將知識圖譜作爲輔助信息引入到推薦系統中可以有效地解決傳統推薦系統存在的稀疏性和冷啓動問題,近幾年有很多研究人員在做相關的工作。目前,將知識圖譜特徵學習應用到推薦系統中主要通過三種方式——依次學習、聯合學習、以及交替學習。
依次學習(one-by-one learning)。首先使用知識圖譜特徵學習得到實體向量和關係向量,然後將這些低維向量引入推薦系統,學習得到用戶向量和物品向量;

聯合學習(joint learning)。將知識圖譜特徵學習和推薦算法的目標函數結合,使用端到端(end-to-end)的方法進行聯合學習;

交替學習(alternate learning)。將知識圖譜特徵學習和推薦算法視爲兩個分離但又相關的任務,使用多任務學習(multi-task learning)的框架進行交替學習。

一、依次學習
Deep Knowledge-Aware Network (DKN)
我們以新聞推薦[1]爲例來介紹依次學習。如下圖所示,新聞標題和正文中通常存在大量的實體,實體間的語義關係可以有效地擴展用戶興趣。然而這種語義關係難以被傳統方法(話題模型、詞向量)發掘。
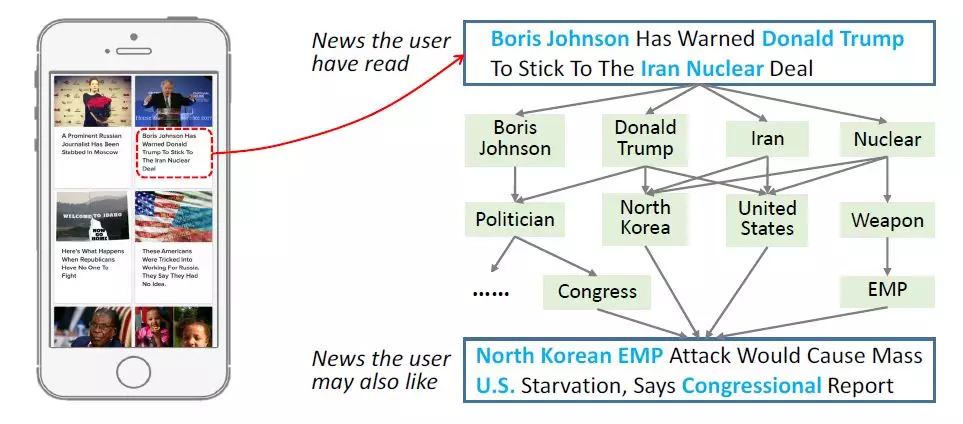
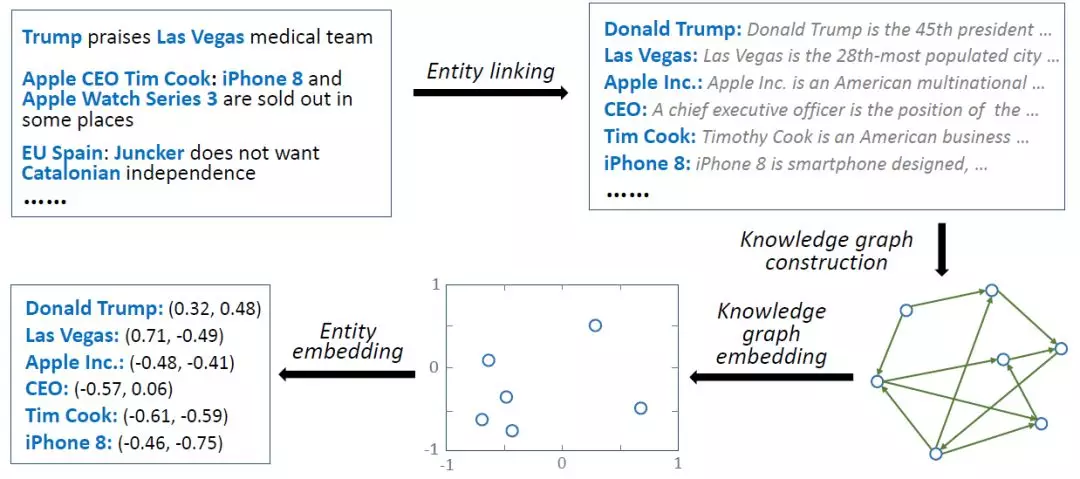
爲了將知識圖譜引入特徵學習,遵循依次學習的框架,我們首先需要提取知識圖譜特徵。該步驟的方法如下:
實體連接(entity linking)。即從文本中發現相關詞彙,並與知識圖譜中的實體進行匹配;
