目錄
1.目錄
2.引言
first-visit 蒙特卡洛
3.蒙特卡洛動作值
4.蒙特卡洛控制
探索開始
在策略:ϵ-貪婪策略
ϵ-貪婪收斂
離策略:重要度採樣
離策略標記法
普通重要度採樣
加權重要度採樣
增量實現
其它:可感知折扣的重要度採樣
其它:預獎勵重要度採樣
5.用 Python 實現的在策略模型
示例:Blackjack
示例:Cliff Walking
6.總結
之前我們討論過馬爾可夫決策過程(MDP,參閱 https://goo.gl/wVotRL)以及尋找最優的動作-價值函數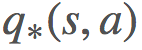 和
和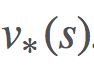 的算法。我們使用了策略迭代和價值迭代來求解最優策略。
的算法。我們使用了策略迭代和價值迭代來求解最優策略。
有用於強化學習的動態編程解決方案是挺好的,但這也有很多限制。比如是否存在很多你知道狀態轉移概率的真實世界問題?你能一開始就從任意狀態起步嗎?你的 MDP 是否是有限的?
那麼,我認爲你會很樂意瞭解蒙特卡洛方法。這是一種可近似困難的概率分佈的經典方法,可以解決你對動態編程解決方案的所有擔憂!
同樣,我們會按照 Richard Sutton 的強化學習教材《Reinforcement Learning: An Introduction》進行講解,並會給出一些該書中沒有的額外解釋和示例。
引言
蒙特卡洛模擬(Monte Carlo simulations)得名於摩納哥的賭城,因爲機率和隨機結果是這種建模技術的核心,所以它就像是輪盤賭、骰子和老虎機等遊戲一樣。
相比於動態編程,蒙特卡洛方法會以一種全新的方式看待問題。其提出的問題是:我需要從環境中獲取多少樣本才能將好策略與差策略區分開?
這時候,我們需要重新引入「回報(return)」的概念,這是指長期運行的期望增益:
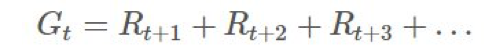
有時候,如果 episode 有持續有限時間的非零概率,那麼我們將使用一個折扣因子:
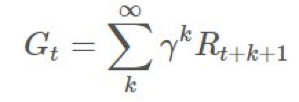
我們將這些回報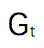 與可能的
與可能的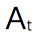 關聯起來,以推導某種類型的:
關聯起來,以推導某種類型的:
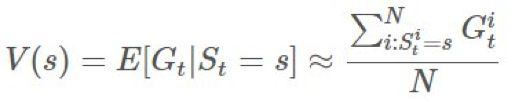
根據大數定律,當 N 趨近 ∞ 時,我們可以得到確切的期望。我們用 i 指代第 i 次模擬。
現在,如果這是一個 MDP(99% 的強化學習問題都是),那麼我們知道其會表現出強馬爾可夫性(Strong Markov Property),即:
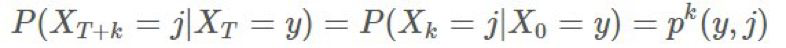
使用這個性質,我們可以輕鬆推導出這個事實:期望中的 t 是完全無關的,從現在起我們將使用 Gs 來表示從某個狀態(將該狀態移至 t=0)開始的回報。
first-visit 蒙特卡洛
求解價值函數的一種經典方法是採樣 s 的第一次出現的回報,這種方法被稱爲 first-visit 蒙特卡洛預測。然後可用下面的算法找到最優的 V:
pi = init_pi()returns = defaultdict(list)for i in range(NUM_ITER): episode = generate_episode(pi) # (1) G = np.zeros(|S|) prev_reward = 0 for (state, reward) in reversed(episode): reward += GAMMA * prev_reward # backing up replaces s eventually, # so we get first-visit reward. G[s] = reward prev_reward = reward for state in STATES: returns[state].append(state)V = { state : np.mean(ret) for state, ret in returns.items() }
