選自arXiv
大規模分類技術對人臉識別等任務的實際應用有着切實的價值。香港中文大學和商湯科技近日公佈的一篇 AAAI 2018 論文介紹了一種旨在高效解決大規模分類問題的方法。我們對該研究成果進行了編譯介紹。
近些年來,在深度學習的發展和數據集的爆發式增長的推動下,人工智能領域已經見證了一波突破浪潮(Shakirov 2016)。伴隨着這一趨勢,涉及極大數量類別的大規模分類變成了一項重要的任務。這種任務常常出現在使用了工業級數據集的人臉識別(Sun, Wang, and Tang 2014)或語言建模(Chen, Grangier, and Auli 2015)等應用中。
大規模分類帶來了很多新難題,其中最爲突出的可能是訓練的計算難度。具體而言,現在的分類器常常採用的是深度網絡架構,其中通常包含一系列用於特徵提取的變換層和一個將頂層特徵表示與每種類別的響應連接起來的 softmax 層。這個 softmax 層的參數大小與類別的數量成正比。在訓練這樣一個分類器時,對於樣本構成的每個 mini-batch,都會通過求特定於類別的權重和被提取的特徵之間的點積來計算對所有相關類別的響應。當類別數量很大時,上面所描述的算法會面臨兩大顯著難題:(1)參數大小可能超出內存容量,尤其是當該網絡是在容量有限的 GPU 上訓練時;(2)計算成本將急劇增長,甚至達到無法實現的程度。
解決這些難題的現有方法(Mnih and Teh 2012; Jean et al. 2015; Wu et al. 2016)大都源自自然語言處理,這往往需要處理大型詞彙庫。這些方法具有一個共同思想:基於之前從訓練語料庫收集到的統計信息來重點關注常見詞。但是,我們往往難以將這些方法擴展到其它領域,因爲這些方法需要一個關鍵條件才能工作,即不同類別的頻率要高度不平衡。而人臉識別等應用卻並不存在這種情況。
我們在探索這一問題時進行了一項實證研究(見第 3 節)。在這項研究中,我們觀察到了兩個重要結果:(1)在大多數情況下,一個類別的樣本只會和少量其它類別產生混淆;(2)當使用了 softmax 損失時,對於每個樣本而言,從這個小的類別子集反向傳播回來的信號會主導其學習過程。這些觀察結果表明,對於每個樣本 mini-batch,在類別的一小部分上執行計算就足夠了,同時可排除影響可以忽略不計的其它類別。受這一研究的啓發,我們探索了一種用於解決大規模分類難題的新方法。我們的基本思想是開發一種可以識別少量活躍類別的方法,這些類別可以爲每個樣本 mini-batch 產生顯著的信號。這種方法需要即準確又有效。更具體而言,它應該要能正確識別那些與給定樣本真正相關的類別,但同時又不會造成過多的計算開銷。要同時滿足這兩個需求可不簡單。