知識圖譜構建。根據所有匹配到的實體,在原始的知識圖譜中抽取子圖。子圖的大小會影響後續算法的運行時間和效果:越大的子圖通常會學習到更好的特徵,但是所需的運行時間越長;
知識圖譜特徵學習。使用知識圖譜特徵學習算法(如TransE等)進行學習得到實體和關係向量。
需要注意的是,爲了更準確地刻畫實體,我們額外地使用一個實體的上下文實體特徵(contextual entity embeddings)。一個實體e的上下文實體是e的所有一跳鄰居節點,e的上下文實體特徵爲e的所有上下文實體特徵的平均值:
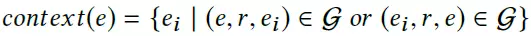
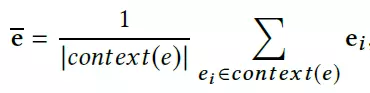
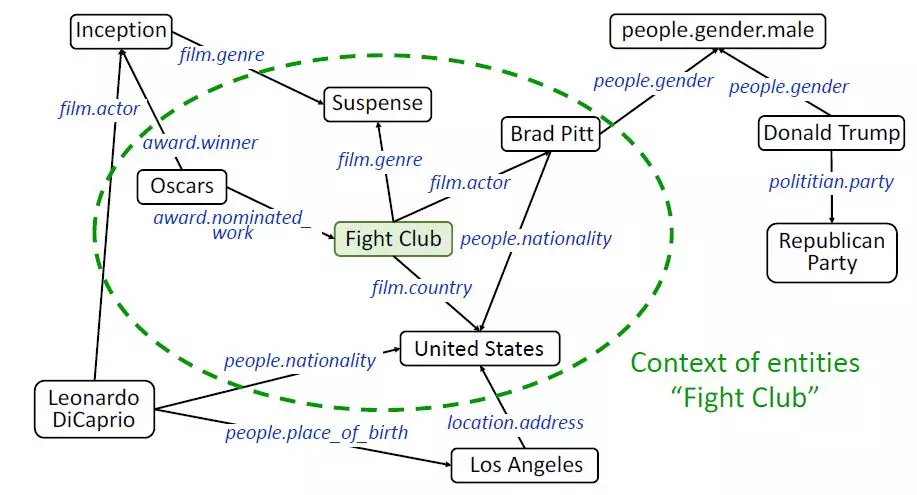
下圖的綠色橢圓框內即爲「Fight Club」的上下文實體。
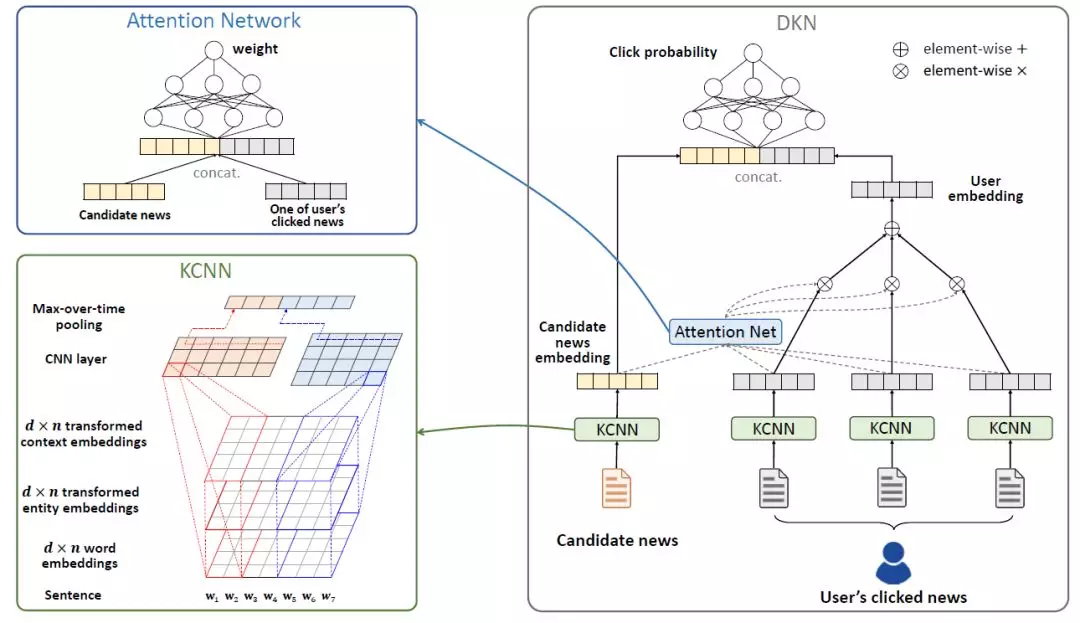
得到實體特徵後,我們的第二步是構建推薦模型,該模型是一個基於CNN和注意力機制的新聞推薦算法:
基於卷積神經網絡的文本特徵提取:將新聞標題的詞向量(word embedding)、實體向量(entity embedding)和實體上下文向量(context embedding)作爲多個通道(類似於圖像中的紅綠藍三通道),在CNN的框架下進行融合;
基於注意力機制的用戶歷史興趣融合:在判斷用戶對當前新聞的興趣時,使用注意力網絡(attention network)給用戶歷史記錄分配不同的權重。
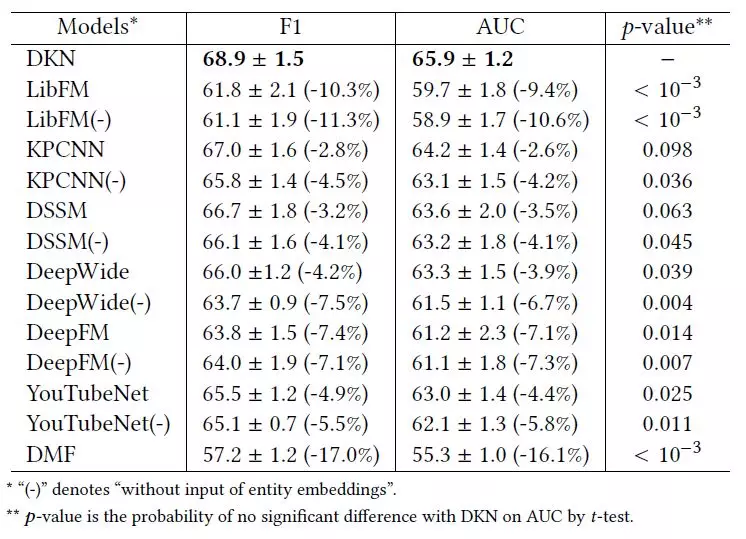
該模型在新聞推薦上取得了很好的效果:DKN取得了0.689的F1值和0.659的AUC值,並在p=0.1水平上比其它方法取得了顯著的提升。
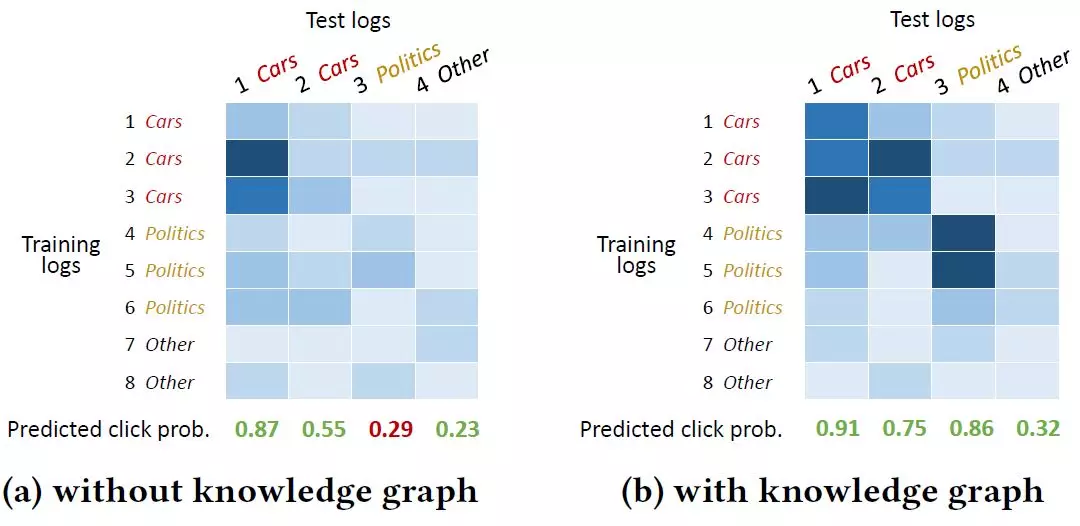
我們也可以通過注意力權重的可視化結果看出,注意力機制的引入對模型的最後輸出產生了積極的影響。由於注意力機制的引入,DKN可以更好地將同類別的新聞聯繫起來,從而提高了最終的正確預測的數量:
依次學習的優勢在於知識圖譜特徵學習模塊和推薦系統模塊相互獨立。在真實場景中,特別是知識圖譜很大的情況下,進行一次知識圖譜特徵學習的時間開銷會很大,而一般而言,知識圖譜遠沒有推薦模塊更新地快。因此我們可以先通過一次訓練得到實體和關係向量,以後每次推薦系統模塊需要更新時都可以直接使用這些向量作爲輸入,而無需重新訓練。
依次學習的缺點也正在於此:因爲兩個模塊相互獨立,所以無法做到端到端的訓練。通常來說,知識圖譜特徵學習得到的向量會更適合於知識圖譜內的任務,比如連接預測、實體分類等,並非完全適合特定的推薦任務。在缺乏推薦模塊的監督信號的情況下,學習得到的實體向量是否真的對推薦任務有幫助,還需要通過進一步的實驗來推斷。
二、聯合學習
聯合學習的核心是將推薦算法和知識圖譜特徵學習的目標融合,並在一個端到端的優化目標中進行訓練。我們以CKE[2]和Ripple Network[3]爲例介紹聯合學習。
