按:視覺與語言的結合,相較於分割、檢測來講是比較新的研究領域,但或許正是因爲如此,在這個領域還有很多有待探索的地方。本文爲 2018 年 5 月 11 日在微軟亞洲研究院進行的 CVPR 2018 中國論文宣講研討會中第四個 Session——「Vision and Language」環節的四場論文報告。
在第一個報告中,微軟亞洲研究院的段楠博士介紹了他們將 VQA(視覺問答)和 VQG(視覺問題生成)兩項任務結合成一個統一模型 iQAN 的工作。由於 VAQ 與 VQG 在某種程度上具有同構的結構和相反的輸入輸出,因此兩者可以相互監督,以進一步同時提升兩個任務的表現。
第二個報告由來自中科院自動化所黃岩介紹他們在圖文匹配方面的工作。不同與其他方法直接提取圖像和句子的特徵然後進行相似性比較,他們認爲(1)圖片比語句包含更多信息;(2)全局圖像特徵並不一定好,於是他們提出了先對圖片進行語義概念提取,再將這些語義概念進行排序,之後再進行圖文匹配的比較。
來自西北工業大學的王鵬教授在第三個報告中介紹了他們在 Visual Dialog 生成方面的工作,他們提出了一種基於對抗學習的看圖生成對話的方法,這種方法可以在保證問答信息的真實性的情況下,維持對話的連續性。
在第四個報告中,來自華南理工大學的譚明奎教授介紹了他們在 Visual Grounding 任務中的工作,也即給定圖片和描述性語句,從圖中找出最相關的物體或區域。他們將這個問題分解爲三個子 attetion 問題,並在提取其中一中數據的特徵時,其他兩個作爲輔助信息來提升其提取質量。
注:
[1] CVPR 2018 中國論文宣講研討會由微軟亞洲研究院、清華大學媒體與網絡技術教育部-微軟重點實驗室、商湯科技、中國計算機學會計算機視覺專委會、中國圖象圖形學會視覺大數據專委會合作舉辦,數十位 CVPR 2018 收錄論文的作者在此論壇中分享其最新研究和技術觀點。研討會共包含了 6 個 session(共 22 個報告),1 個論壇,以及 20 多個 posters,AI 科技評論將爲您詳細報道。
[2] CVPR 2018 將於 6 月 18 - 22 日在美國鹽湖城召開。據 CVPR 官網顯示,今年大會有超過 3300 篇論文投稿,其中錄取 979 篇;相比去年 783 篇論文,今年增長了近 25%。
更多報道請參看:
Session 3: Person Re-Identification and Tracking
Session 4: Vision and Language
Session 5: Segmentation, Detection
Session 6: Human, Face and 3D Shape
一、融合VQA和VQG
論文:Visual Question Generation as Dual Task of Visual Question Answering
報告人:段楠 - 微軟亞洲研究院
論文下載地址:https://arxiv.org/abs/1709.07192
所謂 visual question answering (VQA),即輸入 images 和 open-ended questions,生成相關的 answer;而所謂 visual question generation (VQG),即輸入 images 和 answers,能夠生成相關的 questions。
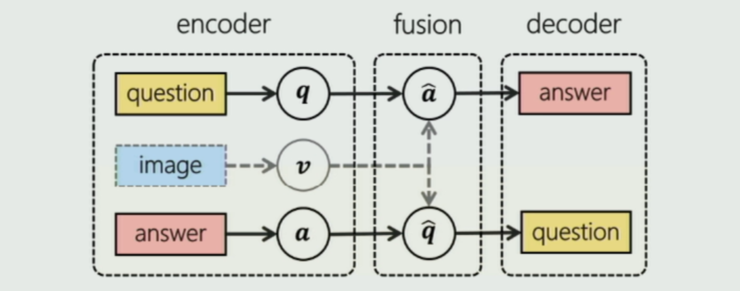
