選自arXiv
作者:Samuel L. Smith等
參與:李亞洲、路雪
谷歌大腦在最新的一篇論文中提出,通過增加訓練過程中的 batch size,能夠在訓練集和測試集上取得類似學習率衰減的表現。此外這種方法還有一系列的優勢:參數更新數量更少、更強大的並行、更短的訓練時間等等。機器之心對此論文做了摘要介紹,更詳細的內容請閱讀原論文。

論文鏈接:https://arxiv.org/abs/1711.00489
摘要:學習率衰減是一種常見的方法。在這篇論文中,我們展示了通過增加訓練過程中的 batch size 也能在訓練集和測試集上獲得同樣的學習曲線。這一方法對隨機梯度下降(SGD)、帶有動量的 SGD、Nesterov 動量和 Adam 同樣有效。在經過同樣數量的訓練 epoch 之後,它能獲得同樣的測試準確率,且需要進行的參數更新更少,從而實現更強大的並行、更短的訓練時間。通過增加學習率ϵ、縮放 batch size B∝ϵ,我們可以進一步減少參數更新的數量。最後,你可以增加動量係數 m,縮放 B∝1/(1−m),儘管這會稍微降低測試準確率。最重要的是,該技術能讓我們在不調整超參數的情況下,重設對大型 batch 訓練的現有訓練調度方法(schdule)。