選自tryolabs
2017 年即將結束,又到了總結的時刻。本文作者把範圍限定爲機器學習,盤點了 2017 年以來最受歡迎的十大 Python 庫;同時在這十個非常流行與強大的 Python 庫之外,本文還給出了一些同樣值得關注的 Python 庫,如 PyVips 和 skorch。
十二月是靜靜坐下來總結過去一年成就的時候。對程序員來說,則通常是回顧那些今年推出的開源庫,或者由於其極好地解決了一個特定問題而最近變的大爲流行的開源庫。
過去兩年來,我們一直通過發表博文的方式做這件事,指出當年 Python 社區中出現的一些最佳工作。現在,2017 年即將結束,又到了總結的時刻。
但是這次開源庫的評選限定在了機器學習的範圍內。也許非機器學習庫的大牛認爲我們有偏見,懇請你們原諒。很希望讀者在評論中對本文做出反饋,幫助我們查缺補遺未收錄的頂級軟件。
因此,放輕鬆,讓我們開始吧!
1. Pipenv
項目地址:https://github.com/pypa/pipenv
2017 年排名第一的 python 庫非 Pipenv 莫屬。它在今年初發行,但卻影響了每個 Python 開發者的工作流程,尤其是現在它成了用於管理依賴項的官方推薦工具。
Pipenv 源自大牛 Kenneth Reitz 的一個週末項目,旨在把其他軟件包管理器的想法整合進 Python。安裝 virtualenv 和 virtualenvwrapper,管理 requirements.txt 文件,確保依賴項的依賴項版本的可復現性,以上這些統統不需要。藉助 Pipenv,你可以在 Pipfile(通常使用添加、刪除或更新依賴項的命令構建它)中指定所有你的依賴項。Pipenv 可以生成一個 Pipfile.lock 文件,使得你的構建成爲決定性的,避免了尋找 bug 的困難,因爲甚至你也不認爲需要一些模糊的依賴項。