另一種方法被稱爲 every-visit 蒙特卡洛預測,其中我們在每個 episode 中都會採樣 s 的每次出現的回報。在這兩種情況下,估計結果都會以二次方式收斂到期望。
蒙特卡洛動作值
有時候,我們並不知道環境的模型,即我們不知道怎樣的動作會導致怎樣的狀態,以及環境一般的交互方式。在這種情況下,我們可以使用動作值而非狀態值,也就是說我們求解的是 q∗
我們希望估計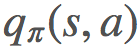 而非
而非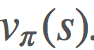 。將 G[s] 簡單地改成 G[s,a] 似乎很恰當,事實也確實如此。一個顯然的問題是:現在我們從 S 空間變成了 S×A 空間,這會大很多,而且我們仍然需要對其進行採樣以找到每個狀態-動作元組的期望回報。
。將 G[s] 簡單地改成 G[s,a] 似乎很恰當,事實也確實如此。一個顯然的問題是:現在我們從 S 空間變成了 S×A 空間,這會大很多,而且我們仍然需要對其進行採樣以找到每個狀態-動作元組的期望回報。
另一個問題是,隨着搜索空間增大,如果我們在我們的策略方面過快地變得貪婪,那就越來越有可能我們也許無法探索所有的狀態-動作對。我們需要適當地混合探索(exploration)和利用(exploitation)。我將在下一節解釋我們克服這一問題的方法。
蒙特卡洛控制
回想一下來自馬爾可夫決策過程的策略迭代。這種情況沒有太大的差別。我們仍然固定我們的 π,尋找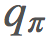 ,然後尋找一個新的 π′ 再繼續。大致過程就像這樣:
,然後尋找一個新的 π′ 再繼續。大致過程就像這樣:
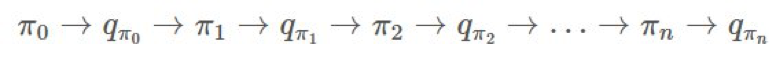
我們尋找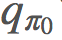 的方式類似於上面我們尋找 v 的方式。我們可以通過貝爾曼最優性方程(Bellman optimality equation)的定義改善我們的 π,簡單來說就是:
的方式類似於上面我們尋找 v 的方式。我們可以通過貝爾曼最優性方程(Bellman optimality equation)的定義改善我們的 π,簡單來說就是:
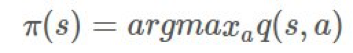
有關於此的更多詳情請參閱之前的馬爾可夫決策過程相關博文。
現在,在蒙特卡洛方法的語境中,策略迭代的核心關鍵是:我們如何確保探索與利用的情況?
探索開始
一種彌補大型狀態空間探索的方法是指定我們從一個特定的狀態開始,然後採取一個特定的動作,再在所有可能性上循環以採樣它們的回報。這假設我們可以從任意狀態開始,然後在每個 episode 開始時採取所有可能的動作;這在很多情況下都不是合理的假設。但是,對於二十一點(BlackJack)這樣的問題,這是完全合理的,這意味着我們可以輕鬆解決我們的問題。
在代碼中,我們只需要給我們 (1) 處的代碼加個小補丁即可:
# Before (Start at some arbitrary s_0, a_0)episode = generate_episode(pi)# After (Start at some specific s, a)episode = generate_episode(pi, s, a) # loop through s, a at every iteration.
在策略:ϵ-貪婪策略
所以,如果我們不能假設我們可以從任何任意狀態開始和採取任意動作,又如何呢?那麼只要我們不太貪婪並且多次無限地探索所有狀態,那麼我們就可以確保收斂,是這樣嗎?
