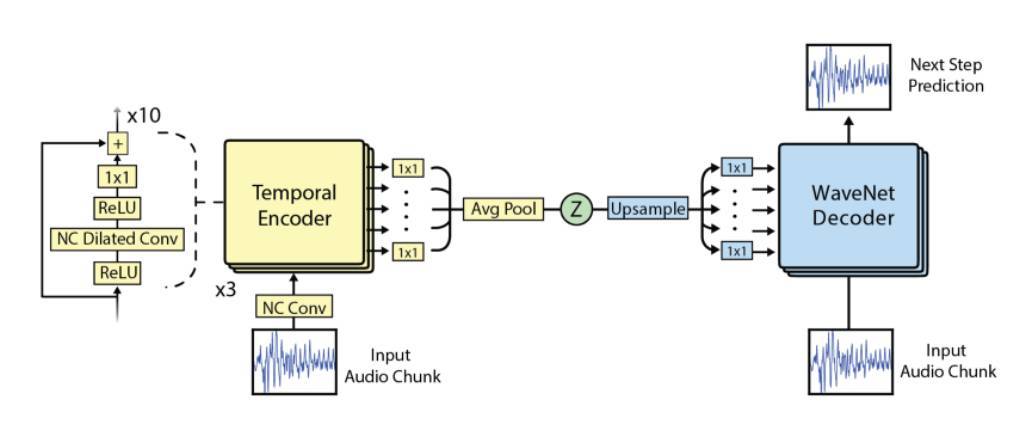
NSynth 的架構。注意,左邊還是像 Wavenet 一樣的擴張卷積。這個項目利用的低維向量 Z 大概在編碼器和解碼器的中間。
使用這個網絡是很簡單的。首先,安裝 Magneta(TensorFlow 的代碼),然後下載這個模型的權值(http://download.magenta.tensorflow.org/models/nsynth/wavenet-ckpt.tar)。下面的代碼將會從壓縮原始信號信息的網絡中得到隱藏狀態的向量化序列。
frommagenta.models.nsynth importutils
frommagenta.models.nsynth.wavenet importfastgen
defwavenet_encode(file_path):
# Load the model weights.
checkpoint_path = './wavenet-ckpt/model.ckpt-200000'
# Load and downsample the audio.
neural_sample_rate = 16000
audio = utils.load_audio(file_path,
sample_length=400000,
sr=neural_sample_rate)
# Pass the audio through the first half of the autoencoder,
# to get a list of latent variables that describe the sound.
# Note that it would be quicker to pass a batch of audio
# to fastgen.
encoding = fastgen.encode(audio, checkpoint_path, len(audio))
# Reshape to a single sound.
returnencoding.reshape((-1, 16))
# An array of n * 16 frames.
wavenet_z_data = wavenet_encode(file_path)
特徵預處理
這個數據集中的所有樣本都具有不同的大小,在下面的控制檯輸出的第五列中可以看到。
ls -lah ./audio_dataset/
...
-rw-rw-r-- 1tollie tollie 3.8MJun282014HAL9K - LongSustainedNote.wav
-rw-rw-r-- 1tollie tollie 2.7MJul22014HAL9K - LostSoul.wav
-rw-rw-r-- 1tollie tollie 7.5MJun292014HAL9K - LowLongTail.wav
-rw-rw-r-- 1tollie tollie 3.8MJun282014HAL9K - LowShort.wav
-rw-rw-r-- 1tollie tollie 4.6MJun282014HAL9K - LowThump.wav
-rw-rw-r-- 1tollie tollie 4.6MJul22014HAL9K - Lute1.wav
-rw-rw-r-- 1tollie tollie 7.7MJul22014HAL9K - Lute2.wav
-rw-rw-r-- 1tollie tollie 4.9MJun282014HAL9K - Mechatronic.wav
-rw-rw-r-- 1tollie tollie 2.4MJun282014HAL9K - Metal+ Delay.wav
-rw-rw-r-- 1tollie tollie 4.8MJun282014HAL9K - MetallicHiss.wav
-rw-rw-r-- 1tollie tollie 5.7MJun282014HAL9K - MysteriousRevelation.wav
-rw-rw-r-- 1tollie tollie 5.7MJul22014HAL9K - Piercing.wav
-rw-rw-r-- 1tollie tollie 2.0MJun282014HAL9K - Room237.wav
-rw-rw-r-- 1tollie tollie 2.7MJun282014HAL9K - SciFi1.wav
-rw-rw-r-- 1tollie tollie 4.1MJun282014HAL9K - SciFi2.wav
