2016 年,人工智能行業經歷了語音識別準確率飆升、神經機器翻譯重大突破、圖像風格遷移的興盛。2017 年,人們對於 AI 領域的期待變得更高了,不過在這一年裏,各家科研機構和大學仍爲我們帶來了很多激動人心的研究成果。本文將試圖對 2017 年人工智能領域實現的重要科研成果進行盤點。
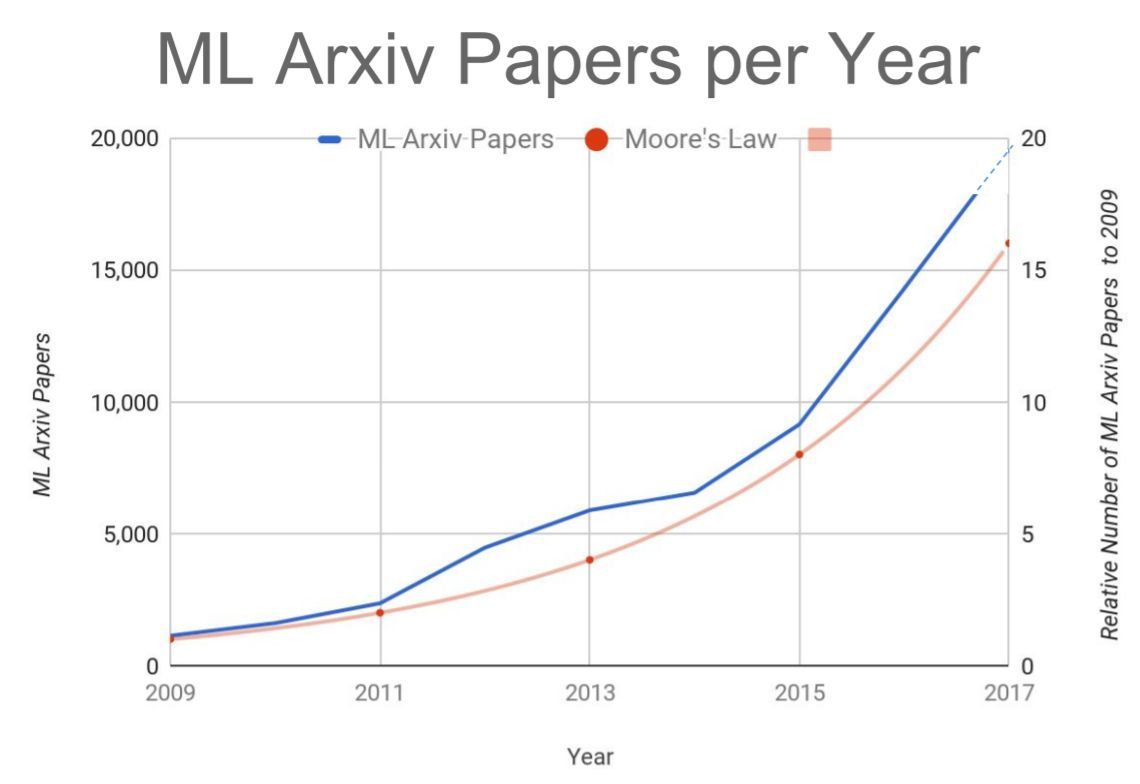
來自谷歌大腦負責人 Jeff Dean 的 Keynote:人們在 arXiv 上提交的機器學習論文數量正遵循摩爾定律增長。人工智能技術的發展速度是否也有這麼快?
AlphaGo:從「零」開始

今天,每當聊起人工智能,我們就不得不提 AlphaGo,這款由谷歌旗下研究型公司 DeepMind 開發的著名圍棋程序在 2017 年再次掀起了 AI 的熱潮。從年初借「Master」名義在網絡圍棋平臺上迎戰各路人類圍棋高手,到 5 月與柯潔等人的「人機最後一戰」,AlphaGo 的故事在 10 月份以又一篇 Nature 論文「AphaGo Zero」再次展示了計算機在圍棋上強大的能力;緊隨而至的 AlphaZero 則將這種強大泛化到了其他領域中。
我們也親歷了 AlphaGo 事件的始末。在 5 月份人機大戰時,除了現場報道之外,我們還邀請了阿爾伯塔大學教授、計算機圍棋頂級專家 Martin Müller 以及《深度強化學習綜述》論文作者李玉喜博士,共同觀看了比賽直播。Müller 教授所帶領的團隊在博弈樹搜索和規劃的蒙特卡洛方法、大規模並行搜索和組合博弈論方面頗有建樹。實際上,參與了大師級圍棋程序 AlphaGo 的設計研發的 David Silver 和黃士傑(Aja Huang)(他們分別是第一篇 DeepMind 的 AlphaGo 相關 Nature 論文的第一作者和第二作者)都曾師從於他。
在擊敗柯潔等中國圍棋名手之後,隨着 DeepMind 宣佈人機大戰計劃結束,AlphaGo 的故事似乎已經結束。然而在 10 月 18 日,DeepMind 的又一篇 Nature論文《Mastering the game of Go without human knowledge》再次讓全世界感到震驚。在論文中,DeepMind 首次展示了全新版本的 AlphaGo Zero —— 無需任何人類知識標註。在歷時三天,數百萬盤的自我對抗之後,它可以輕鬆地以 100 比 0 的成績擊敗李世乭版本的 AlphaGo。DeepMind 創始人哈薩比斯表示:「Zero 是迄今爲止最強大,最具效率,最有通用性的 AlphaGo 版本——我們將見證這項技術很快應用到其他領域當中。」
沒等多久,哈薩比斯的宣言就初步實現了,在 12 月 NIPS 2017 大會舉行期間,DeepMind 又放出了一篇論文《Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm》,其中描述了使用 AlphaGo Zero 技術,並可泛化至其他領域任務的新一代算法 AlphaZero。新的算法可以從零開始,通過自我對弈強化學習在多種任務上達到超越人類水平。據稱,它在經過不到 24 小時的訓練後,可以在國際象棋和日本將棋上擊敗目前業內頂尖的計算機程序(這些程序早已超越人類世界冠軍水平),也可以輕鬆擊敗訓練 3 天時間的 AlphaGo Zero。
12 月 11 日,DeepMind 發佈了圍棋教學程序,其中收錄了約 6000 個近代圍棋史上的主要開局變化,所有變化都附帶了 AlphaGo 評估的勝率。DeepMind 希望以此推動人類圍棋水平的進步,在公佈之後,AlphaGo 的重要研究成員黃士傑博士宣佈離開項目,轉向 DeepMind 旗下的其他方向研究,此舉宣告了 AlphaGo 在圍棋方向上的研究告於段落。
延伸閱讀:
德州撲克擊敗人類:DeepStack 與 Libratus

德州撲克這種複雜的撲克遊戲已經被人工智能(AI)掌握。而且這個遊戲還不是被征服了一次——兩個不同的研究團隊所開發的 bot 都在一對一德州撲克比賽上完成了擊敗人類的壯舉。今年1月份,卡耐基梅隆大學(CMU)開發的名爲 Libratus 的人工智能程序在賓夕法尼亞州匹茲堡的 Rivers 賭場爲期20天的一對一德撲比賽中擊敗了4 名人類職業玩家 Jason Les、Dong Kim、Daniel McAulay 和 Jimmy Chou。而在另一邊,加拿大阿爾伯塔大學、捷克布拉格查理大學和捷克理工大學的研究者聯合發表的論文《Deepstack: Expert-level artificial intelligence in heads-up no-limit poker》出現在了著名學術期刊《Science》上,該研究團隊展示了人工智能已經在無限制撲克(No-Limit Poker)遊戲上達到了專家級的水平。
與信息完全公開的圍棋不同,德州撲克是「不完美信息(imperfect information)」類博弈,能反映真實生活中我們面臨問題時的場景,諸如拍賣以及業務談判,因而在德州撲克上的技術突破也意味着人工智能技術的發展速度正在加快。
有趣的是,在解決同樣的問題時,DeepStack 與 Libratus 採取的方式不盡相同:DeepStack 採用的是深度學習針對大量牌局變化進行訓練(超過 1100 萬局),從而獲得在實際比賽時對獲勝概率擁有「直覺」;而 Libratus 採用的是基於納什均衡的博弈求解技術。
延伸閱讀:
自歸一化神經網絡
《Self-Normalizing Neural Networks》是今年 6 月份在 arXiv 上公開的一篇機器學習論文,後被 NIPS 2017 大會接收,它的作者爲奧地利林茲大學的 Günter Klambauer、 Thomas Unterthiner 與 Andreas Mayr。這篇論文在提交後引起了圈內極大的關注,它提出了縮放指數型線性單元(SELU)而引進了自歸一化屬性,該單元主要使用一個函數 g 映射前後兩層神經網絡的均值和方差以達到歸一化的效果。值得注意的是,該論文作者 Sepp Hochreiter 曾與 Jürgen Schmidhuber 一同提出了 LSTM,之前的 ELU 同樣來自於他們組。回到論文本身,這篇 NIPS 論文雖然只有 9 頁正文,卻有着如同下圖一樣的 93 頁證明附錄:

不知當時審閱這篇論文的學者心情如何。無論如何,它提出的方法可以讓你稍稍修改 ELU 激活就能讓平均單位激活趨向於零均值/單位方差(如果網絡足夠深的話)。如果它最終是正確的方向,批處理規範就會變得過時,而模型訓練速度將會大大加快。至少在論文中的實驗裏,它擊敗了 BN + ReLU 的準確性。
論文鏈接:https://arxiv.org/abs/1706.02515
延伸閱讀:
引爆機器學習圈:「自歸一化神經網絡」提出新型激活函數SELU
GAN 及其各種變體

2016 年,Yann LeCun 曾稱 GAN 是深度學習領域最重要的突破之一,而我們在2016 年也看到了 GAN 變體衍生的苗頭,比如 Energy-based GAN 和最小二乘網絡 GAN。到了 2017 年初,我們就看到了各種 GAN 變體如雨後春筍般出現,其中一篇名爲 WGAN 的論文在年後不久引發了業界極大的討論,有人稱之「令人拍案叫絕」。
從 2014 年 Ian Goodfellow 提出 GAN 以來,它就存在着訓練困難、生成器和判別器的 loss 無法指示訓練進程、生成樣本缺乏多樣性等問題。雖然後續的變體都在嘗試解決這些問題,但效果不盡人意。而 Wasserstein GAN 成功做到了以下幾點:
徹底解決 GAN 訓練不穩定的問題,不再需要小心平衡生成器和判別器的訓練程度
基本解決了 collapse mode 的問題,確保了生成樣本的多樣性
訓練過程中終於有一個像交叉熵、準確率這樣的數值來指示訓練的進程,這個數值越小代表 GAN 訓練得越好,代表生成器產生的圖像質量越高(如題圖所示)
以上一切好處不需要精心設計的網絡架構,最簡單的多層全連接網絡就可以做到
除了 WGAN,也有其他多種 GAN 的變體於 2017 年出現,我們以資源列表的形式爲大家列出:
然而到了年底,谷歌大腦的一篇論文對目前火熱的GAN研究敲響警鐘。在一篇名爲《Are GANs Created Equal?A Large-Scale Study》的論文中, 研究人員對 Wasserstein GAN 等 GAN 目前的六種變體進行了詳盡的測試,得出了「沒有找到任何證據證明任何一個算法優於原版算法」的結論(參見:六種改進均未超越原版:谷歌新研究對 GAN 現狀提出質疑)。或許我們應該更多地把目光轉向到新架構上了。
深度神經網絡碰上語音合成

近年來,隨着深度神經網絡的應用,計算機理解自然語音的能力有了徹底革新,例如深度神經網絡在語音識別、機器翻譯中的應用。但是,使用計算機生成語音(語音合成(speech synthesis)或文本轉語音(TTS))仍在很大程度上基於所謂的拼接 TTS(concatenative TTS)。而這種傳統的方法所合成語音的自然度、舒適度都有很大的缺陷。深度神經網絡,能否像促進語音識別的發展一樣推進語音合成的進步,也成爲了人工智能領域研究的課題之一。
2016 年,DeepMind 提出了 WaveNet,在業內引起了極大的關注。WaveNet 可以直接生成原始音頻波形,能夠在文本轉語音和常規的音頻生成上得到出色的結果。但就實際應用而言,它存在的一個問題就是計算量很大,沒辦法直接用到產品上面。因此,這個研究課題還有非常大的提升空間。
2017 年,我們見證了深度學習語音合成方法從實驗室走向產品。從我們注到的內容,我們簡單梳理出瞭如下研究:
谷歌:Tacotron、WaveNet(應用於谷歌助手)
百度:Deep Voice、Deep Voice 2(NIPS 2017)、Deep Voice 3(提交 ICLR 2018)
蘋果:hybrid unit selection TTS system (應用於Siri)
延伸閱讀:
大批量數據並行訓練 ImageNet

深度學習隨着大型神經網絡和大型數據集的出現而蓬勃發展。然而,大型神經網絡和大型數據集往往需要更長的訓練時間,而這正好阻礙研究和開發進程。分佈式同步 SGD 通過將小批量 SGD(SGD minibatches)分發到一組平行工作站而提供了一種很具潛力的解決方案。然而要使這個解決方案變得高效,每一個工作站的工作負載必須足夠大,這意味着 SGD 批量大小會有很大的增長(nontrivial growth)。今年 6 月,Facebook 介紹了一項研究成果——一種將批量大小提高的分佈式同步 SGD 訓練方法,引發了一場「快速訓練 ImageNet」的競賽。隨着參與研究的機構越來越多,截至 11 月,UC Berkeley 的研究人員已將 ResNet-50 在 ImageNet 上的訓練時間縮短到了 48 分鐘。
延伸閱讀:
革新深度學習:Geoffrey Hinton 與 Capsule
衆所周知,最近一波人工智能行業浪潮是由深度學習及其發展引發的。然而,這一方法是否能夠將人類帶向通用人工智能?作爲深度學習領軍人物,關鍵機制反向傳播提出者之一的 Geoffrey Hinton 率先提出拋棄反向傳播,革新深度學習。他的創新方法就是 Capsule。
Capsule 是由深度學習先驅 Geoffrey Hinton 等人提出的新一代神經網絡形式,旨在修正反向傳播機制。在 Dynamic Routing Between Capsules 論文中,Geoffrey Hinton 這樣介紹 Capsule:「Capsule 是一組神經元,其輸入輸出向量表示特定實體類型的實例化參數(即特定物體、概念實體等出現的概率與某些屬性)。我們使用輸入輸出向量的長度表徵實體存在的概率,向量的方向表示實例化參數(即實體的某些圖形屬性)。同一層級的 capsule 通過變換矩陣對更高級別的 capsule 的實例化參數進行預測。當多個預測一致時(本論文使用動態路由使預測一致),更高級別的 capsule 將變得活躍。」
Capsule 中神經元的激活情況表示了圖像中存在的特定實體的各種性質。這些性質可以包含多種不同的參數,例如姿勢(位置、大小、方向)、變形、速度、反射率、色彩、紋理等。而輸入輸出向量的長度表示了某個實體出現的概率,所以它的值必須在 0 到 1 之間。
我們也詳細解讀了 10 月 Hinton 公開的論文,這篇論文的亮點在於 Capsule 層的輸入與輸出都是向量,構建向量的過程可以認爲是 PrimaryCaps 層利用 8 個標準的 Conv2D 操作產生一個長度爲 8 個元素的向量,因此每一個 Capsule 單元就相當於 8 個卷積單元的組合。此外,在 Capsule 層中,Hinton 等人還使用了動態路由機制,這種更新耦合係數(coupling coefficient)的方法並不需要使用反向傳播機制。