上述內容本質上是在策略(on-policy)方法的主要特性之一。在策略方法是要試圖改善當前正在運行試驗的策略,而離策略(off-policy)方法則是想試圖提升不同於當前運行試驗的策略的另一個策略。
有了這個說法,我們需要形式化「不太貪婪」。一種簡單方法是使用所謂的「k-搖臂賭博機- ϵ-貪婪方法(k-armed bandits - ϵ-greedy methods)」!簡單來說,給定一個狀態,我們有 ϵ 概率會從所有動作的均勻分佈中選取,有 1-ϵ 的概率選取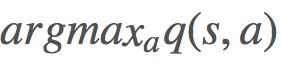 動作。
動作。
現在我們的問題是:這會收斂到蒙特卡洛方法的最優 π∗ 嗎?答案是:會收斂,但不會收斂到那個策略。
ϵ-貪婪收斂
我們從 q 和一個 ϵ-貪婪策略 π′(s) 開始。
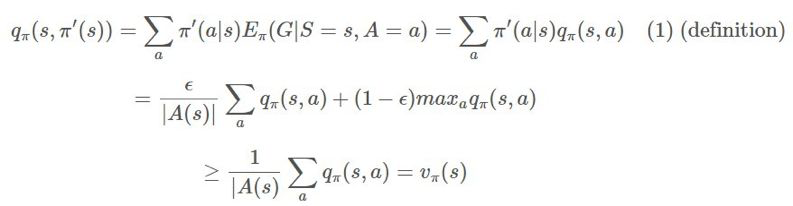
同樣,我們可以這樣陳述:這個 ϵ 貪婪策略,就像任何貪婪策略一樣,會在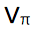 上執行單調的提升。如果我們支持所有時間步驟,那麼會得到:
上執行單調的提升。如果我們支持所有時間步驟,那麼會得到:
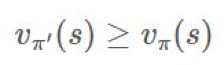
這就是我們收斂所需的。
但是,我們需要找到這一策略實際會收斂到的位置。很顯然,即使最優策略是確定性,因爲我們迫使我們的策略是隨機的,所以無法保證收斂到 π∗。但是,我們可以重構我們的問題:
假設不再讓我們的策略具有以概率 ϵ 均勻選擇動作的隨機性,而是讓我們的策略具有能隨機選取動作而不管策略如何規定的環境。那麼,我們就可以保證有最優解。其證明的大致過程是,在 (1) 中,如果等式成立,那麼我們有 π=π′,因此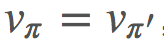 ,則由於該環境的設置,方程在隨機性下是最優的。
,則由於該環境的設置,方程在隨機性下是最優的。
離策略:重要度採樣
1).離策略標記法
現在介紹一些新術語!
π 是我們的目標策略(target policy)。我們試圖優化這個策略的期望回報。
b 是我們的行爲策略(behavioral policy)。我們使用 b 來生成 π 之後會用到的數據。
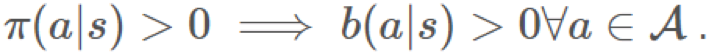 這是覆蓋率(coverage)的概念。
這是覆蓋率(coverage)的概念。
離策略方法通常有 2 個或更多智能體,其中一個會生成數據,以讓另一個智能體在這些數據上進行優化。我們將它們分別稱爲行爲策略和目標策略。離策略方法比在策略方法更「炫酷」,就像神經網絡比線性模型更「炫酷」一樣。類似地,離策略方法通常更加強大,但也有模型的方差更高和收斂更慢的問題。
現在我們來談談重要度採樣(importance sampling)。
重要度採樣回答的是這個問題:「給定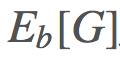 ,則
,則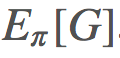 是怎樣的?」換句話說,你該怎樣使用你從 b 的採樣得到的信息來確定來自 π 的期望結果?
是怎樣的?」換句話說,你該怎樣使用你從 b 的採樣得到的信息來確定來自 π 的期望結果?
你可以用這種直觀的方式思考它:「如果 b 選擇 a 很多次且 π 也選擇 a 很多次,則 b 的行爲對確定 π 的行爲而言應該是重要的。」反過來講:「如果 b 選擇 a 很多次且 π 從未選擇 a,則 b 在 a 上的行爲對 π 在 a 上的行爲而言應該沒有任何重要性。」有道理,對不對?