近來的 VQA 和 VQG 都是兩個比較熱門的研究課題,但是基本上都是獨立的研究。段楠認爲這兩項研究本質上具有同構的結構,即編碼-融合-解碼通道,不同之處只是 Q 和 A 的位置。因此他們提出將這兩個任務融合進同一個端到端的框架 Invertible Question Answering Network (iQAN) 中,利用它們之間的相互關係來共同促進兩者的表現。
針對 VQA 部分,他們選用了目前常用的模型 MUTAN VQA,如下圖所示:
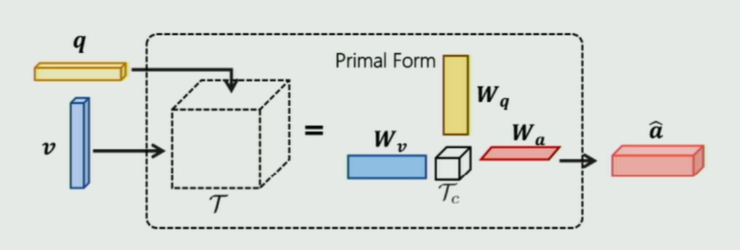
MUTAN VQA 本質上是一個雙線性融合模型。考慮到 VQG 與 VQA 同構,因此他們對 MUTAN 稍加改造(如下圖將 Q、A 位置互換)得到對偶的 MUTAN 形式:
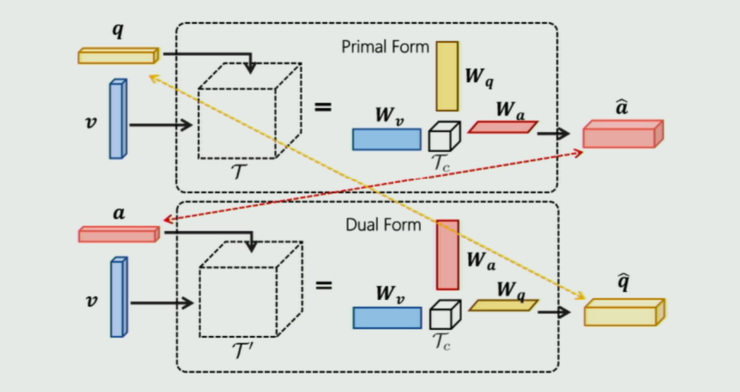
通過兩個模塊中 q 與 Q,a 與 A 的相互監督來提升 VQA 和 VQG 的表現。基於這樣的思考,他們構建了端到端的 iQAN 框架如下:
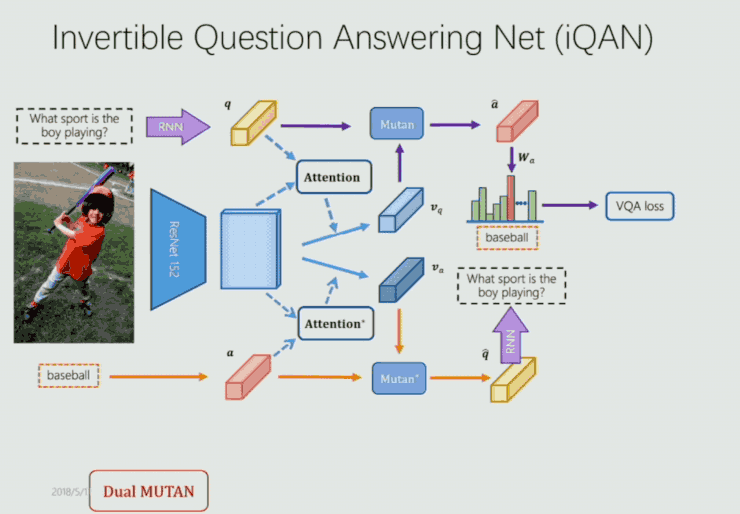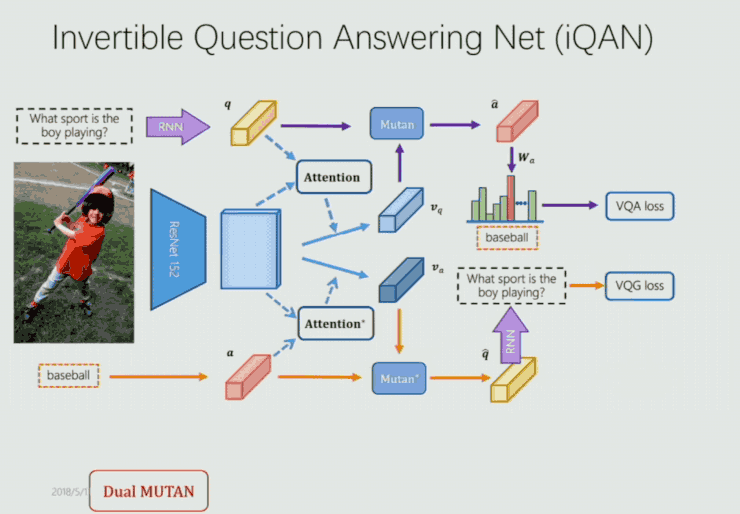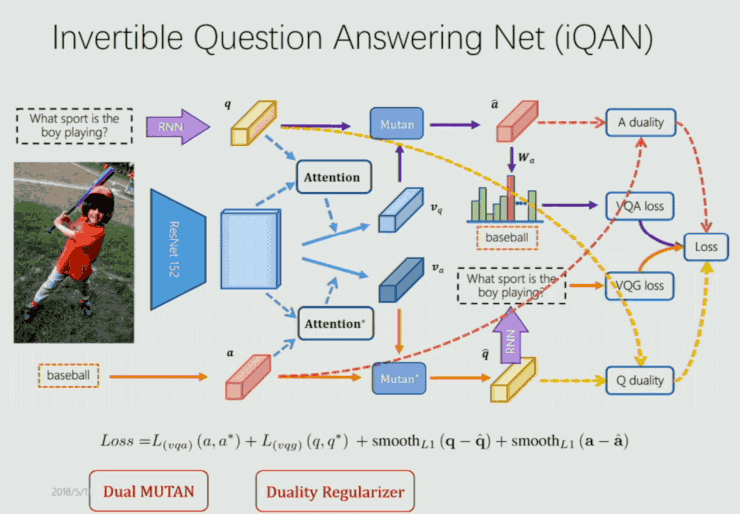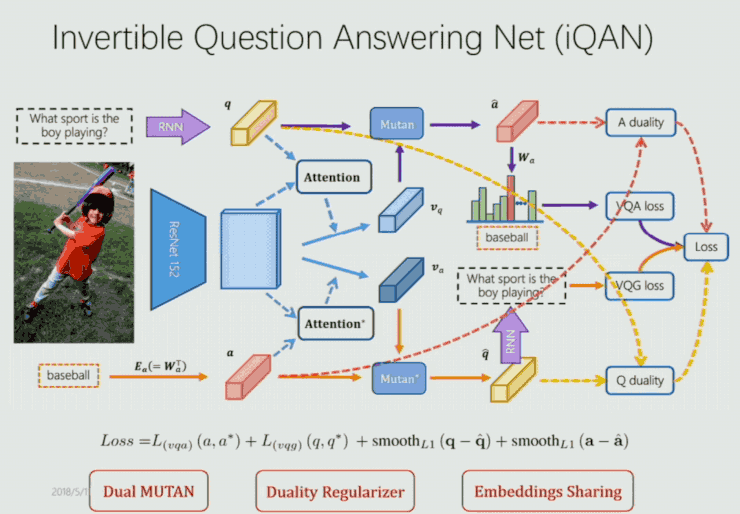
這裏首先是使用 MUTAN 和 Dual MUTAN 的框架生成相應的 VQA loss 和 VQG loss。其次如剛纔提到,由 q 與 Q,a 與 A 的相互監督得到 dual regularizer 的 loss。另外,image 即作爲 VQA 的輸入,也作爲 VQG 的輸入,因此它們在參數上是共享的,因此他們又做了一個 embedding sharing 的部分。
