耶路撒冷希伯來大學的計算機與神經科學家 Naftali Tishby 提出了一項名爲「信息瓶頸」(Information Bottleneck)的新理論,有望最終打開深度學習的黑箱,以及解釋人腦的工作原理。這一想法是指神經網絡就像把信息擠進瓶頸一樣,只留下與一般概念最爲相關的特徵,去掉大量無關的噪音數據。深度學習先驅 Geoffrey Hinton 則在發給 Tishby 的郵件中評價道:「信息瓶頸極其有趣,估計要再聽 10000 遍才能真正理解它,當今能聽到如此原創的想法非常難得,或許它就是解開謎題的那把鑰匙。」

一個稱爲「信息瓶頸」的新想法有助於解釋當今人工智能算法的黑箱問題——以及人類大腦的工作原理。
如今「深度神經網絡」已經學會對話、駕駛汽車、打視頻遊戲、玩圍棋、繪畫並輔助科研,這使其人類構建者很是困惑,併爲深度學習算法的成果深感意外。這些學習系統的設計並沒有一條明確的原則,除了來自大腦神經元的靈感(其實並沒有人知道大腦是如何工作的),並且 DNN 早就和大腦神經元的原理相去甚遠。
像大腦一樣,深度神經網絡具有神經元層——這些人工神經元構成了計算機的記憶。當一個神經元激活,它向連接到下一層的神經元發送信號。在深度學習中,網絡連接按需強化或弱化(加權連接)從而更好地把來自輸入數據的信號——比如,一張狗的圖像像素點——發送到與高級概念(比如狗)相關聯的神經元。當深度神經網絡學習數以千計的狗的樣本圖像之後,它可像人一樣精確地從新圖像中辨識出狗。這一魔術般的學習能力使其具備了可像人一樣推理、創造進而擁有智能的基礎。專家好奇深度學習是如何做到這一點的,並在何種程度上與人腦理解世界的方式相同。
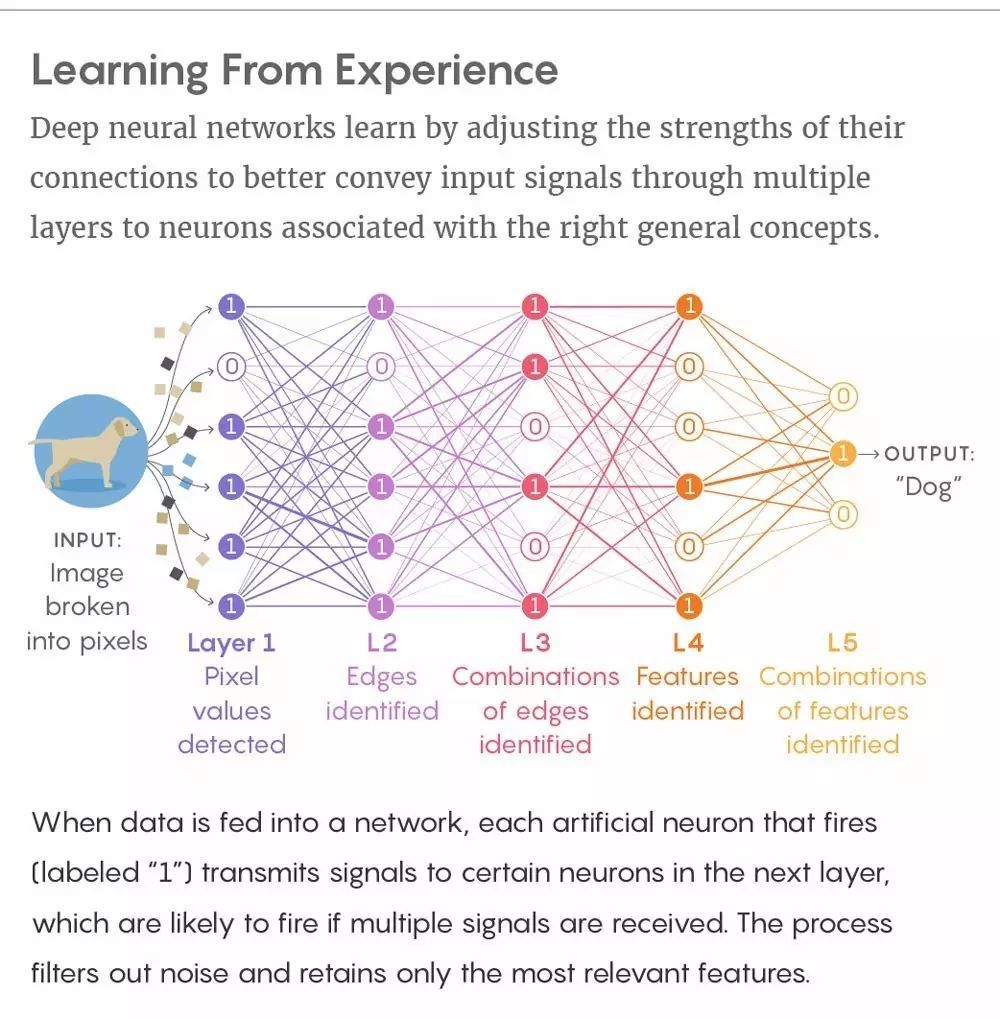
從經驗中學習。深度神經網絡通過調節連接權重以更好地傳遞輸入信號,信號經過隱藏層,最終到達與正確概念相關聯的神經元。當數據輸入到神經網絡,激活的每一個神經元(被標註爲 1)把信號傳遞到下一層的特定神經元(如果接受到多個信號則很可能被激活)。這一過程會過濾掉噪聲並只保留最相關的特徵。
