在驗證集上調優模型已經是機器學習社區通用的做法,雖然理論上驗證集調優後不論測試集有什麼樣的效果都不能再調整模型,但實際上模型的超參配置或多或少都會受到測試集性能的影響。因此研究社區可能設計出只在特定測試集上性能良好,但無法泛化至新數據的模型。本論文通過創建一組真正「未見過」的同類圖像來測量 CIFAR-10 分類器的準確率,因而充分了解當前的測試集是否會帶來過擬合風險。
1 引言
過去五年中,機器學習成爲一塊實驗田。受深度學習研究熱潮的驅動,大量論文圍繞這樣一種範式——新型學習技術出現的主要依據是它在多項關鍵基準上的性能提升。同時,很少有人解釋爲什麼這項技術是對先前技術的可靠改進。研究者對研究進展的認知主要依賴於少量標準基準,如 CIFAR-10、ImageNet 或 MuJoCo。這就引出了一個關鍵問題:
目前機器學習領域衡量研究進展的標準有多可靠?
對機器學習領域的進展進行恰當評估是一件非常精細的事情。畢竟,學習算法的目標是生成一個可有效泛化至未見數據的模型。由於通常無法獲取真實數據的分佈,因此研究人員轉而在測試集上評估模型性能。只要不利用測試集來選擇模型,這就是一種原則性強的評估方案。
不幸的是,我們通常只能獲取具備同樣分佈的有限新數據。現在大家普遍接受在算法和模型設計過程中多次重用同樣的測試集。該實踐有很多例子,包括一篇論文中的調整超參數(層數等),以及基於其他研究者的研究構建模型。儘管對比新模型與之前模型的結果是非常自然的想法,但很明顯當前的研究方法論削弱了一個關鍵假設:分類器與測試集是獨立的。這種不匹配帶來了一種顯而易見的危險,研究社區可能會輕易設計出只在特定測試集上性能良好,但無法泛化至新數據的模型 [1]。
1.1 在 CIFAR-10 上的復現性研究
爲了瞭解機器學習當前進展的可靠性,本文作者設計並實施了一種新型復現性研究。主要目標是衡量現在的分類器泛化至來自同一分佈的未見數據的性能。研究者主要使用標準 CIFAR-10 數據集,因爲它的創建過程是透明的,尤其適合這項任務。此外,近十年的大量研究使用 CIFAR-10。由於該過程的競爭性本質,這是一項調查適應性(adaptivity)是否導致過擬合的優秀測試用例。
該研究分爲三步:
1. 首先,研究者創建一個新的測試集,將新測試集的子類別分佈與原始 CIFAR-10 數據集進行仔細匹配。
2. 在收集了大約 2000 張新圖像之後,研究者在新測試集上評估 30 個圖像分類模型的性能。結果顯示出兩個重要現象。一方面,從原始測試集到新測試集的模型準確率顯著下降。例如,VGG 和 ResNet 架構 [7, 18] 的準確率從 93% 下降至新測試集上的 85%。另一方面,研究者發現在已有測試集上的性能可以高度預測新測試集上的性能。即使在 CIFAR-10 上的微小改進通常也能遷移至留出數據。
3. 受原始準確率和新準確率之間差異的影響,第三步研究了多個解釋這一差距的假設。一種自然的猜想是重新調整標準超參數能夠彌補部分差距,但是研究者發現該舉措的影響不大,僅能帶來大約 0.6% 的改進。儘管該實驗和未來實驗可以解釋準確率損失,但差距依然存在。