Collaborative Knowledge base Embedding (CKE)
在推薦系統中存在着很多與知識圖譜相關的信息,以電影推薦爲例:
結構化知識(structural knowledge),例如導演、類別等;
圖像知識(visual knowledge),例如海報、劇照等;
文本知識(textual knowledge),例如電影描述、影評等。
CKE是一個基於協同過濾和知識圖譜特徵學習的推薦系統:
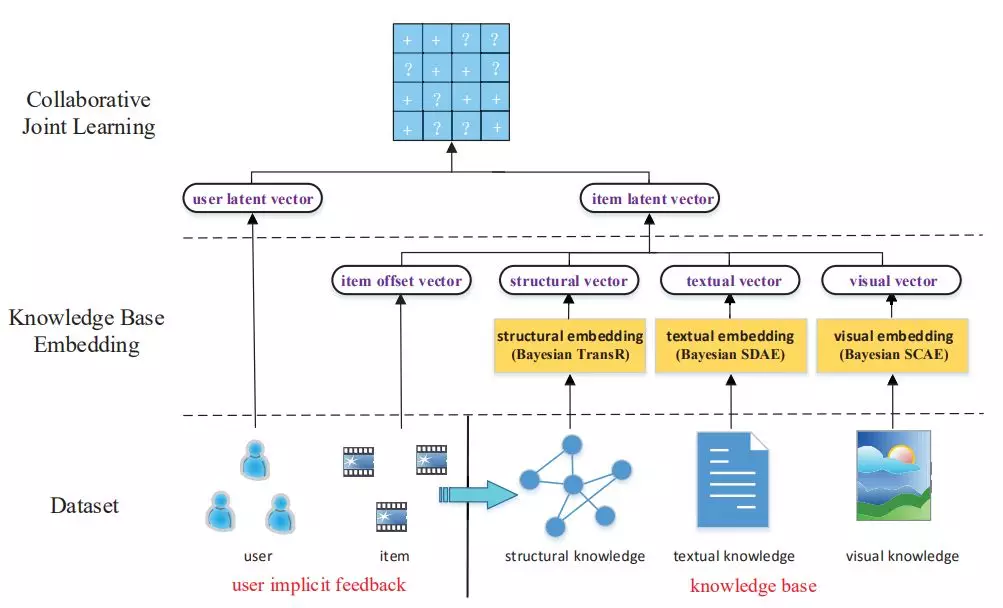
CKE使用如下方式進行三種知識的學習:
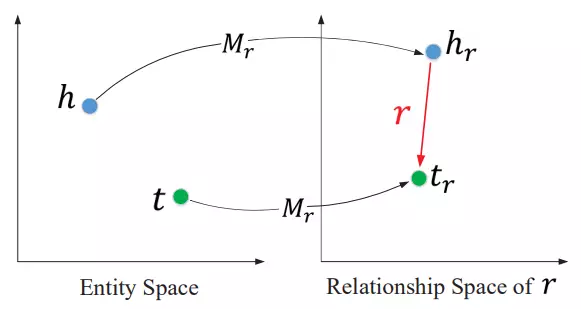
結構化知識學習:TransR。TransR是一種基於距離的翻譯模型,可以學習得到知識實體的向量表示;
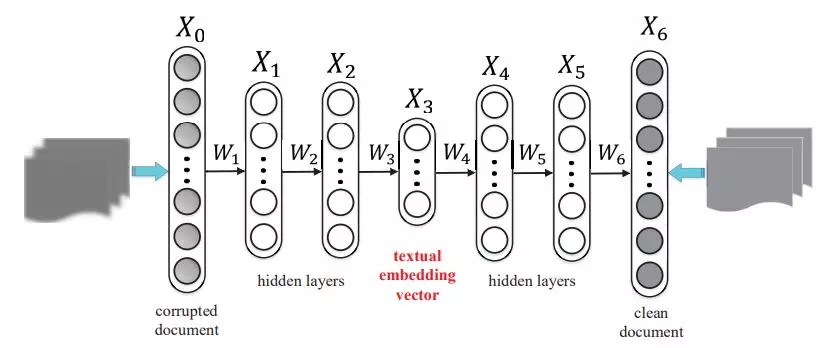
文本知識學習:去噪自編碼器。去噪自編碼器可以學習得到文本的一種泛化能力較強的向量表示;
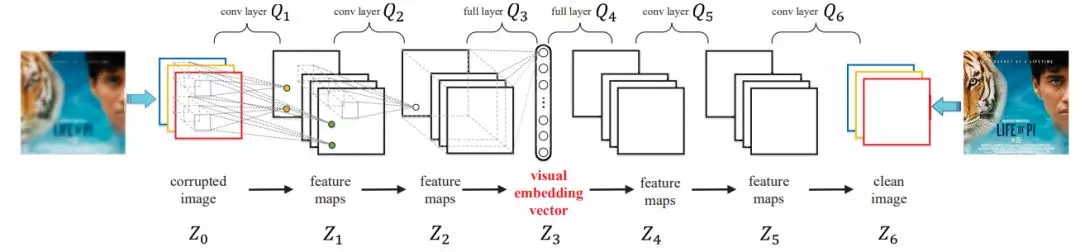
圖像知識學習:卷積-反捲積自編碼器。卷積-反捲積自編碼器可以得到圖像的一種泛化能力較強的向量表示。
我們將三種知識學習的目標函數與推薦系統中的協同過濾結合,得到如下的聯合損失函數:
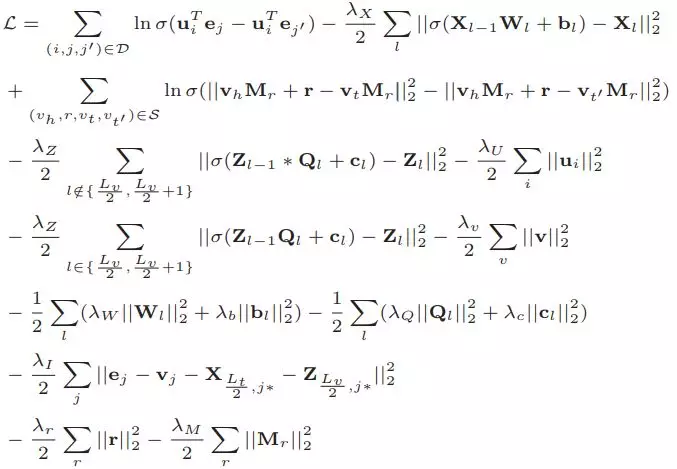
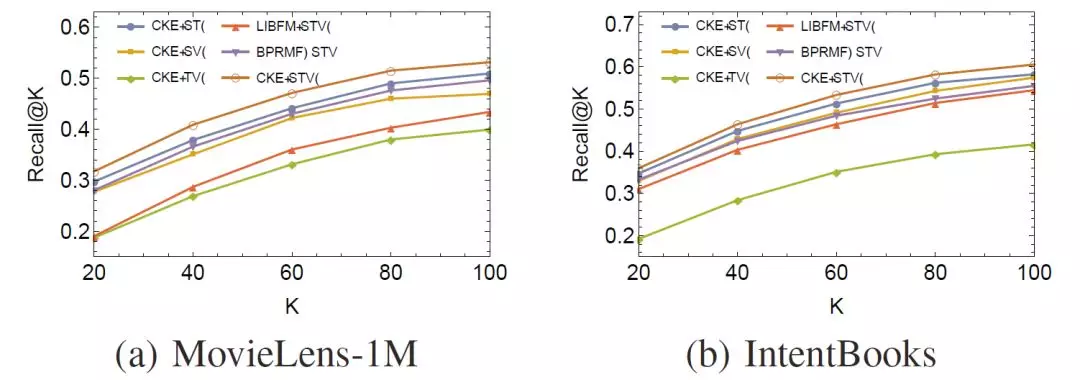