除了 Hinton 等人公佈的 Capsule 論文以外,還有一篇《MATRIX CAPSULES WITH EM ROUTING》論文,該論文采用 EM Routing 修正原論文的 dynamic routing 從而實現更好的效果。
延伸閱讀:
超越神經網絡?Vicarious 提出全新概率生成模型
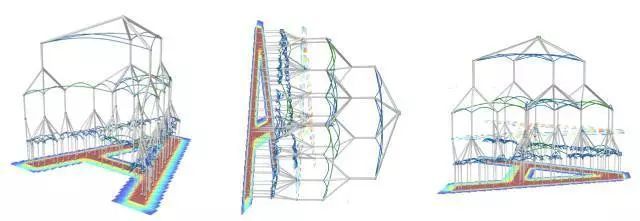
代表字母 A 的四層遞歸皮質網絡結構
儘管曾受到 Yann LeCun 等人的質疑,但知名創業公司 Vicarious 提出的生成視覺模型論文仍然發表到了 Science 上。這種全新的概率生成模型(又名遞歸皮質網絡)能在多種計算機視覺任務中實現強大的性能和高數據效率,具有識別、分割和推理能力,在困難的場景文字識別等基準任務上超過了深度神經網絡。研究人員稱,這種方法或許會將我們帶向通用人工智能。
該模型表現出優秀的泛化和遮擋推理(occlusion-reasoning)能力,且更具有 300 倍的訓練數據使用效率(data efficient)優勢。此外,該模型還突破了基於文本的全自動區分計算機和人類的圖靈測試 CAPTCHA,即在沒有具體驗證碼的啓發式方法下分割目標。
「我認爲 CAPTCHA 是一個『完全的 AI 問題』。如果你完全地解決了這種類型的問題,那你就得到了通用人工智能。」Vicarious CTO George 告訴我們,爲了能徹底識別 CAPTCHA,模型必須能識別任何文本。不只是驗證碼,即使有人在紙上隨便寫什麼形式的字體(就像 PPT 裏的藝術字一樣),模型也需要識別出來。
遞歸皮質網絡不只是用來攻破 CAPTCHA,它還將被應用在控制、推理、機器人技術上。近兩年,Vicarious AI 已經在實驗室裏研究如何將技術應用到工業機器人上。工業機器人是目前 Vicarious AI 技術落地的方式,但並不意味着 Vicarious AI 會就此止步。Vicarious AI 希望在 2040 年前後實現高等智能的 A.I.。
延伸閱讀:
從 TPU 到 NPU:席捲所有設備的神經網絡處理器

人工智能的最近一次浪潮起源於 2011 年前後深度學習引起的大發展。從語音識別到訓練虛擬助理進行自然交流,從探測車道線到讓汽車完全自動駕駛,數據科學家們在技術的發展過程中正一步步攀登人工智能的新高度。而解決這些日益複雜的問題則需要日益複雜的深度學習模型。而在其背後,快速發展的 GPU 技術功不可沒,硬件計算能力突破是這次深度學習大發展背後的原因。
近年來,人們逐漸認識到計算芯片對於人工智能的重要性,圍繞 AI 任務進行專有加速的芯片越來越多,2017 年也成爲了深度學習計算專用芯片不斷投入商用的一年。無論是 AlphaGo 背後的谷歌 TPU ,還是加入了全新 Tensor Core 結構的英偉達 Tesla V100,爲服務器端設計的深度學習專用芯片已經獲得了大規模應用,成爲了雲服務基礎設施必不可少的一部分。而在移動端,對於機器學習任務加速的 SoC 也隨着蘋果 A11(Neural Engine)與華爲麒麟 970(NPU)的推出而來到了用戶的手中。今天,一些神經網絡已經可以塞進智能手機中,爲多種APP 提供判斷能力,而科技巨頭的服務器正以前所未有的高效率處理無數有關機器學習的任務請求,我們所設想的人工智能生態體系正在逐漸成型。
延伸閱讀:
總結
從 AlphaGo 技術通用化到 Geoffrey Hinton 傾力推動的 Capsule,我們可以看到,2017 年的人工智能行業不僅正將技術落地,也在向實現通用 AI 的終極挑戰不斷進發。隨着我們對於深度學習探索的深入,新技術的利與弊已經逐漸展現在了我們的眼前,除了打造產品服務用戶,探索新的方向是刻不容緩的任務。在2018 年,人工智能領域將面臨怎樣的變革?讓我們共同期待。
來源:http://www.sohu.com/a/213685822_465975