選自arXiv
英特爾實驗室聯合豐田研究院和巴塞羅那計算機視覺中心聯合發佈 CALRA,用於城市自動駕駛系統的開發、訓練和驗證的開源模擬器,支持多種傳感模式和環境條件的靈活配置,論文中詳細評估並比較了三種自動駕駛方法的性能。
模擬器和配套的資源將會發布在官方網站:http://carla.org。
論文:CARLA:An Open Urban Driving Simulator

論文鏈接:https://arxiv.org/abs/1711.03938
摘要:本文介紹一款用於自動駕駛研究的開源模擬器:CARLA。CARLA 的開發包括從最基礎的直到支持城市自動駕駛系統的開發、訓練和驗證。除了開源代碼和協議,CARLA 還提供了爲自動駕駛創建的開源數字資源(包括城市佈局、建築以及車輛),這些資源都是可以免費獲取和使用的。這個模擬平臺能夠支持傳感套件和環境條件的靈活配置。我們使用 CARLA 來研究三種自動駕駛方法的性能:傳統的模塊化流水線,通過模仿學習訓練得到的端到端模型,通過強化學習訓練得到的端到端模型。這三種方法在難度遞增的受控環境中做了評估,並用 CARLA 提供的指標進行性能測試,表明 CARLA 可以用來進行自動駕駛的研究。在這個網址中可以看到補充的視頻:https://youtu.be/Hp8Dz-Zek2E。

圖 1:四種不同天氣下城市 2 中的一條街道(第三人稱視角)。從左上順時針開始:晴天、雨天、雨後、晴朗的黃昏。在補充視頻中可以看到模擬器中的錄像。

圖 2:CARLA 提供的三種不同模式的傳感。從左到右依次是:正常的攝像頭視覺、真實深度、真實語義分割。深度和語義分割是由支持控制感知作用實驗的僞傳感器提供的。額外的傳感器模型可以通過 API 接入。
我們在四個難度遞增的駕駛任務重測評了這三種方法—模塊化的流水線(MP)、模仿學習(IL)、以及強化學習(RL),每個測評都分別在兩個不同的城市和六種天氣條件中進行。需要注意的是,我們在四個任務上對這三種方法的測試使用的是同一個智能體,並沒有爲某個場景而單獨地去微調一個模型。任務被設置爲目標導向的導航:智能體被初始化在城市的某個地方,然後它必須到達指定的目的點。在這些實驗中,允許智能體忽略速度限制和交通信號燈。我們遵循難度遞增的順序來安排這些任務,如下:
1. 直線:出發地點和目的地在同一條直線上,而且環境中也沒有運動的物體。平均行駛距離是:城市 1 中 200m,城市 2 中 100m。
2. 一次轉彎:從出發點到目的地需要一次轉彎;沒有運動的物體。平均行駛距離是:城市 1 中 400m,城市 2 中 170m。
3. 導航:沒有與出發點相關的目的地的嚴格限定,沒有運動的物體。距離目標的平均行駛距離是:城市 1 中 770m,城市 2 中 360m。
4. 具有運動障礙物的導航:與上一個的任務一樣,但是有運動的障礙物(包括車輛和行人)。
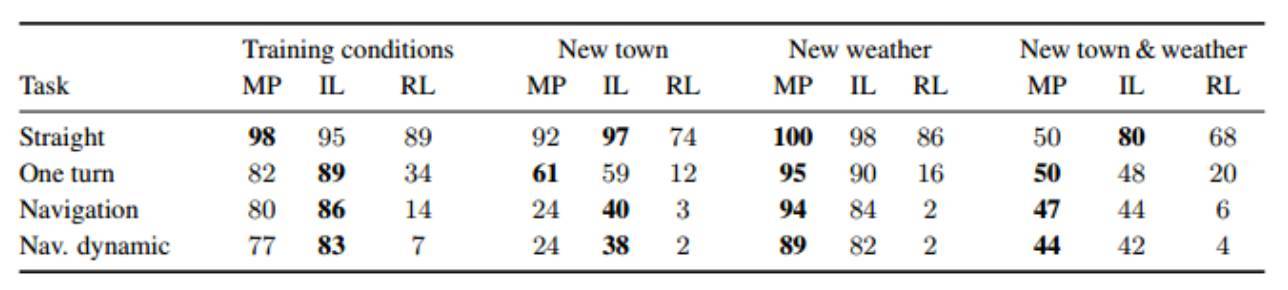
表 1:三種自動駕駛系統在目標導向導航任務中的量化測評。這張表記錄了在每一種環境下每個不同的方法成功完成某個任務中的片段所佔的百分比,越高越好。被測試的三種方法分別是:模塊化流水線(MP)、模仿學習(IL)、以及強化學習(RL)。
表 1 記錄了在每一種環境下每個不同的方法成功完成某個任務中的片段所佔的百分比。首先是訓練條件:城市 1,訓練天氣集。要注意,測試中和訓練過程中使用的起點和目標點是不一樣的:只有通用的環境和條件是一樣的。其他三種實驗條件均設置在具有挑戰性的泛化中:之前從未見過的城市 2 以及從未見過的訓練天氣集。
表 1 中的結果證明了以下結論。總之,即便是在直線行駛的任務中,三種方法都不是完美的,成功率隨着任務難度的增加急劇下降。泛化到新的天氣要比泛化到新的城市更加容易。模塊化流水線法和模擬學習的方法在大多數任務中的性能都平分秋色。強化學習方法的性能趕不上前兩者。我們現在更具體討論一下這四個關鍵結論(見原文)。
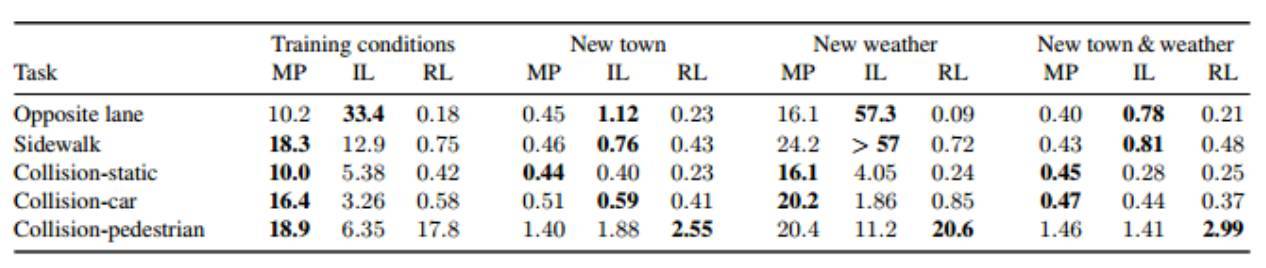
表 2:兩次違規行駛之間的平均行駛距離從(km)。數字越大,性能越好。
違規分析:CARLA 支持細粒度的駕駛規則分析。我們現在測試一下這三個系統在最難的任務上的行爲:在具有運動障礙物的環境中導航。我們用這三種方法在五種不同類型的兩次違規間行駛的平均距離來描述它們的性能:在相反的車道上行駛,在人行道行駛,與其他車輛並道行駛,與行人並道行駛,碰到靜態物體。附錄中有具體細節。
表 2 記錄了在兩次違規行駛之間駕駛的平均距離(km)。所有的方法都在訓練的城市 1 中表現更好一些。對於所有的實驗條件,模仿學習偏離到對向車道的頻率是最低的,強化學習的質量是最糟糕的。在偏向人行道的情況中也是類似的模式。令人驚訝的是,強化學習與行人衝突的頻率是最低的,也許這可以通過在這種碰撞中得到的巨大的負面回報來解釋。然而,強化學習智能體在避免與行駛的車輛以及靜態障礙物發生碰撞時不夠成功,而模塊化流水線方法通常能夠在這些測試中表現得最好。
這些結果突出了端到端方法對罕見事件的脆弱性:在訓練期間很少遇到急剎車或者急轉彎來避免與行人碰撞的情況。儘管可以在訓練期間加大這類事件的頻率以支持端到端訓練方法,但是爲了得到在魯棒性上的重大突破,學習算法和模型架構上的深層進展是很有必要的。