原標題Regular Expressions for Data Scientists,來源dataquest。
翻譯 | 汪其香 Noddleleslee 陳亞彬 趙朋飛 楊婉迪 校對 | 餘杭 整理 | 凡江
作爲數據科學家,快速處理海量數據是他們的必備技能。有時候,這包括大量的文本語料庫。例如,假設要找出在 Panama Papers 泄密事件中郵件的發送方和接收方,我們需要詳細篩查1150萬封文檔!我們可以手工完成上述任務,人工閱讀每一封郵件,讀取每一份最後發給我們的郵件,或者我們可以藉助Python的力量。畢竟,代碼存在的一個至關重要的理由就是自動處理任務。
儘管如此,從頭開始編寫腳本、寫腳本、抓取數據需要大量的時間和精力。這正是正則表達式的用武之地。RE,regex 和regular patterns 表達的意思皆是正則表達式,它形成一門簡潔的語言幫助我們快速地整理和分析文本。
正則出現在1956年,Stephen Cole Kleene 創建它用於描述人類神經系統的MP模型(McCulloch and Pitts model)的概念。1960年代,Ken Thompson 將這個概念添加到類似Windows記事本的文本編輯器中,自此正則開始壯大。
正則一個關鍵特性是節省腳本。我們可以視其爲代碼的捷徑。沒有它,我們不得不爲同樣目的敲大量的垃圾代碼。
本教程需要Python基礎知識。如果你理解if-else 表達式,while 語句和for 循環,列表和字典,本教程的大部分都可以搞定啦。此外你需要代碼編輯器,如Visual Studio Code,PyCharm 或Atom都可以。這樣當我們遍歷每一行代碼時就不會茫然,此外基礎的pandas庫也是必要的。如果你需要複習,可以跳轉到pandas的教程。
學完本教程,你會對正則的使用熟悉很多,可以使用re模塊的基礎模式和函數完成字符串分析。我們也學會如何高效地使用正則和pandas庫化大量紊亂的數據集爲有序。
現在,讓我們看看正則可以做些什麼。
數據集介紹
我們使用Kaggle的欺詐郵件文本語料庫。它包括1998到2007發出的上千封釣魚郵件。點擊此處可以下載數據集。在對整個語料庫操作之前,讓我們先學習在一封郵件應用正則表達。
Python正則表達式模塊的介紹
首先打開文本文件讀取數據,設置爲只讀模式,並讀取數據集,最後將上述操作結果賦給變量 fh(「file handle」 即文件句柄)。

請注意我們在設置目錄路徑之前添加r。它將轉換字符串爲原始字符串,避免機器讀取字符時候引起衝突,例如Windows的目錄路徑中的反斜槓。
你也許注意到我們現在並沒有使用整個語料庫。相反地,我們先人工挑選語料庫的相對靠前的一些郵件作爲測試文件。本教程不打算每次都展示上千行的結果,每次都打印其中的一部分作爲測試。這可能會讓人感到惱怒。你可以使用整個語料庫,也可以使用我們的測試文件。無論哪種方式,都能很好得獲得學習經驗。
現在,假設我們現在想知道郵件的來源。我們可以在自己的Python嘗試如下代碼:

或者,我們可以使用正則表達式:

我們來遍歷這段代碼。首先導入 re 模塊。然後敲出圖示餘下代代碼。這個例子中,這比原來的Python 代碼僅少 1 行 。然而隨着腳本行數的快速增長,正則表達式可以節省腳本的代碼量。
re.findall() 以列表形式返回字符串中符合模式的所有實例。它是Python內置 re 模塊中最經常使用的函數。讓我們來剖析 re.findall。re.findall(pattern, string)接受兩個參數。pattern表示我們想要搜索的子字符串,string 表示我們想要搜索的主字符串。主字符串可以由多行組成。
.* 是字符串模式的簡寫。我們很快就會解釋它的細節。現在它們與From: 域中的名稱和電子郵件地址相匹配。
在讓我們更深一步探索之前,先瀏覽一下常用的正則表達式。
常用的正則表達式
我們之前用到的re.findall() 包含"From:"的字符串。這個函數當我們明確知道搜索目標時候十分有用,甚至包括明確字母拼寫和是否大小寫。如果我們不明確知道搜索目標時,該函數就會失效。幸運的是正則表達有解決這個問題的基本模式。讓我們看一些這篇文章將用到的:
\w 匹配字母數字字符,即a-z,A-Z,0-9。它也匹配下劃線和波折號。
\d 即0-9。
\s matches 匹配空白格,包括製表符、換行字符、回車符和空格字符。
\S 匹配非空白格字符。
. 匹配除換行字符\n外的任意字符串。
有這些正則表達式的說明在手,你就可以在我們解釋上述代碼時能夠快速地理解。
使用正則表達式
現在我們來解釋re.findall("From:.*", text) 中.* 的作用。首先看. :

From:後面添加. ,表示尋找它旁邊的字符,因爲.查找 \n外的任何字符,它也會捕捉肉眼不可見的空格。我們可以添加更多的點來驗證。

看起來添加很多點可以獲得行中我們想要的剩餘部分。但這是冗餘的而且我們不知道要敲多少個點。這就是很有用的*的由來。
* 匹配其左側表達式的0個或多個模式的實例。這意味它尋找重複模式。當我們尋找重複模式時,稱爲貪婪搜索。否則,我們稱之爲非貪婪搜索或懶惰搜索。
讓我們用* 構建一個對 . 的貪婪搜索。

因爲 * 匹配其左側 0 個或多個模式類的實例,而 . 在其左側,因此我們可以獲得From: 到行末的所有字符。這種漂亮高效的方式可以輸出完整的行。
我們甚至可以更進一步,只分離出名字:

我們使用re.findall() 返回包含"From:.*" 模式的列表,就像我們以前做的那樣。爲了簡潔起見 我們給match 變量賦以上述操作的結果。接下來,我們迭代列表。每一次循環,我們都再次執行re.findall 。這一次,這個函數從第一個引號開始匹配。
請注意我們在第一個引號旁使用反斜槓。反斜槓是用於轉義其他特殊字符的特殊字符。例如,當我們想使用引號作爲字符串而不是特殊字符時,我們用反斜槓來表示轉義:\"。如果不使用反斜槓表示轉義,就是"".*"",Python解釋器視作兩個空字符串之間讀取一個句點和一個星號。這就會出現錯誤,腳本不能運行。因此,關鍵是使用反斜槓表示轉義。
在第一個引號匹配之後,.* 獲取行中直到下一個轉義的引號的所有字符。獲取引號內的名字。每個名字都在方括號內打印出,因爲re.findall 以列表形式返回匹配內容。如果我們需要獲取電子郵件地址呢?

看起來很簡單不是嘛?只是匹配模式有些許不同,讓我們逐一攻破。
以下是如何匹配電子郵件地址的前面部分:

電子郵件總是包含@符號,讓我們從它開始。電子郵件@符號之前的部分可能包含字母數字字符,\w 就派上用場。然而,因爲一些郵件包含句點或破折號,這是不夠的。我們用\S 來查找非空白字符。但\w\S 僅僅找到兩個字符。添加 * 重複尋找過程。因此模式前半部分是:\w\S*@。
現在來看看@符號後半部分的模式:

域名通常包含字母數字字符、句點和破折號。這很簡單,一個 . 就能搞定。爲了使用貪婪模式,我們用*來擴展搜索。這使我們可以匹配直到行結束的任何字符。
如果我們仔細觀察這行,我們會發現每個電子郵件都封裝在尖括號內,<和>。 我們的模式.*包括閉合的尖括號。讓我們糾正一下:

電子郵件地址以字母數字字符結束,所以我們用\w模式覆蓋。因此@ 符號後面是.*\w,這意味着我們想要的模式是一組以字母數字字符結尾的字符。這不包括>。
完整電子郵件地址模式是:\w\S*@.*\w。
這是相當多的工作。熟練使用正則表達式需要一段時間,但是一旦您掌握它的模式,您就能夠更快地爲字符串分析編寫代碼。接下來,我們將運行一些re 模塊常見函數,當我們開始重新整理語料庫時它們將非常有用。
常見的正則表達式函數
re.findall() 無疑是有用的,re 模塊提供了更多同樣便捷的函數。
包括:
re.search()
re.split()
re.sub()
在使用它們把雜亂無序的語料庫變爲有序之前,我們對它們逐一分析。
re.search()
re.findall() 以列表形式返回匹配字符串中滿足模式的所有實例,re.search() 匹配字符串中模式的第一個實例,並將其作爲一個re 模塊的匹配對象。

和 re.findall() 類似, re.search() 也接受兩個參數。第一個參數是匹配的模式,第二個參數是要搜索的字符串範圍。這裏爲了簡潔起見,我們已經將結果賦值給match 變量。
因爲 re.search() 返回一個re 模塊的匹配對象,我們不能直接打印出對應的名字和電子郵件地址。 相反,我們必須先採用 group()這個函數. 我們已經在上面的代碼中打印了它們類型,可以看出group() 將匹配對象轉化成一個字符串。
我們也可以看到打印match 時顯示的是對應的屬性而不是字符串本身, 而打印 match.group() 只顯示字符串。
re.split()
假設我們需要一種快速的方法來獲取電子郵件地址的域名。我們可以用三次正則操作,像這樣:

第一行用法前面已經提到了。我們返回一個字符串列表,每個字符串包含From: 字段的內容,並將其賦給變量。接下來的通過遍歷這個列表來查找郵件的地址。同時通過迭代電子郵件地址和使用 re 模塊的split() 函數來把每一個地址剪成兩半,用 @作爲分隔符。最後再打印出來。
re.sub()
另一個方便的 re 函數是 re.sub()。正如函數名所示,它用來替換字符串的各個部分。舉個例子:

前兩行已經在前面出現過了。
在第三行我們將 address 作爲 re.sub() 函數的第三個參數,即郵件標題中完整的From: 字段。
re.sub() 需要三個參數。第一個是被代替的子字符串,第二是想要放在目標位置的字符串,而第三是主字符串。
pandas 中的正則表達式
現在我們有了正則表達式的一些基礎知識,我們可以嘗試一些更復雜的。然而,我們需要正則表達式跟pandas Python數據分析庫結合。Pandas 庫中有一個很有用的把數據組織成整齊表格的對象,即 DataFrame 對象,也可以從不同的角度理解它。結合正則表達式的代碼,它就像用一個特別鋒利的刀雕刻軟黃油。
不用擔心從來沒用過 Pandas。我們會通過代碼一步一步進行,這樣你就不會感到困惑。正如我們在引言中提到的,如果你想詳細學習,請訪問Pandas tutotial。
我們可以通過 Anaconda 或者 pip 來下載 pandas 庫。 詳情請查看安裝指南。
用正則表達式和Pandas分揀郵件
Corpus 是一個包含數千封電子郵件的文本文件。我們將使用正則表達式和Pandas 來將每封電子郵件適當分類 使Corpus 語料庫更便於閱讀和分析。我們會將每封郵件分爲以下幾個類別之一:
sender_name
sender_address
recipient_address
recipient_name
date_sent
subject
email_body
每個類別將成爲我們Pandas數據幀或表格中的一列。這非常有用,因爲我們可以自行處理每一列。例如,我們可以直接編寫來找出電子郵件來自哪個域名,而不需要首先編碼來將電子郵件地址與其他部分隔離開來。基本上,對數據集先分類可以讓我們編寫更簡潔的代碼。反過來,簡潔的代碼減少了機器所需的操作數量,這加快了我們的處理速度,特別是在處理大量數據集時。
準備Script
我們從上面一個簡單的腳本開始。從頭開始以便弄清楚它們內部運行的原理。
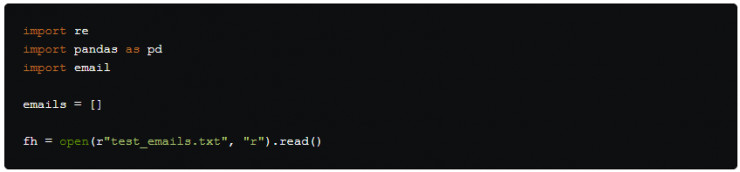
在代碼的一開始首先導入 re 和pandas 模塊,我們導入的Python email 包對於郵件正文很重要,如果僅僅使用正則表達式來處理電子郵件的正文會相當複雜,可能需要足夠的清理不必要信息方面的工作才能保證它能正常運行。
email 包。然後我們創建一個空的列表emails 用來存放包含每個電子郵件詳細信息的字典。
我們經常將代碼的結果打印到屏幕上來判斷代碼是對還是錯。然而,由於數據集中有成千上萬的電子郵件,打印出上千行到屏幕上會佔據本教程頁面。我們當然不想讓你一遍又一遍地滾動成千上萬行的結果。因此,正如我們在本教程開始時所做的,我們打開並閱讀了Corpus的較短版本。爲了本次教程我們手工編寫一點。你可以使用實際的數據集。
每次運行 print() 函數,你只需幾秒鐘就可以把幾千行打印到屏幕上。
現在我們開始使用正則化表達式。

我們用 re 模塊的 split 函數將 fh 中整個文本塊拆分爲一個單獨的電子郵件列表,分配給 contents。這很重要,因爲我們希望通過循環遍歷列表來一個個地處理電子郵件。但是我們怎麼知道用 "From r"來分割呢?我們之所以知道這一點,是因爲在編寫腳本之前查看了文件。我們沒有必要仔細閱讀數千電子郵件。只需要通過前幾行來大致看看數據的結構是什麼樣子的。正因爲如此,每個電子郵件前面都是字符串 "From r"。我們已經截圖了文本文件的樣子:
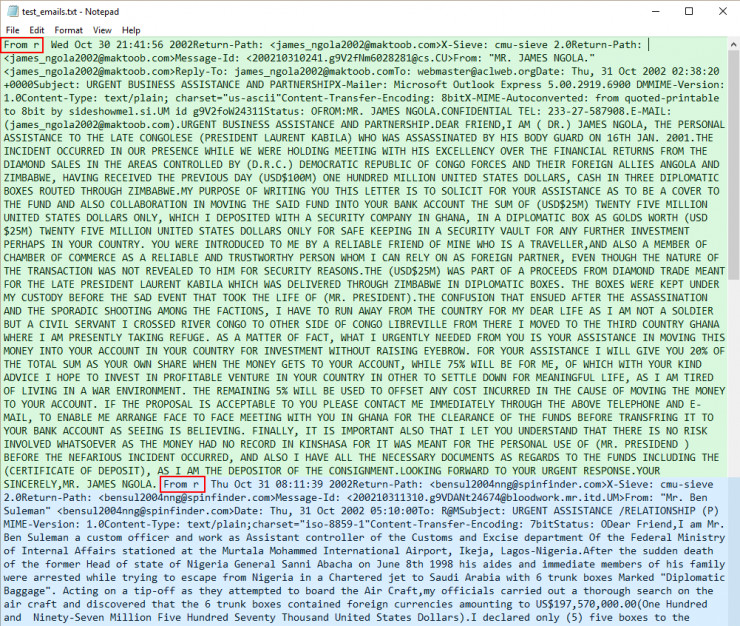
郵件用 「From r」開頭
綠色部分是第一個電子郵件。藍色部分是第二個電子郵件。我們可以看到,這兩個電子郵件都是以 "From r"開頭,用紅色的框來顯示。
我們在這個教程中之所以使用 Fraudulent Email Corpus是爲了表明當數據是無序的和不熟悉的時候,我們不能只依靠代碼來處理,它需要一雙眼睛。就像剛剛展示的那樣,我們需要查看 Corpus 來研究它的結構。另外 這樣的數據可能還需要再處理 ,這個 Corpus 語料庫也是同理。舉個例子,即使我們用本教程的完整腳本算出本數據集包含3977 封郵件,實際上更多。有些郵件的開頭沒有 "From r"字段所以沒有被拆分成單獨的郵件。但是我們保留了這個結果以免它無窮無盡。
注意我們也用了 contents.pop(0)去掉列表中的第一個元素。那是在第一封電子郵件的前面有"From r" 字符串。當這個字段被分割的時候,在索引0的位置生成了一個空字符串。我們即將編寫的腳本是爲電子郵件而設計的。如果出現空字符串它可能會報錯。去掉空字符串可以讓我們避免這些錯誤打斷腳本的運行。
以循環方式獲取每個名稱和地址
接下來我們在電子郵件的 contents 列表中工作。

