選自FreeCodeCamp
作者:Thalles Silva
生成對抗網絡因爲優雅的創意和優秀的性能吸引了很多研究者與開發者,本文從簡潔的案例出發詳解解釋了 DCGAN,包括生成器的解卷積和判別器的卷積過程。此外,本文還詳細說明了 DCGAN 的實現過程,是非常好的實踐教程。
熱身
假設你附近有個很棒的派對,你真的非常想去。但是,存在一個問題。爲了參加聚會,你需要一張特價票——但是,票已經賣完了。
等等!難道這不是關於生成對抗網絡(Generative Adversarial Network)的文章嗎?是的,沒錯。但是請先忍忍吧,這個小故事還是很值得一說的。
好的,由於派對的期望值很高,組織者聘請了一個有資質的安全機構。他們的主要目標是不允許任何人破壞派對。爲了做到這一點,場地的入口安排了很多警衛,檢查每個人門票的真實性。
你並沒有什麼武打天賦能硬闖進去。所以,唯一的途徑是通過一張非常有說服力的假票瞞天過海。
不過,這個計劃存在一個很大的問題——你沒見過真票長什麼樣。
即使根據自己的創造力設計了一張票,你是不可能在第一次嘗試時能騙過警衛的。此外,如果沒有一張足夠真實的派對假票,帶着自己做的假票進門無異於自投羅網。
爲了解決這個問題,你決定打電話給你的朋友 Bob 幫你點忙。
Bob 的任務非常簡單。他將用你做的假票嘗試混進派對中去。如果他被拒之門外,他將爲你帶回有關票面樣式的有用提示。
基於這個反饋,你可以再試着做一張新版假票交給 Bob,讓他再試一次。這個過程不斷重複,直到你能僞造一張完美的假票。
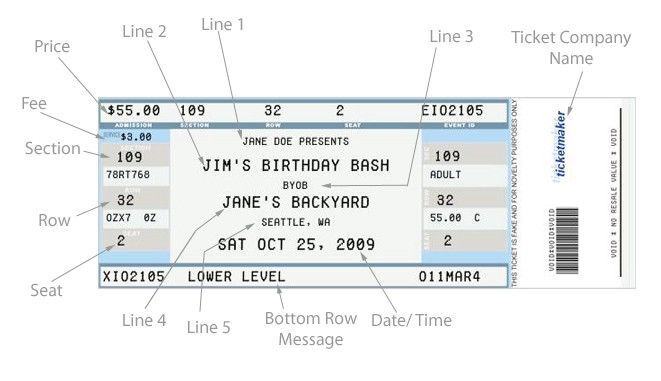
這個派對非去不可!實際上,上圖是從一個假票生成器網站上覆制下來的!
撇開「假票事件」,這幾乎是生成對抗網絡(GAN)所做的全部工作。
目前,GAN 的大部分應用都在計算機視覺領域。其中的一些應用包括訓練半監督分類器,並利用低分辨率的圖像生成高分辨率的圖像。
本文通過親手處理生成圖像的問題來介紹 GAN。你可以在以下地址找到本文的 Github 代碼。
項目地址:https://github.com/sthalles/blog-resources/blob/master/dcgan/DCGAN.ipynb
生成對抗網絡
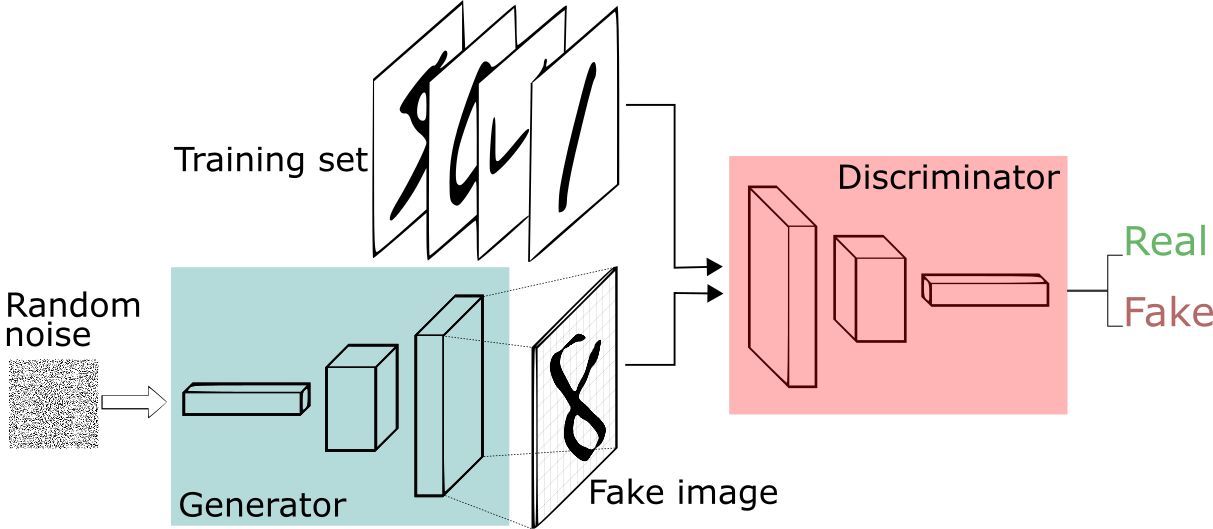