總之,研究者的結果使得當前機器學習領域的進展意味不明。適應 CIFAR-10 測試集的努力已經持續多年,模型表現的測試集適應性並沒有太大提升。頂級模型仍然是近期出現的使用 Cutout 正則化的 Shake-Shake 網絡 [3, 4]。此外,該模型比標準 ResNet 的優勢從 4% 上升至新測試集上的 8%。這說明當前對測試集進行長時間「攻擊」的研究方法具有驚人的抗過擬合能力。
但是該研究結果令人對當前分類器的魯棒性產生質疑。儘管新數據集僅有微小的分佈變化,但廣泛使用的模型的分類準確率卻顯著下降。例如,前面提到的 VGG 和 ResNet 架構,其準確率損失相當於模型在 CIFAR-10 上的多年進展 [9]。注意該實驗中引入的分佈變化不是對抗性的,也不是不同數據源的結果。因此即使在良性設置中,分佈變化也對當前模型的真正泛化能力帶來了嚴峻挑戰。
4 模型性能結果
完成新測試集構建之後,研究者評估了多種不同的圖像分類模型。主要問題在於如何對原始 CIFAR-10 測試集上的準確率和新測試集上的準確率進行比較。爲此,研究者對機器學習研究領域中出現多年的多種分類器進行了實驗,這些模型包括廣泛使用的卷積網絡(VGG 和 ResNet [7,18])、近期出現的架構(ResneXt、PyramidNet、DenseNet [6,10,20])、已發佈的當前最優模型 Shake-Drop[21],以及從基於強化學習的超參數搜索而得到的模型 NASNet [23]。此外,他們還評估了基於隨機特徵的「淺層」方法 [2,16]。總體來說,原始 CIFAR-10 測試集上的準確率的範圍是 80% 到 97%。
對於所有深層架構,研究者都使用了之前在線發佈的代碼來實現(參見附錄 A 的列表)。爲了避免特定模型 repo 或框架帶來的偏差,研究者還評估了兩個廣泛使用的架構 VGG 和 ResNet(來自於在不同深度學習庫中實現的兩個不同來源)。研究者基於隨機特徵爲模型編寫實現。
主要的實驗結果見表 1 和圖 2 上,接下來將介紹結果中的兩個重要趨勢,然後在第 6 部分中討論結果。
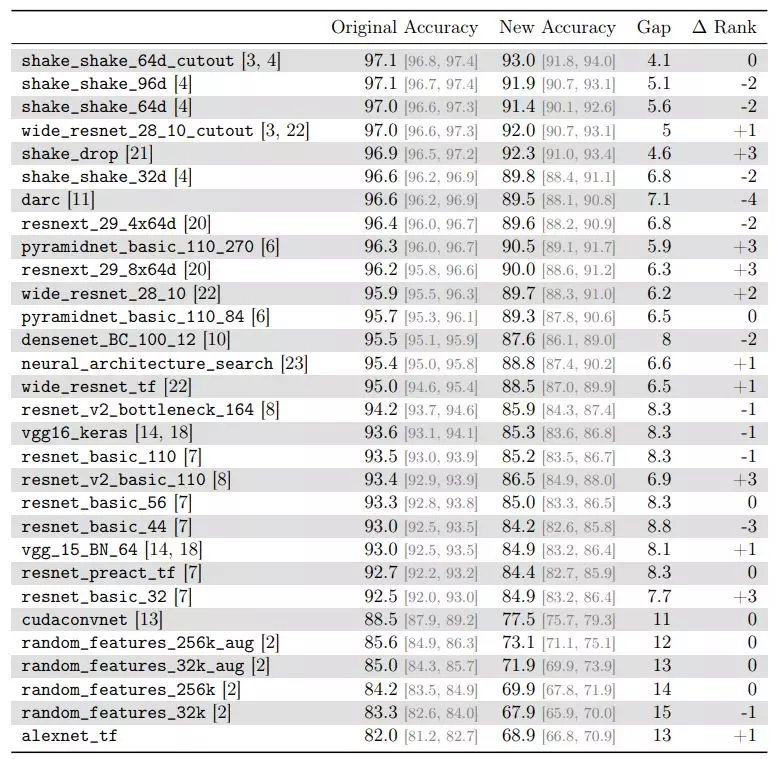 表 1:在原始 CIFAR-10 測試集和新測試集上的模型準確率,其中 Gap 表示兩個準確率之間的差距。∆ Rank 是從原始測試集到新測試集的排名的相對變化。例如,∆ Rank = −2 表示模型在新測試集中的準確率排名下降了兩位。
表 1:在原始 CIFAR-10 測試集和新測試集上的模型準確率,其中 Gap 表示兩個準確率之間的差距。∆ Rank 是從原始測試集到新測試集的排名的相對變化。例如,∆ Rank = −2 表示模型在新測試集中的準確率排名下降了兩位。
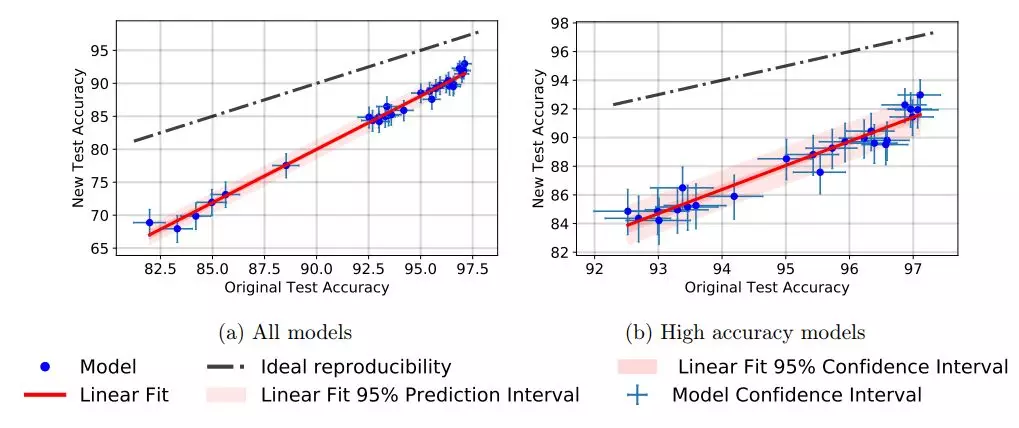 圖 2:新測試集上的模型準確率 vs 原始數據集上的模型準確率。
圖 2:新測試集上的模型準確率 vs 原始數據集上的模型準確率。
4.1 準確率顯著下降
所有模型在新測試集上的準確率都有顯著的下降。對於在原始測試集上表現較差的模型,這個差距更大;對於在原始測試集上表現較好的模型,這個差距較小。例如,VGG 和 ResNet 架構的原始準確率(約 93%)和新準確率(約 85%)的差距大約爲 8%。最佳準確率由 shake_shake_64d_cutout 得到,其準確率大致下降了 4%(從 97% 到 93%)。雖然準確率下降幅度存在變化,但沒有一個模型是例外。
關於相對誤差,擁有更高原始準確率的模型的誤差可能有更大的增長。某些模型例如 DARC、shake_shake_32d 和 resnext_29_4x64d 在誤差率上有 3 倍的增長。對於較簡單的模型例如 VGG、AlexNet 或 ResNet,相對誤差增長在 1.7 倍到 2.3 倍之間。參見附錄 C 中的全部相對誤差的表格。
4.2 相對順序變化不大
按照模型的新舊準確率順序對其進行分類時,總體排序結果差別不大。具有類似原始準確率的模型往往出現相似的性能下降。實際上,如圖 2 所示,從最小二乘法擬閤中派生出的線性函數可以對新舊準確率之間的關係做出很好的解釋。模型的新準確率大致由以下公式得出:
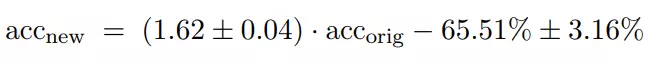
另一方面,值得注意的是一些技術在新測試集上有了持續的大幅提升。例如,將 Cutout 數據增強 [3] 添加到 shake_shake_64d 網絡,在原始測試集上準確率只增加了 0.12%,而在新測試集上準確率增加了大約 1.5%。同樣,在 wide_resnet_28_10 分類器中添加 Cutout,在原始測試集上準確度提高了約 1%,在新測試集上提高了 2.2%。在另一個例子裏,請注意,增加 ResNet 的寬度而不是深度可以爲在新測試集上的性能帶來更大的好處。
4.3 線性擬合模型
儘管圖 2 中觀察到的線性擬合排除了新測試集與原始測試集分佈相同的可能性,但新舊測試誤差之間的線性關係仍然非常顯著。對此有各種各樣的合理解釋。例如,假設原始測試集由兩個子集組成。在「easy」子集上,分類器達到了 a_0 的精度。「hard」子集的難度是κ倍,因爲這些例子的分類誤差是κ倍。因此,該子集的精度爲 1 − κ(1 − a_0)。如果這兩個子集的相對頻率是 p_1 和 p_2,可以得到以下總體準確率:
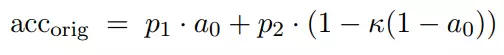
可以重寫爲 a_0 的簡單線性函數:
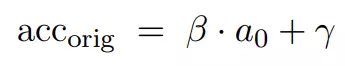
對於新的測試集,研究者也假設有由不同比例的兩個相同分量組成的混合分佈,相對頻率現在是 q_1 和 q_2。然後,可以將新測試集上的準確率寫爲:
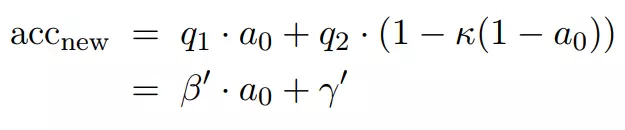
此處像之前一樣把項集合成一個簡單的線性函數。
現在很容易看出,新的準確率實際上是原始準確率的線性函數:
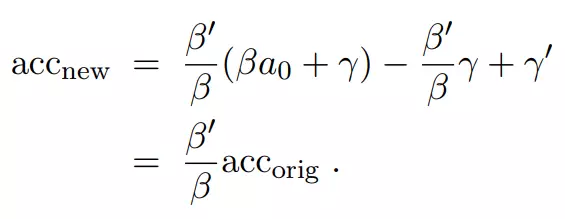
研究人員注意到,這種混合模型並不是一種真實的解釋,而是一個說明性的例子,說明原始和新的測試準確率之間的線性相關性是如何在數據集之間的小分佈移位下自然產生的。實際上,兩個測試集在不同的子集上具有不同準確率的更復雜的組成。儘管如此,該模型揭示了即使分類器的相對排序保持不變,分佈移位也可能存在令人驚訝的敏感性。研究人員希望這種對分佈偏移的敏感性能夠在之後的研究中得到實驗驗證。
5. 解釋差異
爲了解釋新舊準確率之間的巨大差距,研究人員探究了多種假設(詳見原文)。
統計誤差
近似重複移除的差異
超參數調整
檢測高難度圖像
