Petuum 專欄
作者:Baoyu Jing、Pengtao Xie、Eric Xing
在過去一年中,我們看到了很多某種人工智能算法在某個醫療檢測任務中 「超越」人類醫生的研究和報道,例如皮膚癌、肺炎診斷等。如何解讀這些結果?他們是否真正抓住醫療實踐中的痛點、解決醫生和病人的實際需要? 這些算法原型如何落地部署於數據高度複雜、碎片化、異質性嚴重且隱含錯誤的真實環境中?這些問題常常在很多「刷榜」工作中迴避了。事實上,從最近 IBM Watson 和美國頂級醫療中心 MD Anderson 合作失敗的例子可以看出,人工智能對醫療來說更應關注的任務應該是如何幫助醫生更好地工作(例如生成醫療圖像報告、推薦藥物等),而非理想化地着眼於取代醫生來做診斷,並且繞開這個終極目標(暫且不論這個目標本身是否可行或被接受)之前各種必須的鋪墊和基礎工作。因此與人類醫生做各種形式對比的出發點本身有悖嚴肅的科學和工程評測原則。這些不從實際應用場景出發的研究,甚至無限放大人機PK,對人工智能研究者、 醫療從業者和公衆都是誤導。
知名人工智能創業公司 Petuum 近期發表了幾篇論文,本着尊重醫療行業狀況和需求的研究思路, 體現出了一種務實風格,並直接應用於他們的產品。爲更好地傳播人工智能與醫療結合的研究成果,同時爲人工智能研究者和醫療從業者帶來更加實用的參考,我們和 Petuum 將帶來系列論文介紹。本文是該系列第一篇,介紹瞭如何使用機器學習自動生產醫療圖像報告,從而更好地輔助醫生做治療與診斷。
如今,放射學圖像和病理學圖像這樣的醫療圖像在醫院與診所已有普遍的應用,特別是在許多疾病的診斷與治療上,例如肺炎、氣胸、間質性肺病、心理衰竭等等。而這些疾病醫療圖像的閱讀與理解通常是由專業的醫療從業者完成。