生成式對抗網絡框架
GAN 是由 Goodfellow 等人設計的生成模型(參見論文
Generative Adversarial Networks,2014,Ian J. Goodfellow et al.)。在 GAN 的設計中,由神經網絡表示的兩個可微函數被鎖定在這場極大極小博弈中。這兩個參與者(即生成器和判別器)在這個框架中扮演着不同的角色。
生成器(generator)試圖產生來自某種概率分佈的數據。換句話說,它代表着上述故事中的你——企圖生成派對的門票。
判別器(discriminator)像一個法官,它可以判定輸入是來自生成器還是真正的訓練集。這也就代表着故事中的警衛——將你的假票和真票進行對比,找出設計的缺陷。
我們用帶有批歸一化的 4 層卷積網絡構建生成器和判別器,訓練該模型將生成 SVHN 和 MNIST 圖像。
總而言之,遊戲規則如下:
生成器試圖使判別器發生錯誤判斷的概率最大化。
判別器引導生成器產生更逼真的圖像。
在理想的平衡狀態中,生成器將捕獲訓練數據的一般性分佈。因此,判別器將總是不能確定其輸入是否真實。
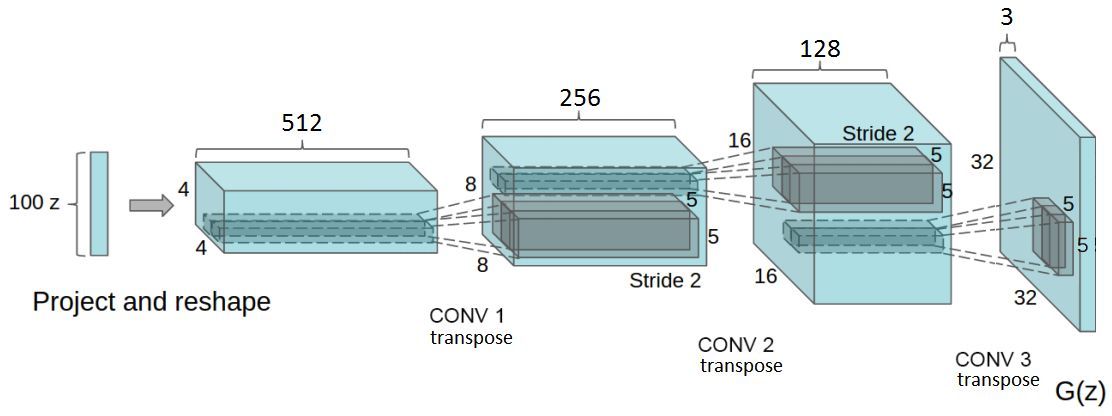
以上改編自 DCGAN 論文,是生成器網絡的實現方式。請注意全連接層和池化層並不存在。
在 DCGAN 論文(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)中,作者描述了深度學習技術的結合,這是訓練 GAN 的 關鍵。這些技術包括:(i)全卷積網絡和(ii)批歸一化(BN)。
前者強調 Strided Convolutions(以替代池化層):增加和減少特徵空間的維度。而後者歸一化特徵向量,從而顯著地減少多層之間的協調更新問題。這有助於穩定學習,並能幫助處理糟糕的權重初始化問題。
不必多說,讓我們深入實施細節,在細節中同時多談談 GAN。下面,我們展示了深度卷積生成對抗網絡(DCGAN)的實現方法。我們遵循 DCGAN 論文中描述的實踐方法,使用 Tensorflow 框架進行實現。
生成器
生成器網絡有 4 個卷積層。除輸出層外,其他所有層後都緊接着批歸一化(BN)和線性修正單元(ReLU)進行激活。
它將隨機向量 z(從正態分佈中抽取)作爲輸入。把向量 z 進行四維重塑後,將其送入生成器,啓動一系列上採樣層。