當我們爲這些樣本計算特徵的時候,不管是 MFCCs 還是 NSYTH,樣本大小不一導致最終的特徵序列的長度也不同。可以這麼說,我們在這個項目中面臨的問題是取可變長度的特徵,將它們壓縮爲一系列的數字向量,最終得到能夠較好描述這段聲音的向量。
最後,每段聲音的特徵向量會是以下三部分的拼接。首先是平均特徵,它給我們提供了一段聲音的特徵序列中的平均值。這意味着,每一個維度的特徵都被計算了平均值。對於 MFCCs 而言,平均特徵的維度是 13,NSynth 是 16。
第二部分是所得特徵中每一維的標準差。它和平均特徵有一樣的大小(維度),它告訴了我們特徵分佈的擴展。
最後一部分是相鄰兩幀特徵之間的一階差分的均值。這一部分反映了特徵隨時間變化的平均值。同樣,該值在 MFCCs 對應的維度是 13,Nsynth 是 16。
對特徵的這種拼接意味着,從端到端的角度,對於任意長度的任意樣本而言,都能將它壓縮到一個固定長度的特徵,如果使用 MFCCs,那麼這個特徵的維度就是 39,如果使用的是基於 Wavenet 的網絡,那麼這個特徵的維度就是 48。給定一個任意長度和特徵維度的 numpy 數組,對其計算某個長度的特徵向量的代碼如下所示:
importnumpy asnp
# Create some random MFCC shaped features as a sequence of 10 values
feature_sequence = np.random.random((10, 13))
# Get the standard deviation
stddev_features = np.std(feature_sequence, axis=0)
# Get the mean
mean_features = np.mean(feature_sequence, axis=0)
# Get the average difference of the features
average_difference_features = np.zeros((16,))
fori inrange(0, len(feature_sequence) - 2, 2):
average_difference_features += feature_sequence[i] - feature_sequence[i+1]
average_difference_features /= (len(feature_sequence) // 2)
average_difference_features = np.array(average_difference_features)
# Concatenate the features to a single feature vector
concat_features_features = np.hstack((stddev_features, mean_features))
concat_features_features = np.hstack((concat_features_features, average_difference_features))
PCA
降維算法的首選是標準的線性代數算法--主成分分析。我想起了 Rebecca Fiebrink 博士,他教過一個很棒的機器學習課程(https://www.kadenze.com/courses/machine-learning-for-musicians-and-artists/info),他曾斥責像我一樣的機器學習菜鳥在搞清楚簡單算法(例如 PCA)之前就直接跳到更復雜的算法(例如 t-SNE)上去。
PCA 通過最大化數據方差的同時降低數據的維度。它將數據轉換成線性不相關的變量(就是所謂的主成分)。假設我們想得到這些數據的二維圖,那麼我們就會使用具有最大方差的兩個主成分來揭示數據中的結構。如果你想更深一層地理解它,可以看一下我寫的關於用 numpy 來進行線性代數算法的實現及其解釋。
我們可以很容易地實現特徵的 PCA 計算:
fromsklearn.decomposition importPCA
fromsklearn.preprocessing importMinMaxScaler
defget_pca(features):
pca = PCA(n_components=2)
transformed = pca.fit(features).transform(features)
scaler = MinMaxScaler()
scaler.fit(transformed)
returnscaler.transform(transformed)
my_array_of_feature_vectors = ...
scaled_pca = get_pca(my_array_of_feature_vectors)
注意,最後的輸出是進行縮放了的。我們將會在繪製的每一副圖中這樣做,從而可以在我們的交互式網頁應用圖中插入結果。
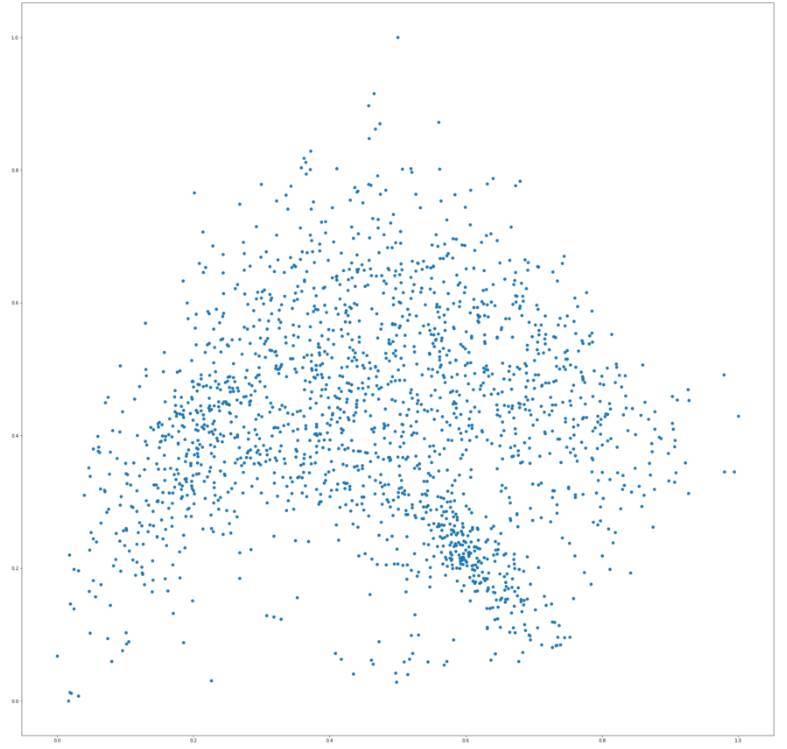
那麼,最後的圖長什麼樣呢?我們實際上有兩個數據集,一個是基於 Wavenet 的特徵,另一個是 MFCC 導出的特徵。所以下面的二維圖中的每一個點都代表一個音頻文件。這是基於 Wavenet 的特徵圖:
這是 MFCCs 的特徵圖:
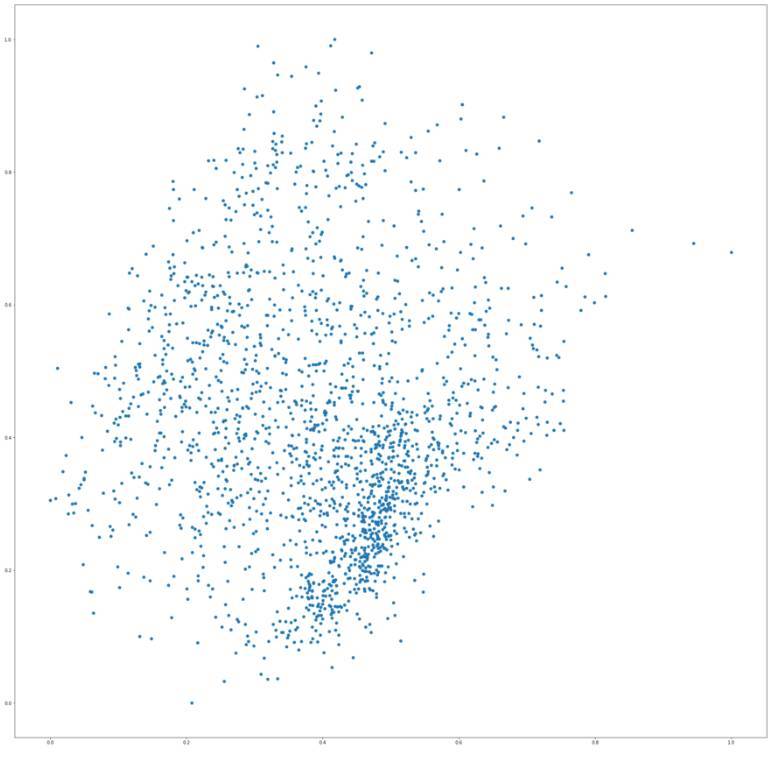
有趣的是,這兩張圖在兩種類似的樣本上都有一小部分的聚集,就是踢球的聲音或者短暫的敲擊聲,通常在這種信號中有着低能量的末尾。估計這兩種特徵向量能夠較好地區分這種類型的聲音。
在這兩張圖上我們可以粗略總結,y 軸代表的是頻率;如果你嘗試在網頁應用的圖上從上至下移動鼠標,踩鈸等高頻聲音出現在上邊,敲擊等低頻聲音出現在下面,同時,中等能量的鼓掌等聲音出現在中間部分。
t-SNE
下一個降維算法是 t 分佈的隨機近鄰嵌入(t-SNE/t-Distributed Neighbour Embedding),這個算法是由 Laurens van der Maaten 和神經網絡先驅 Geoffrey Hinton 共同設計的。
t-SNE 算法有兩個階段。它首先在高維對象對中構造一個概率分佈,這樣就更有可能找到相似的對象。爲了獲得這些高維對象的低維表徵,它爲低維映射構造了一個類似的概率分佈。然後兩個概率分佈之間的散度被最小化。這個散度,或者是相對熵,被稱作 KL 散度。
用 Sklearn 計算 t-SNE 向量很容易。
fromsklearn.manifold importTSNE
fromsklearn.preprocessing importMinMaxScaler