部分實驗結果如下:
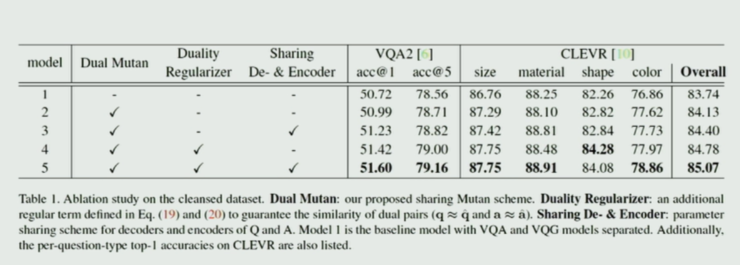
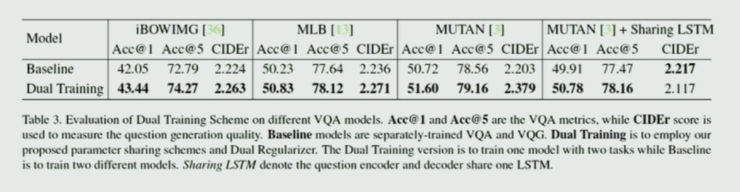
段楠提到,在這篇文章中他們使用的主要是 MUTAN 的框架,而事實上可以很容易替換成別的框架,對比實驗如下,分別使用了 iBWIMG、MLB、MUTAN 和 MUTAN+sharing LSTM:
這裏是一個注意力熱圖結果:

二、圖文匹配
論文:Learning Semantic Concepts and Order for Image and Sentence Matching
報告人:黃岩 - 中科院自動化所
論文下載地址:https://arxiv.org/abs/1712.02036
一張圖片包含信息豐富多彩,而如果單單用一個句子來描述就會漏掉許多信息。這或許也是當前圖像與文本匹配任務當中的一個問題。黃岩等人針對此問題,提出了學習圖像語義概念和順序,然後再進行圖像/文本匹配的思路。
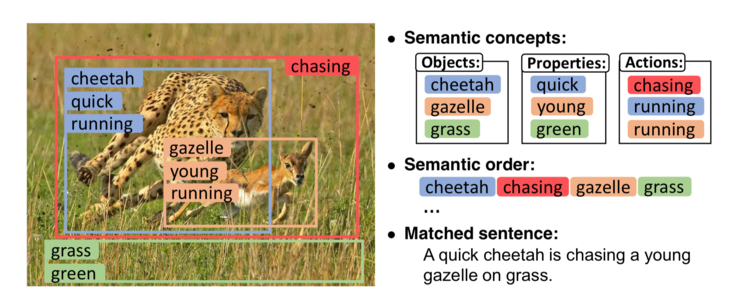
如上圖所示,他們希望能先提取出圖像中所包含的基本概念,例如 cheetah、gazelle、grass、green、chasing 等,包括各種事物、屬性、關係等;然後學習出這些語義概念的順序,如 cheetah chasing gazelle grass,顯然這裏不同的語義順序也將導致不同的語義意義。基於這些語義概念和順序在進行圖片與文本的匹配。
整體來說,即用多區域、多標籤的 CNN 來進行概念預測,用全局上下文模塊以及語句生成來進行順序學習。模型框架如下圖所示:
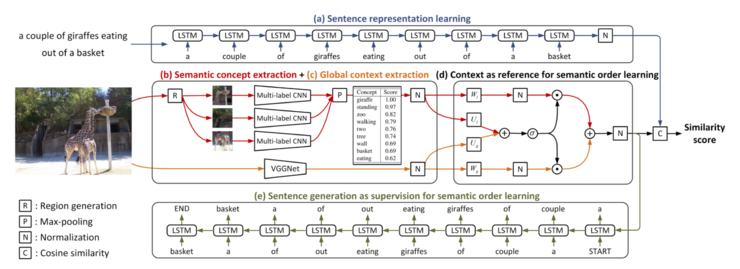
(a)針對句子用 LSTM 學習其特性;(b)使用多區域、多標籤的 CNN 從圖中進行語義概念提取;(c)使用 VGGNet 提取上下文信息;(d)利用提取出的語義概念和上下文的信息,例如空間位置等,通過 gated fusion unit 對語義進行排序;(e)此外,他們還發現事實上語句本身也包含着「順序」的信息,因此他們利用生成的語句作爲監督來學習語義順序,進一步提高語義順序的準確性。最後通過學習出的語義概念和順序進行相似性打分,判斷圖像與句子是否匹配。
其實驗結果與當前的一些 state-of-art 方法對比如下:
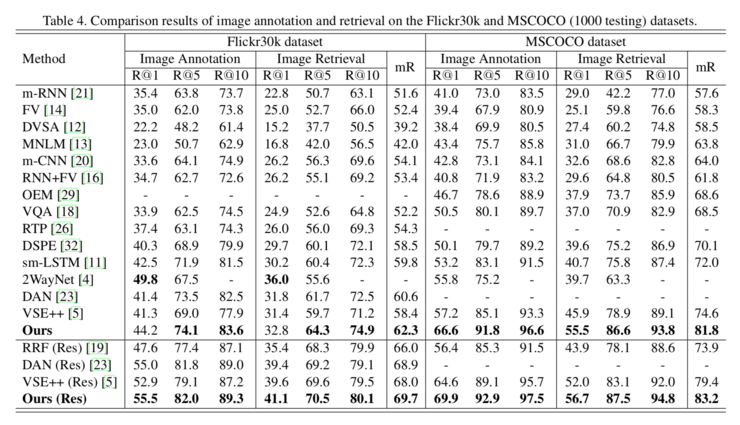
可以看出,在兩個數據集中該方法的表現相比其他方法都有顯著的提升。下面是一個實例:
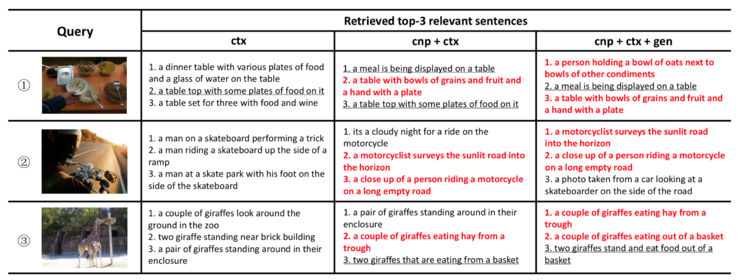
ctx = context,cnp = concept,gen = generation。其中 groundtruth 匹配語句用紅色標註;與 groundtruth 有相同意思的句子以下劃線標註。
三、看圖寫對話
論文:Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
報告人:王鵬 - 西北工業大學
論文下載地址:https://arxiv.org/abs/1711.07613
所謂 Visual Dialog Generation,簡單來講,即以一張圖片和對話歷史爲條件來回答相關問題。相比於 NLP 領域的對話,其不同之處在於輸入中除了 dialog history 和 question 外,還有一個圖片信息;而相比於 Visual Answer 則多了 dialog history。如下圖所示:
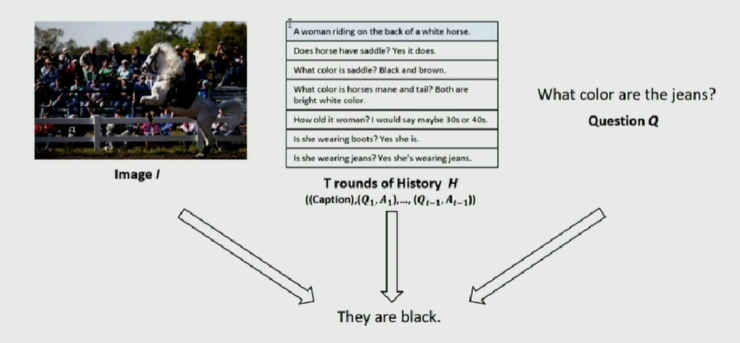
一個很自然的想法就是仍然使用 Visual Answer 中的方案,將 dialog history 中的每一對對話視作圖片中的一個 fact 去提取和生成。這種方法有一個缺點,及 Visual Answer 任務的重點是針對問題給出一個儘可能對的答案。但是對於 dialog 任務來講,除了回答正確外,還需要維持對話的有序進行。在對話中一個好的回答是,除了回答問題外,還要提供更多的信息,以便提問者能夠根據這信息繼續問下去。
基於這樣的想法,王鵬等人提出了基於對抗學習的方式來生成 Visual Dialog。具體來講,他們使用了較爲傳統的 dialog generator,即針對 image、question 和 dialog history 分別使用 CNN 和 LSTM 對其進行編碼,隨後經過 co-attention 模型對每個 local representation 給出一個權重,然後將 local feature 做一個帶權求和從而得到 attented feature,將該 feature 經過 LSTM 解碼即可得到一個相應的 Answer。
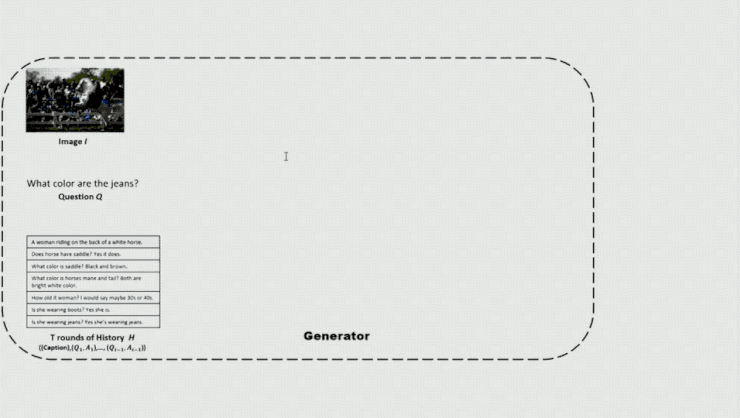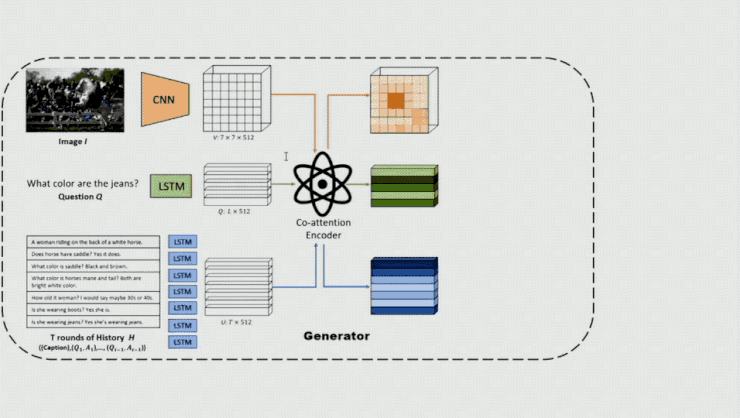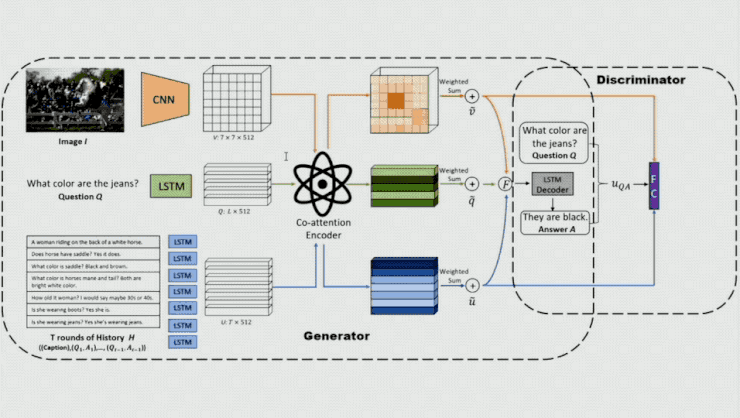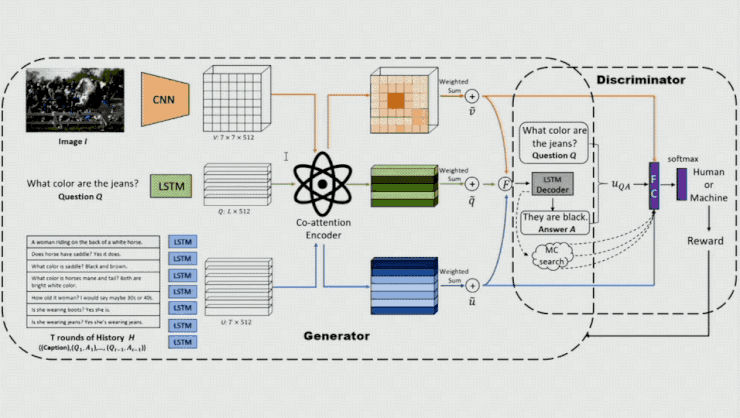