我們在 ImageNet 上訓練 ResNet-v2,驗證準確率達到 77%,參數更新低於 2500,高效利用了 65536 張圖片的訓練 batch。
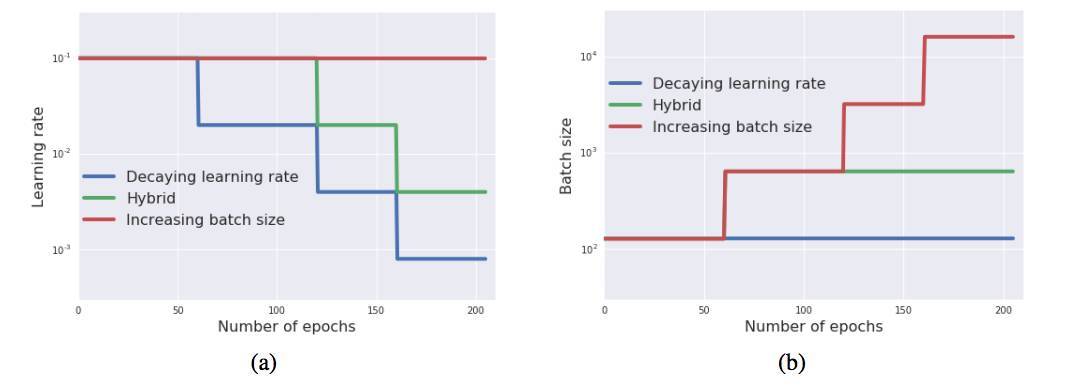
圖 1:作爲訓練 epcoch 中的函數,學習率(a)和 batch size(b)的調度方法
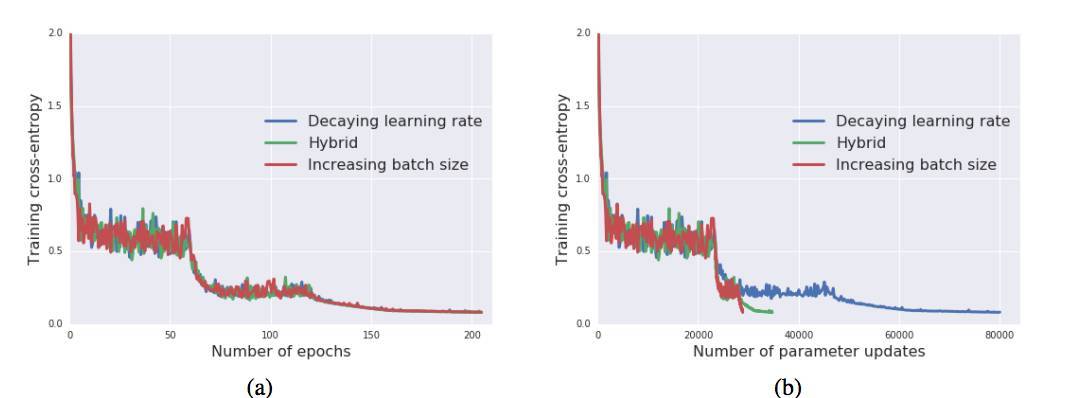
圖 2:訓練集的交叉熵,(a)橫軸爲訓練 epoch 的數量,(b)橫軸爲參數更新數量。三種學習曲線變化一致,但增加 batch size 能極大地減少所需參數更新的數量。
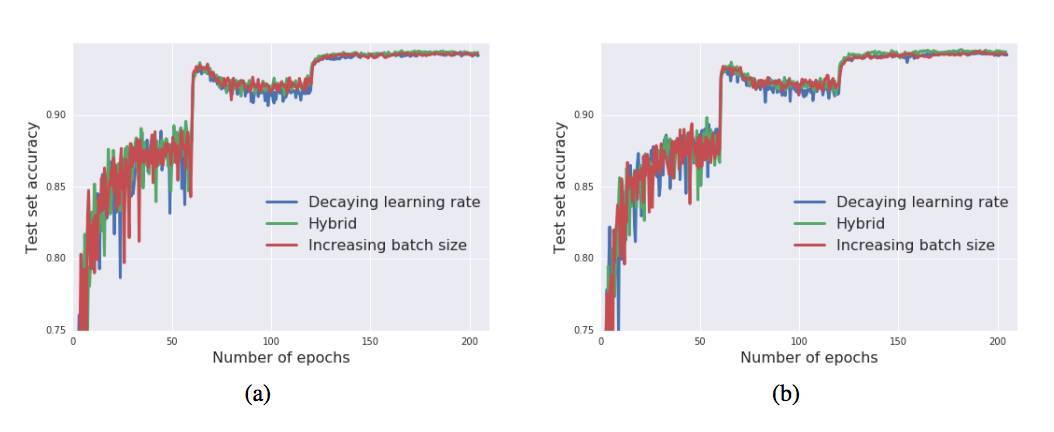
圖 3:訓練過程中的測試集準確率,(a)帶有動量的 SGD,(b)帶有 Nesterov 動量的 SGD。在兩種情形中,三種調度方法的曲線變化保持一致。
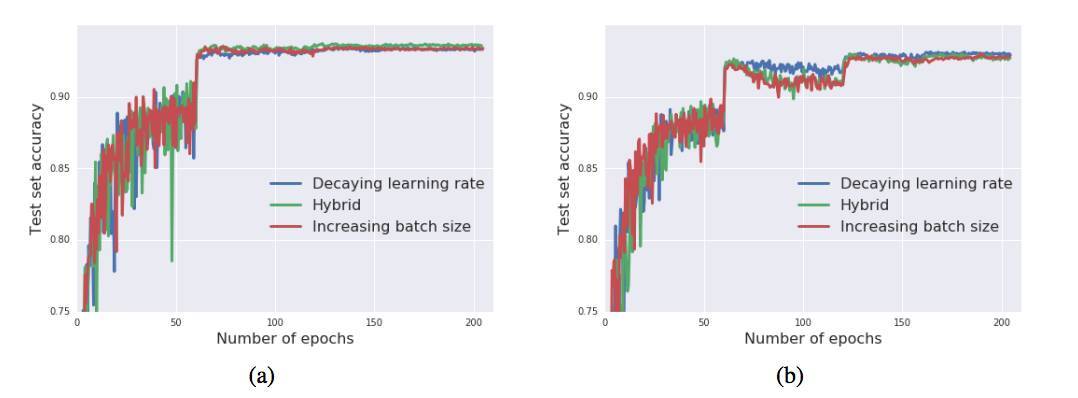
圖 4:訓練過程中的測試集準確率,(a)vanilla SGD,(b)Adam。同樣,三種調度方法的測試集表現一致。
