
雷鋒網AI研習社【本期論文】
"Imagination-Augmented Agents for Deep Reinforcement Learning"
用於深度強化學習的增強想象智能體
DeepMind發佈的最新論文中提出了,用於深度強化學習的增強想象智能體(Imagination-Augmented Agents)。這個智能體的有趣之處在於,它用到了想象力。不僅能夠獲取當前信息、想象行動結果,還能制定計劃,選擇一種可以夠達到最大預期值的方法。

研究發現,在軟件中植入想象智能體,就能讓它們更快地學習,論文描述了通過想象計劃(imaginative planning)提高深度強化學習的新方法。
學會想象的智能體在玩 Sokoban(推箱子)遊戲時,解決了 85% 的問題,而基準智能體完成了 65%。增強想象智能體的完成率也超過了沒有使用想象計劃的標準智能體的增強版本。

當然,這個通用算法,可以用在很多不同的問題上。推箱子這種小遊戲只是展示這個新技術優異性能的一種方式。
▷觀看論文解讀大概需要 3 分鐘
其實在兩年前,DeepMind團隊就推出了一種算法,能夠通過觀看視頻,就把Atari Breakout(打磚塊)玩得很溜。這個算法推出的時候可以說是轟動一時,短短兩年,那篇論文已經被一千多篇研究論文引用。
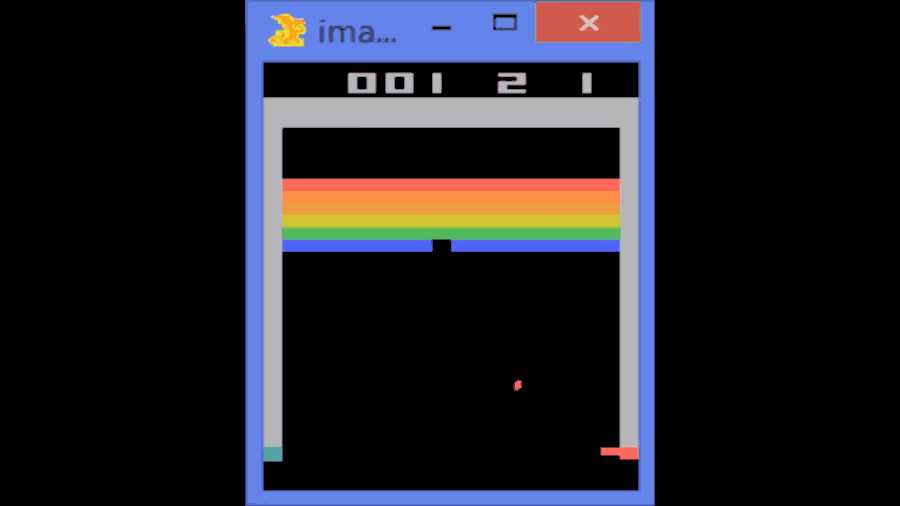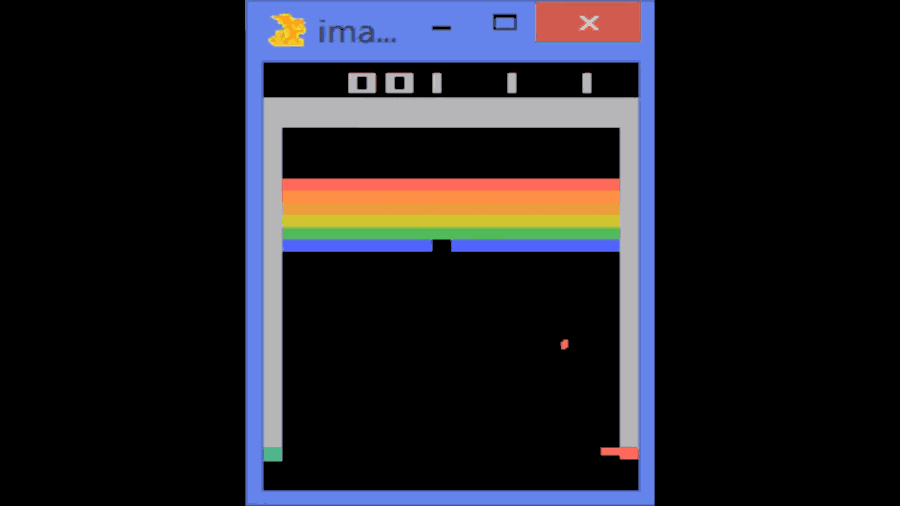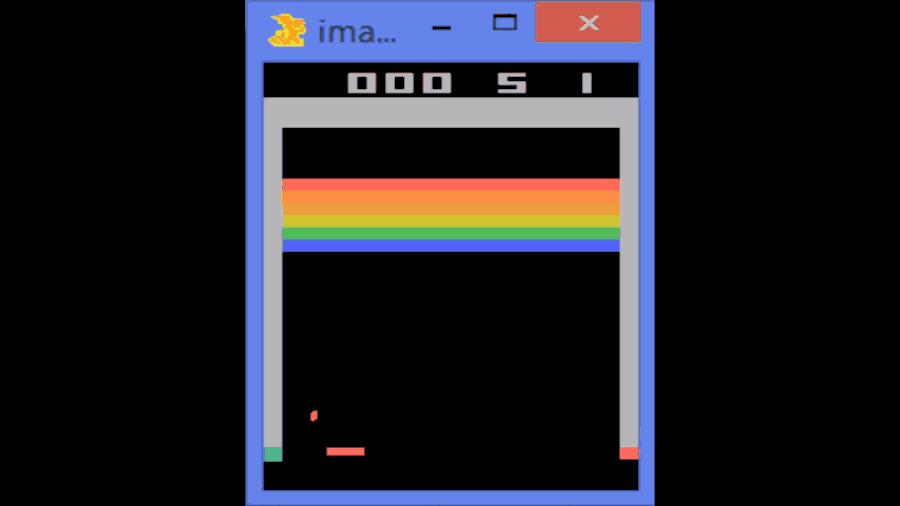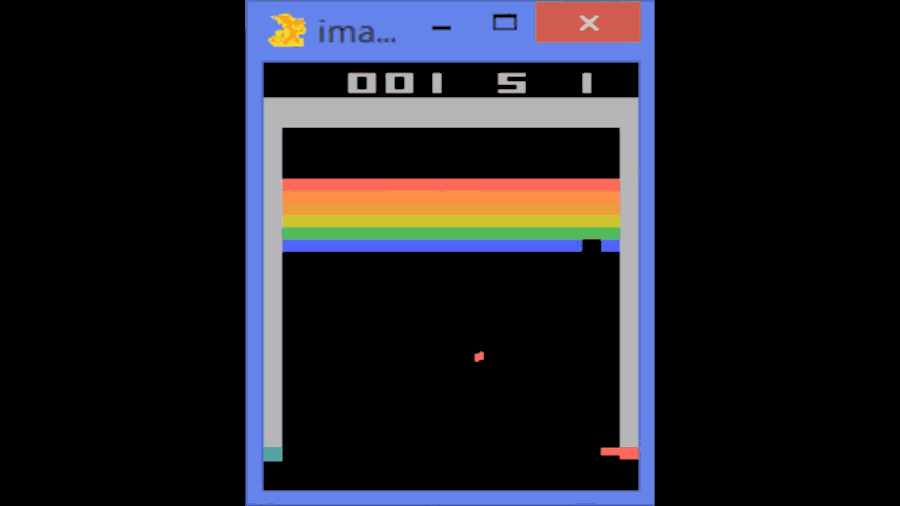