當然,Pipenv 還有很多其他特性,以及很好的文檔,因此確保檢查完畢,再開始在所有你的 Python 項目上使用它。
2. PyTorch
項目地址:http://pytorch.org/
如果有一個庫在今年特別是在深度學習社區中大爲流行,那麼它很可能是 PyTorch。PyTorch 是 Facebook 今年推出的深度學習框架。
PyTorch 構建在 Torch 框架之上,並對這個(曾經?)流行框架做了改善,尤其是 PyTorch 是基於 Python 的,這與 Lua 形成鮮明對比。鑑於過去幾年人們一直在使用 Python 進行數據科學研究,這爲深度學習的普及邁出了重要一步。
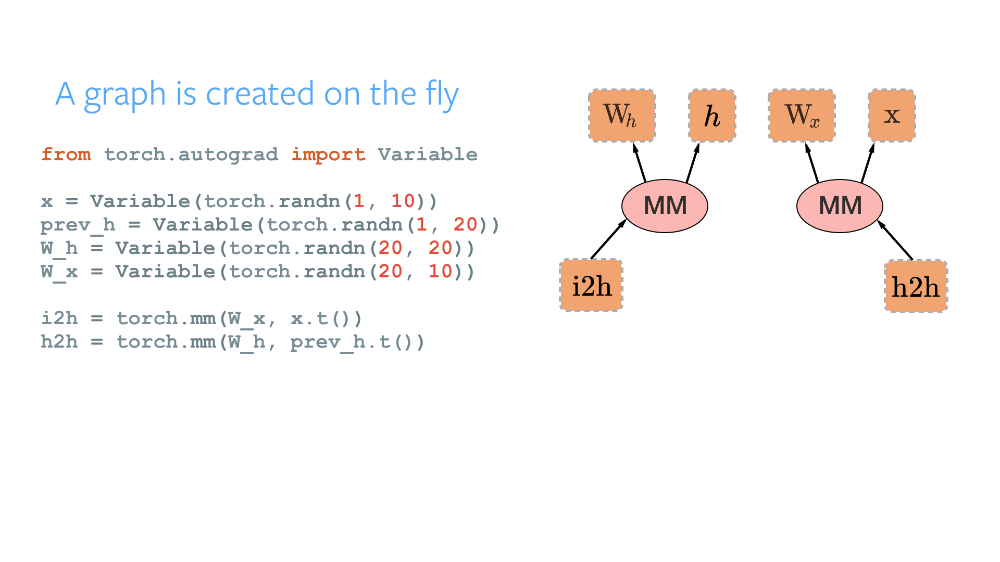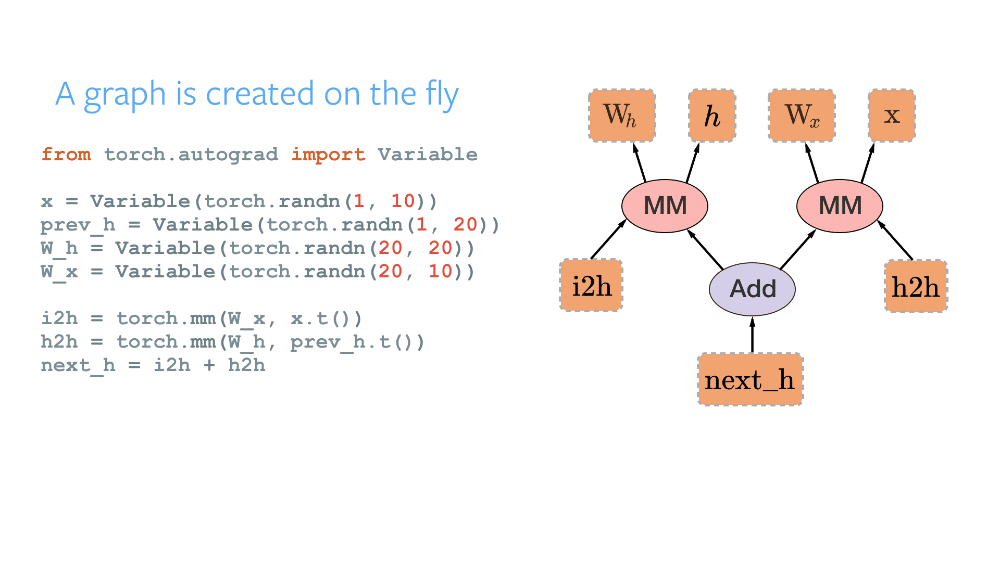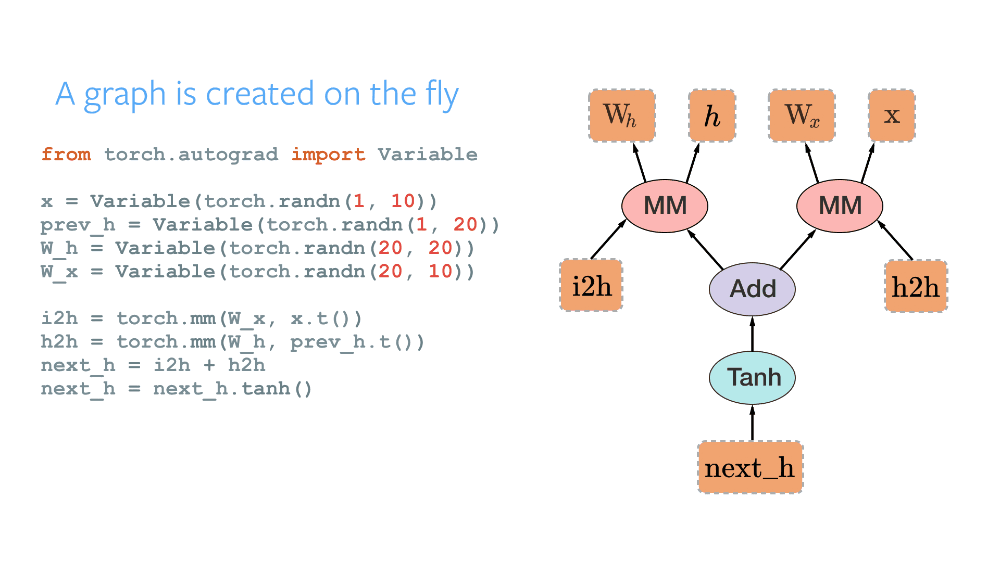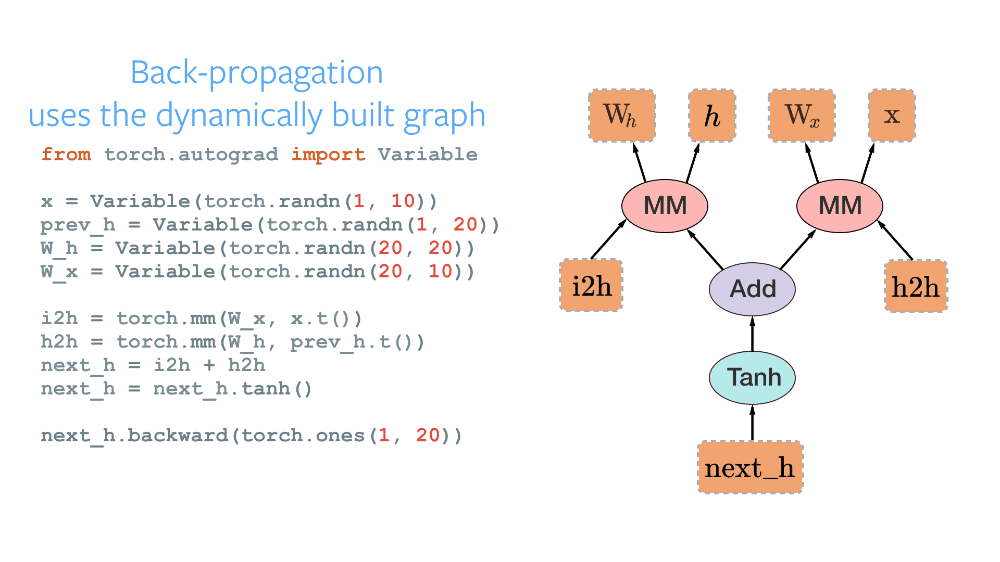
最值得注意的是,由於其實現了全新的動態計算圖(Dynamic Computational Graph)範式,PyTorch 成爲了衆多研究者的首選框架之一。當使用其他框架比如 TensorFlow、CNTK、MXNet 編寫代碼時,必須首先定義一個稱之爲計算圖的東西。