我們實現這一目標的努力由兩個階段構成。首先,我們得到一個最優類別選擇器(optimal class selector)。我們通過實驗表明,通過使用活躍類別的最優選擇,學習後的網絡可以在每次迭代中僅使用選擇出的類別的 1% 就達到同等水平的表現。但是,這種最優選擇需要計算所有類別的響應,這個過程本身的成本就過於高昂。然後在第二個階段,我們基於動態類別層次開發出了這種最優選擇器的一種有效近似。這種動態類別層次能有效地得到類別之間的接近程度,我們可以將其用於近似地確定 mini-batch 的活躍類別,從而極大地降低成本。注意這裏的類別層次是根據與單個類別相關的權重向量動態更新的。因此,活躍類別的選擇同時考慮了樣本特徵和權重向量。這讓我們的方法有別於之前提到的依賴於先驗統計的方法。另外,我們觀察到真正的活躍類別的平均數量往往會隨着訓練的進行而減少,我們由此開發出了一種自適應的分配方案,這能實現成本和表現之間的更好權衡。
在大規模基準 LFW(Huang et al. 2007)、IJB-A(Klare et al. 2015)、Megaface(Kemelmacher-Shlizerman et al. 2016)上的實驗表明,我們的方法可以極大地降低訓練時間和內存需求。
論文:通過動態類別選擇加速用於大規模分類的訓練(Accelerated Training for Massive Classification via Dynamic Class Selection)

鏈接:https://arxiv.org/abs/1801.01687
大規模分類是指在數量很大的類別(成百上千乃至數百萬)上的分類任務,這已經變成了人臉識別等很多真實系統的一大關鍵部分。包括深度網絡在內的在近些年取得了顯著成功的現有方法基本上都是爲類別數量適中的問題所設計的。當被應用大規模問題時,這些方法會遇到很多難題,比如過大的內存需求和計算成本。我們提出了一種解決這個問題的新方法。這個方法可以基於一組在工作過程中構建的動態類別層次而有效且準確地爲每個 mini-batch 識別出少量「活躍類別(active class)」。我們還在此之上開發了一個自適應的分配方案,可以實現表現與成本之間的更好權衡。我們的方法在多種大規模基準上都能顯著降低訓練成本和內存需求,同時還能維持有競爭力的表現。
方法
我們的方法的基本思想是爲每個樣本 mini-batch 選擇數量較少的活躍類別,然後根據它們計算一個選擇性 softmax 和梯度。在這一節,我們首先會提供整個流程的一個概述,然後會繼續詳細討論選擇活躍類別的方法。具體來說,我們會從一個最優的但成本高昂的方案開始,然後基於動態類別層次開發一個有效的近似。此外,我們還會引入一個自適應分配方案,可以隨着網絡狀態的改變而調整算法參數,這樣可以實現表現與成本之間的更好平衡。最後,我們將給出我們的實現的有用細節。
