生成對抗網絡 ( GAN )在圖像生成方面已經得到了廣泛的應用,目前基本上是 GAN 一家獨大,其它如 VAE 和流模型等在應用上都有一些差距。儘管 wasserstein 距離極大地提升了 GAN 的效果,但其仍在理論上存在訓練不穩定和模式丟失的問題。Facebook 的兩位研究者近日融合了兩種非對抗方法的優勢,並提出了一種名爲 GLANN 的新方法。
這種新方法在圖像生成上能與 GAN 相媲美,也許除了 VAE、Glow 和 Pixcel CNN,這種新模型也能加入到無監督生成的大家庭中。當然在即將到來的 2019 年中,我們也希望 GAN 之外的更多生成模型會得到更多的成長,也希望生成模型能有更多的新想法。

生成式圖像建模是計算機視覺長期以來的一大研究方向。無條件生成模型的目標是通過給定的有限數量的訓練樣本學習得到能生成整個圖像分佈的函數。生成對抗網絡(GAN)是一種新的圖像生成建模技術,在圖像生成任務上有廣泛的應用,原因在於:1)能訓練有效的無條件圖像生成器;2)幾乎是唯一一種能用於不同域之間無監督圖像轉換的方法(但還有 NAM 也能做圖像轉換);3)是一種有效的感知式圖像損失函數(例如 Pix2Pix)。
GAN 有明顯的優勢,但也有一些關鍵的缺點:1)GAN 很難訓練,具體表現包括訓練過程非常不穩定、訓練突然崩潰和對超參數極其敏感。2)GAN 有模式丟失(mode-dropping)問題——只能建模目標分佈的某些模式而非所有模式。例如如果我們用 GAN 生成 0 到 9 十個數字,那麼很可能 GAN 只關注生成「1」這個數字,而很少生成其它 9 個數字。
一般我們可以使用生日悖論(birthday paradox)來衡量模式丟失的程度:生成器成功建模的模式數量可以通過生成固定數量的圖像,並統計重複圖像的數量來估計。對 GAN 的實驗評估發現:學習到的模式數量顯著低於訓練分佈中的數量。
GAN 的缺陷讓研究者開始探索用非對抗式方案來訓練生成模型,GLO 和 IMLE 就是兩種這類方法。Bojanowski et al. 提出的 GLO 是將訓練圖像嵌入到一個低維空間中,並在該嵌入向量輸入到一個聯合訓練的深度生成器時重建它們。GLO 的優勢有:1)無模式丟失地編碼整個分佈;2)學習得到的隱含空間能與圖像的形義屬性相對應,即隱含編碼之間的歐幾里德距離對應於形義方面的含義差異。但 GLO 有一個關鍵缺點,即沒有一種從嵌入空間採樣新圖像的原則性方法。儘管 GLO 的提出者建議用一個高斯分佈來擬合訓練圖像的隱編碼,但這會導致圖像合成質量不高。
IMLE 則由 Li and Malik 提出,其訓練生成模型的方式是:從一個任意分佈採樣大量隱含編碼,使用一個訓練後的生成器將每個編碼映射到圖像域中並確保對於每張訓練圖像都存在一張相近的生成圖像。IMLE 的採樣很簡單,而且沒有模式丟失問題。類似於其它最近鄰方法,具體所用的指標對 IMLE 影響很大,尤其是當訓練集大小有限時。回想一下,儘管經典的 Cover-Hart 結果告訴我們最近鄰分類器的誤差率漸進地處於貝葉斯風險的二分之一範圍內,但當我們使用有限大小的示例樣本集時,選擇更好的指標能讓分類器的表現更好。當使用 L2 損失直接在圖像像素上訓練時,IMLE 合成的圖像是模糊不清的。
在本研究中,我們提出了一種名爲「生成式隱含最近鄰(GLANN:Generative Latent Nearest Neighbors)」的新技術,能夠訓練出與 GAN 質量相當或更優的生成模型。我們的方法首次使用了 GLO 來嵌入訓練圖像,從而克服了 IMLE 的指標問題。由 GLO 爲隱含空間引入的迷人的線性特性能讓歐幾里德度量在隱含空間 Z 中具有形義含義。我們訓練了一個基於 IMLE 的模型來實現任意噪聲分佈 E 和 GLO 隱含空間 Z 之間的映射。然後,GLO 生成器可以將生成得到的隱含編碼映射到像素空間,由此生成圖像。我們的 GLANN 方法集中了 IMLE 和 GLO 的雙重優勢:易採樣、能建模整個分佈、訓練穩定且能合成銳利的圖像。圖 1 給出了我們的方法的一種方案。
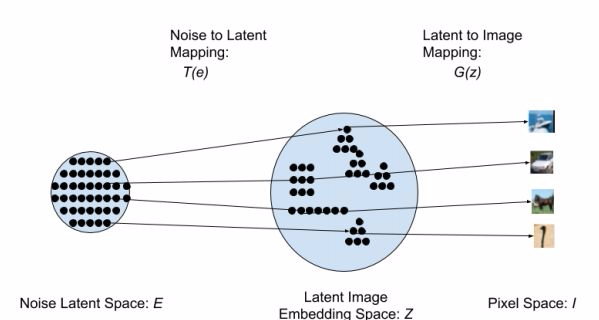
圖 1:我們的架構的示意圖:採樣一個隨機噪聲向量 e 並將其映射到隱含空間,得到隱含編碼 z = T(e)。該隱含編碼再由生成器投射到像素空間,得到圖像 I = G(z)
我們使用已確立的指標評估了我們的方法,發現其顯著優於其它的非對抗式方法,同時其表現也比當前的基於 GAN 的模型更優或表現相當。GLANN 也在高分辨率圖像生成和 3D 生成上得到了出色的結果。最後,我們表明 GLANN 訓練的模型是最早的能真正執行非對抗式無監督圖像轉換的模型。
論文:使用生成式隱含最近鄰的非對抗式圖像合成

