昨晚,
暴雪聯合 DeepMind 發出一則新聞,
DeepMind 開發的星際 2 AI「AlphaStar」很快就會出現在星際 2 歐洲服務器上的 1v1 天梯比賽中。
人類玩家們不僅會有機會匹配到它們、
和它們展開標準的比賽,
比賽結果也會像正常比賽一樣影響自己的天梯分數。
在星際 2 上做科研實驗
正如人盡皆知的圍棋 AI AlphaGo,
DeepMind 喜歡的強化學習 AI 研究過程是在某個比賽(博弈)環境中進行技術探索,
在新技術的輔助下讓智能體從歷史數據中學習、從自我博弈中學習,
然後與人類高手比賽,評估 AI 的水準。
樊麾、李世石、柯潔都光榮地成爲了「人工智能測試高級工程師」。

在此次星際 2 AI「AlphaStar」的研究過程中,
DeepMind 繼續沿用這個思路,
但這次他們更大膽一點,
讓大批不同水準的普通玩家參與到 AI 表現的評估中來,
最終的比賽結果會寫到論述星際 2 AI 科研項目的論文裏,向期刊投稿。
這就是暴雪和 DeepMind 聯手把 AI 送上天梯比賽的最重要原因。
進入星際 2 遊戲,
在 1v1 比賽設置了允許接入 DeepMind(DeepMind opt-in)之後,
參加 1v1 天梯比賽的玩家們就可能會遇到 AlphaStar。
爲了控制所有的比賽都儘量接近正常的人類 1v1 天梯比賽,
以及減小不同比賽之間的差異,
AlphaStar 會隨機匹配到一部分玩家的天梯比賽中,
並且 AI 會在遊戲保持匿名,
匹配到的玩家和星際 2 後臺都無法知道哪些比賽是有 AlphaStar 參與的。
不過,設置了允許接入 AI 之後,
相信玩家們立即就會開始對匹配到 AI 對手產生期待,
而且在比賽開始之後也可能很快就會發現自己的對手有一些不尋常之處。

一月的比賽中,AlphaStar 會建造大量工人,快速建立資源優勢(超過人類職業選手的 16 個或 18 個的上限)