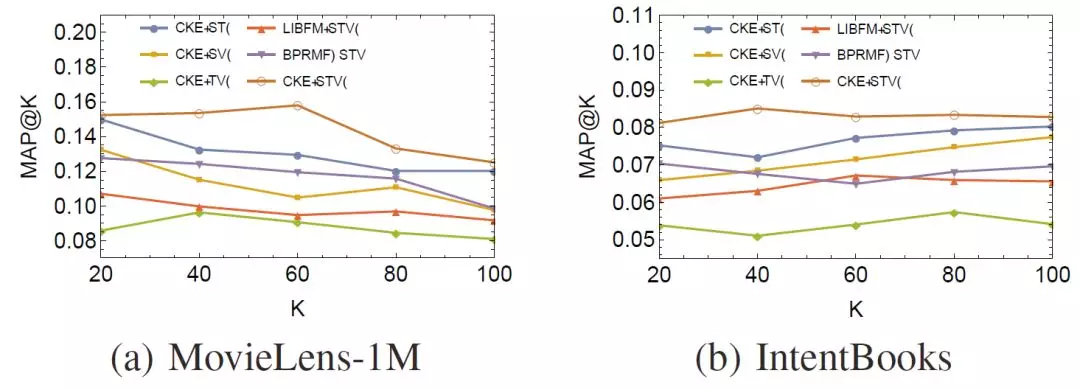
使用諸如隨機梯度下降(SGD)的方法對上述損失函數進行訓練,我們最終可以得到用戶/物品向量,以及實體/關係向量。CKE在電影推薦和圖書推薦上取得了很高的Recall值和MAP值:
Ripple Network
Ripple的中文翻譯爲「水波」,顧名思義,Ripple Network模擬了用戶興趣在知識圖譜上的傳播過程,整個過程類似於水波的傳播:
一個用戶的興趣以其歷史記錄中的實體爲中心,在知識圖譜上向外逐層擴散;
一個用戶的興趣在知識圖譜上的擴散過程中逐漸衰減。
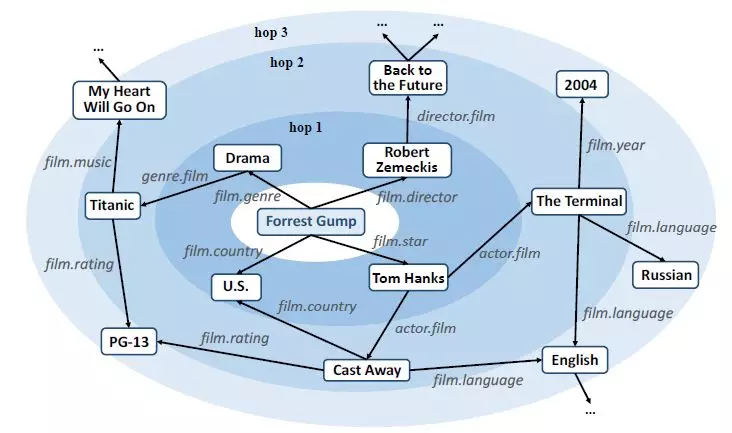
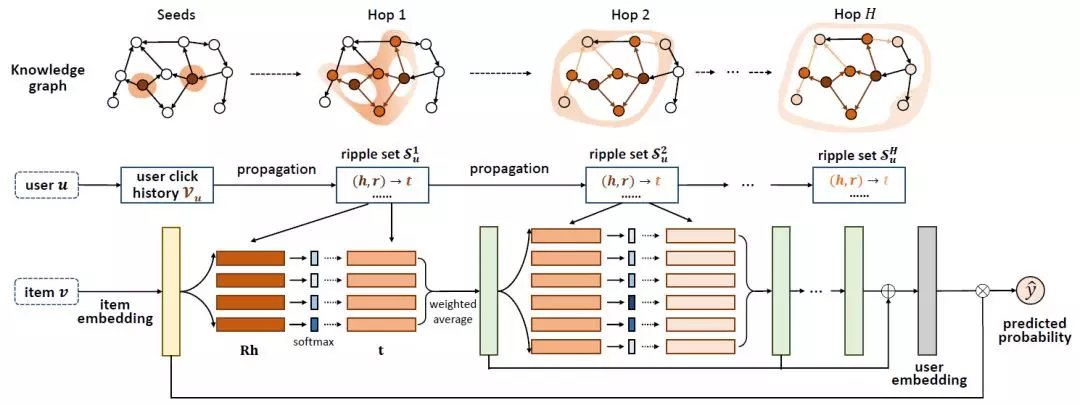
下圖展示了用戶興趣在知識圖譜上擴散的過程。以一個用戶看過的「Forrest Gump」爲中心,用戶的興趣沿着關係邊可以逐跳向外擴展,並在擴展過程中興趣強度逐漸衰減。
下圖展示了Ripple Network的模型。對於給定的用戶u和物品v,我們將歷史相關實體集合V中的所有實體進行相似度計算,並利用計算得到的權重值對V中實體在知識圖譜中對應的尾節點進行加權求和。求和得到的結果可以視爲v在u的一跳相關實體中的一個響應。該過程可以重複在u的二跳、三跳相關實體中進行,如此,v在知識圖譜上便以V爲中心逐層向外擴散。
最終得到的推薦算法和知識圖譜特徵學習的聯合損失函數如下:
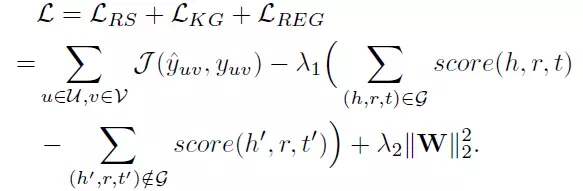