上月,一個在人工智能研究者之間廣泛流傳的柏林會議 YouTube 視頻給出了黑箱可能的答案。會議中來自耶路撒冷希伯來大學的計算機與神經科學家 Naftali Tishby 爲一項解釋深度學習工作原理的新理論提供了證據。Tishby 論證道深度神經網絡依據被稱作「信息瓶頸」的步驟學習,這一術語其與另外兩名合作者早在 1999 年就已提出。這一想法是指神經網絡就像把信息擠進瓶頸一樣,只留下與一般概念最爲相關的特徵,去掉大量無關的噪音數據。由 Tishby 及其學生 Ravid Shwartz-Ziv 聯合進行的引人注目的實驗揭示了發生在深度學習之中的擠壓過程,至少在他們研究案例中是這樣。Tishby 的發現在人工智能社區中引發了躁動。谷歌研究員 Alex Alemi 說:「我認爲信息瓶頸對未來的深度神經網絡研究很重要。我甚至發明了新的近似方法,從而把信息瓶頸分析應用到大型深度神經網絡中。」他又說:「信息瓶頸不僅可以作爲理論工具用來理解神經網絡的工作原理,同樣也可以作爲構建網絡架構和新目標函數的工具。」
一些研究者則仍懷疑該方法是否徹底解釋了深度學習的成功,但是 Kyle Cranmer——一名來自紐約大學粒子物理學家,他曾使用機器學習分析了大量強子對撞機中的粒子對撞——則認爲信息瓶頸作爲一般性的學習原理,「多少還是正確的」。
深度學習先驅 Geoffrey Hinton 在柏林會議之後給 Tishby 發了郵件:「信息瓶頸極其有趣,估計要再聽 10000 遍才能真正理解它,當今能聽到如此原創的想法非常難得,或許它就是解開謎題的那把鑰匙。」
據 Tishby 所講,信息瓶頸是一個根本性的學習原則,不管是算法、家蠅、有意識的存在還是突發事件的物理計算。我們期待已久的答案即是「學習的關鍵恰恰是遺忘。」
瓶頸
Tishby 大概是在其他的研究者開始搞深度神經網絡之時開始構思信息瓶頸的。那是 1980 年代,Tishby 在思考人類在語音識別上的極限是什麼,當時這對人工智能來說是一個巨大的挑戰。Tishby 意識到問題的關鍵是相關性:口頭語言最爲相關的特徵是什麼?我們如何從與之相隨的變量中(口音、語調等)將其提取出來?一般來講,當面對現實世界的海量數據之時,我們會保留哪些信號?

