數據集地址:https://sites.google.com/view/totally-looks-like-dataset
人類對圖像的感知遠遠超出了物體、形狀、紋理和輪廓這些因素。人們看到一個場景時通常會喚醒和當前場景在總體特徵或關係上類似的其它場景。這種特性的實現依賴於大腦中的圖像空間的豐富表徵,包括場景結構、語義以及使用觀察場景的表徵來喚醒海量存儲記憶中相似場景的機制。雖然尚未被完全理解,但人類的大腦的記憶容量是相當驚人的 [1,2]。對於近期深度學習在計算機視覺所有領域(包括圖像檢索和對比 [6])的爆炸式發展 [3,4,5],人們可能會認爲計算機視覺的表徵能力已經接近甚至超越了人類。爲了探索這個問題,本文的研究測試了深度神經網絡在一個新數據集(Totally-Looks-Like,TTL)的圖像對上的相似性判斷行爲。如圖 1 所示。

圖 1:Totally-Looks-Like 數據集例圖:人類用戶選出的知覺上相似的圖像對。這些圖像對隱含了人類在相似性判斷時使用的豐富特徵集,包括而不限於:物體和動物的面部特徵屬性(a,b)、整體形狀相似性(c,d)、近似重複(d)、相似面部(e)、紋理相似性(f)、顏色相似性(g)等。


該數據集基於一個娛樂性的網站,用戶可以發佈一對認爲很相似的圖片,並讓網友發表看法。這些圖片通常在低層特徵上的相似性是很低的。這些圖像對的類型包括(但不限於)多種畫風的物體、場景、模式、動物和人臉,有素描、卡通以及自然圖像。網站上還有用戶評級功能(「贊」或「踩」),展示了網友對此圖像對的相似性同意度。雖然該數據集規模不是很大,但其中圖像的多樣性和複雜度隱含地捕捉到了人類對圖像相似性感知的很多層面。
網站鏈接:http://memebase.cheezburger.com/totallylookslike
作者以圖像檢索任務的形式,評估了多個當前最佳模型在該數據集上的表現,並將結果與人類的相似性判斷行爲進行了對比。該研究不僅構成了特徵評估的一類新基準,並且揭示了當前深度學習表徵方法的具體弱點,爲未來研究指出了新的方向。作者還實施了人類評估實驗來驗證收集數據的一致性。雖然在一些實驗中爲深度學習模型設置了很好的條件,它們仍然無法正確地重構出人類選擇的匹配圖像。
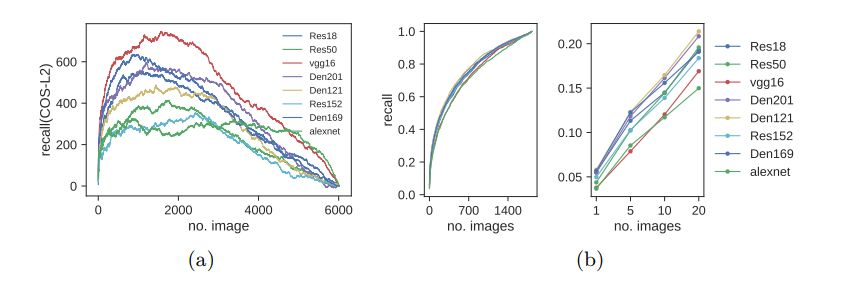
圖 3:(a)各種當前最佳模型的基於餘弦和 L2 距離的圖像檢索的每張圖像召回率的對比。使用餘弦距離得到的召回率總是比使用 L2 距離得到的召回率更高。(b)在 TTL 數據集中學習特徵後得到的檢索性能。左:使用所有圖像進行檢索的召回率;右:僅使用 top-1、5、10、20 圖像進行檢索的召回率。

圖 4:自動檢索誤差:每一行的左邊展示了一張參考圖像,右邊展示了一張正確的匹配圖像。知覺相似性適用於卡通面部和真實面部的相似性判斷(前 3 行),還有面部表情的靈活遷移(第 4 行)、局部區域的視覺相似性(最後兩行,第 5 行的人的頭髮和蜘蛛腿相似,第 6 行的人的頭髮和海浪相似)。雖然這些檢索得到的圖像和參考圖像在嚴格意義上有更高的相似性,人類還是一致認爲最後一行的圖像更加匹配。

圖 5:每一行展示了左邊的一張參考圖像和其它 5 張匹配圖像。某些匹配結果是高度集中於某張圖像的,而某些匹配結果是均勻分佈的。讀者可以猜猜看,哪一行是第一種情況,哪一行是第二種情況(各有兩行)。
論文:Totally Looks Like - How Humans Compare, Compared to Machines

論文地址:https://arxiv.org/abs/1803.01485
摘要:人類對圖像相似性的知覺判斷依賴於豐富的內部表徵,包括低級特徵、高級特徵、場景特性,甚至文化聯想等。試圖解釋知覺相似性的已有方法和數據集使用的刺激信號並沒有覆蓋影響人類判斷的所有因素。我們在這裏介紹基於一個娛樂性網站構建的新數據集 Totally-Looks-Like(TTL),該數據集收集了很多人類在視覺上認爲很相似的圖像,其中包含了網站上採集的 6016 個圖像對,擁有對人類而言足夠的多樣性和複雜度。我們做了實驗試圖從當前最佳的深度卷積神經網絡提取的特徵重構圖像對,還做了人類判斷實驗以驗證收集數據的一致性。雖然在一些實驗中人工地爲深度學習模型設置了很好的條件,但結果表明它們仍然無法通過提取的特徵正確地重構和人類選擇的匹配圖像。我們討論和分析了這些結果,爲未來的圖像表徵研究指出了新的方向。