雷鋒網 AI 科技評論按:近日 Facebook 科學家團隊發佈基於主題標籤的深度學習方法,使用已有的擁有主題標籤的圖片作爲訓練數據,從而大幅提升了訓練數據集的大小。數據集的增大必然會引起圖片錯誤率的提升,他們同時發佈了處理圖片噪音的方法。他們團隊的這項工作對於現今的圖片識別領域有着廣泛而深遠的影響。雷鋒網(公衆號:雷鋒網)對全文翻譯如下。
圖片識別是AI 的一個支柱領域,目前也是 Facebook 關注的領域之一。我們的研究人員與工程師專注於開拓 CV 的邊界,並將相關工作應用到生活中從而服務世界。例如,利用 AI 生成圖片的音頻提示來照顧一些視力受損的用戶。爲了改善我們的 CV 系統並使他們可以持續識別和分類各種各樣的物體,我們需要數以十億級的照片數據集,而不是今天常用的百萬數據集。
因爲現在用來訓練模型的數據集一般需要人爲標註的,所以簡單增加圖片(無標註)數量的方法並不能很好的提高識別效果。這種計算密集型的監督學習通常可以表現的很好,但缺點是這種手動標註的數據集的大小受到「手動」這個特點的嚴重限制。舉個例子,現在 Facebook 用一個有 5000 萬張圖片的數據集訓練模型,但「手動」將這個數據集拓展到 10 億級是非常難實現的。
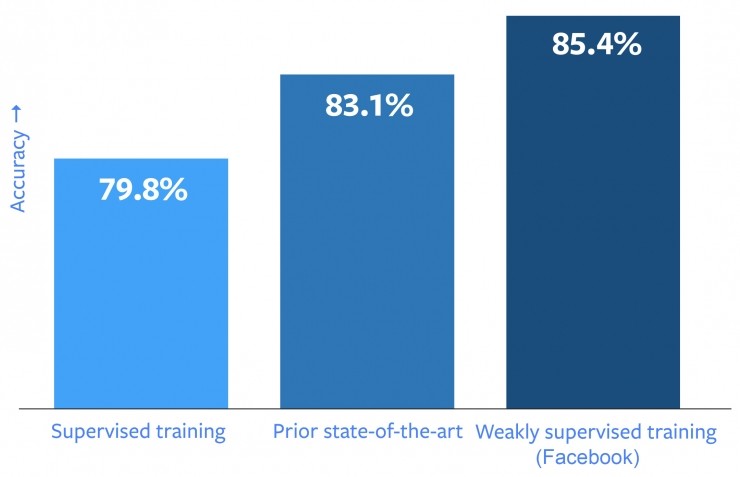
現在我們的研究員和工程師通過訓練帶有主題標籤的數據集的方法解決了這個問題,這個超大數據集包含了 35 億張圖片和 17,000 個主題標籤。這個方法的關鍵點在於使用已經存在的由用戶提供的公開主題標籤來取代手動分類的標籤。這個方法在我們的測試中表現良好。通過使用這個包含 10 億張圖片的版本訓練模型,我們的模型取得了 85.4% 的識別準確度,打破了 ImageNet(常用基準測試工具)的準確度記錄。這項工作除了在圖像識別性能上有了真正的突破,還爲如何從監督學習遷移到弱監督學習提供了重要思路,即使用已經存在的標籤(如本實驗中的主題標籤)而不是專門爲 AI 訓練而準備的標籤。我們打算在未來開源這些模型的嵌入部件,這樣其他研究團隊就可以在這個表示方法上使用、建立高級任務。
大規模使用主題標籤
人們通常會爲他們的照片打上主題標籤,我們由此認爲這是模型訓練數據的一個理想來源。我們使用主題標籤的另一個考量是主題標籤可以簡要概括某一類事物,從而讓圖片更加容易被理解。
但主題標籤經常會涉及到不直觀的概念,例如 #tbt 代表着「throwback Thursday」。有時又會模棱兩可,例如標籤 #party 既可以用來描述一項活動也可以表示一項設置。對於識別圖像這個目的來說,標籤被用作弱監督數據,那麼模棱兩可或者不相關的主題標籤就成了會誤導深度學習模型的「不相關標籤噪音」。
這些噪音標籤是我們大規模性訓練必須關注的核心問題,爲此我們研發出新的基於主題標籤的監督學習方法,這種方法針對圖像識別實驗進行了專門的調整。這些調整包括對每個圖片進行多標籤處理(人們通常給圖片打上不止一個標籤),按主題標籤同義詞進行排序,以及平衡常見標籤與不常見標籤對模型的影響。爲了讓標籤可以更好的應用於圖片識別訓練,我們團隊先訓練了一個大規模的主題標籤預測模型。這是一次效果極佳的遷移學習,結果這個模型分類後的圖片可以廣泛應用於其他 AI 系統。這項新的工作基於 Facebook 之前的研究,比如基於評論、主題標籤和視頻的圖像分類調查。這次對於弱監督學習的探索是 AML(Facebook's Applied Machine Learning)和 FAIR(Facebook Artificial Intelligence Research)廣泛合作的成果。
規模和性能雙雙破紀錄
由於一臺機器要花一年多時間才能完成模型訓練,我們發明了一種新方法將任務分發給 336 塊 GPU,這樣就將訓練時間縮短至一週。隨着訓練模型越來越大(我們研究中使用的最大的模型是有 8.61 億個參數的 ResNeXt 101-32x48d),這種分佈式訓練也越來越重要。除此之外,我們還設計了一個移除副本的方法,這種方法可以防止我們把待評估的圖片用來訓練模型—一個困擾此領域相關研究的問題。