defget_scaled_tsne_embeddings(features, perplexity, iteration):
embedding = TSNE(n_components=2,
perplexity=perplexity,
n_iter=iteration).fit_transform(features)
scaler = MinMaxScaler()
scaler.fit(embedding)
returnscaler.transform(embedding)
tnse_embeddings_mfccs = []
tnse_embeddings_wavenet = []
perplexities = [2, 5, 30, 50, 100]
iterations = [200, 500, 1000, 2000, 5000]
forperplexity inperplexities:
foriteration initerations:
tsne_mfccs = get_scaled_tsne_embeddings(mfcc_features,
perplexity,
iteration)
tnse_wavenet = get_scaled_tsne_embeddings(wavenet_features,
perplexity,
iteration)
t-SNE 函數只需要一小部分參數,這裏有很棒的解釋:https://distill.pub/2016/misread-tsne/。但我在這裏還是做一個簡單的解釋吧。這個算法的第一個參數就是困惑度(perplexity),它是一個在其他流形學習算法中關於最近鄰數目的參數。每一列的困惑度都會變化。另一個參數是迭代量,它指的是 t-SNE 應該優化多少次。迭代量會在每個相連的行中相繼增加。迭代量對圖的影響很大,使用 Wavenet 特徵,我們可以在下圖可以看到:
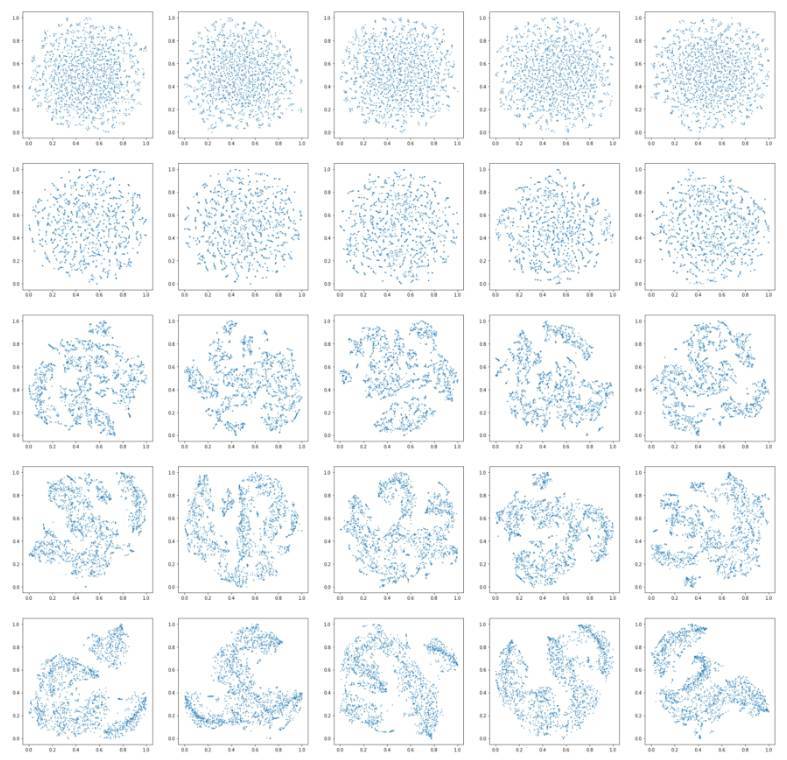
基於 MFCC 特徵的圖在下面:
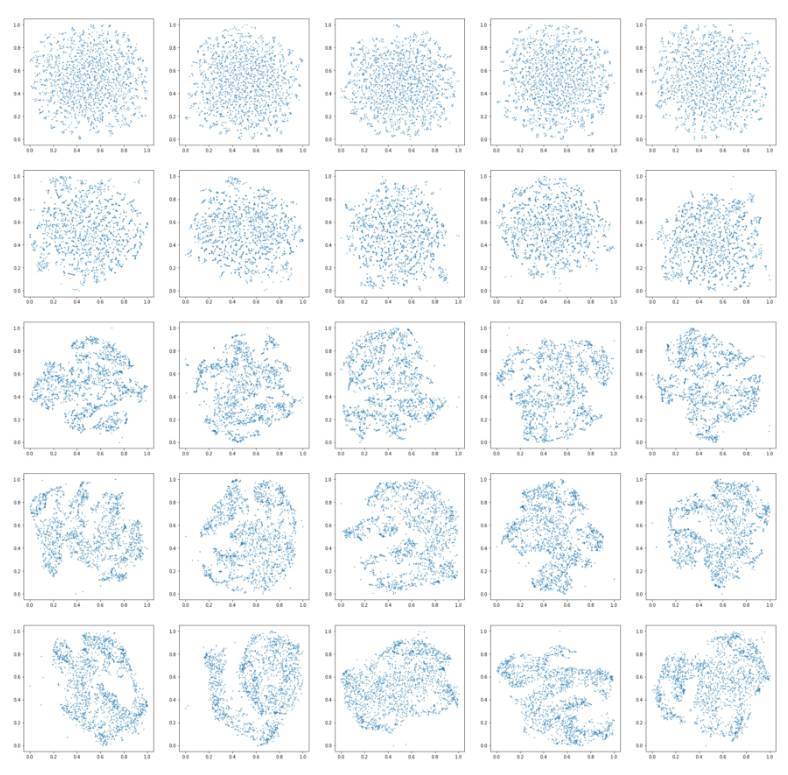
顯而易見,對於兩個特徵數據集而言,當迭代量太小的時候,最終的解並沒有得到充足的優化(兩幅大圖中的第一行就是這樣的情形)。在 distill 中關於有效使用 t-SNE 的文章中特別地指出了這一點。
在更多次數的迭代時,出現了一些聲音的聚類。然而,對於兩個特徵集而言,有時候局部的結構沒有相似的聲音。而全局結構經常能夠表現出聲音的趨勢--也就是說,圖中的一大部分中,大多數是敲擊聲,而另一部分是踩鈸等聲音。困惑度貌似對算法沒有很大的影響,這在相關文獻以及 sklearn 的文檔中都有很好的表述。
UMAP
均勻流形近似和投影(UMAP/uniform manifold approximation and projection)是一種降維技術。它已經產生了一些相當激動人心的結果,我強烈建議你用一下。在 github 頁面(https://github.com/lmcinnes/umap)上是這麼描述的:
UMAP 是建立在對數據的三種假設之上:
數據在黎曼流形上是均勻分佈的;
黎曼度量是局部恆定的(或者說是近似恆定的);
流形是局部連續的(不是全局,而是局部);
基於這些假設,可以使用一個模糊拓撲結構對流形進行建模。通過搜索具有最大可能的等價模糊拓撲結構的數據的低維投影可以找到向量。
umap 的使用是很簡單的,因爲它的功能設計和 sklearn 的 t-SNE 包很類似。下面是分別爲 Wavenet 特徵和 MFCC 特徵創建向量的代碼。
importumap
fromsklearn.preprocessing importMinMaxScaler
defget_scaled_umap_embeddings(features, neighbour, distance):
embedding = umap.UMAP(n_neighbors=neighbour,
min_dist=distance,