每個上採樣層都代表一個步長爲 2 的轉置卷積運算。轉置卷積運算與常規卷積運算類似。
一般而言,常規卷積運算的層從寬而淺到窄而深。而轉置卷積運算恰好相反:其層從窄而深到寬而淺。
轉置卷積運算操作的步長定義了輸出層的大小。在使用'same'填充、步長爲 2 時,輸出特徵圖的尺寸將是輸入層大小的兩倍。
這是因爲,每當我們移動輸入層中的一個像素時,我們都會將輸出層上的卷積核移動兩個像素。換句話說,輸入圖像中的每個像素都被用於在輸出圖像中繪製一個正方形。
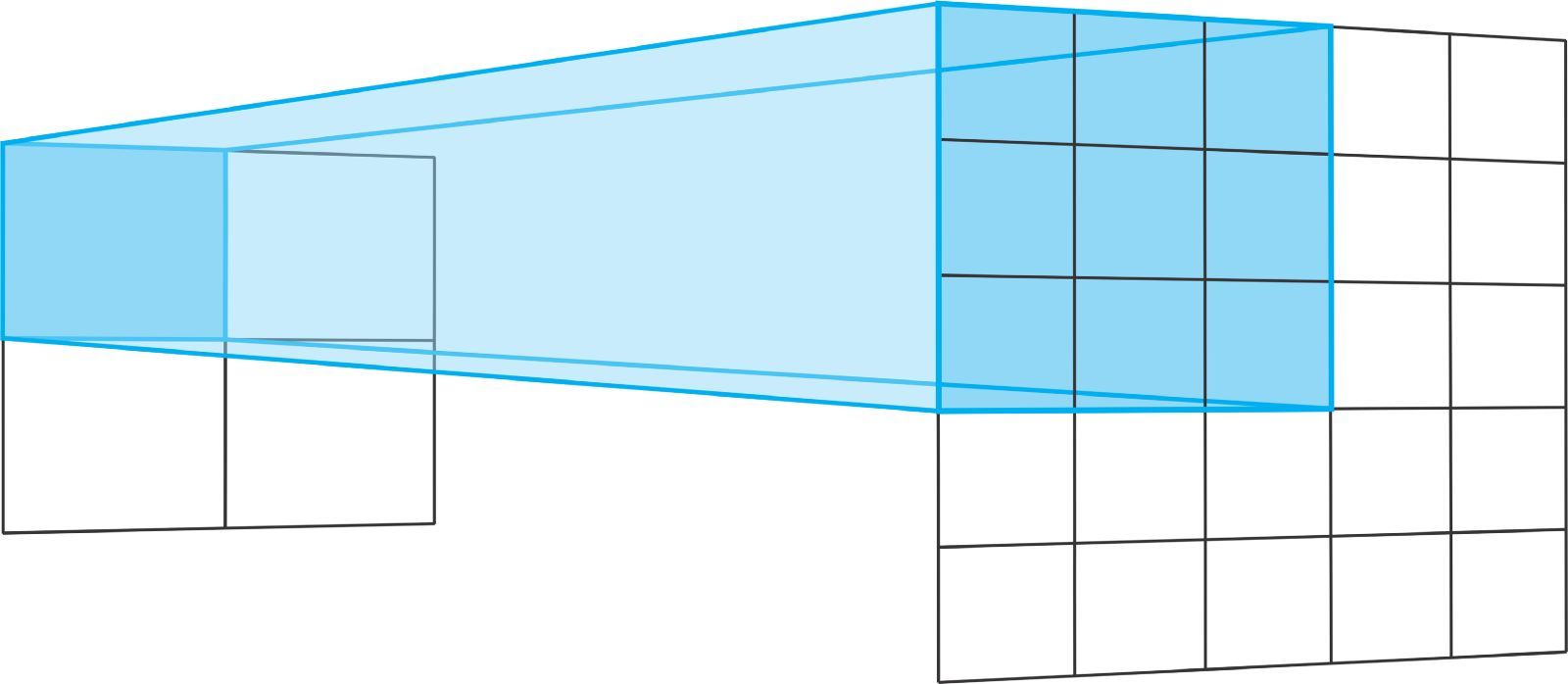
將 3x3 的卷積核在 2x2 的輸入上進行步長爲 2 的轉置卷積運算,相當於將 3x3 的卷積核在 5x5 的輸入上進行步長爲 2 的常規卷積運算。對於二者,均使用不帶零填充的「VALID」。
簡而言之,窄而深的的輸入向量是生成器的開始。在每次轉置卷積之後,z 變得更加寬而淺。所有轉置卷積運算都使用 5x5 大小的卷積核,其深度從 512 逐漸降到 3——此處的 3 代表 RGB 彩色圖像的 3 個通道。
deftranspose_conv2d(x, output_space):
returntf.layers.conv2d_transpose(x, output_space,
kernel_size=5, strides=2, padding='same',
kernel_initializer=tf.random_normal_initializer(mean=0.0,
stddev=0.02))
最後一層輸出一個 32x32x3 的張量並使用 tanh 函數將值壓縮在 -1 和 1 之間。
最終的輸出尺寸由訓練集圖像的大小定義。在這種情況下,如果對 SVHN 進行訓練,生成器將產生 32x32x3 的圖像。但是,如果對 MNIST 進行訓練,則會生成 28x28 的灰度圖像。
最後,請注意,將輸入矢量 z 傳送到生成器前,需要將其縮放到 -1 到 1 的區間,以遵循 tanh 函數的使用規則。
defgenerator(z, output_dim, reuse=False, alpha=0.2, training=True):
"""
Defines the generator network
:param z: input random vector z