這差不多就是重要度採樣比(importance-sampling ratio)的意思了。給定一個軌跡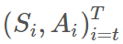 ,這個確切軌跡在給定策略 π 時的概率爲:
,這個確切軌跡在給定策略 π 時的概率爲:
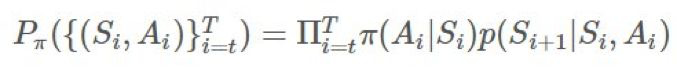
π 和 b 之間的比即爲:
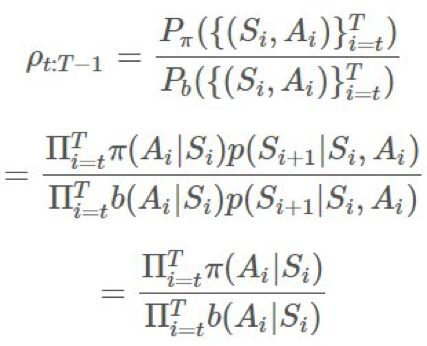
2).普通重要度採樣
現在,有很多可以利用這個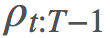 的方法,以給我們提供一個
的方法,以給我們提供一個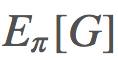 的優良估計。最基本的方法是使用被稱爲普通重要度採樣(ordinary importance sampling)的技術。假設我們有采樣得到的 N 個 episode:
的優良估計。最基本的方法是使用被稱爲普通重要度採樣(ordinary importance sampling)的技術。假設我們有采樣得到的 N 個 episode:
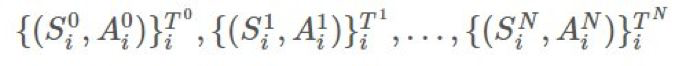
並將 s 的第一次到達時間表示爲:
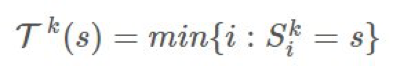
我們想要估計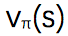 ,然後我們可以通過 first-visit 方法使用實驗的均值來估計價值函數:
,然後我們可以通過 first-visit 方法使用實驗的均值來估計價值函數:
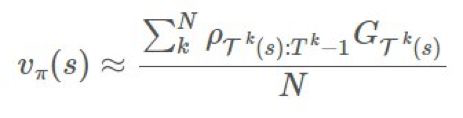
當然,這可以輕鬆泛化成一種 every-visit 方法,但我只想呈現最簡單的形式,理解要點就行了。也就是說,我們需要以不同的方式給每個 episode 的回報加權,因爲對於 π 來說,更有可能發生的軌跡應該比永遠不會發生的軌跡有更大的權重。
重要度採樣方法是一種無偏差估計器(unbiased estimator),但它有極端方差問題(extreme variance problems)的麻煩。假設某第 k 個 episode 的重要度比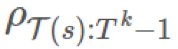 是 1000。這是個很大的比值,但絕對有可能發生。這是否意味着獎勵必然會多 1000 倍?如果我們只有 1 個 episode,我們的估計就會是那樣。在長期運行時,因爲我們有乘法關係,所以這個比值可能要麼會爆炸,要麼就會消失。這對估計的目的而言是有一點問題的。
是 1000。這是個很大的比值,但絕對有可能發生。這是否意味着獎勵必然會多 1000 倍?如果我們只有 1 個 episode,我們的估計就會是那樣。在長期運行時,因爲我們有乘法關係,所以這個比值可能要麼會爆炸,要麼就會消失。這對估計的目的而言是有一點問題的。
3).加權重要度採樣
爲了降低方差,降低估計的幅度是一種簡單又直觀的方法,具體做法是除以所有重要度比的幅度的總和(有點類似於一個 softmax 函數):
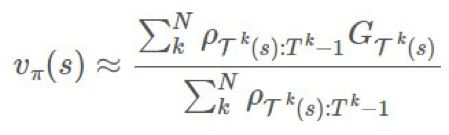
這被稱爲加權重要度採樣(weighted importance sampling)。這是一種有偏差估計(其偏差會漸漸向 0 趨近),但方差更小。在此之前,人們可以爲普通估計器提出糟糕的無界方差(unbounded variance),但這裏的每一項的最大權重都爲 1,這限制了方差的上界。Sutton 建議說,在實踐中,總是使用加權的重要度採樣。
4).增量實現
和很多采樣技術一樣,我們可以增量地實現它。假設我們使用了前一節介紹的加權重要度採樣方法,那麼我們可以有一些這種形式的採樣算法:
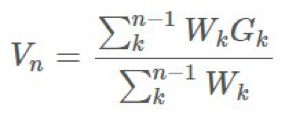
其中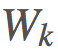 是我們的權重。
是我們的權重。
我們希望基於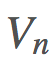 構建
構建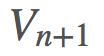 ,這是非常可行的。用
,這是非常可行的。用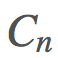 表示
表示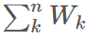 ,則我們可以保持這個運行總和的更新,即:
,則我們可以保持這個運行總和的更新,即:
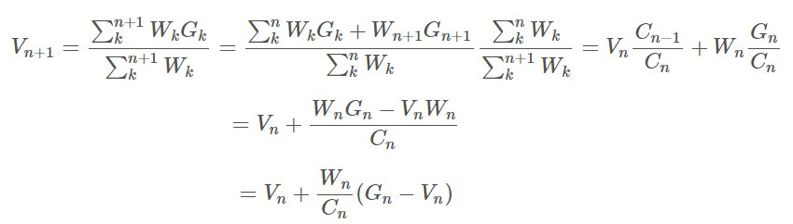
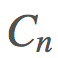 的更新規則相當明顯:
的更新規則相當明顯: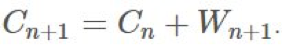 現在,
