選自arXiv
作者:Lu Jiang、Zhengyuan Zhou、Thomas Leung、Li-Jia Li、Li Fei-Fei
有老師指導就能更好地學習嗎?對於深度神經網絡是否也是如此?近日,谷歌和斯坦福大學的研究者在其論文中提出了一種用 MentorNet 監督 StudentNet 進行訓練的新技術。這項研究的第一作者是谷歌雲機器學習的研究科學家蔣路(Lu Jiang),另外李佳和李飛飛也參與了該研究。
在目標識別 [19, 15, 39] 和檢測 [14] 等多種視覺任務上,深度神經網絡已經取得了很大的成功。當前最佳的深度網絡有數百層,而可訓練的模型參數的數量更是遠遠超過了它們訓練所用的樣本的數量。最近一項研究發現即使是在有損的標籤上(其中部分或所有真實標籤被隨機標籤替換),深度網絡也能記憶整個數據 [45]。正則化(regularization)是一種用於克服過擬合的有效方法。張弛原等人 [45] 通過實驗表明:當在有損的標籤上訓練時,權重衰減、數據增強 [20] 和 dropout [36] 等常用於神經網絡的正則化算法(即模型正則化器(model regularizer))在提升深度卷積神經網絡(CNN)的生成表現上的效果不佳;我們的研究也證實了這個觀察結果。深度 CNN 通常是在大規模數據上訓練的,在這些數據上的標註通常有很多噪聲 [1,11]。過擬合訓練數據中的噪聲常常會讓模型的表現變得很差。
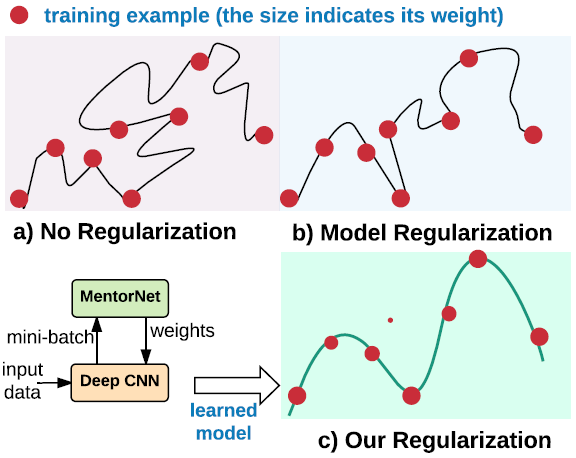
圖 1:已有的正則化方法和我們的正則化方法的圖示。每個點表示一個訓練樣本,點的大小表示樣本權重。曲線表示學習到的模型。權重衰減等已有的正則化方法對深度 CNN 而言效果不佳。數據正則化是通過學習爲樣本分配合適的權重來解決深度 CNN 的過擬合問題。
由於模型參數數量龐大,所以正則化非常深度的 CNN 頗具挑戰性。爲了解決這一難題,我們提出了一種在數據維(data dimension)中正則化深度 CNN 的全新技術,我們稱之爲數據正則化(data regularization)。我們的目標是通過正則化在有損標籤上訓練的 CNN 來提升其在清潔測試數據上的泛化表現。可以被看作是深度 CNN 的網絡有 Resnet [15] 和 Inception-resnet [39],它們有幾百層,而且參數的數量比訓練樣本的數量多幾個數量級。具體來說,我們提出爲用於訓練該分類網絡(即 StudentNet)的每個樣本學習隨時間變化的權重。我們引入了一種 MentorNet 來監督該 StudentNet 的訓練。如圖 1 所示,在訓練過程中,MentorNet 學習爲每個訓練樣本分配一個權重。通過學習不均衡的權重,MentorNet 鼓勵某些樣本學得更早,並且得到更多注意,由此對學習工作進行優先級排列。對於 MentorNet 訓練,我們首先預訓練一個 MentorNet 來近似得到有標籤數據中特定的一些預定義權重。然後我們在具有清潔標籤的第三個數據集上對它進行微調。在測試的時候,StudentNet 獨自進行預測,不會使用 MentorNet。
我們的方法受到了課程學習(curriculum learning)[4] 的啓發。MentorNet 學習給訓練樣本加權,從而得到一個課程(curriculum),該課程決定了學習每個樣本的時間和注意程度。課程學習已經在各種計算機視覺問題 [38, 26, 7, 16, 25, 44]、臉部檢測 [26]、目標檢測 [7]、視頻檢測 [16] 中被用來尋找更好的極小值了。我們的模型通過神經網絡從數據學習課程,從而推進了課程學習方法。我們提出的模型讓我們可以通過一個共同框架來理解和進一步分析已有的加權方案,比如自步式加權(self-paced weighting)[21]、hard negative mining [31] 和 focal loss [27],更重要的是讓我們可以通過神經網絡學習這些方案。此外,我們討論了一種使用深度 CNN 在大規模數據上用於優化 MentorNet 的算法。我們從理論上證明了它的收斂性並且通過實驗在大規模 ImageNet 數據上評估了該算法的表現。
我們在 CIFAR-10、CIFAR-100、ImageNet 和 YFCC100M 這四個基準上驗證了 MentorNet。全方位的實驗表明 MentorNet 可以提升在受控和真實有噪聲標籤上訓練的深度 CNN 的表現,並且表現也優於之前最佳的弱監督學習方法。總而言之,本論文有三大貢獻:
我們發現通過學習另一個網絡來加權訓練樣本,在有損標籤上訓練的深度 CNN 可以獲得提升。
我們提出了一種使用在大數據上的深度 CNN 來優化 MentorNet 的算法,並且在標準的輕微假設下證明了其收斂性。
我們在具有受控的和真實的有噪聲標籤的 4 個數據集上實證驗證了我們提出的模型。
算法
事實證明,相關研究中所使用的其它最小化方法難以應付大規模訓練,這主要是由於兩大重要原因。首先,在固定隱變量 v 時最小化網絡參數 w 的子程序中,隨機梯度下降通常需要很多步驟才能實現收斂。這意味着這一單個子步驟可能需要消耗很長的時間。但是,這樣的計算往往很浪費,尤其是在訓練的初始部分;因爲當 v 離最優點還很遠時,找到對應於這個 v 的準確的最優 w 並沒有多大用處。其次,更重要的是,固定 w 而最小化 v 的子程序往往不切實際,因爲固定的向量 v 甚至可能都無法放入內存。比如,在 5000 個類別上訓練 1000 萬個樣本,光是存儲其權重矩陣就需要消耗 2TB。在有大規模訓練數據時訓練數據正則化目標需要一些算法層面的思考。

算法 1
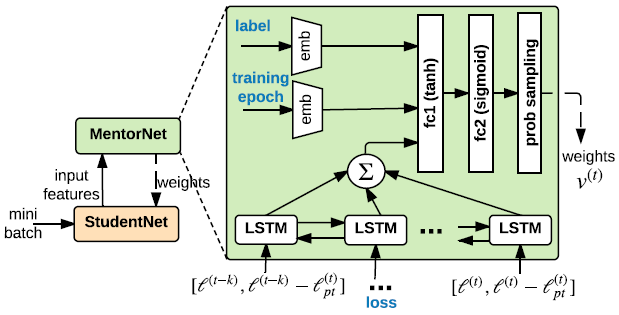
圖 2:我們提出的 MentorNet 架構。輸入特徵是樣本損失、標籤和訓練 epoch。輸出是 mini-batch 中每個樣本的權重。emb、fc 和 prob sampling 分別表示嵌入、全連接和概率採樣層。和分別表示在 epoch t 處的樣本損失和損失移動平均(loss moving average)。
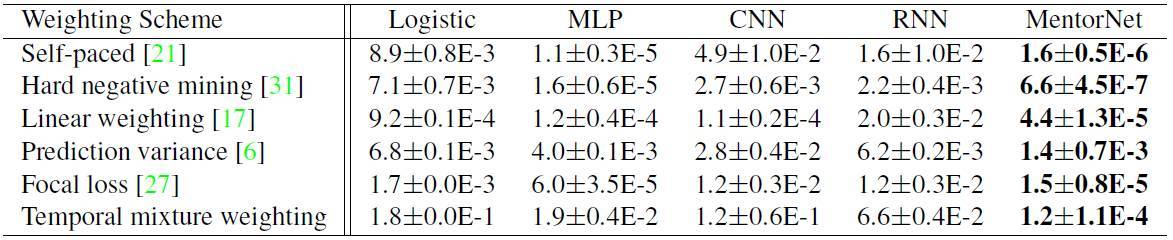
表 1:學習預定義的加權方案的 MSE 比較。
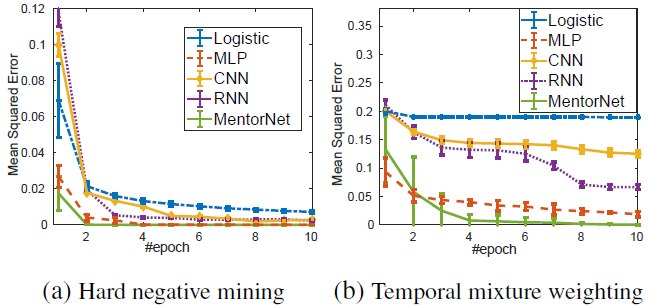
圖 3:MentorNet 架構的收斂比較。
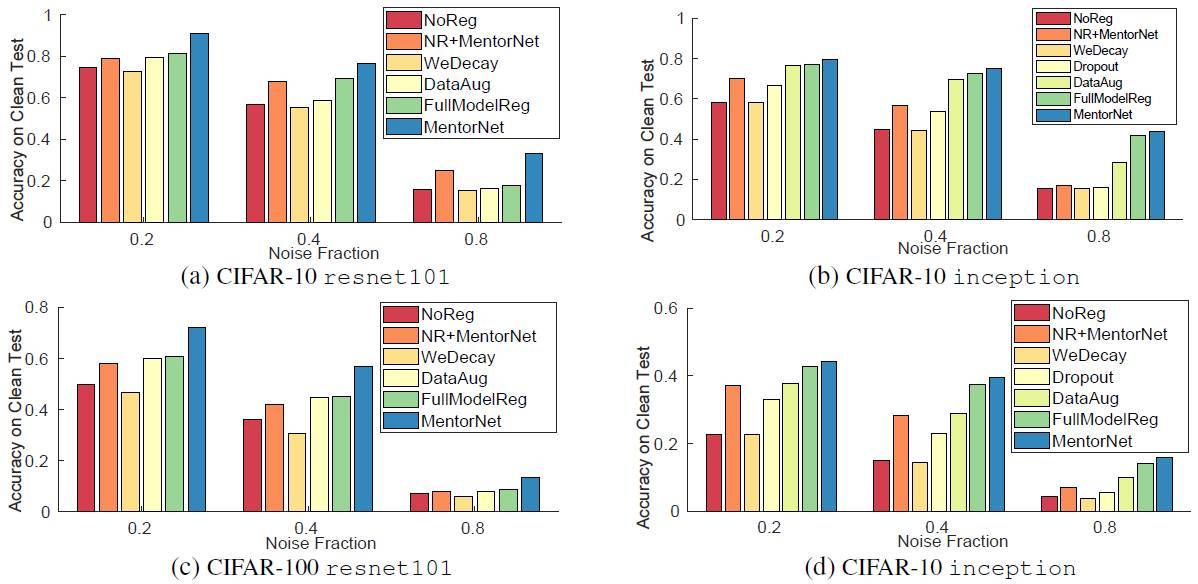
圖 4:經典正則化算法和我們的正則化算法在 CIFAR-10 和 CIFAR-100 上的結果比較。圖上說明了數據集和 StudentNet。x 軸和 y 軸分別表示噪聲比例和在清潔的測試數據上的分類準確度。
論文:MentorNet:在有損的標籤上正則化非常深度的神經網絡(MentorNet: Regularizing Very Deep Neural Networks on Corrupted Labels)
論文鏈接:https://arxiv.org/abs/1712.05055
摘要:最近的研究發現即使當標籤完全隨機時,深度網絡也能記憶整個數據。因爲深度模型是在標籤往往有噪聲的大數據上訓練的,過擬合噪聲可能會導致模型表現不佳。爲了克服過擬合有損訓練數據的問題,我們提出了一種在數據維中正則化深度網絡的全新技術。這種方法是學習一個名叫 MentorNet 的神經網絡來監督基礎網絡 StudentNet 的訓練。我們的工作受到了課程學習的啓發並且通過神經網絡從數據學習課程而推進了這一理論。我們在幾個基準上演示了 MentorNet 的效果。全方位的實驗表明其能夠顯著提升有損訓練數據上當前最佳深度網絡的泛化表現。