metric='correlation').fit_transform(features)
scaler = MinMaxScaler()
scaler.fit(embedding)
returnscaler.transform(embedding)
umap_embeddings_mfccs = []
umap_embeddings_wavenet = []
neighbours = [5, 10, 15, 30, 50]
distances = [0.000, 0.001, 0.01, 0.1, 0.5]
forneighbour inneighbours:
fordistance indistances:
umap_mfccs = get_scaled_umap_embeddings(mfcc_features,
neighbour,
distance)
umap_wavenet = get_scaled_umap_embeddings(wavenet_features,
neighbour,
distance)
我還是將得到的向量縮放到 0 和 1 之間,因爲圖像需要在每個向量之間插入。向量中,縮放並不是重點,就像在 t-SNE 中一樣,唯一重要的是和一個點近鄰的其它點。在代碼中,我們可以再一次看到,一些列表嵌套 for 循環來參數化 UMAP 函數,所以我們可以看到它是如何影響向量的。請注意,列表最左邊和最右邊的參數設置是不好的參數,作者只是希望看到算法如何運行這樣的參數。
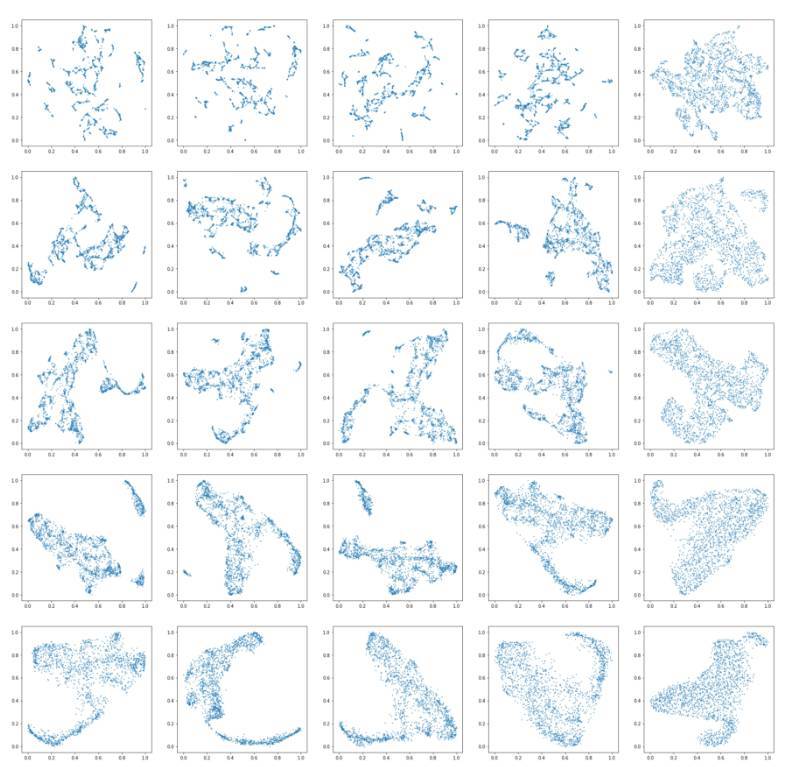
Wavenet 特徵得到的結果的圖像很漂亮,具有有趣的全局結構和局部結構。每一列中爲算法給定的近鄰數量是一樣的,從一系列取值中選擇 [5,10,15,30,50]。流形結構的局部近似中具有較大數目的近鄰點會導致較好的全局結構,但是會損失局部結構。每一行分別對應着設置好的最小距離參數 [0.000,0.001,0.01,0.1,0.5],這個參數控制着向量可以將數據點壓縮到多近。較大的數值保證了數據更均勻的數據分佈,而更小的值會確保更精確的局部結構。
