在機器學習研究領域,生成式對抗網絡(GAN)在學習生成模型方面佔據着統治性的地位,在使用圖像數據進行訓練的時候,GAN能夠生成視覺上以假亂真的圖像樣本。但是這種靈活的算法也伴隨着優化的不穩定性,導致模式崩潰(mode collapse)。將自動編碼器(auto-encoder)與GAN相結合,能夠使模型更好的表示所有被訓練的數據,以阻止模式崩潰。雷鋒網瞭解到,來自Google DeepMind的研究者Mihaela Rosca等人利用生成模型的層級結構,提出了將自動編碼器與生成對抗網絡相結合的原則,結合了兩種方法的優點,得到了頂尖結果。
而Ian Goodfellow也鼎力推薦了論文內容。
以下爲雷鋒網(公衆號:雷鋒網(公衆號:雷鋒網))AI科技評論據論文內容進行的部分編譯:
論文摘要
生成對抗網絡是目前機器學習研究領域學習生成模型的最主要的方法之一,它提供了一種學習隱變量模型的更靈活的算法。定向隱變量模型描述了源噪聲數據是如何通過非線性函數變換爲貌似真實的數據樣本的,而GAN則通過辨別真實數據和模型生成數據來驅動學習過程。GAN可以在大型數據集上進行訓練,當使用圖像數據進行訓練的時候,GAN能夠生成視覺上相當真實的圖像樣本。但這種靈活性也帶來了優化過程中的不穩定性,會導致模式崩潰的問題,即生成的數據不能反應潛在的數據分佈的差異。基於自編碼器的GAN(auto-encoder-based GAN, AE-GAN)正是爲了解決這個問題的GAN變種,它使用了自動編碼器來鼓勵模型更好的表示所有被訓練的數據,從而阻止模式崩潰。
自動編碼器的應用成功的改善了GAN訓練。例如,即插即用生成網絡(plug and play generative network, PPGN)通過優化結合了自動編碼器損失,GAN損失,和通過與訓練的分類器定於的分類損失的目標函數,得到了最高水平的樣本。AE-GAN可以大致分爲三種:(1)使用自動編碼器作爲判別器,例如energy-based GAN和boundary-equilibrium GAN。(2)使用去噪自動編碼器以得到更稱其的輔助損失函數,例如denoising feature matching GAN。(3)結合了VAE和GAN的方法,例如變分自動編碼器GAN(variational auto-encoder GAN, VAE-GAN)。
該論文中,作者提出了結合AE-GAN的原則性方法。通過探索由GAN學習到的隱變量模型的層次結構,作者展示瞭如何將變分自動編碼器與GAN結合到一起。該方法能夠克服各自方法的限制,因此具有極大的優勢。當基於圖像進行訓練時,VAE方法經常會生成模糊的圖像,但VAE不會像GAN一樣受到模式崩潰問題的困擾。GAN幾乎不允許對模型進行分佈假設,而VAE允許對隱變量進行推斷,這對於表徵學習,可視化和解釋是很有用的。該論文開發的方法結合了這兩個方法中的優點,提供統一的學習目標函數,無監督,不需要預訓練或外部分類器,並且可以輕鬆的擴展到其他生成模型任務。
該論文主要進行了一下工作:
表明變分推理(variational inference)同樣使用與GAN,以及如何可以將判別器用於具有隱式後驗近似的變分推理。
在學習生成模型時,可以組合likelihood-based和likelihood-free模型。在likelihood-free設定中,開發了具有合成似然性的變分推理,使得可以學習這種模型。
制定了自動編碼GAN(auto-encoding GAN,α-GAN)的原則目標函數,並描述了使它進行實際工作所需的思考。
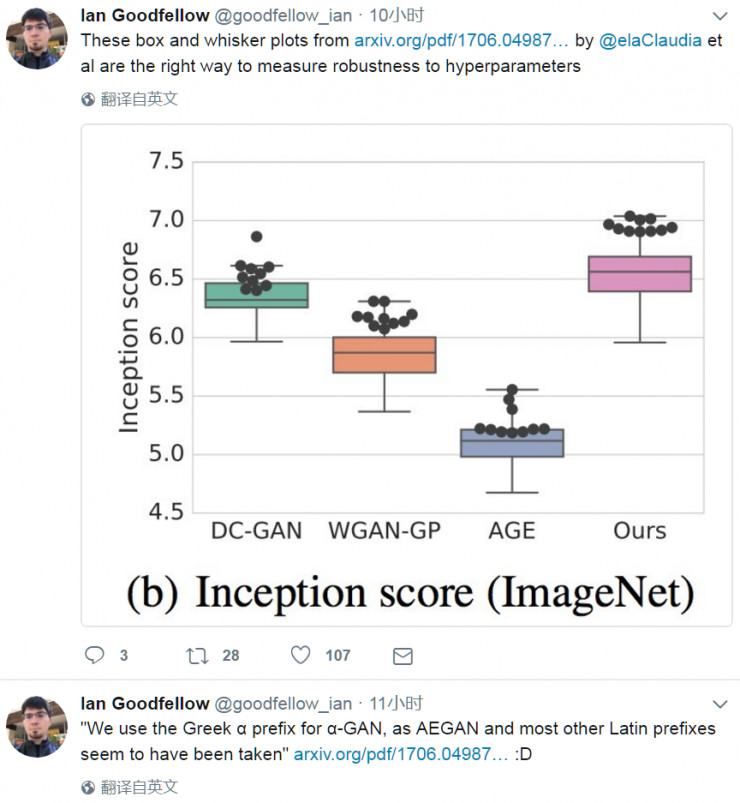
評估是GAN研究中的主要挑戰之一,作者使用了一系列評估措施仔細評估了該方法的性能,與DC-GAN, WGAN和對抗-生成-編碼器(adversarial-generator-encoder,AGE)進行比較,展示了論文中的方法與這些方法有相媲美的性能,並強調隱生成模型中持續評估的挑戰。
實驗結果
爲了更好地理解基於自動編碼器的方法在GAN領域中的重要性,作者將該方法與其他GAN方法在三個數據集上進行了對比,包括混合模型AGE,和其他純GAN方法的變種,例如DCGAN和WGAN-GP。數據集爲ColorMNIST,CelebA和CIFAR-10。在實驗中,使用了Inception score,MS-SSIM和Independent Wasserstein critic作爲評估指標。爲了綜合分析實驗結果,結果採用了每個算法獲得的最佳值。爲了評估模型對超參數的敏感性,採用了每個模型各個超參數中最好的十個,在圖中由黑色圓圈表示。
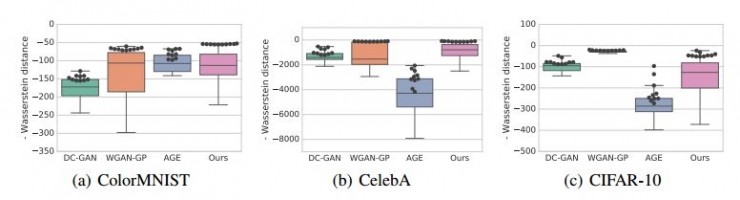
圖一:Wasserstein critic指標下各方法的實驗結果
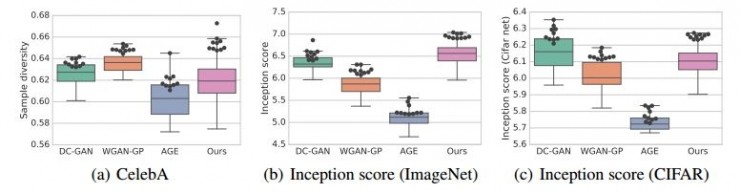
圖二:Sample diversity和Inception score指標下各方法實驗結果
ColorMNIST數據集結果:
在上圖(a)中比較了Wasserstein critic指標的值,其中值越高越好。該方法對超參數的敏感度較低,在這個指標下,該方法在各種設置下都取得了最佳的性能。這也在下圖生成的樣本中得到了證明:

從左到右分別爲:DCGAN,WGAN-GP,AGE,論文中方法
CelebA數據集結果:
CelebA數據集有64*64像素的名人臉圖片組成。下圖展示了四種模型生成的樣本。作者也在Wasserstein critic指標下(見圖一(b))和sample diversity score標準下(見圖二(a))對各方法進行了比較,論文中方法與WGAN-GP和AGE方法有接近的表現。

從左到右分別爲:DCGAN,WGAN-GP,AGE,論文中方法
CIFAR-10數據集結果:
下圖中展示了CIFAR-10數據集上四種模型生成的樣本。如圖一(c)所示,在Wasserstein critc指標下,WGAN-GP是最佳模型。如圖二(b)所示,基於ImageNet的Inception score中,論文種方法有最佳的性能,如圖二(c)所示,基於CIFAR-10的Inception score中,論文中方法與DC-GAN有相近的性能。

從左到右分別爲:DCGAN,WGAN-GP,AGE,論文采用的方法
想要深入瞭解該方法的請閱讀原論文:https://arxiv.org/pdf/1706.04987.pdf, 雷鋒網編譯