希伯來大學計算機科學教授 Naftali Tishby
「相關性的理念在歷史上多有提及,但從未得到正確的闡述;從香農本人有誤差的概念開始,多年來人們並不認爲信息論是闡述相關性的正確方式。」Tishby 在上月的採訪中說。
信息論的建立者香農通過抽象思考在一定意義上解放了始於 1940 年代的信息研究——1 和 0 只具有純粹的數學意義。正如 Tishby 所說,香農認爲信息與語義學無關,但是 Tishby 並不認同。藉助信息論,Tishby 意識到可以精確地定義相關性。
假設 X 是一個複雜的數據集,比如狗的圖像像素,Y 是一個被這些數據表徵的較簡單的變量,比如單詞「狗」。通過儘可能地壓縮 X 而又不失去預測 Y 的能力,我們在關於 Y 的 X 中可以捕獲所有的相關性信息。在 1999 年的論文中,Tishby 與聯合作者 Fernando Pereira(現在谷歌)、William Bialek(現在普林斯頓大學)共同將這個概念闡述爲一個數學優化問題。這是一個沒有潛在黑箱問題的基本思想。
Tishby 說:「30 年來我在不同的環境下一直思考它,我唯一的慶幸是深度神經網絡變的如此重要。」
眼球長在臉上,臉長在人身上,人處於場景中
儘管這一隱藏在深度神經網絡後面的概念已經討論了幾十年,但是它們在語音識別、圖像識別等任務中的表現在 2010 年代纔出現較大的發展,這和優化的訓練機制、更強大的計算機處理器息息相關。2014 年,Tishby 閱讀了物理學家 David Schwab 和 Pankaj Mehta 的論文《An exact mapping between the Variational Renormalization Group and Deep Learning》(變分重整化和深度學習之間的映射關係),認識到他們與信息瓶頸原則的潛在聯繫。
Schwab 和 Mehta 發現 Hinton 發明的深度學習算法「深度信念網絡」在特定的情況下和重整化(renormalization)一樣,重整化是一種通過粗粒化物理系統的細節、計算全局狀態從而簡化該系統的技術。二人將深度信念網絡應用到分形(在不同的尺度上有自相似性)臨界磁化系統模型中時,他們發現網絡將自動使用一種類似重整化的過程尋找模型的狀態。這令人印象深刻,正如生物物理學家所說,「統計物理學中的提取相關特徵和深度學習中的提取相關特徵不只是相似的詞,它們的含義也是一樣的。」
唯一的問題是,現實世界一般而言不是分形的(fractal)。「自然世界並不是耳朵長在耳朵再長在耳朵上;而是眼球長在臉上,臉長在人身上,人處於場景中,」Cranmer 說,「因此我不會說,深度學習網絡處理自然圖像很優秀是因爲其類似重整化的工作方式。」但是,Tishby 意識到,深度學習和粗粒化過程可以被包含於更廣義的思維中。

