作者:Daniel A. Abolafia、Mohammad Norouzi、Quoc V. Le
由谷歌大腦 Quoc V. Le 團隊提交的論文提出了一種使用循環神經網絡進行程序合成的新方法——優先級隊列訓練(PQT)。目前,該論文已提交 ICLR 2018 大會,正在接受評議。
GitHub 鏈接:https://github.com/tensorflow/models/tree/master/research/brain_coder
自動程序合成是一項具備廣泛應用潛力的任務。傳統方法(如 Muggleton & de Raedt (1994); Angulin (1987))通常不使用機器學習,因此需要編程語言和手動啓發式方法方面的專業知識來加速底層組合搜索。爲了創建無需領域專業知識的更通用的編程工具,近期大量研究開始開發神經模型,可促進某種形式的內存訪問和符號推理(如 Reed & de Freitas (2016); Neelakantan et al. (2016); Kaiser & Sutskever (2016); Zaremba et al. (2016); Graves et al. (2016))。儘管這些研究取得了很大成果,但是沒有一種方法能夠用富於表達性的編程語言合成源代碼。
近期出現了多項使用神經網絡從輸入-輸出示例導出程序的成功嘗試(Riedel et al., 2016; Bunel et al., 2016; Balog et al., 2017; Parisotto et al., 2016),甚至從非結構化文本生成程序(Parisotto et al., 2016),但是它們通常使用限制性編程語法,需要真正程序或正確輸出形式的監控信號。與之相反,本論文提倡使用富於表達性的編程語言 BF,其語法簡單,且圖靈完備。此外,本論文旨在使用強化學習合成程序,只需要一個 solution checker 就可以計算獎勵信號。你可以將代碼長度罰分或執行速度納入獎勵信號,進而搜索高效的短程序。因此,相比訓練過程中需要程序或正確輸出的其他方式,基於獎勵的程序合成具備更高的靈活性。
爲解決基於獎勵信號的程序合成,本論文研究了兩種不同方法。第一種方法是策略梯度(PG)算法(Williams, 1992),訓練一個循環神經網絡(RNN)來生成程序,每次生成一個 token。然後執行該程序並打分,獎勵反饋將返回至 RNN 以更新參數,這樣隨着時間,生成的程序將越來越好。第二個方法是一種欺騙性的簡單優化算法——優先級隊列訓練(priority queue training,PQT)。訓練過程中保持 K 個最優程序的優先級隊列可見,對隊列中前 K 個程序使用對數似然目標函數來訓練 RNN。然後從 RNN 中採樣新程序,更新隊列,進行迭代。本論文還對比了遺傳算法(GA)基線(之前證明其可生成 BF 程序,Becker & Gottschlich (2017))。令人驚訝的是,論文發現 PQT 算法顯著優於 GA 和 PG 方法。
論文在 BF 編程語言上評估了提出方法的有效性。BF 語言是圖靈完備的語言,僅有 8 條指令。BF 語言的極簡語法使之易於生成語法正確的程序,這與比較高級的語言相反。本論文考慮了不同字符串操作、數值和算法任務。結果顯示文中考慮的所有搜索算法在大部分任務中都能夠找到正確的程序,而論文提出的方法是最可靠的,因爲它是在最隨機的種子上找到解決方案的,且可以解決的任務也是最多的。
本論文的主要貢獻:
提出一個程序合成學習框架,訓練過程中僅需要獎勵函數(無需真正程序或正確輸出)。此外,論文提倡使用簡單且富於表達性的編程語言 BF 作爲程序合成的基準環境(還可以參考 Becker & Gottschlich (2017))。
受 Liang et al. (2017) 論文的啓發,本論文使用優先級隊列和 RNN 的搜索算法進行實驗,並展示了將優先級隊列作爲 RNN 的訓練目標是一種高效、穩定的方法。
提出一種實驗方法來對比不同的程序合成方法,包括遺傳算法和策略梯度方法。該方法評估了每個合成方法的平均成功率,並提供了一種調整超參數的標準方法。使用該方法,研究者發現使用優先級隊列訓練的循環神經網絡優於基線模型。
方法
研究者實現了一個程序生成模型,即每次輸出一串 BF 語言字符串的 RNN。圖 2 展示了 RNN 模型,允許用自迴歸方式採樣 BF 字符串,即將前一個預測作爲下一步的輸入。第一步的輸入是特殊的 START 符號。RNN 生成特殊的 EOS 符號時終止,該符號表示字符串終結,或者程序長度超出預先指定的最大長度。每個時間步的預測通過多項式分佈(一種多個時間步共享權重的 softmax 層)進行採樣。程序序列的聯合概率是所有 token 概率的積。
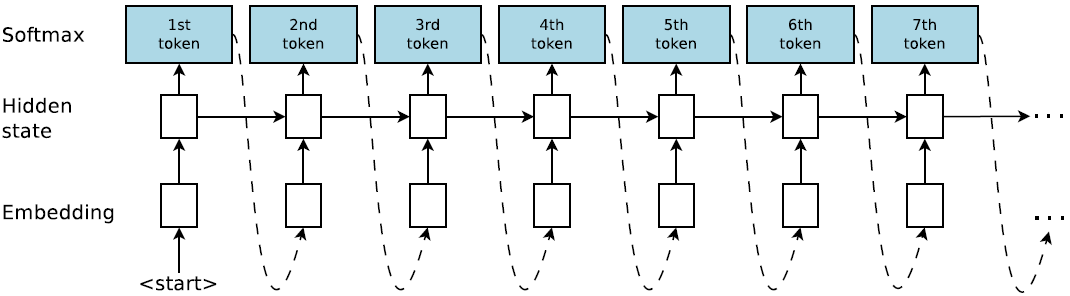
圖 1:合成器圖示。合成器是一個循環神經網絡,以自迴歸的方式生成程序。
表 3 展示了相同的算法加上均勻隨機搜索的成功率,以及訓練和評估測試案例的成功率。研究者還在最後一行列出平均值,進行各列之間的整體對比。從表中可知,根據訓練和評估平均值,PQT 要明顯優於 PG 和 GA。PG+PQT 僅與 PQT 相當。由於過擬合,在很多情況下評估成功率要低於訓練成功率。
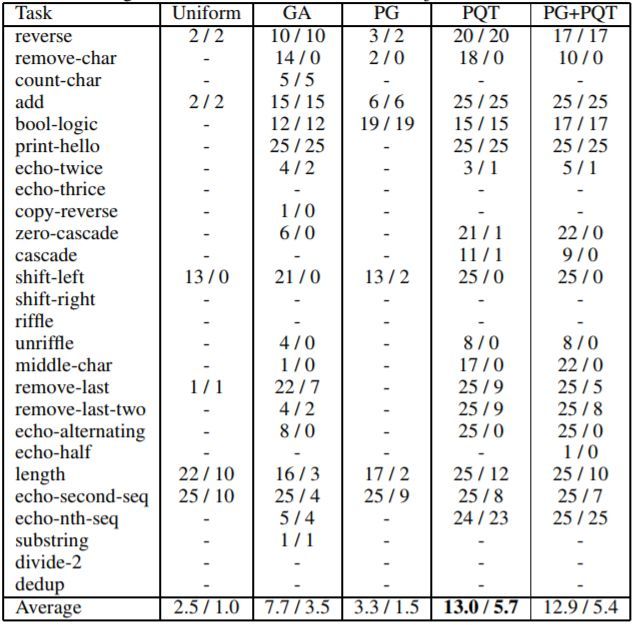
表 3:當執行程序的最大數(max NPE)是 20M 時,在所有任務上合成方法成功的數量(25 個之中)。單元格中有斜槓分割的兩個數。第一個數是訓練測試案例中的成功數量,第二個數是留出評估測試案例中的成功數量。對於無法合成滿足某個任務訓練案例的方法,用短線進行標記。

表 4:用於已解決任務的合成 BF 程序。所有程序由原本的智能體發現,並且沒有任何代碼字符被刪除或改變。注意,一些程序與任務產生過擬合。我們標紅了代碼方案過擬合的所有任務(經過手動檢查確定)。
論文:Neural Program Synthesis with Priority Queue Training

論文鏈接:https://arxiv.org/abs/1801.03526
摘要:我們認爲程序合成任務是在程序的輸出中存在一個獎勵函數,目標是找到獎勵最大的程序。我們採用了一種迭代優化方案,在這種方法中,我們在目前已生成的 K 個最佳程序數據集上訓練一個 RNN 模型。隨後,我們合成新的程序,並通過 RNN 採樣將它們添加到優先級隊列中。我們使用一種簡單但富於表達性的圖靈完備語言 BF,對該算法(優先級隊列訓練,PQT)與遺傳算法和強化學習基線進行了對比。實驗結果證明簡單的 PQT 算法顯著優於基線。通過在獎勵函數中添加程序長度罰分,我們就可以生成簡短、人類可讀的程序。