雷鋒網(公衆號:雷鋒網)按:本文來自英特爾中國研究院。
五月末的人機大戰讓世人大開眼界,頂級圍棋手柯潔落下的眼淚、微博的嘆息,都是對AlphaGo這顆強勁「大腦」的讚歎。然而,讓人工智能走出娛樂和遊戲,真正進入人類的實際生活,通過實現機器人的自主運動來爲人類提供服務同樣是我們長久以來的夢想。
但是,機器人的自主運動該如何實現?隨着深度學習部分解決了機器人的視聽識別問題,增強學習技術有望成爲突破機器人自主運動難題的一把利劍。
增強學習實際上是「試錯法」這一在生活中廣泛使用的技巧的理論抽象,即爲了達到理想目標而不斷試驗,並在實際嘗試中修正方案,從而逐步提高成功率。
比如在圍棋程序中,盤面情況稱爲「狀態」,落子選擇稱爲「行爲」;根據狀態選擇行爲的方法就稱爲「策略」,根據當前狀態和行爲對輸贏的預測就稱爲「價值」,而當前一步的輸贏結果稱爲「回報」。增強學習就是修正策略從而實現價值最大化的過程。
在2017年《麻省理工科技評論》全球十大突破性技術榜單中,增強學習技術高居榜首,並已在棋類運動和電腦遊戲領域獲得突破性進展,如AlphaGo使用增強學習技術擊敗世界圍棋冠軍柯潔,基於增強學習的電腦程序在一系列Atari遊戲中超過人類水平等。
那麼,針對機器人的運動控制問題,增強學習技術的運用存在哪些難點?我們又可以採取哪些有效的解決方法?今天,我們爲大家奉上六字真言:高、大、少;虛、先、近。
三個難點
與棋類運動和電腦遊戲不同,在機器人運動控制領域運用增強學習方法主要有以下三個難點:
「高」,即狀態和行爲維數高。比如讓機器人爲我們端杯水,需要增強學習算法提供如下的最優運動控制策略:憑藉具有深度、魚眼和普通圖像拍攝功能的實感TM攝像頭獲得圖像,分析出人和杯子的方向、距離、姿態以及人的表情,並通過聽覺獲得人發出命令的方位和急促程度,從而控制機器人(機械腿或底盤)走到人的面前;藉助機器人手獲得重量、溫度、滑動信息,依據人手的方位控制機器人手臂和手指各關節的實時角度。這個過程所涉及的狀態和行爲的維數以百萬計,而對每個狀態行爲進行價值(如人的滿意度)計算也非常困難。

機器人模型
「大」,即狀態信息誤差大。棋類運動中的狀態(盤面)信息完全準確,但機器人所面對的狀態信息,大多存在明顯誤差。如在遞水這個場景中,我們所獲得的人和杯子的方向、距離、姿態以及人的表情、動作信息都存在誤差。誤差可能是由機械振動或機器人運動等因素造成,也可能是因爲傳感器精度不夠高,存在噪聲,亦或是由於算法不夠精確。這些誤差都增加了增強學習的難度。
「少」,即樣本量少。不同於人臉等圖像識別任務中動輒百萬的訓練樣本,機器人增強學習可獲得的樣本數量少、成本高,主要原因是:機器人在運動過程中可能出現疲勞和損壞,還可能會對目標物或環境造成破壞;機器人的參數在運動中會發生改變;機器人運動需要一定的時間;很多機器人學習任務需要人的參與配合(如上述遞水場景中需要有人接水)。這些都使得獲得大量訓練樣本十分困難。
三種解決方法
面對上述困難,我們難道就無計可施了嗎?當然不是,科學家們提出了一整套解決問題的思路,主要有如下三點:
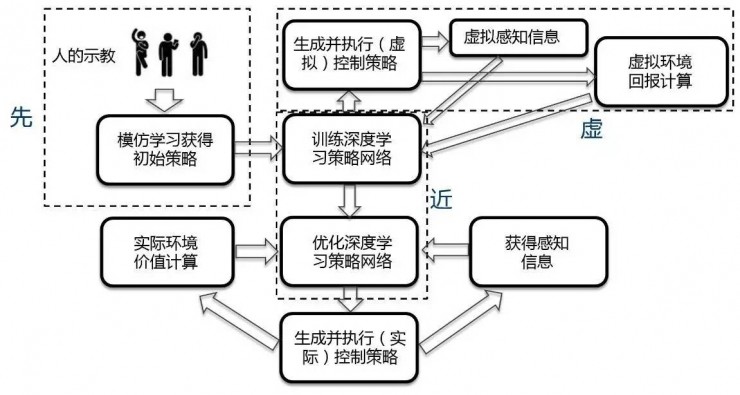
一個融合了「虛、先、近」三種策略的機器人運動控制增強學習框架
「虛」,即採用虛實結合的技術。我們可以通過程序虛擬出環境讓機器人進行預訓練,以克服實際採樣過程中可能出現的種種難題。虛擬軟件不但能模擬機器人的完整運動特性,如有幾個關節、每個關節能如何運動等,還能模擬機器人和環境作用的物理模型,如重力、壓力、摩擦力等。機器人可以在虛擬環境中先進行增強學習的訓練,直到訓練基本成功再在實際環境中進一步學習。虛實結合的增強學習主要面臨兩個挑戰。一個是如何保證虛擬環境中的學習結果在實際中仍然有效。面對這一難題,我們可以對虛擬環境與實際環境中的差別進行隨機性的建模,在虛擬環境中訓練時引入一些噪聲。另一個挑戰是如何實時獲得外部環境和目標的虛擬模型,最新的深度攝像頭可以幫助我們解決這個問題。
「先」,即先驗知識。引入先驗知識可以大幅降低增強學習優化的難度。先驗知識有很多種,但對於機器人而言,獲得先驗知識比較有效的途徑是「學徒學習」,即讓機器人模仿人的示教動作,再在應用中通過增強學習優化。由於機器人運動所面臨的狀態維數極高,通過手工輸入知識非常困難,而人做示範則較爲方便,還降低了先驗知識引入的門檻,不太瞭解機器人技術的人也可以進行。示教主要有三類方法:一是由人拖動機器手做動作;二是使用專門的運動捕捉設備獲得人的動作;三是直接使用深度攝像頭獲取人的動作。從長遠看,第三種方法會成爲以後的發展趨勢。
「近」,即近似。由於機器人運動控制的狀態維數高、樣本少且存在誤差,所以將維數高的狀態近似爲不丟失主要信息又能增加可訓練性的函數就成爲一項重要的選擇。使用近似方法提高增強學習算法性能的一大熱點就是將深度學習技術與增強學習相結合所形成的深度增強學習技術,此技術直接將機器人的狀態(如傳感器和關節狀態輸入)通過高層的卷積神經網絡映射爲機器人的動作輸出,大大提高了機器人基於增強學習進行運動控制的性能。該技術在近兩年來取得了突破性的進展。
上述解決方法爲增強學習在機器人動作控制領域的應用打開了大門,成爲機器人研究的重要方向之一,但目前還存在許多實際難題亟待解決。科研人員正在對深度增強學習、學徒學習(模仿學習)和虛實結合學習方面進行一系列探索。