在這個模型中關鍵的一點是他們在模型的後面加入一個鑑別器,通過它來區分輸入的答案是人產生的還是機器產生的。這裏輸入的不僅有相應的 question 和 Answer,還有 attention 的 output,以便讓鑑別器在一定的環境下分析 Q、A 是否合理。鑑別器產生的概率將作爲生成器的 reward,以對生成器的參數進行更新。
這裏需要重點提一下生成器中的 Co-attention 模型,這是一個序列 Co-attention 模型,他們也曾將這個模型用在 CVPR 2017 中的一篇文章中。如下圖所示:
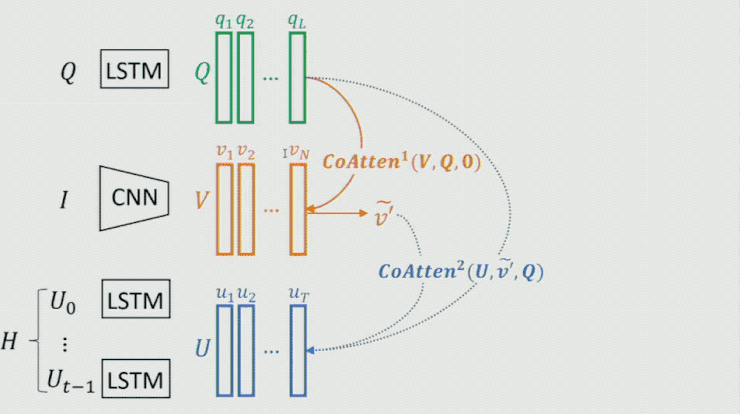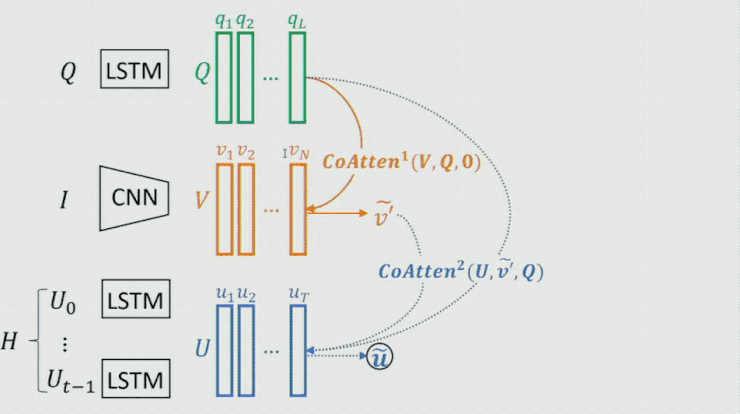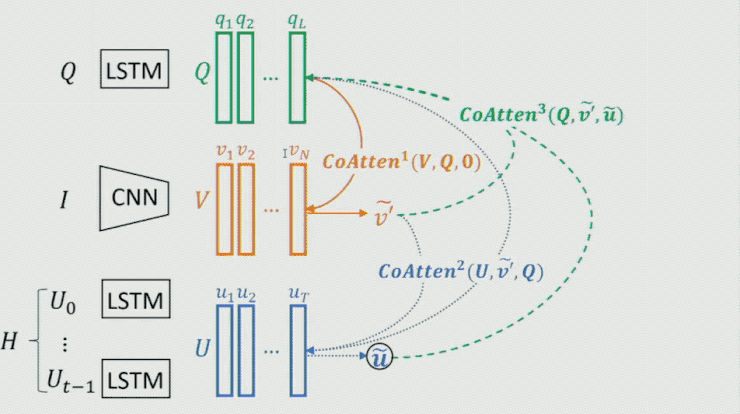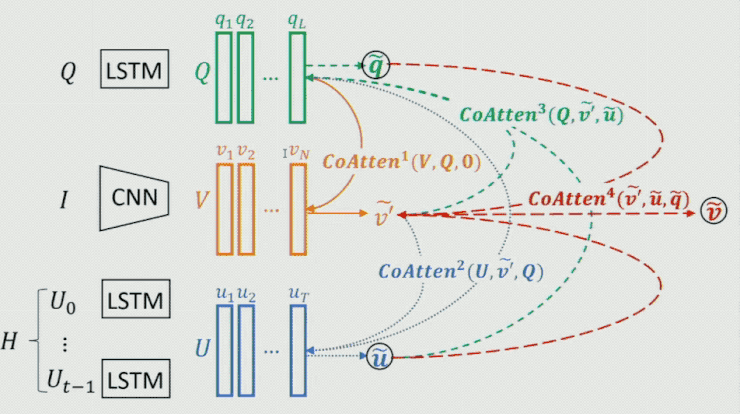
首先對 Question 做一個 attention,然後將結果作爲 guidance 在 Image 上做 attention,從而得到 image 的feature;時候再把這兩個的結果作爲 guidance 在 history dialog 上做 attention,得到 history dialog 的 feature;如此往復,不斷把結果提高。最終將輸出 feature 作爲整個模型的表示。
其算法如下所示:

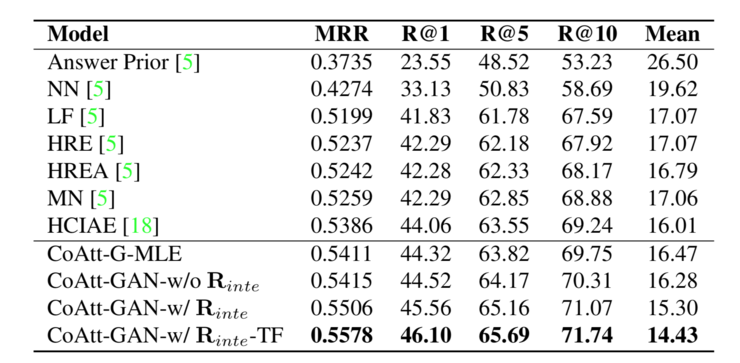
其實驗結果顯示比其他方法有很大提升:
一個實例如下:
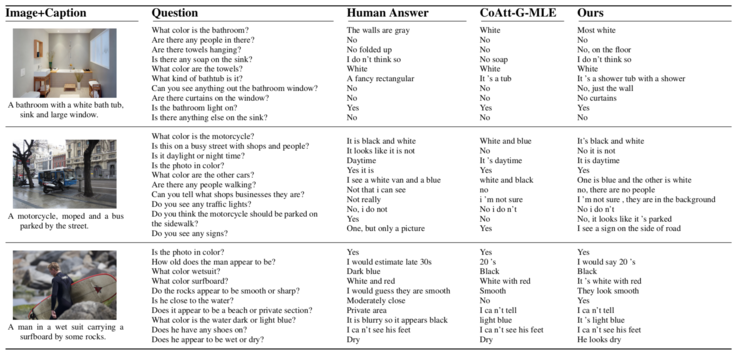
可以看出其生成對話的長度,相比其他方法要更長(這某種程度上也意味着包含更多的信息)。
四、如何找到竹筐裏的熊貓?
論文:Visual grounding via accumulated attention
報告人:譚明奎 - 華南理工大學
論文下載地址:暫無
Visual Grounding 任務是指:當給定一張圖片以及一句描述性句子,從圖片中找出最相關的對象或區域。形象來說,如下圖:
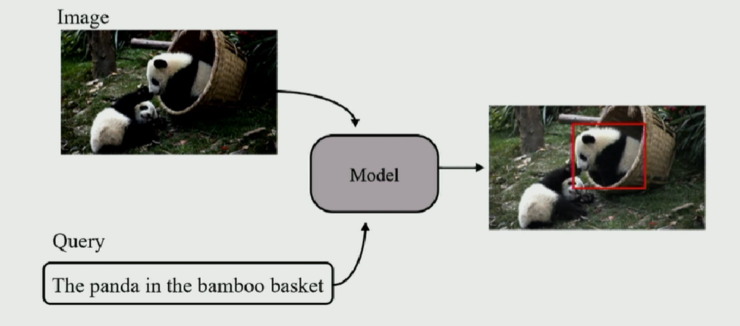
Visual Grounding 任務即從圖中找出「在竹筐中的熊貓」(注意:而不是在地上的熊貓)。
據譚明奎教授介紹這篇文章的工作是由華南理工大學的一名本科生完成。在文章中,作者針對此任務,提出了 Accumulate Attention 方法,將 Visual Grounding 轉化爲三個子問題,即 1)定位查詢文本中的關鍵單詞;2)定位圖片中的相關區域;3)尋找目標物體。
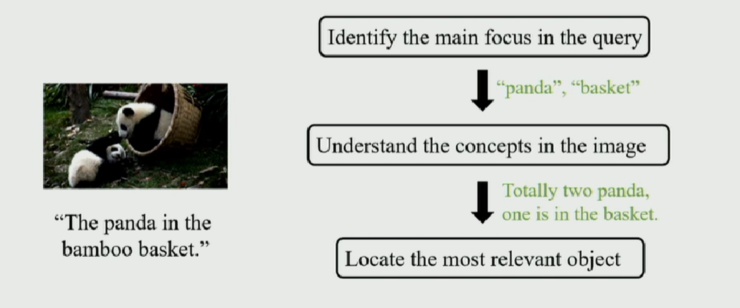
作者針對這三個子問題分別設計了三種 Attention 模塊,分別從文本、圖像以及候選物體三種數據中提取特徵。
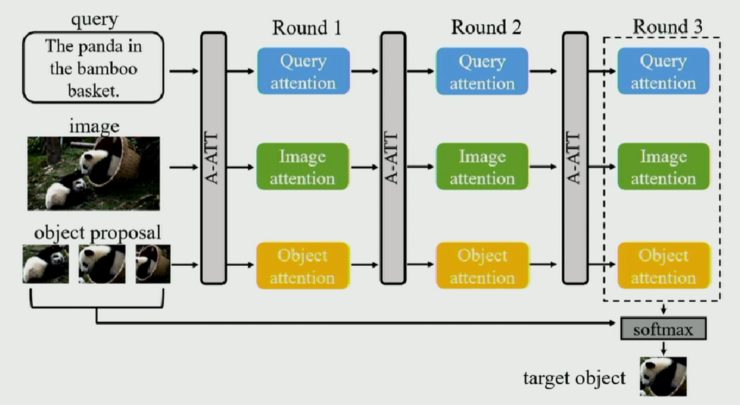
首先針對文本、圖像以及物體,他們分別使用 Hierarchical LSTM、VGG-16 以及 Faster-RCNN 來提取特徵,然後使用 attention 機制計算出每個三種數據特徵向量每個元素的權重。
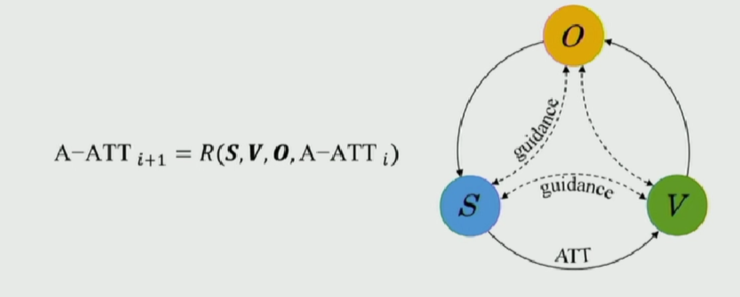
作者在提取一種特徵的過程中,將另外兩種數據的特徵作爲輔助信息來提高特徵提取的質量。Accumulate Attention 方法按照循環的方式不斷對這三種數據進行特徵提取,使得特徵的質量不斷提高,分配在目標相關的數據上的 attention 權重不斷加大,而分配在無關的噪聲數據上的 attention 權重則不斷減小。
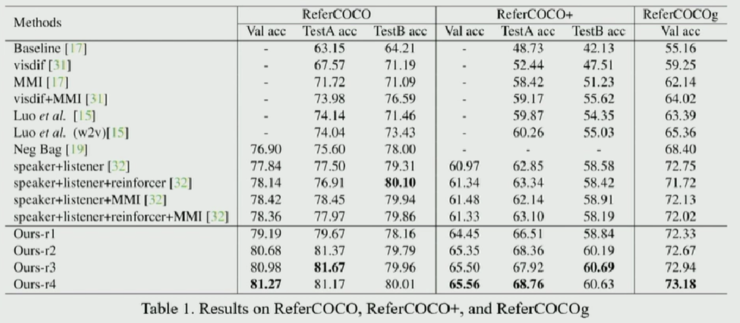
其實驗表明 Accumulate Attention 方法在 ReferCOCO、ReferCOCO+、ReferCOCOg 等數據集上均取得較好的效果。(其中的 r1、r2、r3、r4 分別代表循環輪數。)
相關文章:
CVPR 2018 中國論文分享會 之「人類、人臉及3D形狀」
CVPR 2018 | 斯坦福大學提出自監督人臉模型:250Hz 單眼可重建
CVPR 2018 | 英特爾實驗室讓 AI 在夜間也能拍出精彩照片