這個算法的原理和動物學習新事物的方法類似。它會觀察環境,嘗試不同的行動然後看它是否奏效。如果奏效,它就會繼續下去;如果不行,它就會去嘗試其他的東西。
算法背後是基於神經網絡和強化學習的結合。神經網絡系統用來理解視頻,而強化學習則會實施一系列高效的動作,也就是玩遊戲的那部分。強化學習非常適合那些處於複雜多變的環境中的任務。我們需要根據周圍的環境選擇合適的動作,以便儘可能的多得分。
但是,就早期的算法而言,只要玩遊戲的時間一長,它的表現就會變差。(比如,你家小汪在第一次吃到狗糧時開心得抓狂,但是越到後面刺激越弱,它也就不會爲狗糧激動了。)
其中有兩個重要的原因,一個是因爲這個遊戲需要長遠考慮,這對強化學習算法是一個很棘手的問題。第二個原因是,玩家會犯一些難以挽回的錯誤。比如,把箱子推到一個了死角,那他就過不了這一關了,除非我們有一個算法,它能試很多次然後看箱子是不是固定不動。(唔,要實現還是非常有難度的)
根據本期論文顯示,DeepMind增強想象智能體能夠有效解決以上問題。
想知道它具體怎麼操作?學霸們還請自行閱讀論文以獲得更多細節。
論文原址:https://arxiv.org/abs/1707.06203
雷鋒網(公衆號:雷鋒網)AI研習社出品系列短視頻《 2 分鐘論文 》,帶大家用碎片時間閱覽前沿技術,瞭解 AI 領域的最新研究成果。歡迎關注雷鋒網雷鋒字幕組專欄,獲得更多AI知識~感謝志願者對本期內容作出貢獻。