該圖指定了由我們的代碼構建的所有操作與數據流,且它在構建完後會進行編譯和利用框架潛在地優化,因此靜態計算圖能很自然地在 GPU 上實現並行處理。這一範式被稱爲靜態計算圖,它很棒,因爲你可以利用各種優化,並且這個圖一旦建成即可運行在不同設備上(因爲執行與構建相分離)。但是,在很多任務中比如自然語言處理中,工作量經常是變動的:你可以在把圖像饋送至算法之前把其大小重新調整爲一個固定的分辨率,但是相同操作不適用於語句,因爲其長度是變化的。這正是 PyTorch 和動態圖發揮作用的地方。通過在你的代碼中使用標準的 Python 控制指令,圖在執行時將被定義,給了你對完成若干任務來說很關鍵的自由。
當然,PyTorch 也會自動計算梯度(正如你從其他現代深度學習框架中所期望的一樣),這非常快,且可擴展,何不試一試呢?
3. Caffe2
項目地址:https://caffe2.ai/
也許這聽起來有點瘋狂,但是 Facebook 在今年也發佈了另外一個很棒的深度學習框架。原始的 Caffe 框架多年來一直被廣泛使用,以無與倫比的性能和經過測試的代碼庫而聞名。但是,最近的深度學習趨勢使得該框架在一些方向上停滯不前。Caffe2 正是一次幫助 Caffe 趕上潮流的嘗試。

Caffe2 支持分佈式訓練、部署(甚至在移動端平臺)和最新的 CPU、支持 CUDA 的硬件。儘管 PyTorch 更適合於研究,但是 Caffe2 適合大規模部署,正如在 Facebook 上看到的一樣。
同樣,查看最近的 ONNX 工作。你可以在 PyTorch 中構建和訓練你的模型,同時使用 Caffe2 來部署!這是不是很棒?