現在,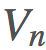 是我們的價值函數,但在我們的動作值
是我們的價值函數,但在我們的動作值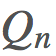 上也可以應用一個非常類似的類比。
上也可以應用一個非常類似的類比。
在我們更新價值函數的同時,我們也可以更新我們的策略 π。我們可以使用古老又好用的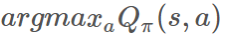 更新我們的 π。
更新我們的 π。
警告:前方有大量數學內容。目前已有的信息實際已經夠用了,但下面的介紹會讓我們更接近現代的研究課題。
5).其它:可感知折扣的重要度採樣
到目前爲止,我們已經統計了回報,並且採樣了回報以得到我們的估計。但是,我們忽略了 G 的內部結構。它實際上只是折扣獎勵的和,而且我們無法將其整合進我們的比值 ρ 中。可感知折扣的重要度採樣(discount-aware importance sampling)模型 γ 是一種終止概率,即 episode 在某個時間步驟 t 終止的概率,因此必然是一個幾何分佈 ∼geo(γ):
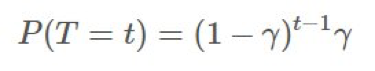
而完全回報可被視爲是在隨機變量 的隨機數上的期望:
的隨機數上的期望:
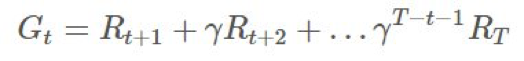
可以這樣構建一個任意伸縮和(telescoping sum):
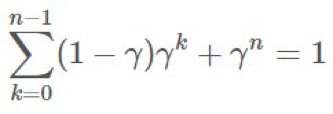
歸納起來,我們可以看到對於從 x 開始的 k,我們有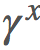 。
。
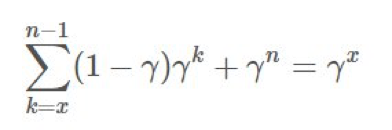
將其代入 G 中:
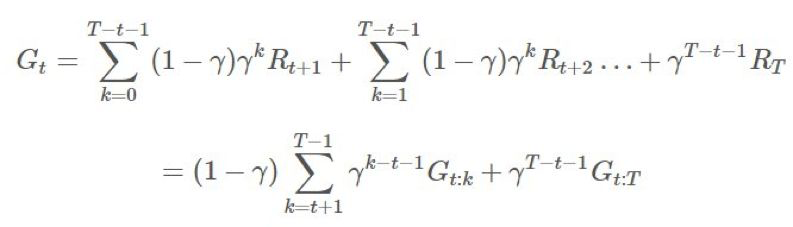
這將導致在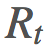 項上的等效係數爲 1、γ、γ2。這意味着我們現在可將
項上的等效係數爲 1、γ、γ2。這意味着我們現在可將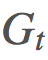 分解成不同的部分並在重要度採樣比上應用折扣。
分解成不同的部分並在重要度採樣比上應用折扣。
現在回想一下,之前我們有:
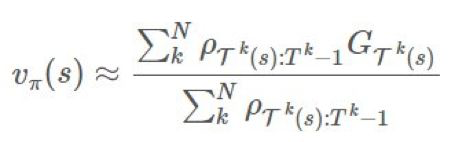 (加權重要度採樣)
(加權重要度採樣)
如果我們擴展 G,我們會有,總和中的一個分子爲:
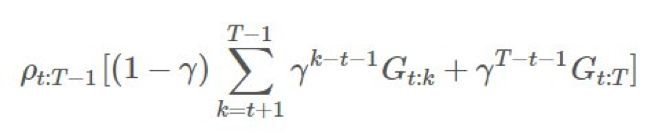
注意我們在所有回報上應用同一比值的方式。其中某些回報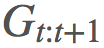 乘上了整個軌跡的重要度比,這在「γ 是終止概率」的建模假設下是「不正確的」。直觀來看,我們希望
乘上了整個軌跡的重要度比,這在「γ 是終止概率」的建模假設下是「不正確的」。直觀來看,我們希望
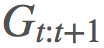 有
有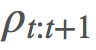 ,這是很簡單的:
,這是很簡單的:
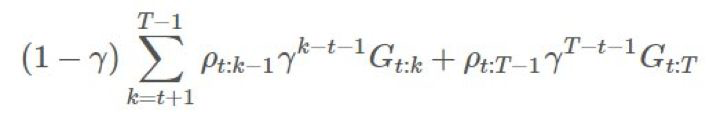
這樣就好多了!這樣,每一部分回報都會有自己合適的比。這能極大地消除無界方差問題。
6).其它:預獎勵重要度採樣
這是另一種緩解有問題的 ρ 及其方差問題的方法,我們可以將 G 分解成它各自的回報並執行一些分析。來看一看: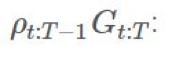 :
:
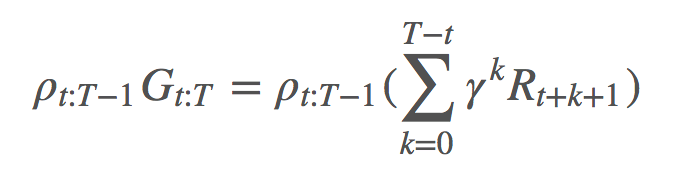 對於每一項,我們有
對於每一項,我們有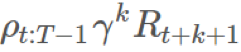 。擴展 ρ,我們可以看到:
。擴展 ρ,我們可以看到:
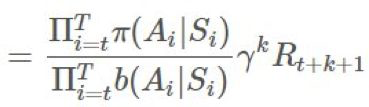
取沒有恆定的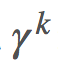 的期望:
的期望:
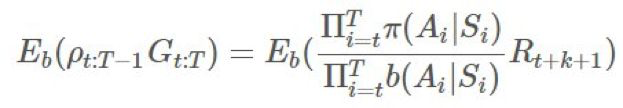
回想一下,當且僅當它們獨立時,你只能取 E(AB)=E(A)E(B)。根據馬爾可夫性質,很顯然如果 i≥t+k+1 且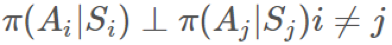 ,那麼任何
,那麼任何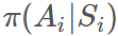 和
和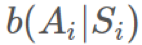 獨立於
獨立於
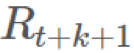 (對 b 的情況也一樣)。我們可以將它們取出,然後得到:
(對 b 的情況也一樣)。我們可以將它們取出,然後得到:
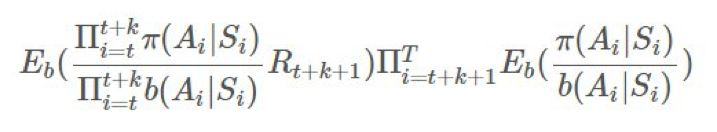
這可能看起來很醜陋,但可以觀察到:
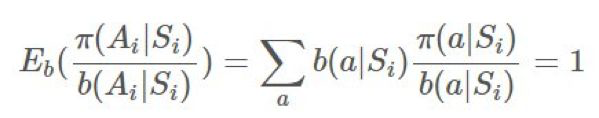
因此我們實際上可以完全忽略後半部分:
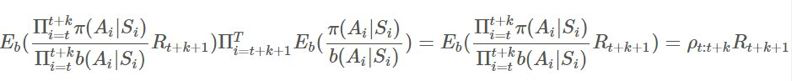
這意味着什麼?我們實際上可以用期望表示我們原來的和:
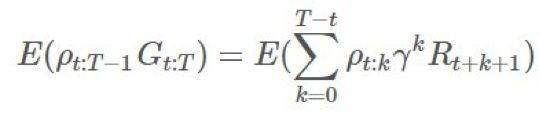
然後這又能再次降低我們的估計器的方差。
用 Python 實現的在策略模型
因爲蒙特卡洛方法一般都有相似的結構,所以我用 Python 做了一個離散的蒙特卡洛模型類,而且是可以即插即用的。你也可以在這裏找到這些代碼:https://github.com/OneRaynyDay/MonteCarloEngine。這已經經過了文檔測試(doctest)。
"""General purpose Monte Carlo model for training on-policy methods."""from copy import deepcopyimport numpy as npclass FiniteMCModel: def __init__(self, state_space, action_space, gamma=1.0, epsilon=0.1): """MCModel takes in state_space and action_space (finite) Arguments --------- state_space: int OR list[observation], where observation is any hashable type from env's obs. action_space: int OR list[action], where action is any hashable type from env's actions. gamma: float, discounting factor. epsilon: float, epsilon-greedy parameter. If the parameter is an int, then we generate a list, and otherwise we generate a dictionary. >>> m = FiniteMCModel(2,3,epsilon=0) >>> m.Q [[0, 0, 0], [0, 0, 0]] >>> m.Q[0][1] = 1 >>> m.Q [[0, 1, 0], [0, 0, 0]] >>> m.pi(1, 0) 1 >>> m.pi(1, 1) 0 >>> d = m.generate_returns([(0,0,0), (0,1,1), (1,0,1)]) >>> assert(d == {(1, 0): 1, (0, 1): 2, (0, 0): 2}) >>> m.choose_action(m.pi, 1) 0 """ self.gamma = gamma self.epsilon = epsilon self.Q = None if isinstance(action_space, int): self.action_space = np.arange(action_space) actions = [0]*action_space # Action representation self._act_rep = "list" else: self.action_space = action_space actions = {k:0 for k in action_space} self._act_rep = "dict" if isinstance(state_space, int): self.state_space = np.arange(state_space) self.Q = [deepcopy(actions) for _ in range(state_space)] else: self.state_space = state_space self.Q = {k:deepcopy(actions) for k in state_space} # Frequency of state/action. self.Ql = deepcopy(self.Q) def pi(self, action, state): """pi(a,s,A,V) := pi(a|s) We take the argmax_a of Q(s,a). q[s] = [q(s,0), q(s,1), ...] """ if self._act_rep == "list": if action == np.argmax(self.Q[state]): return 1 return 0 elif self._act_rep == "dict": if action == max(self.Q[state], key=self.Q[state].get): return 1 return 0 def b(self, action, state): """b(a,s,A) := b(a|s) Sometimes you can only use a subset of the action space given the state. Randomly selects an action from a uniform distribution. """ return self.epsilon/len(self.action_space) + (1-self.epsilon) * self.pi(action, state) def generate_returns(self, ep): """Backup on returns per time period in an epoch Arguments --------- ep: [(observation, action, reward)], an episode trajectory in chronological order. """ G = {} # return on state C = 0 # cumulative reward for tpl in reversed(ep): observation, action, reward = tpl G[(observation, action)] = C = reward + self.gamma*C return G def choose_action(self, policy, state): """Uses specified policy to select an action randomly given the state. Arguments --------- policy: function, can be self.pi, or self.b, or another custom policy. state: observation of the environment. """ probs = [policy(a, state) for a in self.action_space] return np.random.choice(self.action_space, p=probs) def update_Q(self, ep): """Performs a action-value update. Arguments --------- ep: [(observation, action, reward)], an episode trajectory in chronological order. """ # Generate returns, return ratio G = self.generate_returns(ep) for s in G: state, action = s q = self.Q[state][action] self.Ql[state][action] += 1 N = self.Ql[state][action] self.Q[state][action] = q * N/(N+1) + G[s]/(N+1) def score(self, env, policy, n_samples=1000): """Evaluates a specific policy with regards to the env. Arguments --------- env: an openai gym env, or anything that follows the api. policy: a function, could be self.pi, self.b, etc. """ rewards = [] for _ in range(n_samples): observation = env.reset() cum_rewards = 0 while True: action = self.choose_action(policy, observation) observation, reward, done, _ = env.step(action) cum_rewards += reward if done: rewards.append(cum_rewards) break return np.mean(rewards)if __name__ == "__main__": import doctest doctest.testmod()
如果你想在不同的 gym 使用它,你就要自己動手試試看。
示例:Blackjack(二十一點)
我們在這個示例中使用了 OpenAI 的 gym。在這裏,我們使用了一個衰減的 ϵ-貪婪策略來求解 Blackjack。
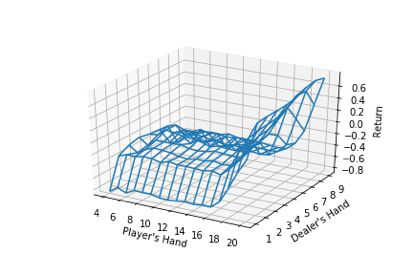