但對缺乏經驗的放射科醫師或病理學家來說,特別是在鄉村地區工作的醫師,編寫醫療圖像報告更爲艱難。對經驗豐富的醫師而言,編寫醫療圖像報告又過於乏味、耗時。總之,對二者而言編寫醫療圖像報告是件痛苦的事。
如此看來,能否使用機器學習自動生成醫療報告呢?爲了做到這一點,我們需要解決多個挑戰。首先,一份完整的診斷報告包含多種不同的信息形式。如下圖 1 所示,胸腔 X 光照圖像報告包含 Impression 描述,通常是一句話;Findings 是一段描述;Tags 是一列關鍵詞。用一個統一的框架生成這樣的不同信息,技術上非常有挑戰。在這篇論文中,研究人員解決該問題的方法是建立一個多任務框架,把對標籤的預測當作多標籤分類任務,把長描述(例如生成 Impression 和 Findings)的生成當作文本生成任務。在此框架中,兩種任務共用同樣的 CNN,來學習視覺特徵並聯合完成任務。
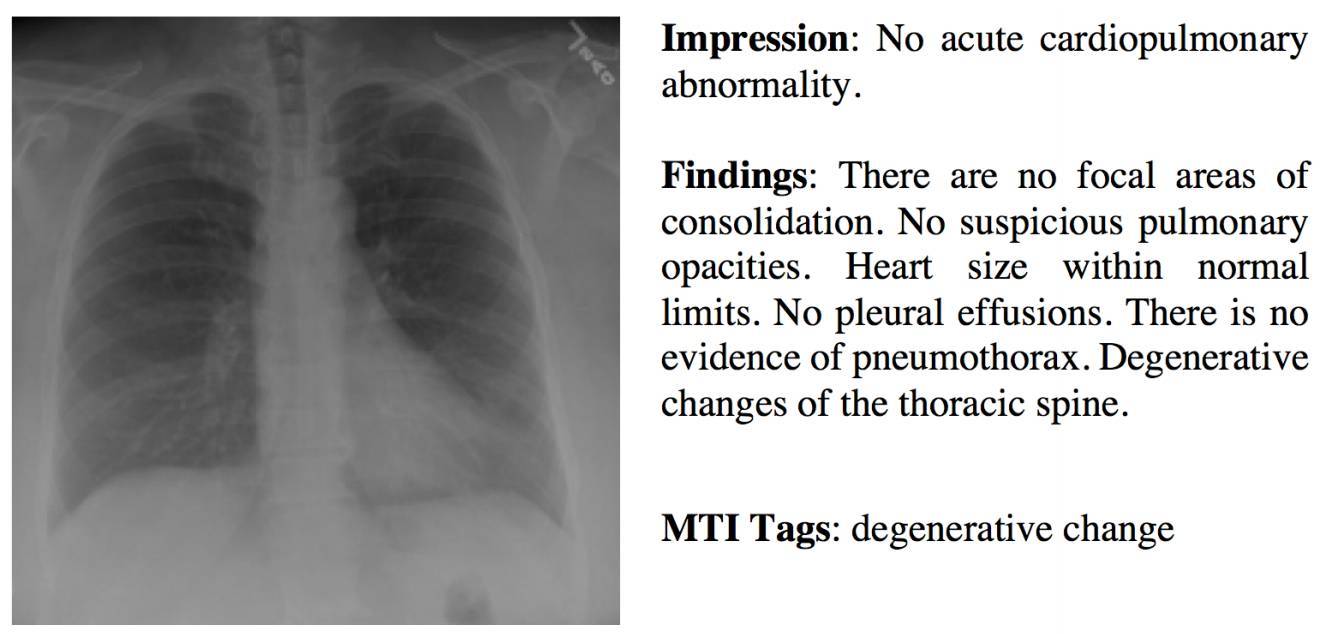
圖 1. 一個包含三部分信息的胸部 X 光報告示例。在 impression 部分,放射專家結合 Findings、病人臨牀歷史及影像學研究的指導做出診斷。Findings 部分列出了影像學檢查中所檢測的身體各部分放射學觀察結果。Tags 部分給出了表示 Findings 核心信息的關鍵詞。這些關鍵詞使用醫學文本索引器(MTI)進行標識。
第二,醫療圖像報告通常更注重敘述異常發現,因爲這樣能直接指出疾病、引導治療。但如何定位圖片中的病變區域並附上正確的描述非常困難。作者們解決該問題的方法是引入一種協同注意力機制(co-attention mechanism),它能同步關注圖像和預測到的標籤,並探索視覺與語義信息帶來的協同效應。
第三,通常醫療圖像的描述非常長,包含多個語句或段落。生成這樣的長文本非常重要。相比於直接採用單層 LSTM(難以建模長語句),作者們利用報告的合成特性採用了一種層級 LSTM 來生成長文本。結合協同注意力機制,層級 LSTM 首先生成高級主題,然後根據主題生成細緻的描述。