在部分新測試集上進行訓練
交叉驗證
 表 2:交叉驗證拆分的模型準確率。
表 2:交叉驗證拆分的模型準確率。
6 討論
過擬合:實驗是否顯示出過擬合?這是解釋結果時的主要問題。簡單來說,首先定義過擬合的兩個概念:
訓練集過擬合。過擬合的一個概念是訓練準確率和測試準確率之間的差異。請注意,本研究的實驗中的深度神經網絡通常達到 100% 的訓練準確率。所以這個過擬合的概念已經出現在已有數據集上了。
測試集過擬合。過擬合的另一個概念是測試準確率和潛在數據分佈準確率之間的差距。通過使模型設計選擇適應測試集,他們擔心的是這將隱性地使模型適應測試集。測試準確率隨後失去了對真正未見過數據準確性進行測量的有效性。
由於機器學習的整體目標是泛化到未見過的數據,研究者認爲通過測試集適應性實現的第二種過擬合更重要。令人驚訝的是,他們的研究結果顯示在 CIFAR-10 並沒有這種過擬合的跡象。儘管在該數據集上具有多年的競爭適應性,但在真正的留出數據(held out data)上並沒有停滯不前。事實上,在新測試集中,性能最好的模型比更成熟的基線有更大的優勢。儘管這一趨勢與通過適應性實現過擬合所暗示的相反。雖然最終的結果需要進一步的複製實驗,但研究者認爲他們的結果支持基於競爭的方法來提高準確率。
研究者注意到 Blum 和 Hardt 的 Ladder 算法分析可以支持這一項聲明 [1]。事實上,他們表明向標準機器學習競賽中加入一些小修改就能避免這種程度的過擬合,即通過激進的適應性導致過擬合。他們的結果表明即使沒有這些修改,基於測試誤差的模型調優也不會在標準數據集上產生過擬合現象。
分佈轉移(distribution shift)。儘管研究者的結果並不支持基於適應性的過擬合假設,但仍需要解釋原始準確率和新準確率之間的顯著性差異。他們認爲這種差異是原始 CIFAR-10 數據集與新的測試集之間小的分佈轉移造成的。儘管研究者努力複製 CIFAR-10 數據集的創建過程,但它和原始數據集之間的差距還是很大,因此也就影響了所有模型。通常可以通過對數據生成過程中的特定變換(如光照條件的改變),或用對抗樣本進行攻擊來研究數據分佈的轉移。本研究的實驗更加溫和而沒有引起這些挑戰。儘管如此,所有模型的準確率都下降了 4-15%,對應的誤差率增大了 3 倍。這表明目前 CIFAR-10 分類器難以泛化到圖像數據的自然變化。
論文:Do CIFAR-10 Classifiers Generalize to CIFAR-10?

論文地址:https://arxiv.org/abs/1806.00451
摘要:目前大部分機器學習做的都是實驗性的工作,主要集中在一些關鍵任務的改進上。然而,性能最好的模型所具有的令人印象深刻的準確率令人懷疑,因爲多年來一直使用相同的測試集來選擇這些模型。爲了充分了解其中的過擬合風險,我們通過創建一組新的真正未見過的圖像來測量 CIFAR-10 分類器的準確率。儘管確保了新的測試集儘可能接近原始數據分佈,但我們發現,很多深度學習模型的準確率下降很大(4% 到 10%)。然而,具有較高原始準確率的較新模型顯示出較小的下降和較好的整體性能,這表明這種下降可能不是由基於適應能力的過擬合造成的。相反,我們認爲我們的結果表明了當前的準確率是脆弱的,並且容易受到數據分佈中微小自然變化的影響。