選擇性 softmax
選擇性 softmax 相當於迫使非活躍類別的概率爲零,同時重新歸一化活躍類別的概率。如果活躍類別選擇正確,那麼這就會非常接近完全的 softmax,因爲非活躍類別原本的概率實際上就接近於零。由此,所得到的梯度也會近似接近於原來的梯度。
活躍類別的最優選擇
選擇性 softmax 能提供完整 softmax 的優良近似,同時還能顯著降低成本。但是,這種方法的有效性取決於我們是否能準確和有效地選擇活躍類別。這也是我們研究中的關鍵難題。
近似的選擇
我們提出使用哈希森林(HF:Hashing Forest)來近似最優的選擇方案。這種方法的要點是通過遞歸式的分割來將權重向量空間分割爲小單元。具體來說,一開始時整個空間只是一個單元,然後遞歸式地應用如下的隨機分割。在每次迭代中,它會選擇一個帶有超過 B 個點的單元,然後在其中隨機選擇一對點,然後使用最大邊界計算用於分割所選點的超平面。該超平面會將這個單元一分爲二。這個過程會持續進行,直到任何單元內的點都不超過 B 個。注意,這種遞歸式分割流程本質上是構建該單元的二元樹。算法 1 給出了構建該樹的總體流程。
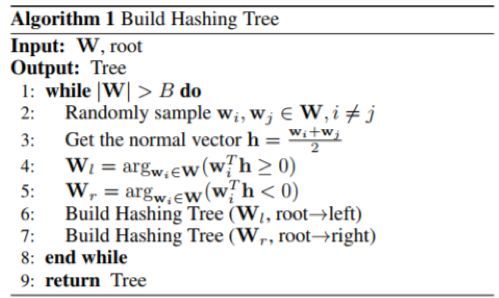
因爲每個單元都是以隨機的方式進行分割的,所以單個哈希樹可能不足以可靠地得到類之間的接近程度。爲了提升搜索的準確度,我們會構建 L 個哈希樹,它們集中到一起會形成一個哈希森林。樹的數量 L 可以根據成本和準確度之間的權衡通過實驗的方式確定。
自適應分配
第 3 節中的實證研究表明:由於模型的判別能力越來越強,預測的概率和梯度都會隨着訓練的進行而變得更加集中。受此啓發,我們提出了一種改進過的訓練方案,該方案能自適應地調整會影響計算資源的使用的參數(比如在早期 epoch 中允許更多活躍類別),從而有助於實現表現與成本之間的更好平衡。
該方案控制了三個參數:(1)M,每次迭代中活躍類別的數量;(2)L,哈希樹的數量;(3)結構更新的間隔 T。具體而言,我們會每隔 T 次迭代重建一次哈希森林,以保持更新。一般來說,在降低 T 的同時增大 M 和 L 可以提升表現,但會付出更高的計算成本。我們的策略是基於多種啓發式方法定期調整 M、L 和 T。具體而言,我們會將整個訓練過程分成幾個階段,我們會根據網絡更新後的狀態重置這些設計參數。
實現細節
爲了說明清晰,上面所討論的算法僅涉及一個實例。在實際過程中,我們會在每次迭代中使用多個實例構成的 mini-batch。用 X 表示從當前 mini-batch 提取出的一組特徵 x,那麼 S(X) 是 S(x) 的並集。另外,爲每次迭代中所使用的活躍類別集合設置一個最大大小也通常會很方便。當 S(X) 的基數大於最大大小時,將會應用基於活躍類別的重新歸一化概率的採樣。
實驗
方法比較
我們將我們提出的方法與多個基準進行了比較。下面簡要介紹了這些方法。
(1)Softmax:完整版本的 softmax,在每次迭代中所有類別都是活躍類別。
(2)Random:一種樸素的方法,會在每次迭代中隨機選擇固定數量的類別來進行 softmax 計算。
(3)PCA:一種簡單的哈希方法。它會將權重向量投射到一個低維空間,並會根據被投射向量的每個條目的極性將其編碼成二值哈希碼。對於來自類別 c 的樣本,會選擇具有相同哈希碼的類別。
(4)KMeans:另一種用於尋找活躍類別的簡單方法。它會根據對應的權重向量將所有類別聚類成 1024 組。對於來自類別 c 的樣本,會選擇包含 c 的組。
(5)Optimal:最優選擇方案,它會完整計算 Wx 並選擇具有最高響應的類別作爲活躍類別。這能提供表現的上限,但成本非常高昂。
(6)HF:我們提出的方法的基本版本,它使用一個會定期更新的哈希森林來近似最優選擇方案。
(7)HF-A:我們提出的方法的一個改進版本,使用了自適應分配方案來調節計算資源的使用,以便實現更好的平衡。
結果
我們在 MSCeleb-1M 上使用不同的方法訓練了網絡,並在 Megaface & Facescrub 上對它們進行了測試。表 1 給出了不同方法的一些數值結果。圖 2 在成本基礎上比較了它們的表現。這裏的表現是用 top-1 識別準確度衡量的,成本則包括類別選擇與計算受限的 softmax 和梯度的時間。
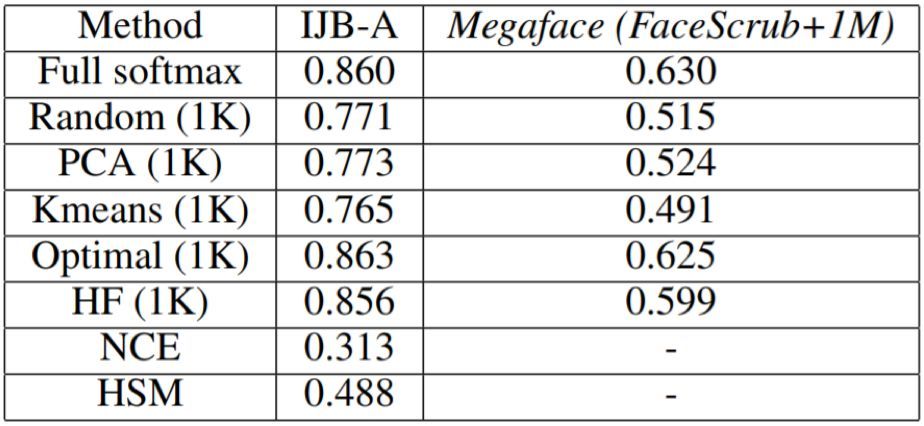
表 1:IJB-A 列中的量是當 FPR 爲 0.001 時的 TPR,在 Megaface 識別任務中的是 top-1 準確度
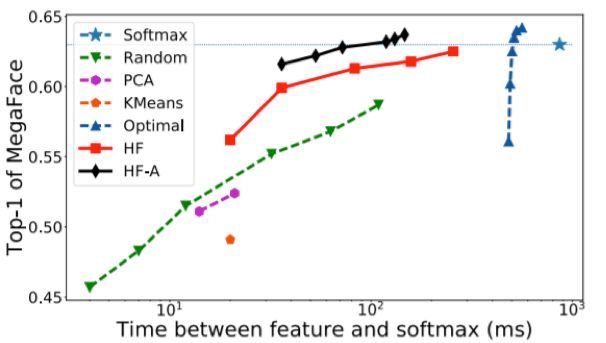
圖 2:不同方法的人臉識別準確度與對應的計算成本。當點在左上角時表示使用低成本實現了優良的表現。注意 x 軸是對數標度
結果表明:
(1)對於隨機採樣,當活躍類別數量增大時,表現會緩慢增長。這說明隨機採樣對於選擇活躍類別而言並不是一種有效的方法。
(2)K 均值和 PCA 等基於聚類的方法表現並不很好,這說明只使用權重向量的聚類而忽視樣本特徵 x 不足以得到優良的表現。
(3)最優選擇方法的表現非常好,甚至還略微超過了完全 softmax 方法。但這種方法在類別選擇方面開銷嚴重,因爲它需要計算所有類別的響應。
(4)我們的方法(HF)明顯顯著優於其它方法。在同等的成本基礎上,它可以得到顯著更好的表現。另一方面,爲了達到相同的表現,它所需的成本會低得多(有時候低差不多一個數量級)。
(5)HF-A 在基礎版本之上還有明顯的提升,這清楚地表明瞭自適應分配策略的優勢。值得注意的是,它只需完全 softmax 方法 10% 的成本就能超越其表現。這是一個出色的改進。
(6)噪聲對比估計(NCE)和 Hierarchical Softmax(HSM) 的結果遠不如經典方法。這樣的結果說明這兩種方法也許並不適合大規模分類問題。
圖 3 給出了相對於近似精度的表現,即所選擇的類別和最優選擇之間的平均重疊量。我們可以看到更好的近似通常會有更好的表現。由我們提出的 HF 方法所選擇的類別非常接近最優子集(比其它方法精確很多),由此能得到顯著更優的表現。
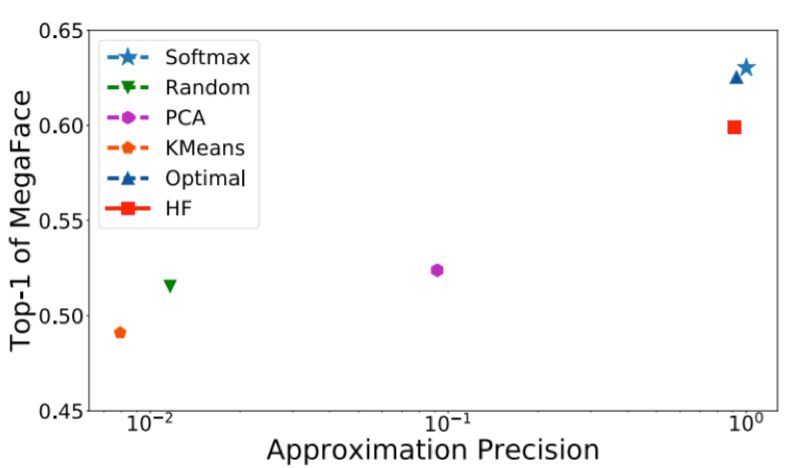
圖 3:不同方法的人臉識別準確度與近似精度。注意 x 軸是對數標度
大規模實驗
我們還使用 ResNet-101 進行了一次大規模實驗,其中訓練集是 MS-Celeb-1M 和 Megaface (MF2) 的並集,總共包含 75 萬個類別。訓練是在一臺帶有 8 個英偉達 Titan X GPU 的服務器上完成的。在這項實驗中,HF-A 可以將每次迭代的訓練時間從 3.5s 降低至 1.5s,也即提速 60%。注意這是指整個網絡的總體速度(而不只是 softmax 層)。另外,每個 GPU 的總體內存消耗也從 10.8G 降低至了 8.2G。這得益於 softmax 層對 GPU 內存的需求的極大減少,如表 2 所示。研究還表明我們的方法可以實現與完全 softmax 相媲美的表現,同時每次迭代僅需選擇 1% 的類別。這個結果說明我們的方法可以很好地延展到大規模分類問題上。
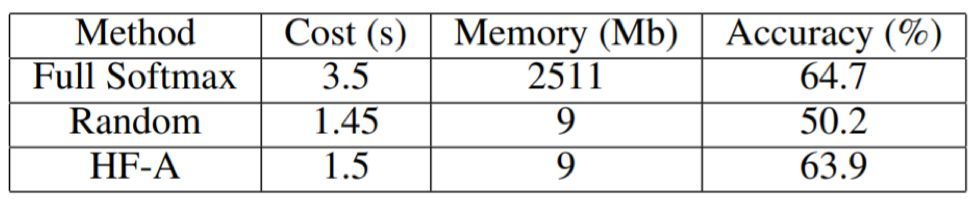
表 2:大規模實驗中的表現與成本
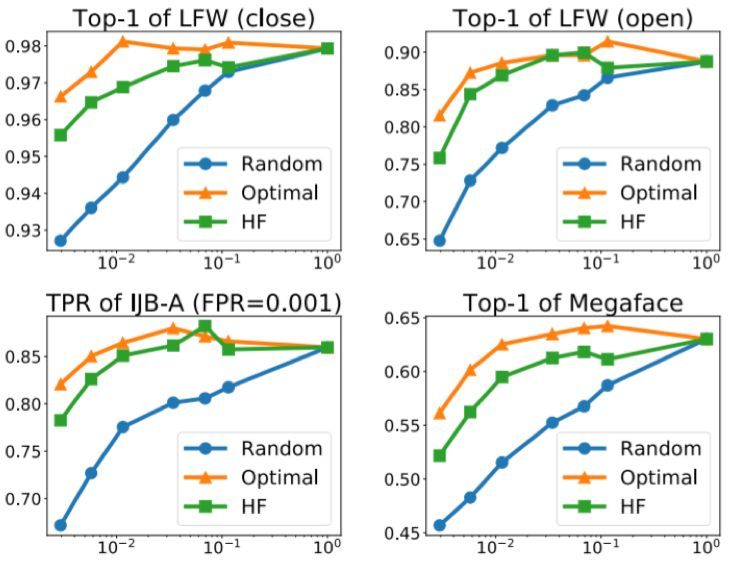
圖 4:Random、Optimal 和 HF 在不同數據集上使用不同的活躍類別數量 M 時所應對的表現
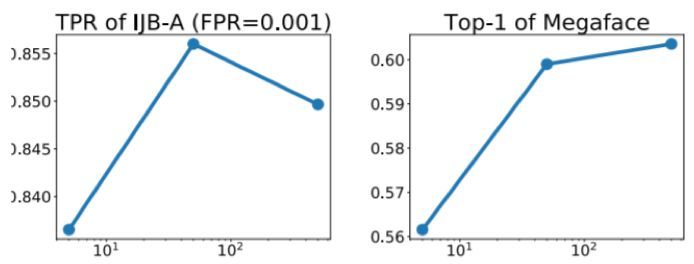
圖 5:不同的哈希樹數量 L 所應對的表現
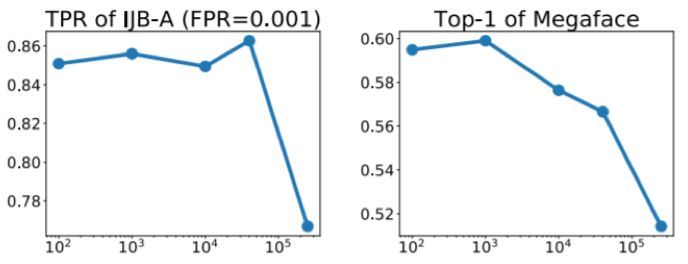
圖 6:不同的結構更新間隔 T 所應對的表現