一月的比賽中,AlphaStar 控制的兩個追獵者黑血極限逃生
今年一月時 AlphaStar 就曾與人類職業選手比賽並取得了全勝。相比於當時的版本,此次更大規模測試的 AlphaStar 版本進行了一些改動,其中一些改動明顯對人類有利:
一月的版本可以直接讀取地圖上所有的可見內容,不需要用操作切換視角,這次需要自己控制視角,和人類一樣只能觀察到視野內的單位,也只能在視野內移動單位;
一月的版本僅使用了神族,這次 AlphaStar 會使用人族、蟲族、神族全部三個種族;
一月的版本在操作方面沒有明確的性能限制,這次,在與人類職業選手共同商議後,對 AlphaStar 的平均每秒操作數、平均每分鐘操作數(APM)、瞬時最高 APM 等一些方面都做了更嚴格的限制,減少操作方面相比人類的優勢。
參與測試的 AlphaStar 都是從人類比賽 replay 和自我比賽中學習的,沒有從與人類的對局中學習,同時 AlphaStar 的表現會在整個測試期間保持不變,不進行訓練學習;這樣得到的測試結果能直接反應 DeepMind 目前的技術水準到達了怎麼樣的水平。另一方面,作爲 AlphaStar 技術方案的一大亮點,參與測試的 AlphaStar 也會是 AlphaStar 種羣(AlphaStar league,詳見下文)中的多個不同個體,匹配到的不同 AlphaStar 個體可能會有迥異的遊戲表現。
AlphaStar 技術特點
在今年一月 DeepMind 首次公開 AlphaStar 與人類職業選手的比賽結果時,我們就結合 DeepMind 官方博客對 AlphaStar 的技術特點進行了報道。這裏我們再把 AlphaStar 的技術特點總結如下:(詳細可以參見文章)
模型結構 - AlphaStar 使用的是一個長序列建模模型,模型從遊戲接口接收的數據是單位列表和這些單位的屬性,經過神經網絡計算後輸出在遊戲中執行的指令。這個神經網絡的基礎是 Transformer 網絡,並且結合了一個深度 LSTM 網絡核心、一個帶有指針網絡的自動迴歸策略頭,以及一箇中心化的評分基準。
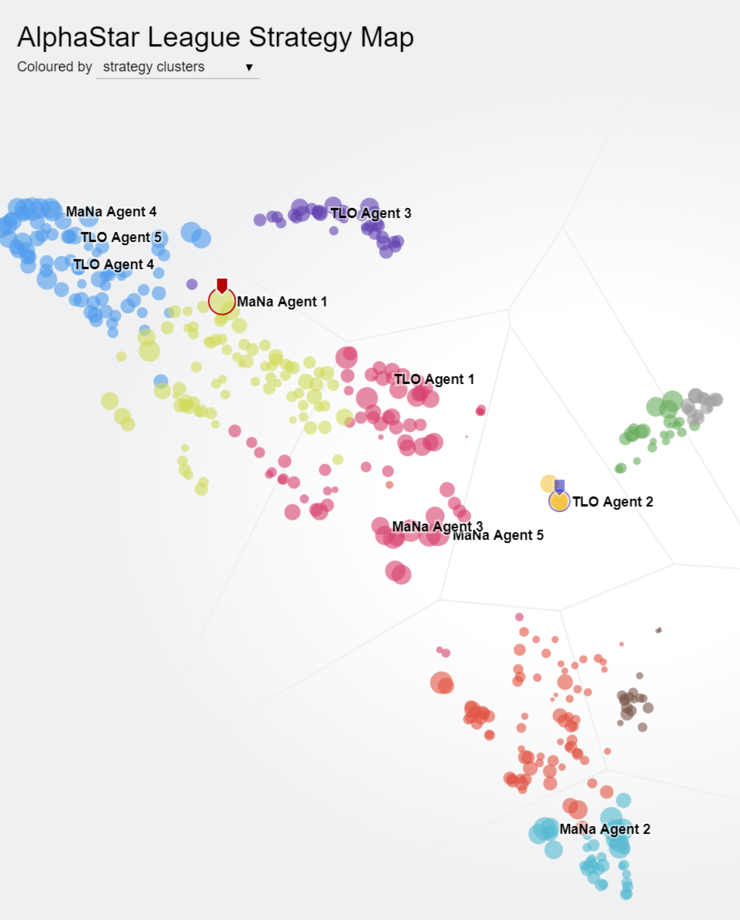
AlphaStar league 中的個體形成了明顯的策略分佈
訓練策略 - AlphaStar 首先根據高水平人類比賽進行監督學習訓練(模仿學習),然後進行自我對弈。自我對弈的過程中使用了羣體強化學習的思路:AlphaStar 自我對弈過程中始終都同時記錄、更新多個不同版本的網絡,保持一個羣體,稱作 AlphaStar league;AlphaStar league 中不同的網絡具有不同的對戰策略、學習目標等等,維持了羣體的多樣性,整個羣體的對弈學習保證了持續穩定的表現提升,而且很新的版本也不會「忘記」如何擊敗很早的版本。
訓練結果輸出 - 當需要輸出一個網絡作爲最終的訓練結果時,以 AlphaStar league 中的納什分佈進行採樣,可以得到已經發現的多種策略的綜合最優解。
算力需求 - 爲了支持大批不同版本 AlphaStar 智能體的對戰與更新,DeepMind 專門構建了一個大規模可拓展的分佈式訓練環境,其中使用了最新的谷歌 TPUv3。AlphaStar league 的自我對戰訓練過程用了 14 天,每個 AlphaStar 智能體使用了 16 個 TPU,最終相當於每個智能體都有長達 200 年的遊戲時間。訓練結束後的模型在單塊消費級 GPU 上就可以運行。
操作統計 - 在今年一月的版本中,AlphaStar 的平均 APM 爲 280,峯值 APM 超過 1000,計算延時平均爲 350 毫秒;切換關注區域的速度大約是每分鐘 30 次。
此次在 AlphaStar 中測試的大行動空間下的長序列建模,以及羣體強化學習的訓練策略,都是對提升強化學習算法表現上限、應對複雜環境長期任務的積極技術探索。我們期待早日看到 DeepMind 的這篇論文成文,更早日看到基於強化學習的決策系統整個領域都發展得更成熟。當然了,喜歡星際 2 的讀者,可以準備起來,爲 DeepMind 的這篇論文貢獻自己的一分力量吧!