論文鏈接:https://arxiv.org/pdf/1812.08985v1.pdf
生成對抗網絡(GAN)近來已經主導了無條件圖像生成領域。GAN 方法會訓練一個生成器和一個判別器,其中生成器根據隨機噪聲向量對圖像進行迴歸操作,判別器則會試圖分辨生成的圖像和訓練集中的真實圖像。GAN 已經在生成看似真實的圖像上取得了出色的表現。GAN 儘管很成功,但也有一些關鍵性缺陷:訓練不穩定和模式丟失。GAN 的缺陷正促使研究者研究替代方法,其中包括變分自編碼器(VAE)、隱含嵌入學習方法(比如 GLO)和基於最近鄰的隱式最大似然估計(IMLE)。不幸的是,目前 GAN 仍然在圖像生成方面顯著優於這些替代方法。在本研究中,我們提出了一種名爲「生成式隱含最近鄰(GLANN)」的全新方法,可不使用對抗訓練來訓練生成模型。GLANN 結合了 IMLE 和 GLO 兩者之長,克服了兩種方法各自的主要缺點。結果就是 GLANN 能生成比 IMLE 和 GLO 遠遠更好的圖像。我們的方法沒有困擾 GAN 訓練的模式崩潰問題,而且要穩定得多。定性結果表明 GLANN 在常用數據集上優於 800 個 GAN 和 VAE 構成的基線水平。研究還表明我們的模型可以有效地用於訓練真正的非對抗式無監督圖像轉換。
方法
我們提出的 GLANN(生成式隱含最近鄰)方法克服了 GLO 和 IMLE 兩者的缺點。GLANN 由兩個階段構成:1)使用 GLO 將高維的圖像空間嵌入到一個「行爲良好的」隱含空間;2)使用 IMLE 在一個任意分佈(通常是一個多維正態分佈)和該低維隱含空間之間執行映射。
實驗
爲了評估我們提出的方法的表現,我們執行了定量和定性實驗來比較我們的方法與已確立的基線水平。

表 1:生成質量(FID/ Frechet Inception Distance)
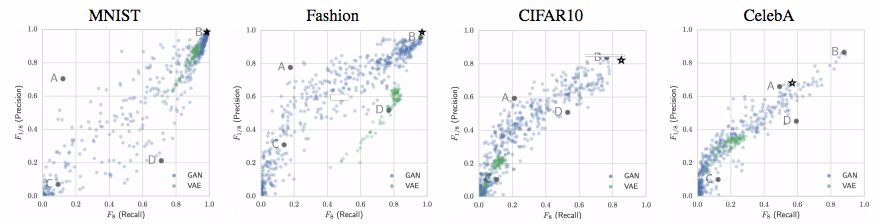
圖 2:在 4 個數據集上根據衡量的精度-召回率情況。這些圖表來自 [31]。我們用星標在相關圖表上標出了我們的模型在每個數據集上的結果。

圖 3:IMLE [24]、GLO [5]、GAN [25] 與我們的方法的合成結果比較。第一排:MNIST。第二排:Fashion。第三排:CIFAR10。最後一排:CelebA64。IMLE 下面空缺的部分在 [24] 中沒有給出。GAN 的結果來自 [25],對應於根據精度-召回率指標評估的 800 個生成模型中最好的一個。

圖 4:在 CelebA-HQ 上以 256×256 的分辨率得到的插值實驗結果。最左邊和最右邊的圖像是根據隨機噪聲隨機採樣得到的。中間的插值圖像很平滑而且視覺質量很高。

圖 5:在 CelebA-HQ 上以 1024×1024 的分辨率得到的插值實驗結果

圖 6:GLANN 生成的 3D 椅子圖像示例
討論
損失函數:在這項研究中,我們用一種感知損失(perceptual loss)代替了標準的對抗損失函數。在實踐中我們使用了 ImageNet 訓練後的 VGG 特徵。Zhang et al. [40] 宣稱自監督的感知損失的效果並不比 ImageNet 訓練的特徵差。因此,我們的方法很可能與自監督感知損失有相似的表現。
更高的分辨率:分辨率從 64×64 到 256×256 或 1024×1024 的增長是通過對損失函數進行簡單修改而實現的:感知損失是在原始圖像以及該圖像的一個雙線性下采樣版本上同時計算的。提升到更高的分辨率只簡單地需要更多下采樣層級。研究更復雜精細的感知損失也許還能進一步提升合成質量。
其它模態:我們這項研究關注的重點是圖像合成。我們相信我們的方法也可以擴展到很多其它模態,尤其是 3D 和視頻。我們的方法流程簡單,對超參數穩健,這些優點使其可比 GAN 遠遠更簡單地應用於其它模態。我們在 4.4 節給出了一些說明這一點的證據。未來的一大研究任務尋找可用於 2D 圖像之外的其它域的感知損失函數。
2018 人工智能期末考試正在進行中,衝擊「最高段位:王者機器」即有機會獲得「華爲雲獎學金」:66666元。
識別下方二維碼,立即開始答題。閱讀原文,查看考試攻略。