Noga Zaslavsky(左)和 Ravid Shwartz-Ziv(右)作爲 Naftali Tishby 的畢業生幫助建立了深度學習的信息瓶頸理論
在 2015 年,他和他的學生提出假設,(https://arxiv.org/abs/1503.02406)深度學習是一個信息瓶頸程序,儘可能的壓縮數據噪聲,保留數據想表達的信息。Tishby 和 Shwartz-Ziv 的新的深度神經網絡實驗揭示了瓶頸程序是如何工作的。在一個案例中,研究員訓練小型網絡使其將數據標記爲 1 或 0(比如「狗」或「非狗」),網絡一共有 282 個神經連接並隨機初始化連接強度,然後他們使用 3000 個樣本的輸入數據集追蹤網絡究竟在做什麼。
大多數深度學習網絡訓練過程中用來響應數據輸入和調整神經連接強度的基本算法都是「隨機梯度下降」:每當輸入訓練數據到網絡中,一連串的激活行爲將接連每一層的神經元。當信號到達最頂層時,最後的激活模式將對應確定的標籤,1 或 0,「狗」或「非狗」。激活模式和正確的模式之間的不同將會「反向傳播」回網絡的層中,即,正如老師批改作業一樣,這個算法將強化或者弱化每一個連接的強度以使網絡能輸出更產生的輸出信號。經過訓練之後,訓練數據的一般模式將體現在神經連接的強度中,網絡將變成識別數據的專家。
在他們的實驗中,Tishby 和 Shwartz-Ziv 追蹤了深度神經網絡的每一層保留了多少輸入數據的信息,以及每一層保留了多少輸出標籤的信息。他們發現,網絡逐層收斂到了信息瓶頸的理論範圍(Tishby 導出的理論極限)。Pereira 和 Bialek 最初的論文中展示了系統提取相關信息的最佳結果。在信息瓶頸的理論範圍內,網絡將盡可能地壓縮輸入,而無需犧牲精確預測標籤的能力。
Tishby 和 Shwartz-Ziv 還發現了一個很有趣的結果,深度學習以兩個狀態進行:一個短期「擬合」狀態,期間網絡學習標記輸入數據,和一個時間長得多的長期「壓縮」狀態,通過測試其標記新測試數據的能力可以得出期間網絡的泛化能力變得很強。
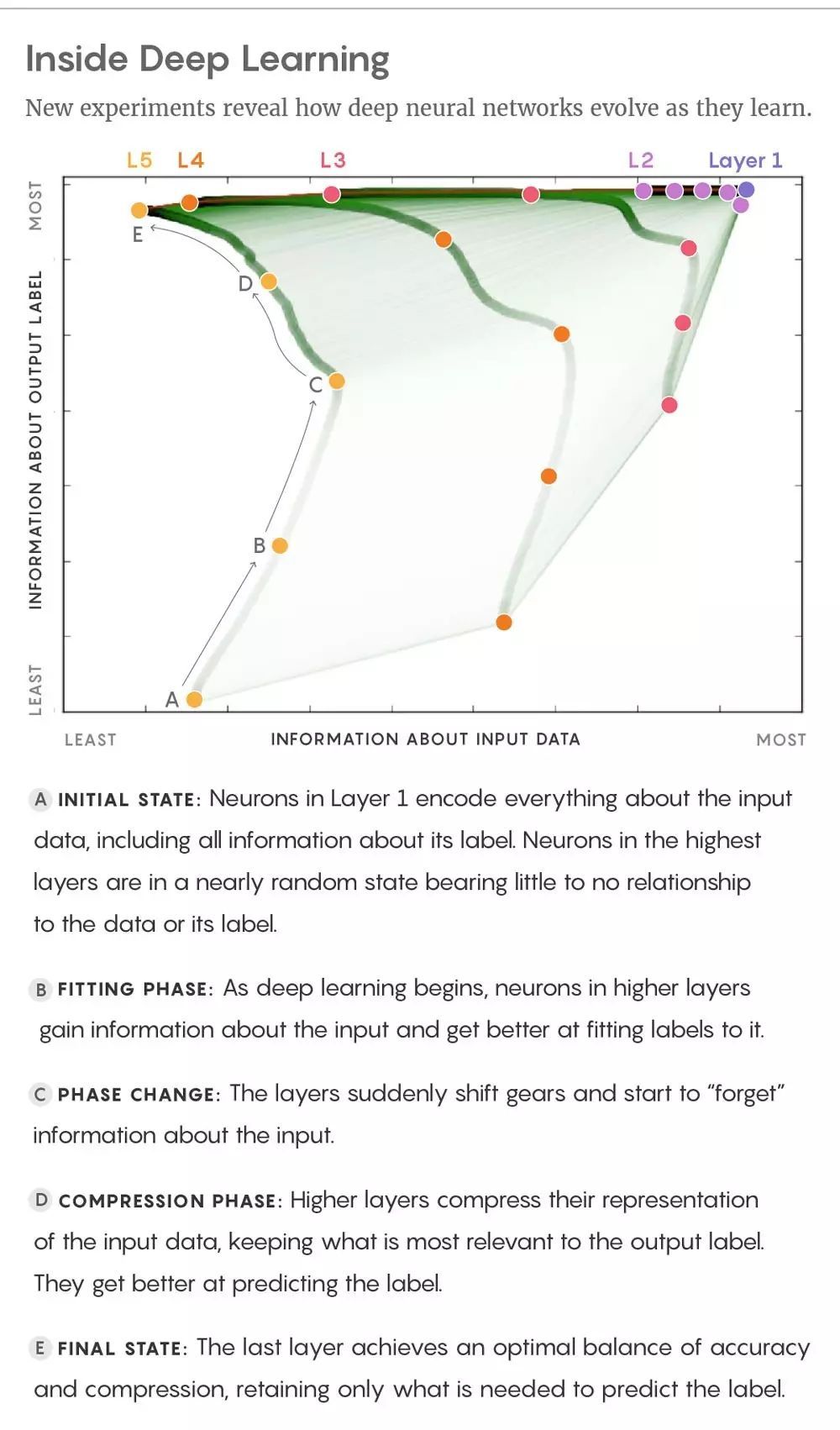
圖片來自 arXiv:1703.00810
A. 初始狀態:第一層的神經元編碼輸入數據的所有信息,包括其中的標籤信息。最高層神經元處於幾乎無序的狀態,和輸入數據或者其標籤沒有任何關聯。
B. 擬合狀態:深度學習剛開始的時候,高層神經元獲得輸入數據的信息,並逐漸學會匹配標籤。
C. 狀態變化:網絡的層的狀態突然發生變化,開始「遺忘」輸入數據的信息。
D. 壓縮狀態:網絡的高層壓縮對輸入數據的表示,保留與輸出標籤關聯最大的表示,這些表示更擅長預測標籤。
E. 最終狀態:網絡的最高層在準確率和壓縮率之間取得平衡,只保留可以預測標籤的信息。
當深度神經網絡用隨機梯度下降調整連接強度時,最初網絡存儲輸入數據的比特數基本上保持常量或者增加很慢,期間連接強度被調整以編碼輸入模式,而網絡標註數據的能力也在增長。一些專家將這個狀態與記憶過程相比較。
然後,學習轉向了壓縮狀態。網絡開始對輸入數據進行篩選,追蹤最突出的特徵(與輸出標籤關聯最強)。這是因爲在每一次迭代隨機梯度下降時,訓練數據中或多或少的偶然關聯都驅使網絡做不同的事情,使其神經連接變得或強或弱,隨機遊走。這種隨機化現象和壓縮輸入數據的系統性表徵有相同的效果。舉一個例子,有些狗的圖像背景中可能會有房子,而另一些沒有。當網絡被這些照片訓練的時候,由於其它照片的抵消作用,在某些照片中它會「遺忘」房子和狗的關聯。Tishby 和 Shwartz-Ziv 稱,正是這種對細節的遺忘行爲,使系統能生成一般概念。實際上,他們的實驗揭示了,深度神經網絡在壓縮狀態中提高泛化能力,從而更加擅長標記測試數據。(比如,被訓練識別照片中的狗的深度神經網絡,可以用包含或者不包含狗的照片進行測試。)
至於信息瓶頸是不是在所有深度學習中都存在,或者說有沒有除了壓縮以外的其它泛化方式,還有待近進一步考察。有些 AI 專家評價 Tishby 的想法是近來深度學習的重要理論洞察之一。哈佛大學的 AI 研究員和理論神經學家 Andrew Saxe 提出,大型深度神經網絡並不需要冗長的壓縮狀態進行泛化。取而代之,研究員使用提前停止法(early stopping)以切斷訓練數據,防止網絡對數據編碼過多的關聯。
Tishby 論證道 Saxe 和其同事分析的神經網絡模型不同於標準的深度神經網絡架構,但儘管如此,信息瓶頸理論範圍比起其它方法更好地定義了這些網絡的泛化能力。而在大型神經網絡中是否存在信息瓶頸,Tishby 和 Shwartz-Ziv 最近的實驗中部分涉及了這個問題,而在他們最初的文章中沒有提過。他們在實驗中通過包含 60,000 張圖片的國家標準與技術局(National Institute of Standards and Technology)(http://yann.lecun.com/exdb/mnist/)的已完善數據集(被視爲測量深度學習算法的基準)訓練了 330,000 個連接的深度神經網絡以識別手寫體數字。他們觀察到,網絡中同樣出現了收斂至信息瓶頸理論範圍的行爲,他們還觀察到了深度學習中的兩個確切的狀態,其轉換界限比起小型網絡甚至更加銳利而明顯。「我完全相信了,這是一個普遍現象。」Tishby 說道。
人類和機器
大腦從我們的感知中篩選信號並將其提升到我們的感知水平,這一奧祕促使 AI 先驅關注深度神經網絡,他們希望逆向構造大腦的學習規則。然而,AI 從業者在技術進步中大部分放棄了這條路徑,轉而追尋與生物合理性幾乎不相關的方法來提升性能。但是,由於他們的思考機器取得了很大的成績,甚至引起「AI 可能威脅人類生存」的恐懼,很多研究者希望這些探索能夠提供對學習和智能的洞察。

紐約大學心理學和數據科學助理教授 Brenden Lake 研究人類和機器學習方式的異同,他認爲 Tishby 的研究成果是『打開神經網絡黑箱的重要一步』,但是他強調大腦展示了一個更大、更黑的黑箱。成年人大腦包含 860 億神經元之間的數百萬億連接,可能具備很多技巧來提升泛化,超越嬰兒時期的基本圖像識別和聲音識別學習步驟,這些步驟可能在很多方面與深度學習類似。
比如,Lake 說根據他的研究,Tishby 確認的擬合和壓縮詞組看起來與孩子學習手寫字的方式並不相同。孩子們並不需要看數千個字並經過一段時間的壓縮心理表徵,才能認識那個字,並學會寫字。事實上,他們可以從單一樣本中進行學習。Lake 及其同事製作的模型說明大腦可以將一個新的字解構成一系列筆畫(先前存在的心理建構),使這個字的概念附加到先前知識之上。「並非像標準機器學習算法那樣,把字的圖像當作像素塊,把概念當成特徵映射進行學習。」Lake 解釋道,「我的目的是構建該字的簡單因果模型。」一種導致泛化的更短路徑。
如此聰明的想法有助於人工智能社區增長經驗,進一步加強兩個領域的溝通。Tishby 相信信息瓶頸理論最終將會在兩個學科發揮作用,即使它採取了一種在人類學習(而不是人工智能)中更普遍的形式。從該理論中,我們可以更好地理解哪些問題可被人類或人工智能解決。Tishby 說:「它給出了可以學習的問題的完整描述,在這些問題中我可以去除輸入中的噪音而無損於我的分類能力。這是一個自然的視覺問題,語音識別。這也正是人腦可以應對的問題。」
同時,人類和人工神經網絡很難解決每一個細節都很重要以及細微差別影響結果的問題。例如,大多數人無法快速心算兩個大數字相乘的結果。「我們有一大堆這樣的問題,對於變量的細微變化非常敏感的邏輯問題。」Tishby 說道。「分類問題、離散問題、加密問題。我不認爲深度學習會幫助我們破解密碼。」
泛化——測量信息瓶頸,或許意味着我們會喪失一些細節。這對於運行中的計算並不友好,但它並不是大腦的主要任務。我們在人羣中找到熟悉的面孔,在複雜內容中找到規律,並在充滿噪聲的世界裏提取有用的信息。
原文鏈接:https://www.quantamagazine.org/new-theory-cracks-open-the-black-box-of-deep-learning-20170921/