總而言之,該論文的主要貢獻包括:
提出一種多任務學習框架,能同步預測標籤並生成文本描述;
介紹了一種協同注意力機制來定位異常區域,並生成相應的描述;
建立了一種層級 LSTM 來生成長語句、段落;
通過大量定量與定性的實驗展示該方法的有效性。
論文:On the Automatic Generation of Medical Imaging Reports

論文地址:https://arxiv.org/abs/1711.08195
摘要:醫學影像廣泛用於診斷和治療等醫療實踐中。通常專業醫師需要查看醫學影像,並寫文本報告來記錄發現。缺乏經驗的醫生寫報告容易出錯,且在醫患比例過低的國家,編寫報告會耗費大量時間。爲了解決該問題,我們研究了醫學影像報告的自動生成系統,以幫助人類醫生更準確高效地寫報告。但目前該任務面臨多個挑戰。首先,完整的報告包含多種異質形式的信息,如用段落表示的發現和關鍵詞列表表示的標籤。第二,機器很難識別醫學影像中的異常區域,在此基礎上生成文本描述則更加困難。第三,報告通常比較長,包括多個段落。爲了解決這些挑戰,我們(1)構建一個多任務學習框架,能夠同時執行標籤預測和段落生成;(2)提出一種協同注意力(co-attention)機制來定位異常區域,並生成描述;(3)開發一種分層 LSTM 模型用於生成長段落。最後我們展示了該方法在胸部 x 光和病理數據集上的有效性。
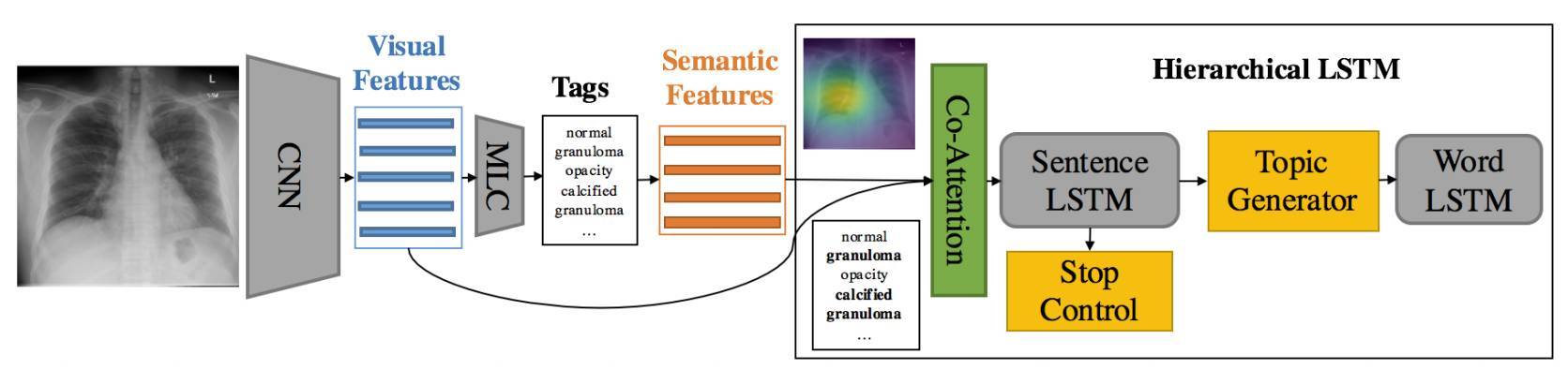
圖 2. 整個模型的結構與過程。其中 MLC 代表多標籤分類網絡,語義特徵是預測標籤的詞向量。粗體標記的「calcified granuloma」和「granuloma」是協同注意力網絡關注的標籤。
3. 方法
在本章節中,我們將介紹具體使用的方法。以下簡要地介紹了整個方法的過程,各部分詳細的過程或理論請查看原論文。
一份完整的醫學影像報告通常包括非結構化的描述(以語句和段落的形式展示)和半結構化標籤(以關鍵字列表的形式展示),如上圖 1 所示。我們提出了一種多任務層級模型,該模型帶有協同注意力機制(co-attention)且能自動預測關鍵字並生成長段落。給定一張經過分割的圖像,我們使用一個 CNN 來學習這些圖像塊的視覺特徵。然後再饋送這些視覺特徵到多標籤分類網絡(MLC)以預測相關的標籤。
在標籤詞彙表中,每一個標籤由一個詞向量表徵。若給定特定圖像一些預測的標籤,模型會檢索它們的詞嵌入向量以作爲該圖像的語義特徵。模型隨後將視覺特徵和語義特徵饋送到協同注意力(co-attention)模型以生成能同時捕獲視覺和語義信息的上下文向量。至此,編碼的過程就完成了,下面模型將從背景向量(context vector)開始解碼生成文本描述。
醫學影像的描述通常包含多條語句,並且每條語句都集中在一個特定的主題上。我們的模型利用這種組合結構以層級的方式生成報告:它首先生成一系列代表語句的高級主題向量,然後在根據這些主題向量生成一系列的語句(由單詞組成的序列)。具體來說,先將背景向量輸入到一個只有少量時間步的 Sentence LSTM 中,然後每一個背景向量就能生成一個主題向量。其中每個主題向量都表示一條語句的語義。隨後給定一個主題向量,Word LSTM 將以它爲輸入生成一個單詞序列或語句。主題生成的終止條件由 Sentence LSTM 控制。
4. 實驗
我們使用以下文本生成評估手段(BLEU [13]、METEOR [4]、ROUGE [12] 和 CIDER [17])度量段落生成(表 1 上半部分)和單語句生成(表 1 下半部分)的結果。
如表 1 上半部分所示,對於段落生成來講,使用單個 LSTM 解碼器的模型的表現明顯要差於使用層級 LSTM 解碼器的模型。