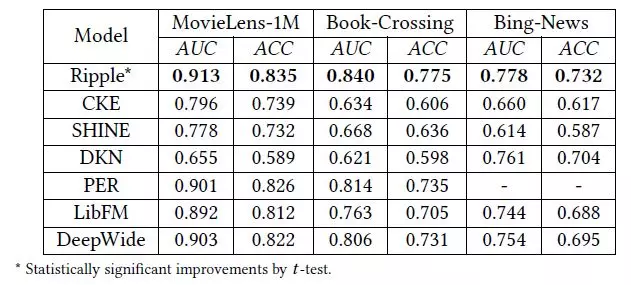
類似於CKE,我們在該損失函數上訓練即可得到物品向量和實體向量。需要注意的是,Ripple Network中沒有對用戶直接使用向量進行刻畫,而是用用戶點擊過的物品的向量集合作爲其特徵。Ripple Network在電影、圖書和新聞的點擊率預測上取得了非常好的效果:
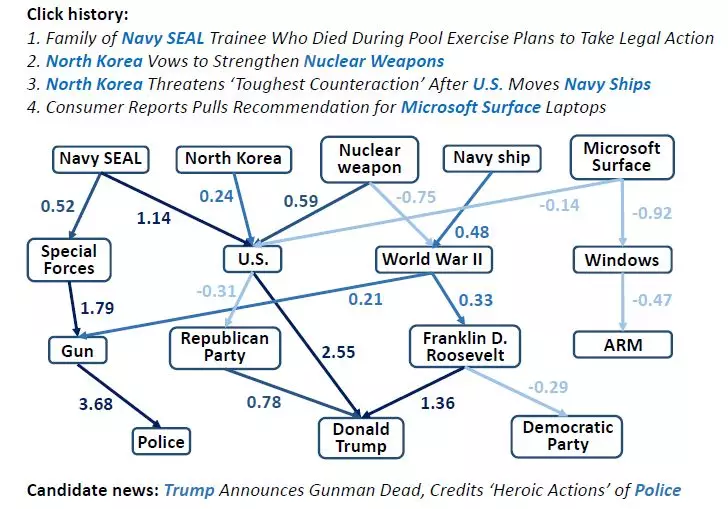
我們將Ripple Network的計算結果可視化如下。可以看出,知識圖譜連接了用戶的歷史興趣和推薦結果,其中的若干條高分值的路徑可以視爲對推薦結果的解釋:
聯合學習的優劣勢正好與依次學習相反。聯合學習是一種端到端的訓練方式,推薦系統模塊的監督信號可以反饋到知識圖譜特徵學習中,這對於提高最終的性能是有利的。但是需要注意的是,兩個模塊在最終的目標函數中結合方式以及權重的分配都需要精細的實驗才能確定。聯合學習潛在的問題是訓練開銷較大,特別是一些使用到圖算法的模型。
三、交替學習
Multi-task Learning for KG enhanced Recommendation (MKR)
推薦系統和知識圖譜特徵學習的交替學習類似於多任務學習的框架。該方法的出發點是推薦系統中的物品和知識圖譜中的實體存在重合,因此兩個任務之間存在相關性。將推薦系統和知識圖譜特徵學習視爲兩個分離但是相關的任務,採用多任務學習的框架,可以有如下優勢:
兩者的可用信息可以互補;
知識圖譜特徵學習任務可以幫助推薦系統擺脫局部極小值;
知識圖譜特徵學習任務可以防止推薦系統過擬合;
知識圖譜特徵學習任務可以提高推薦系統的泛化能力。
MKR[4]的模型框架如下,其中左側是推薦任務,右側是知識圖譜特徵學習任務。推薦部分使用用戶和物品的特徵表示作爲輸入,預測的點擊概率作爲輸出。知識圖譜特徵學習部分使用一個三元組的頭結點和關係表示作爲輸入,預測的尾節點表示作爲輸出。
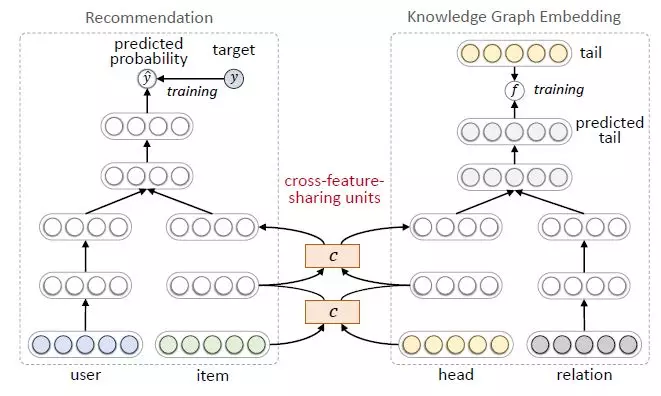
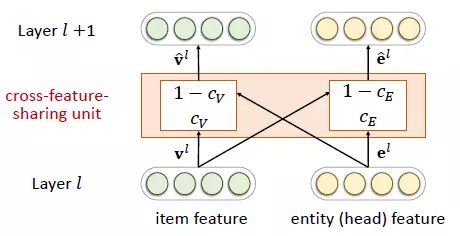
由於推薦系統中的物品和知識圖譜中的實體存在重合,所以兩個任務並非相互獨立。我們在兩個任務中設計了交叉特徵共享單元(cross-feature-sharing units)作爲兩者的連接紐帶。
交叉特徵共享單元是一個可以讓兩個任務交換信息的模塊。由於物品向量和實體向量實際上是對同一個對象的兩種描述,他們之間的信息交叉共享可以讓兩者都獲得來自對方的額外信息,從而彌補了自身的信息稀疏性的不足。
MKR的整體損失函數如下:
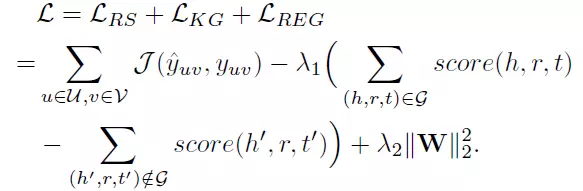
在實際操作中,我們採用交替訓練的方式:固定推薦系統模塊的參數,訓練知識圖譜特徵學習模塊的參數;然後固定知識圖譜特徵學習模塊的參數,訓練推薦系統模塊的參數:

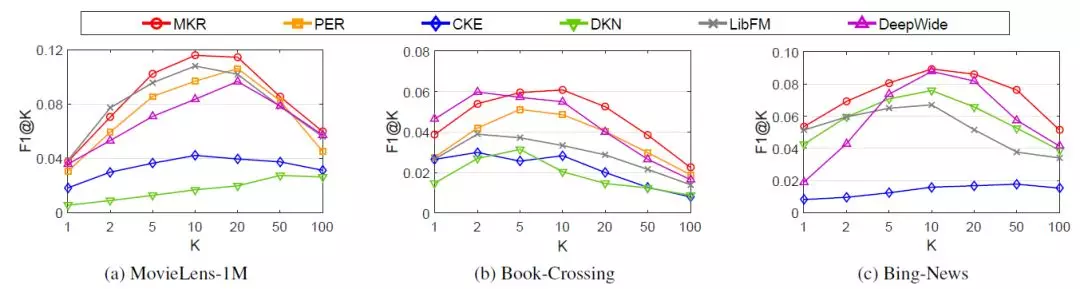
MKR在電影、圖書和新聞推薦上也取得了不錯的效果,其F1@K指標在絕大多數情況下都超過了baseline方法:
交替學習是一種較爲創新和前沿的思路,其中如何設計兩個相關的任務以及兩個任務如何關聯起來都是值得研究的方向。從實際運用和時間開銷上來說,交替學習是介於依次學習和聯合學習中間的:訓練好的知識圖譜特徵學習模塊可以在下一次訓練的時候繼續使用(不像聯合學習需要從零開始),但是依然要參與到訓練過程中來(不像依次學習中可以直接使用實體向量)。
知識圖譜作爲推薦系統的一種新興的輔助信息,近年來得到了研究人員的廣泛關注。未來,知識圖譜和時序模型的結合、知識圖譜和基於強化學習的推薦系統的結合、以及知識圖譜和其它輔助信息在推薦系統中的結合等相關問題仍然值得更多的研究。歡迎感興趣的同學通過留言與我們互動溝通。
參考文獻
[1] DKN: Deep Knowledge-Aware Network for News Recommendation.
[2] Collaborative knowledge base embedding for recommender systems.
[3] Ripple Network: Propagating User Preferences on the Knowledge Graph for Recommender Systems.
[4] MKR: A Multi-Task Learning Approach for Knowledge Graph Enhanced Recommendation.
超鏈接:https://mp.weixin.qq.com/s/QO34vyt3uBSKvnYSW0Kumg