:param output_dim: output dimension of the network
:param reuse: Indicates whether or not the existing model variables should be used or recreated
:param alpha: scalar for lrelu activation function
:param training: Boolean for controlling the batch normalization statistics
:return: model's output
"""
withtf.variable_scope('generator', reuse=reuse):
fc1 = dense(z, 4*4*512) # Reshape it to start the convolutional stack
fc1 = tf.reshape(fc1, (-1, 4, 4, 512))
fc1 = batch_norm(fc1, training=training)
fc1 = tf.nn.relu(fc1)
t_conv1 = transpose_conv2d(fc1, 256)
t_conv1 = batch_norm(t_conv1, training=training)
t_conv1 = tf.nn.relu(t_conv1)
t_conv2 = transpose_conv2d(t_conv1, 128)
t_conv2 = batch_norm(t_conv2, training=training)
t_conv2 = tf.nn.relu(t_conv2)
logits = transpose_conv2d(t_conv2, output_dim)
out = tf.tanh(logits) returnout
判別器
判別器也是一個帶有 BN(輸入層除外)的 4 層 CNN,並使用 leaky ReLU 進行激活。在基本的 GAN 結構中,有許多激活函數能正常工作。但是 leaky ReLU 尤爲受歡迎,因爲它可以使得梯度在結構中更容易傳播。