對於單語句生成(見表 1 下半部分)的結果來說,我們模型的控制變量版(Ours-Semantic-Only 和 Ours-Visual-Only)相較於當前最優的模型取得了有競爭力的分值。
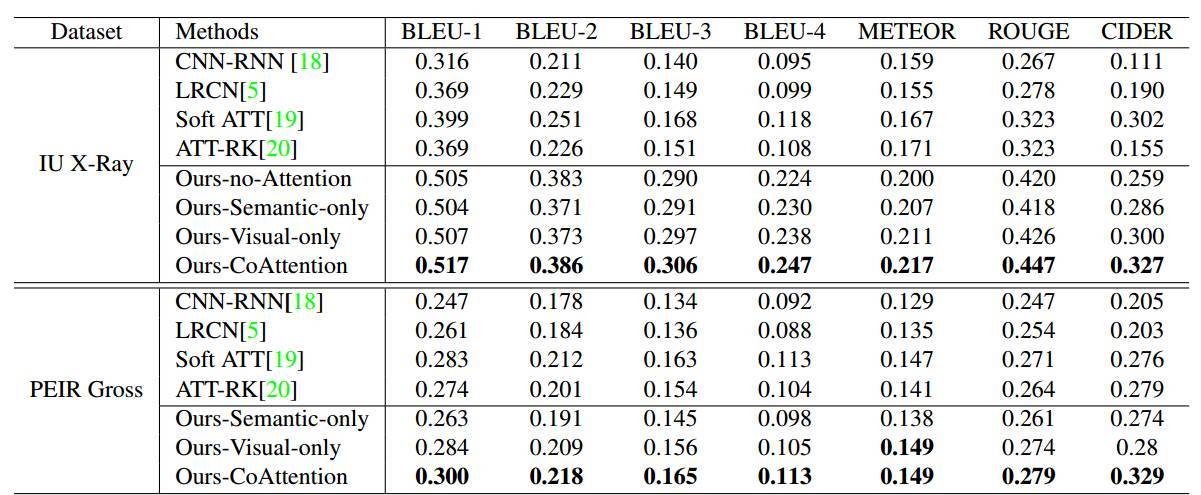
表 1. 模型在 IU X-Ray 數據集(上半 部分)上生成段落的主要結果,以及在 PEIR Gross 數據集(下半部分)上生成單語句的結果。BLUE-n 表示最多使用 n-grams 的 BLUE 分值。
爲了更好地理解模型檢測真實或潛在異常情況的能力,我們在表 2 中展示了描述正常情況與異常情況的語句,及它們所佔的比率。
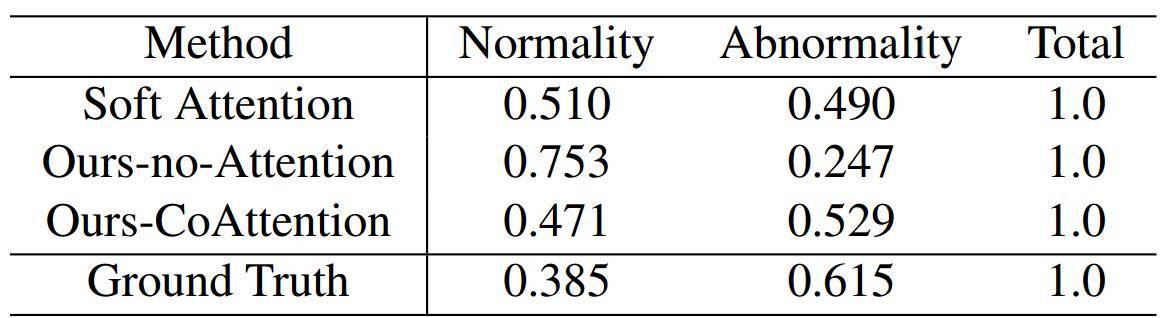
表 2. 描述圖像中正常情況和異常情況語句所佔的比率。

圖 3. 協同注意力 、無注意力、軟注意力模型生成的段落圖示。劃線句子是檢測到異常情況的描述。第二個圖是胸部側面 x 光圖像。前兩個例子的結果是與真實報告相一致的,第三個出現了部分失敗,最底下的圖像完全失敗。這些圖像來自測試數據集
圖 4 展示了協同注意力的可視化。第一個特性是 Sentence LSTM 能夠關注圖像的不同區域和語句的不同標籤,並在不同的時間步上生成不同的主題。第二個特性是視覺注意力可以指引模型關注圖像的相關區域。
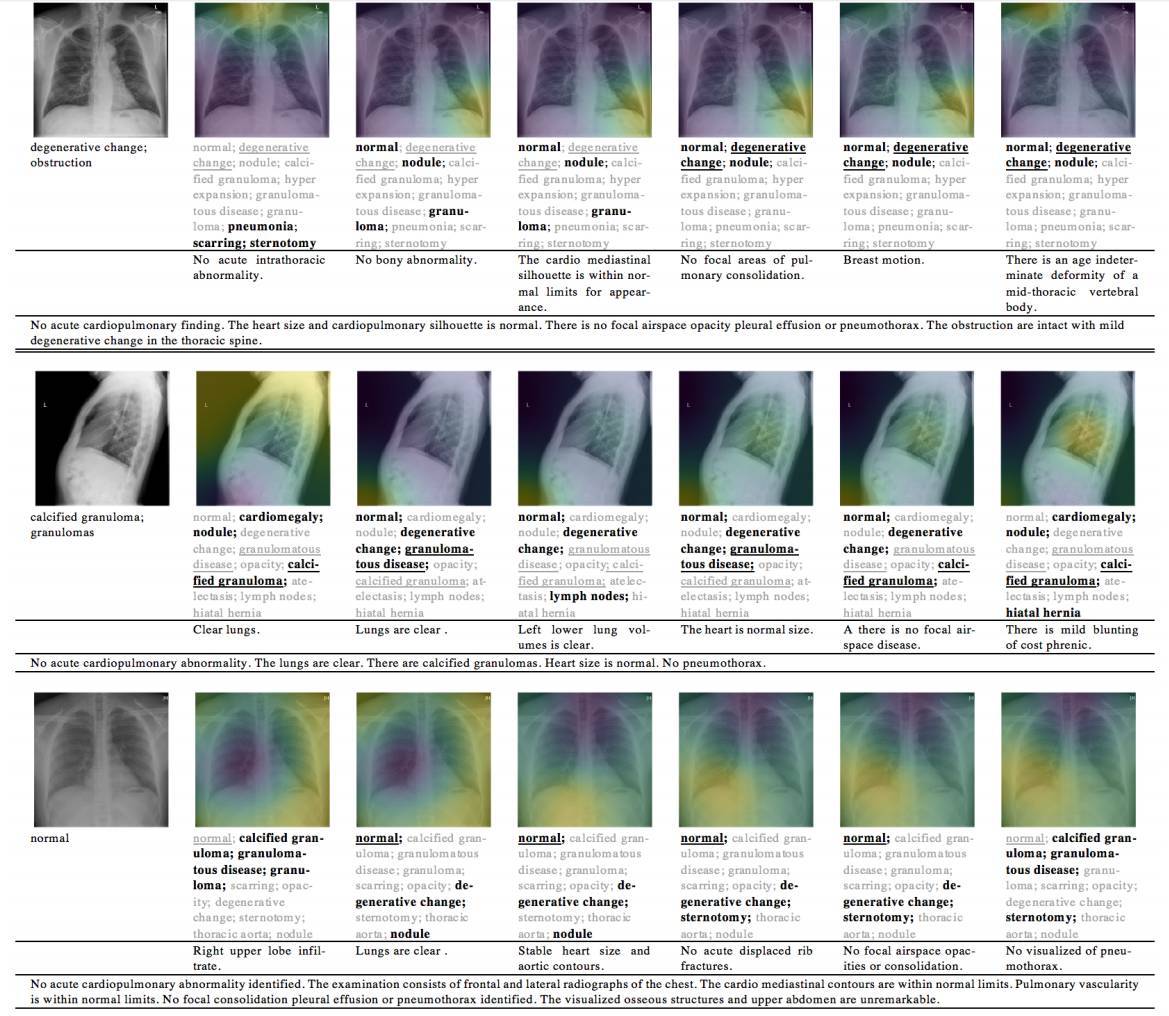
圖 4. 協同注意力在三個示例上的可視化。每個示例由四部分組成:(1)圖像和視覺注意力;(2)真實標籤,預測標籤以及預測標籤上的語義注意力;(3)生成的描述;(4)真實描述。對於語義注意力而言,注意力分數最高的三個標籤被突出顯示。加下劃線的標籤是在真實標籤中出現的標籤。