import gymenv = gym.make("Blackjack-v0")# The typical importsimport gymimport numpy as npimport matplotlib.pyplot as pltfrom mc import FiniteMCModel as MCeps = 1000000S = [(x, y, z) for x in range(4,22) for y in range(1,11) for z in [True,False]]A = 2m = MC(S, A, epsilon=1)for i in range(1, eps+1): ep = [] observation = env.reset() while True: # Choosing behavior policy action = m.choose_action(m.b, observation) # Run simulation next_observation, reward, done, _ = env.step(action) ep.append((observation, action, reward)) observation = next_observation if done: break m.update_Q(ep) # Decaying epsilon, reach optimal policy m.epsilon = max((eps-i)/eps, 0.1)print("Final expected returns : {}".format(m.score(env, m.pi, n_samples=10000)))# plot a 3D wireframe like in the example mplot3d/wire3d_demoX = np.arange(4, 21)Y = np.arange(1, 10)Z = np.array([np.array([m.Q[(x, y, False)][0] for x in X]) for y in Y])X, Y = np.meshgrid(X, Y)from mpl_toolkits.mplot3d.axes3d import Axes3Dfig = plt.figure()ax = fig.add_subplot(111, projection='3d')ax.plot_wireframe(X, Y, Z, rstride=1, cstride=1)ax.set_xlabel("Player's Hand")ax.set_ylabel("Dealer's Hand")ax.set_zlabel("Return")plt.savefig("blackjackpolicy.png")plt.show()
我們得到了一個看起來相當不錯的圖表,因爲此時沒有可用的王牌(因此 Z 中使用了 False 來繪製網格圖)。
我也寫了一個該模型的快速離策略版本,但還尚待完善,因爲我只是想得出一個表現基準。下面是結果:
Iterations: 100/1k/10k/100k/1million.Tested on 10k samples for expected returns.On-policy : greedy-0.1636-0.1063-0.0648-0.0458-0.0312On-policy : eps-greedy with eps=0.3-0.2152-0.1774-0.1248-0.1268-0.1148Off-policy weighted importance sampling:-0.2393-0.1347-0.1176-0.0813-0.072
因此,看起來離策略的重要度採樣可能更難以收斂,但最終結果比 ϵ-貪婪策略好。
示例:Cliff Walking
所需的代碼修改實際上很少,因爲正如我之前提到的那樣,蒙特卡洛採樣受環境的影響相當小。我們只需要修改這部分代碼(去除繪圖部分):
# Before: Blackjack-v0env = gym.make("CliffWalking-v0")# Before: [(x, y, z) for x in range(4,22) for y in range(1,11) for z in [True,False]]S = 4*12 # Before: 2A = 4
然後我們運行這個 gym,Eπ(G) 得到 -17.0。還不錯!在 Cliff Walking 問題中,一張地圖中有的模塊是懸崖,其它的是平臺。每一步時,你走在平臺上的獎勵是 -1,掉下懸崖的獎勵是 -100。每當你走在懸崖模塊上時,你都要回到開始位置。對於這麼大的地圖,每 episode -17.0 是接近最優的策略。
總結
對於任意具有「奇怪的」動作或觀察空間概率分佈的任務而言,蒙特卡洛方法在計算最優價值函數和動作價值方面是一種非常好的技術。我們未來還將介紹蒙特卡洛方法的更好變體,但這篇文章也能爲你學習強化學習提供很好的基礎知識。
原文鏈接:https://oneraynyday.github.io/ml/2018/05/24/Reinforcement-Learning-Monte-Carlo/