儘管我們都希望圖片識別的性能提升,但結果着實給人驚喜。我們使用 10 億張圖片(含 1500 個主題標籤)訓練出的模型在 ImageNet 上取得了 85.4% 的準確率。這是當前 ImageNet 最高識別率,這成績比以往最佳模型的識別率高了 2%。考慮到卷積神經網絡架構的影響,目前可見的性能提升更加顯著:使用數以十億級的圖片(含主題標籤)進行深度學習,對識別率的提升高達 22.5%。
在另外一個基準測試—COCO 物體檢測挑戰中,我們發現使用主題標籤進行預訓練可以將模型的平均精度提升 2%。
這些是對圖像識別和物體檢測的基礎改進,代表着計算機視覺前進了一步。但是我們的實驗也揭示了與大規模訓練和噪音標籤相關的具體機遇和挑戰。
儘管提升訓練數據集的大小是非常有用,選擇和特定識別任務相匹配的主題標籤一樣重要。我們對 10 億張圖片(1500 個主題標籤且與 ImageNet 數據集中的類相匹配)進行訓練得到的結果要優於對 10 億張圖片(17000 個主題標籤)進行訓練的結果。另一方面,對具有更大視覺多樣性的任務,使用 17,000 個主題標籤進行訓練的模型的性能改進變得更加明顯,這表明我們應該在未來的訓練中增加主題標籤的數量。
增加訓練數據量通常對圖像分類有好處。但它可能會產生新的問題,包括圖像中物體定位能力的明顯下降。我們還了解到,我們當前最大的模型遠沒有充分利用 35 億圖像訓練集的數據,這意味着我們應該訓練更大的模型。
更大規模,自我標記的未來圖像識別
這項研究的一個重要結果—甚至比在圖像識別方面的各項改進還要重要—就是確認使用主題標籤去訓練計算機視覺模型完全可行。由於我們使用了一些基礎技術來合併同類主題標籤以及削弱標籤權重,我們完全不需要複雜的「清理」程序來消除標籤噪音。相反,我們可以用主題標籤訓練我們的模型並且對訓練過程修改很少。這時候數據集規模的提升就顯得很有益,因爲在數十億的圖像上訓練的模型顯示出對標籤噪聲的顯着恢復能力。
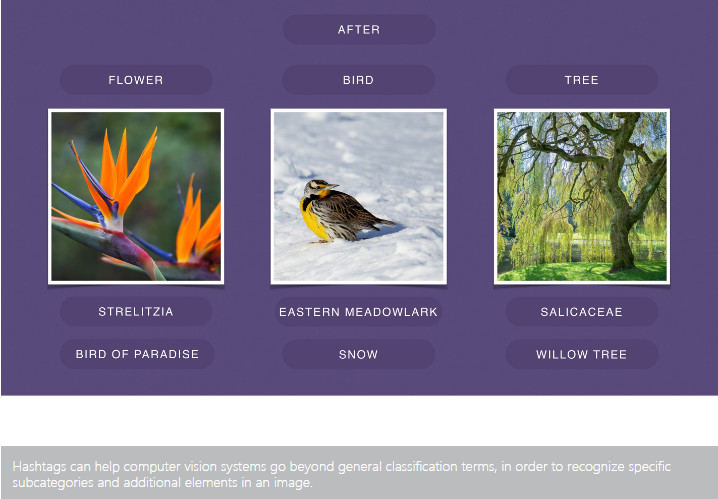
在不遠的將來,我們還設想了其他將主題標籤用作計算機視覺標籤的方式。這些方式可能包括使用 AI 來更好地理解視頻片段或改變圖片在 Facebook 推薦中的排名方式。主題標籤不僅可以幫助系統識別一般類別的圖片還可以識別特定子類別的圖片。例如,「樹上有個鳥」這種語音提示是有用的,但一個可以指明確切物種的語音提示可以爲視障用戶提供更好的場景描述,比如「一個北美紅雀棲息在北美楓樹上」。

拋開主題標籤的使用不談,這項研究依舊取得了廣泛的圖片識別相關的進展,這些改進足以影響現有產品和新產品。例如,更加精確的模型可能會改善我們在 Facebook 上呈現歷史記錄的方式。這項研究還指出長期影響與弱監督數據有關。隨着訓練數據集越來越大,弱監督(長期來說,無監督)學習變得越來越重要。知道如何彌補噪音大。標籤少的缺點對建立和使用的大規模訓練數據集至關重要。
Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan 等人的論文—「Exploring the Limits of Weakly Supervised Pretraining」對研究進行了詳細描述。因爲本實驗使用了超大規模級別的數據集,最後的觀測結果爲一系列新研究方向鋪平了道路,包括開發新一代的足夠複雜的深度學習模型用來從數十億的圖像中有效地學習。
這項工作還表明,我們需要開發像 ImageNet 一樣可以廣泛使用的新基準數據庫,一是可以讓我們更好地衡量當今圖像識別系統的質量和侷限性。二是爲以後更大,監督更弱的系統做準備。
雷鋒網認爲Facebook團隊這項工作對於現如今圖像識別領域會有很大影響。一是訓練數據集的提升導致訓練模型的提升,二是他們還引導學習方式從監督到弱監督的轉變。閱讀原文戳:Facebook F8。