4. Pendulum
項目地址:https://github.com/sdispater/pendulum
去年,Arrow——一個旨在爲你減負同時使用 Python datatime 的庫入選了榜單;今年,該輪到 Pendulum 了。
Pendulum 的優點之一在於它是 Python 標準 datetime 類的直接替代品,因此你可以輕易地將其與現有代碼整合,並在你真正需要時利用其功能。作者特別注意以確保時間區正確處理,默認每個實例意識到時間區。你也會獲得擴展的 timedelta 來簡化日期時間的計算。
與其他現有庫不同,它努力使 API 具有可預測性行爲,因此知道該期望什麼。如果你正在做一個涉及 datetime 的重要工作,它會使你更開心。查看該文件獲得更多信息:https://pendulum.eustace.io/docs/。
5. Dash
項目地址:https://plot.ly/products/dash/
研究數據科學的時候你可以在 Python 生態系統中使用如 Pandas 和 scikit-learn 等非常棒的工具,還可以使用 Jupyter Notebook 管理工作流程,這對於你和同事之間的協作非常有幫助。但是,當你的分享對象並不知道如何使用這些工具的時候,該怎麼辦?如何建立一個可以讓人們輕鬆地處理數據並進行可視化的接口?過去的辦法是建立一個專業的熟悉 Java 前端設計團隊,以建立所需要的 GUI,沒有其它辦法。
Dash 是幾年發佈的用於構建網頁應用(特別針對於數據可視化的高效利用)的純 Python 開源庫。它建立在 Flask、Plotly.js 和 React 的頂部,可以提供數據處理的抽象層次的接口,從而讓我們不需要再學習這些框架,進行高效的開發。該 app 可在瀏覽器上使用,以後將發佈低延遲版本,以在移動設備上使用。
可以在這個網站中查看 Dash 的有趣應用:https://plot.ly/dash/gallery。
6. PyFlux
項目地址:https://github.com/RJT1990/pyflux
Python 中有很多庫可以用於研究數據科學和機器學習,但是當你的數據點是隨時間演化的度量的時候(例如股價,甚至任何儀器測量值),這就不一樣了。
PyFlux 就是一個專用於處理時序數據的開源 Python 庫。對時序數據的研究是統計學和經濟學的一個子領域,其研究的目的可以是描述時序數據的(關於隱變量或感興趣特徵的)演化行爲,也可以是預測時序數據的未來狀態。
PyFlux 允許使用概率方法對時序數據建模,擁有多種現代時序數據模型的實現,例如 GARCH。
7. Fire
項目地址:https://github.com/google/python-fire
大多數情況下,我們需要爲項目創建一個命令行界面(CLI)。除了傳統的 argparse 之外,Python 還有 clik 和 docopt 等很棒的工具。Fire 是今年穀歌發佈的軟件庫,它在解決這個問題上採取了不同的方法。
Fire 是能爲任何 Python 項目自動生成 CLI 的開源庫。這裏的關鍵點是自動化:我們幾乎不需要編寫任何代碼或文檔來構建 CLI。我們只需要調用一個 Fire 方法並把它傳遞到所希望構建到 CLI 中的目標,例如函數、對象、類、字典或根本不傳遞參數(這樣將會把整體代碼導入 CLI)。
一般我們需要閱讀該項目下的指導手冊,以便通過案例瞭解它是如何工作的。
8. imbalanced-learn
項目地址:https://github.com/scikit-learn-contrib/imbalanced-learn
在理想的情況中,我們總會有完美的平衡數據集,用它來訓練模型將十分舒爽。但不幸的是,在實際中我們總有不平衡的數據集,甚至有些任務擁有非常不平衡的數據。例如,在預測信用卡欺詐的任務中絕大多數交易(99%+)都是合法的,只有極少數的行爲需要算法識別爲欺詐。如果我們只是樸素地訓練 ML 算法,那麼算法的性能可能還不如全都預測爲佔比大的數據,因此在處理這一類問題時我們需要非常小心。
幸運的是,該問題已經經過充分的探討,且目前存在各種各樣的技術以解決不平衡數據。imbalanced-learn 是一個強大的 Python 包,它提供了很多解決數據不平衡的方法。此外,imbalanced-learn 與 scikit-learn 相互兼容,是 scikit-learn-contrib 項目的一部分。
9. FlashText
項目地址:https://github.com/vi3k6i5/flashtext
在大多數數據清理流程或其它工作中,我們可能需要搜索某些文本以替換爲其它內容,通常我們會使用正則表達式完成這一工作。在大多數情況下,正則表達式都能完美地解決這一問題,但有時也會發生這樣的情況:我們需要搜索的項可能是成千上萬條,因此正則表達式的使用將變得十分緩慢。
爲此,FlashText 提供了一個更好的解決方案。在該項目作者最初的基準測試中,它極大地縮短了整個操作的運行時間,從 5 天到 15 分鐘。FlashText 的優點在於不論搜索項有多少,它所需要的運行時都是相同的。而在常用的正則表達式中,運行時將隨着搜索項的增加而線性增長。
# FlashText替代關鍵詞
>>>keyword_processor.add_keyword('New Delhi','NCR region')
>>>new_sentence =keyword_processor.replace_keywords('I love Big Apple and new delhi.')