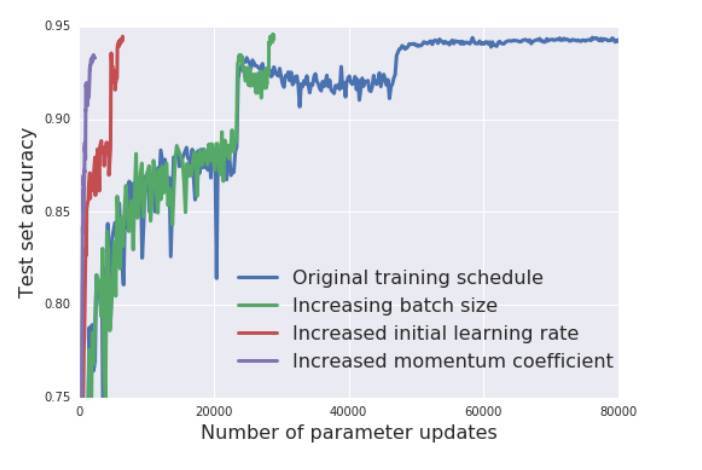
圖 5:不同的訓練調度方法下,測試集準確率隨着參數更新數量的變化而變化。通過增加 batch size 取代學習率衰減的「增加 batch size」方法;把初始學習率從 0.1 增加到 0.5 的「增加初始學習率」方法;最後是把動量係數從 0.9 增加到 0.98 的「增加動量係數」方法。
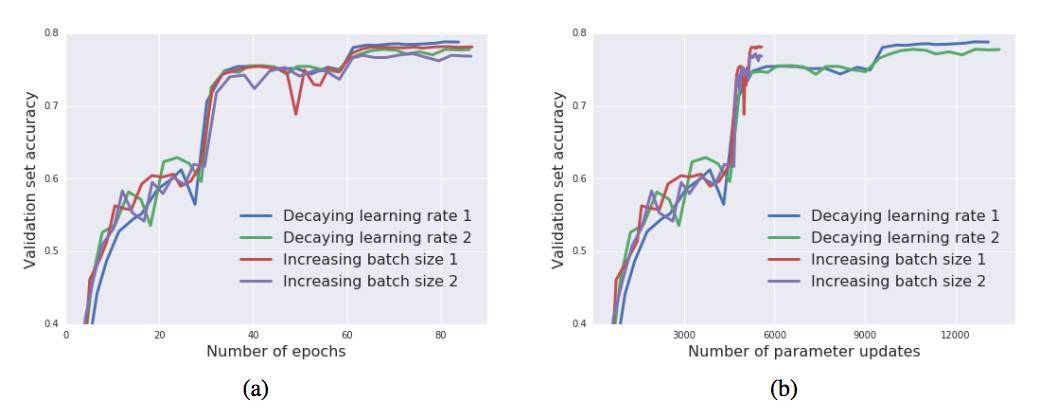
圖 6:在 ImageNet 上訓練 Inception-ResNet-V2。增加 batch size 能獲得與學習率衰減類似的結果,但這種方法能夠減少參數更新的數量,從 14000 降低到 6000。我們可以把每個實驗運行兩次來說明其中的變化。
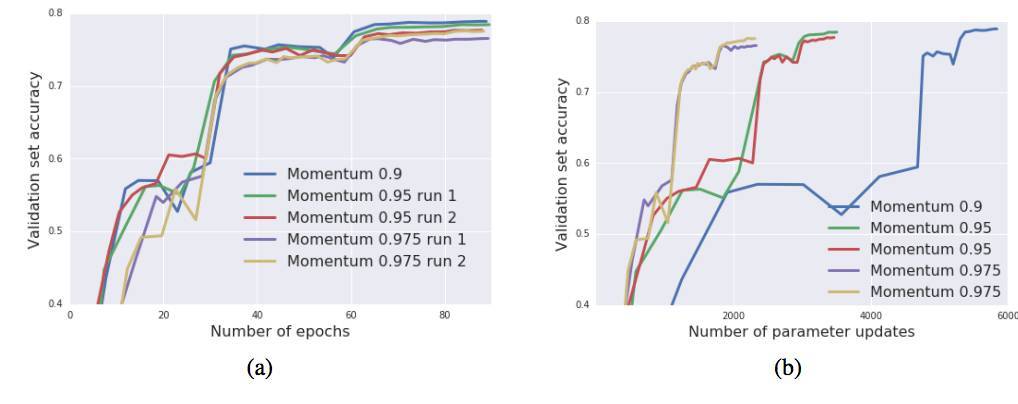
圖 7:在 ImageNet 上訓練 Inception-ResNet-V2。增加動量參數能夠減少所需參數更新的數量,但也導致最終測試準確率的略微下降。
本文爲機器之心編譯,轉載請聯繫本公衆號獲得授權。
責任編輯: