雷鋒網(公衆號:雷鋒網) AI 科技評論按:自然語言處理(NLP)一直是人工智能領域的重要話題,而人類語言的複雜性也給NLP佈下了重重困難等待解決。隨着深度學習(Deep Learning)的熱潮來臨,有許多新方法來到了NLP領域,給相關任務帶來了更多優秀成果,也給大家帶來了更多應用和想象的空間。
近期,雷鋒網 AI 研習社就邀請到了達觀數據的張健爲大家分享了一些NLP方面的知識和案例。
分享主題:達觀數據 NLP 技術的應用實踐和案例分析
分享人:張健,達觀數據聯合創始人,文本挖掘組總負責人,包括文本審覈系統的架構設計、開發和日常維護升級,文本挖掘功能開發。復旦大學計算機軟件與理論碩士,曾在盛大創新院負責相關推薦模塊,在盛大文學數據中心負責任務調度平臺系統和集羣維護管理,數據平臺維護管理和開發智能審覈系統。對大數據技術、機器學習算法有較深入的理解和實踐經驗。

此次分享中,張健按照NLP概述、文本分類的傳統方法、深度學習在文本分類中的應用和案例介紹四個板塊,結合在達觀數據的系統設計和應用經驗,分享了他的見解。
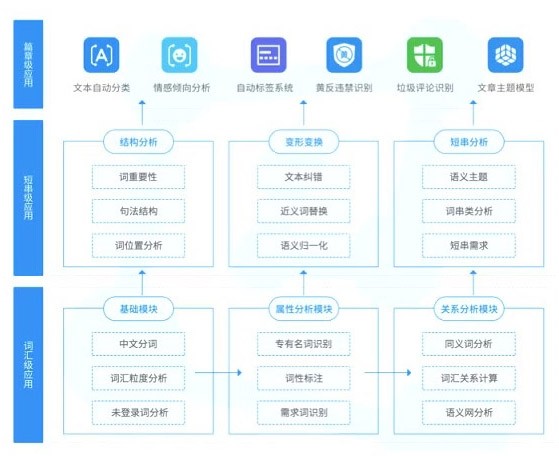
達觀數據是一家專注於文本挖掘和搜索推薦技術服務的企業,總部位於上海浦東軟件園。達觀的NLP挖掘系統的設計思路是,用戶直接接觸的到的最終功能,他們稱爲是篇章級應用,可以處理整段的文本,提供的功能包括文本自動分類、情感分析、自動文本標籤、違禁詞彙和垃圾評論識別等。在下方支持編章級應用的是短串級應用,更底層一些,在詞組、短句的層面上提供結構分析和變形、詞位置分析、近義詞替換等功能。最底層、最小粒度的是詞彙級應用,比如中文分詞、詞粒度分析、調性標柱等等。


文本挖掘的任務可以分成四類:
同步的序列到序列,特點是輸入文本的每一個位置都有對應的輸出
異步序列到序列,輸入和輸出可以不完全對應
序列到類別,給文本加上標籤
類別到序列,根據給定的標籤生成文本
然後張健依次介紹了序列到序列任務中幾種問題的常見解決方案。
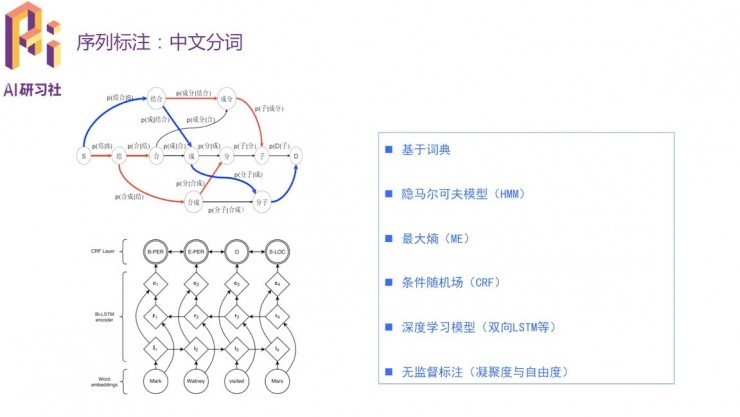
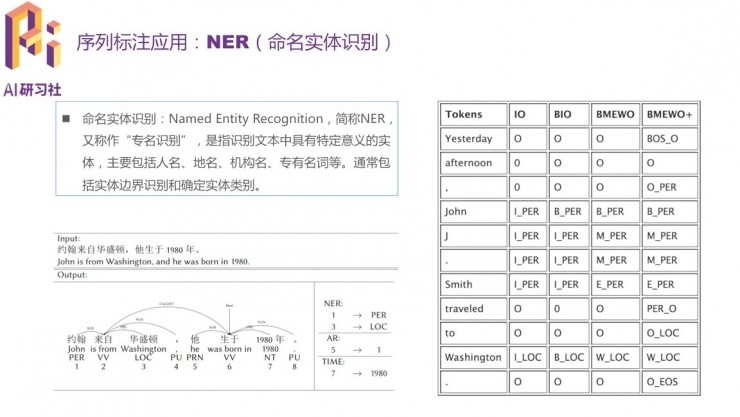
在序列標註/命名實體識別問題中,每個詞都會有各自的標籤;選用的詞彙標籤體系越複雜,標註精度就越高,但同時訓練也就越慢。所以需要根據人力、時間等成本選擇合適的標籤體系。

英文不需要分詞,但是多了詞形還原和詞根提取的問題。在這裏,張健推薦WordNet來幫助解決相關問題。


接下來進入了今天講解的重點,就是文本分類。

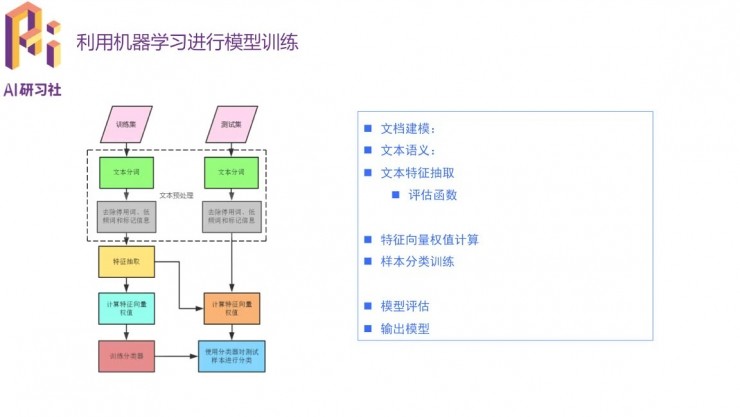
傳統機器學習方法做文本分類會需要文檔建模、文本語意、特徵抽取、特徵向量賦權等步驟。



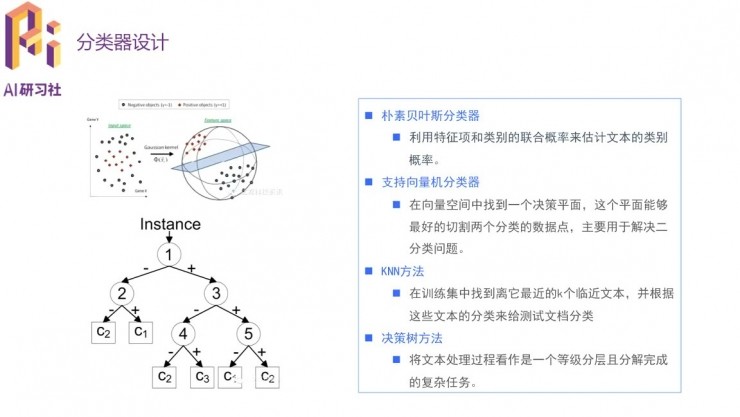
具體到分類器的設計,常用的四種思路爲樸素貝葉斯分類器、支持向量機分類器、KNN方法和決策樹方法。
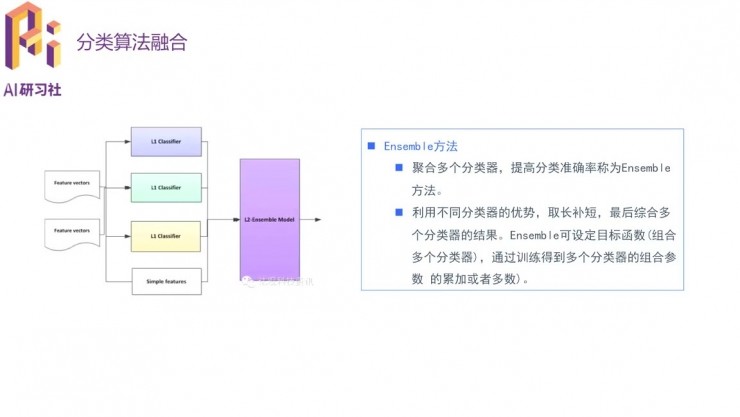
然後還可以聚合多個分類器來提高準確率。最簡單的想法是用多個模型分別預測然後投票,實際的聚合方法是另外訓練一個分類器,模仿多個分類器組合後的結果。這裏需要原來的幾個分類器效果不能太接近,而且不能有太差的。

在有了深度學習以後,文本分類又有了很多效果出色的新方法。
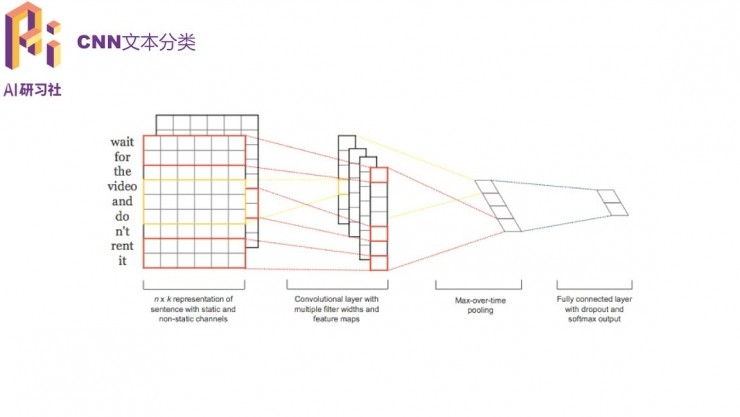
首先可以用CNN做文本分類,它不需要人工特徵,而對詞序包含的信息提取能力更強。
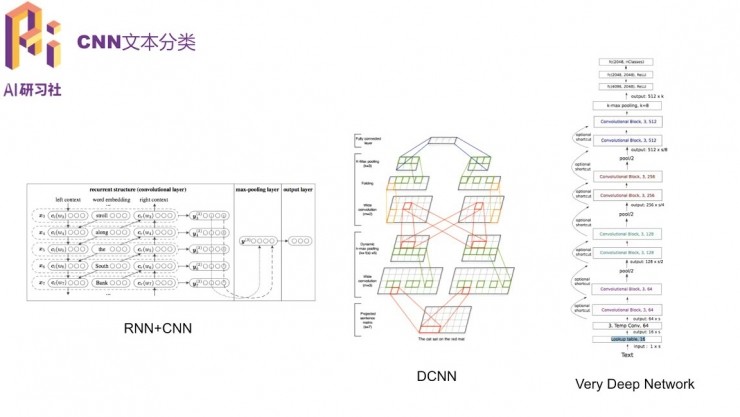
在基礎的CNN之上,可以在其中不同的層使用不同的思路,衍生出來RNN+CNN、DCNN(動態池化,更適合不同長度的文本)、Very Deep Network等等。
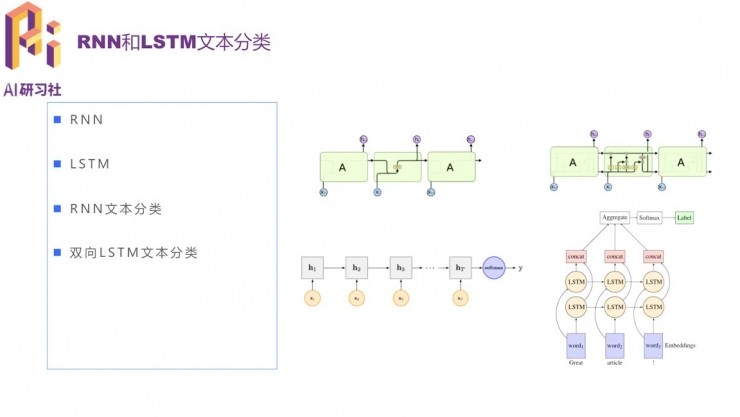
常用的方法還有RNN和LSTM,適合變長序列的建模。序列過長的時候,一般的RNN因爲容量的問題會丟失信息、誤差增大,它的變種LSTM中通過三個門之間的信息保留和更新,更好地解決了長距離依賴的問題。雙向LSTM同時有正向和反向的部分,可以同時捕獲上文和下文的信息,表現也比單向的更好。
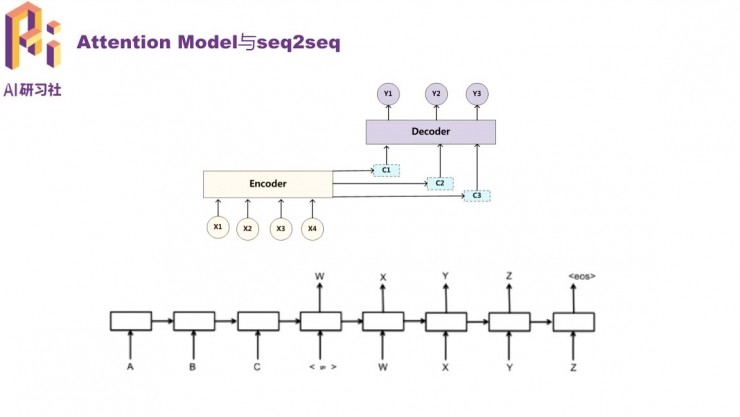
然後就是近期風靡的注意力模型,是編碼解碼器的升級版本。Encoder-Decoder模型的問題是,輸入中的每個詞都對輸出有同樣程度的影響。但實際語言中往往不是這樣的,注意力模型就可以對輸入中的不同詞賦予不同的權重,讓對語意影響程度更高的詞語對輸出有更高的影響力,從而在輸出中更好地體現了輸入的關鍵信息。

張健最後結合達觀數據的業務介紹了一些NLP的應用案例。

比如結合定製行業專業語料、垂直語意模型、離線統計、語意拓展等等方法進行新聞分類,結合無監督預訓練+持續Fune Tuning的訓練方法,不僅可以分爲新聞、財經、科技、體育、娛樂、汽車等大類,財經中股票、基金、外匯,體育中NBA、英超、中超等細分類別也可以分得出來。

第二個案例是垃圾信息識別。現在許多廣告信息都會用特殊字符(火星文)嘗試騙過識別系統,就需要對變形詞做識別還原,方法包括去除特殊符號、同音和繁簡變換、偏旁拆分等。還可以先用語言模型識別文字,發現語意不通順、胡言亂語的,就很有可能是故意規避關鍵字檢查的垃圾信息。
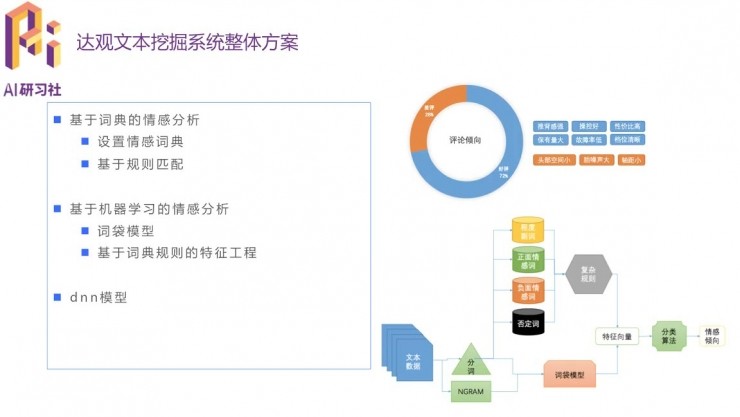
第三個案例是情感分析。簡單的方法可以根據直接表達感情的關鍵詞做判斷,還可以做特徵工程然後用機器學習的方法識別語句模式,以及用深度學習的方法得到更好的信息提取效果。

最後張健還分享了一個他們的文本挖掘系統的使用鏈接,感興趣的讀者可以嘗試一下他們系統不同層次的豐富功能。
本次分享的視頻錄像可以點此觀看
更多精彩分享請繼續關注雷鋒網!