>>>new_sentence
>>># 'I love New York and NCR region.'
FlashText 證明了算法和數據結構設計的重要性,即使對於簡單的問題,更好的算法也可以輕鬆超越在最快處理器上運行的樸素實現。
10. Luminoth
項目地址:https://luminoth.ai/
如今圖像無處無在,理解圖像的內容對於許多應用程序來說都是至關重要的。值得慶幸的是,由於深度學習的進步,圖像處理技術已經有了非常大的進步。
Luminoth 是用於計算機視覺的開源 Python 工具包,它使用 TensorFlow 和 Sonnet 構建,且目前支持 Faster R-CNN 等目標檢測方法。此外,Luminoth 不僅僅是一個特定模型的實現,它的構建基於模塊化和可擴展,因此我們可以直接定製現有的部分或使用新的模型來擴展它而處理不同的問題,即儘可能對代碼進行復用。

它還提供了一些工具以輕鬆完成構建 DL 模型所需要的工程工作:將數據(圖像等)轉換爲適當的格式以饋送到各種操作流程中,例如執行數據增強、在一個或多個 GPU 中執行訓練(分佈式訓練是訓練大規模模型所必需的)、執行評價度量、在 TensorBoard 中可視化數據或模型和部署模型爲一個簡單的 API 接口等。所以因爲 Luminoth 提供了大量的方法,我們可以通過它完成很多關於計算機視覺的任務。
此外,Luminoth 可以直接與 Google Cloud 的 ML 引擎整合,所以即使我們沒有強大的 GPU,我們也可以在雲端進行訓練。
更多優秀的 Python 庫
除了以上十個非常流行與強大的 Python 庫,今年還有一些同樣值得關注的 Python 庫,包括 PyVips、Requestium 和 skorch 等。
1. PyVips
項目地址:https://github.com/jcupitt/pyvips
你可能還沒聽過 libvips 庫,但你一定聽說過 Pillow 或 ImageMagick 等流行的圖像處理庫,它們支持廣泛的格式。然而相比這些流行的圖像處理庫,libvips 更加快速且只佔很少的內存。例如一些基準測試表明它相比 ImageMagick 在處理速度上要快三倍,且還節省了 15 倍的內存佔用。
PyVips 是最近發佈用於 libvips 的 Python 綁定包,它與 Python 2.7-3.6(甚至是 PyPy)相兼容,它易於使用 pip 安裝。所以如果你需要處理圖像數據的應用,那麼這個庫是我們所需要關注的。
2. skorch
項目地址:https://github.com/dnouri/skorch
假設你很喜歡使用 scikit-learn 的 API,但卻遇到了需要使用 PyTorch 工作的情況,該怎麼辦?別擔心,skorch 是一個封裝,可以通過類似 sklearn 的接口提供 PyTorch 編程。如果你熟悉某些庫,就會希望使用相應的直觀可理解的句法規則。通過 skorch,你可以得到經過抽象的代碼,從而將精力集中於重要的方面。
原文鏈接:https://tryolabs.com/blog/2017/12/19/top-10-python-libraries-of-2017/