常規 ReLU 函數通過將負值截斷爲 0 起作用。這可能有阻止梯度在網絡中傳播的效果。然而,在輸入負值時,leaky ReLU 函數值不爲零,因此允許一個小的負值通過。也就是說,該函數計算的是輸入特徵和一個極小因子之間的最大值。
deflrelu(x, alpha=0.2):
# non-linear activation function
returntf.maximum(alpha * x, x)
Leaky ReLU 試圖解決 ReLU 的梯度消失問題。如果神經元陷入這種情況,即對任意輸入,ReLU 單元總是輸出爲 0,就會出現梯度消失。對於這些情況,梯度完全消失,網絡無法進行反向傳播。
這對於 GAN 來說尤其重要。這是因爲,生成器學習的唯一方式是接收判別器的梯度。
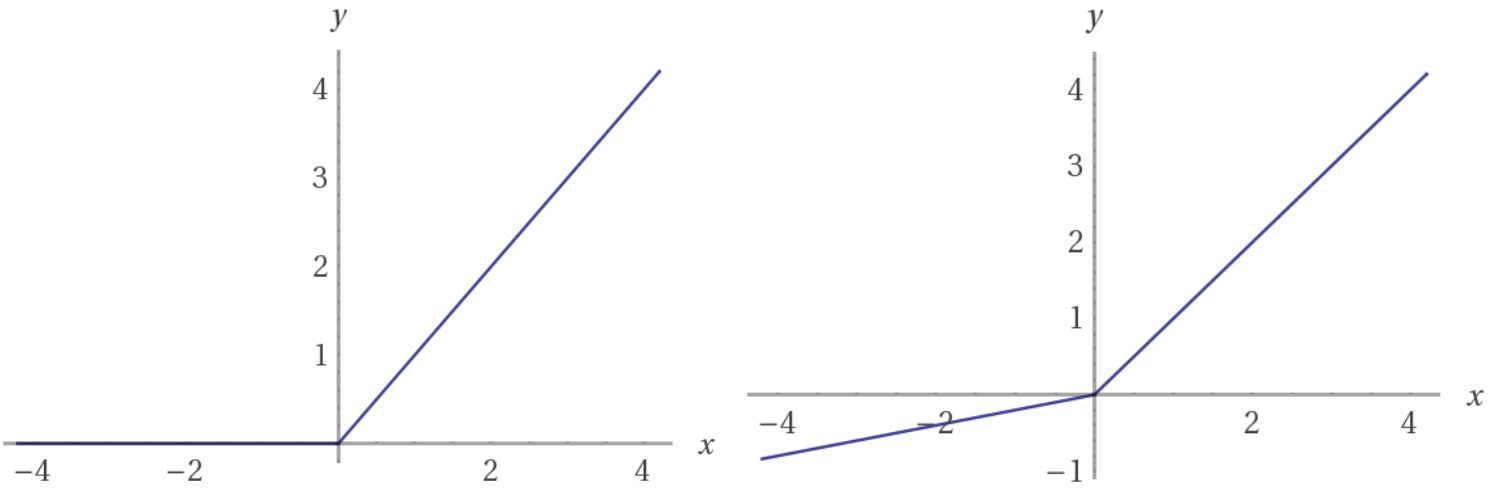
激活函數:ReLU(左),Leaky ReLU(右)。請注意,當 x 爲負值時,Leaky ReLU 有一個很小的斜率。
一開始,判別器會收到一個 32x32x3 圖像張量。與生成器相反,判別器執行一系列步長爲 2 的常規卷積運算。每經過一次卷積,特徵向量的空間維度就會減少一半,而訓練的卷積核數量會加倍。
最後,判別器需要輸出概率。爲此,我們在最後一層使用 Sigmoid 激活函數。
defdiscriminator(x, reuse=False, alpha=0.2, training=True):
"""
Defines the discriminator network
:param x: input for network
:param reuse: Indicates whether or not the existing model variables should be used or recreated
:param alpha: scalar for lrelu activation function
:param training: Boolean for controlling the batch normalization statistics
:return: A tuple of (sigmoid probabilities, logits)
"""
withtf.variable_scope('discriminator', reuse=reuse): # Input layer is 32x32x?
conv1 = conv2d(x, 64)
conv1 = lrelu(conv1, alpha)
conv2 = conv2d(conv1, 128)
conv2 = batch_norm(conv2, training=training)
conv2 = lrelu(conv2, alpha)
conv3 = conv2d(conv2, 256)
conv3 = batch_norm(conv3, training=training)
conv3 = lrelu(conv3, alpha) # Flatten it
flat = tf.reshape(conv3, (-1, 4*4*256))
logits = dense(flat, 1)
out = tf.sigmoid(logits) returnout, logits
請注意,在此框架中,判別器的角色是一個常規二元分類器。在一半時間裏,它從訓練集接收圖像,另一半時間從生成器接收圖像。
現在再回到我們的派對門票事件。爲了僞造假票,唯一的信息來源是朋友 Bob 的反饋。換句話說,在每次嘗試中,Bob 提供的反饋質量對於完成工作至關重要。
同樣地,每當判別器注意到真實圖像和虛假圖像之間的差異時,它就向生成器發送一個信號。該信號是從判別器向生成器反向傳播的梯度。通過接收它,生成器能調整其參數,從而接近真實數據的分佈。
這就顯示了判別器的重要性。事實上,生成器生成的數據有多棒,判別器區分它們的能力就有多強。
損失函數
現在,讓我們來描述這個結構中最棘手的部分——損失函數。首先,我們知道,判別器從訓練集和生成器中接收圖像。
我們希望判別器能區分真實和虛假的圖像。每當我們通過判別器運行一個小批量值時,我們都會得到 logits。這些是來自模型未經縮放的值。
不過,我們可以將判別器接收的小批量分成兩種類型。第一種僅由來自訓練集的真實圖像組成,第二種僅由生成器創造的虛假圖像組成。
defmodel_loss(input_real, input_z, output_dim, alpha=0.2, smooth=0.1):
"""
Get the loss for the discriminator and generator
:param input_real: Images from the real dataset
:param input_z: random vector z
:param out_channel_dim: The number of channels in the output image
:param smooth: label smothing scalar
:return: A tuple of (discriminator loss, generator loss)
"""
g_model = generator(input_z, output_dim, alpha=alpha)
d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
d_model_fake, d_logits_fake = discriminator(g_model, reuse=True, alpha=alpha) # for the real images, we want them to be classified as positives,
# so we want their labels to be all ones.
# notice here we use label smoothing for helping the discriminator to generalize better.
# Label smoothing works by avoiding the classifier to make extreme predictions when extrapolating.
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1- smooth))) # for the fake images produced by the generator, we want the discriminator to clissify them as false images,
# so we set their labels to be all zeros.
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_model_fake))) # since the generator wants the discriminator to output 1s for its images, it uses the discriminator logits for the
# fake images and assign labels of 1s to them.
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_model_fake)))
d_loss = d_loss_real + d_loss_fake returnd_loss, g_loss
由於兩個網絡同時訓練,GAN 也需要兩個優化器。它們分別用於最小化判別器和生成器的損失函數。
我們希望,判別器對真實圖像輸出接近 1 的概率,對虛假圖像輸出接近 0 的概率。爲了做到這一點,判別器需要兩類損失,其總損失函數是兩部分損失函數之和。其中之一用於最大化真實圖像的概率,另一個用於最小化虛假圖像的概率。

比較實際(左)和生成(右)的 SVHN 樣本圖像。雖然有些圖像看起來很模糊,有些圖像很難辨認,但顯而易見的是,數據分佈是由模型捕獲的。
訓練開始時,會出現兩個有趣的情況。其一,生成器不知如何創建和訓練集類似的圖像。其二,判別器不知如何將其接收的圖像進行分類爲「真」或「假」。
因此,判別器接收兩類有顯著差異的批數據。一個由訓練集的真實圖像組成,另一個則包含高噪聲的信號。隨着訓練的進行,生成器開始輸出更接近訓練集圖像的圖像。這是因爲生成器不斷訓練,學習了組成訓練集圖像的數據分佈。
與此同時,判別器開始越來越好,它變得很擅長將樣品分類爲真或假。結果,這兩種小批量數據在結構上開始變得相似。因此,判別器無法識別圖像的真假。
我們使用原版的交叉熵作爲損失函數,且 Adam 作爲該函數的優化器也是一個不錯的選擇。

比較實際(左)和生成(右)的 MNIST 樣本圖像。因爲 MNIST 圖像數據結構更簡單,所以與 SVHN 相比,該模型能夠產生更逼真的樣本。
總結
GAN 是機器學習中目前最熱門的話題之一。這些模型也許可以打開無監督學習的大門,將機器學習擴展到新的視野中。
自 GAN 創立以來,研究人員已經開發出許多用於訓練 GAN 的技術。在這些用於訓練 GAN 的改進技術中,作者描述了用於圖像生成和半監督學習的最新技術。
如果你想深入瞭解這些主題,我推薦你閱讀生成模型(Generative Models)相關的內容:https://blog.openai.com/generative-models/#gan。
同時,你也可以看看半監督學習與 GAN(https://towardsdatascience.com/semi-supervised-learning-with-gans-9f3cb128c5e),以此獲得半監督學習上的應用。
原文鏈接:https://medium.freecodecamp.org/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394