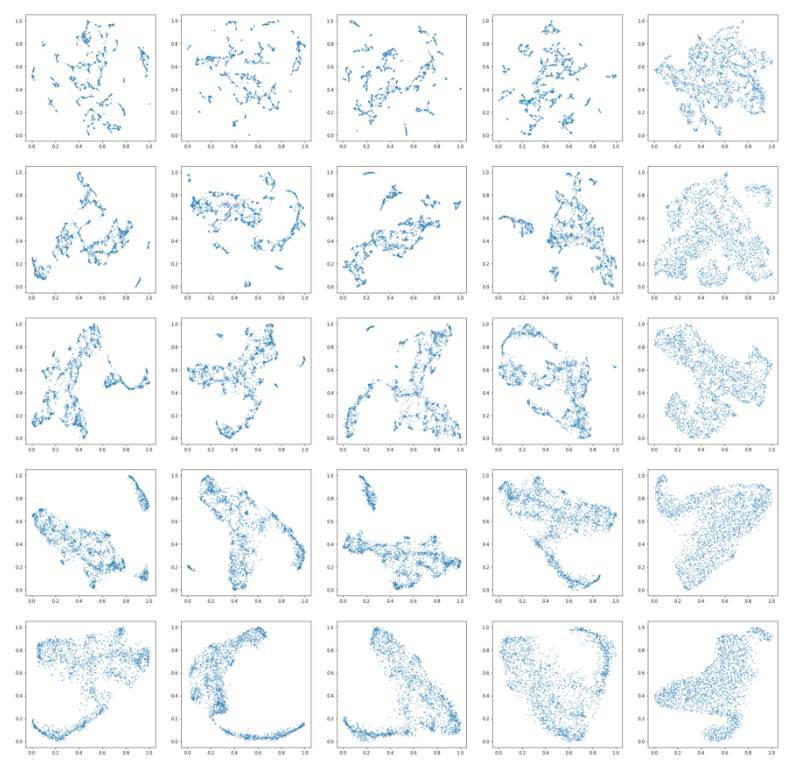
MFCC 特徵對應的圖也是一樣的好看。
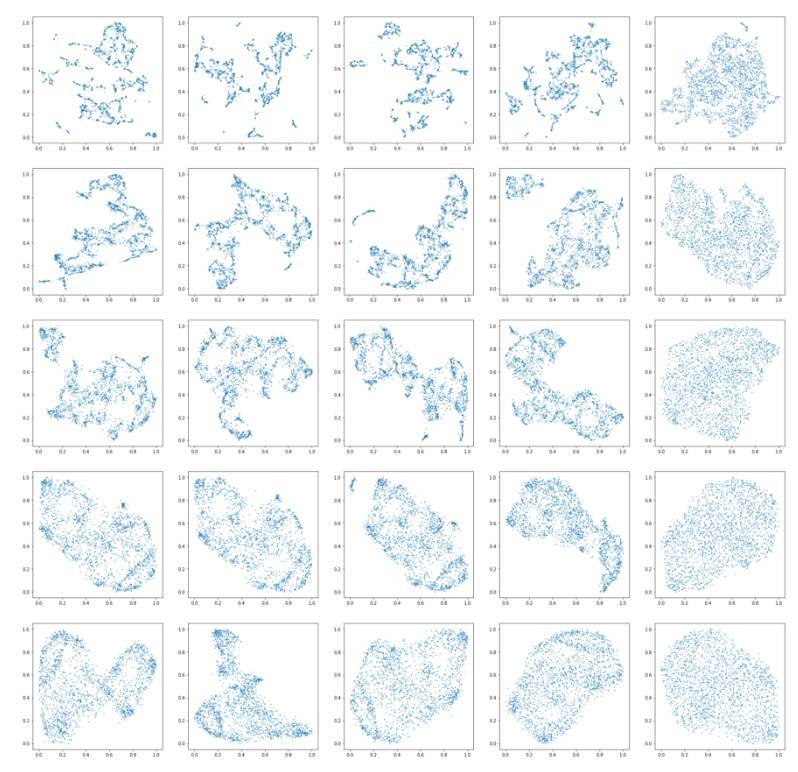
圖中引人注目的是在較低的參數設置下出現的局部結構,相反,當兩個參數設置都很高時會出現全局結構。在參數設置相同時,基於 Wavenet 的特徵比基於 MFCC 的特徵能夠更好地保持局部結構。
在交互演示中,以近鄰數和距離滑塊較小的設置下(1 或者 2)在局部結構中嘗試移動鼠標,你應該能夠注意到這個算法能夠正確地將這些聲音聚類在一起。
總結
在很大程度上,每個算法都是有用的,並且參數化算法和繪製兩組特徵的輸出是非常有用的。一個值得注意的說法是關於圖的解釋性。PCA 似乎是這個領域中最強大的算法,因爲它相對簡單。容易注意到,y 軸或多或少包含了樣本的高頻成分,這是一個很好的啓示。
確保 UMAP 的距離不是很高,並且近鄰數也在一個較低的水平時,可以確定 UMAP 的局部結構是很好的。通常那些擁有較高感知相似度的樣本會出現少量的線和聚類。將參數倒過來,換成較大的近鄰數和最小的距離數目,這意味着在算法中結合了更多的全局結構,全局結構更加具有說服力,而且從經驗上來說,要比 t-SNE 和 PCA 的結構更強大。
Wavenet 特徵的結果證明,在和降維技術結合的時候,這些特徵確實很魯棒,很可靠。與 MFCC 特徵得到的圖相比時,聚類中並沒有明顯的退化,在其他情況下,與具有相同參數設置的 MFCC 相比,使用 Wavenet 向量實際上還改善了最終得到的圖。
原文鏈接:https://medium.com/@LeonFedden/comparative-audio-analysis-with-wavenet-mfccs-umap-t-sne-and-pca-cb8237bfce2f