上面的代碼中用 for 循環去遍歷 contents 這樣我們就可以一個一個處理每封郵件。我們創建一個字典, emails_dict,這將保存每個電子郵件的所有細節,如發件人的地址和姓名。事實上,這些是我們要尋找的第一項信息。
這個過程總共有 3 步,首先是找到 From: 字段
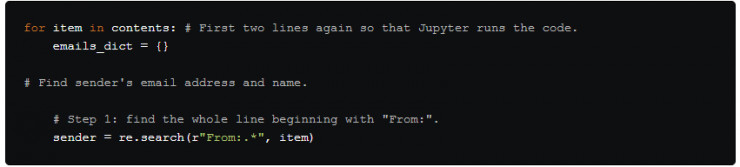
第一步,我們通過 re.search() 函數找到完整的 From: 字段。 句點 . 表示除了\n之外的任何字符 ,* 延伸到該行的結尾處。然後將它賦給變量 sender.
但是,數據並不總是直截了當的。常常會有意想不到的情況出現。例如,如果沒有 From: 字段怎麼辦?腳本將報錯並中斷。在步驟2中可以避免這種情況。
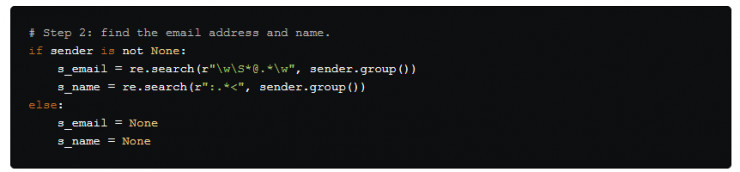
爲了避免由 From: 域導致的錯誤,我們要用一個 if 來檢查 sender 是不是 None。如果是一個空字段的話,用 s_email 和 s_name 的值來取代 None ,這樣腳本就可以繼續運行而不是意外中斷。
雖然這個教程讓使用正則表達式看起來很簡單(Pandas在下面)但是也要求你有一定實際經驗。例如,我們知道使用if-else語句來檢查數據是否存在。事實上,之所以我們知道如何處理,是因爲我們在寫這個腳本時反覆地嘗試過。編寫代碼是一個迭代過程。值得注意的是,即使教程看起來是線性的,即使教程看起來是直截了當的,但實踐中需要更多的嘗試。
第二步中使用了一個之前熟悉的正則表達式 \w\S*@.*\w, 用來 匹配實際的郵件地址格式。
我們用不同的規則來命名,每一個名字的左邊都用 "From:" 字段中的:來分割,電子郵件的右邊用開括號 <。因此可以用 :.*< 形式來找郵件名稱。 我們從每個結果中快速的去掉 : 和 <
現在,讓我們打印出代碼的結果來看看。

注意我們沒有使用 sender 變量在 re.search()函數中作爲搜索字符串。我們已經打印了 sender 和 sender.group() 的類型,這樣就能看到區別。看起來 sender 是一個 re 的匹配對象,並且不能用re.search()來搜索。然而sender.group() 是一個字符串,而 re.search 接受的參數即是字符串形式。
我們來看看 s_email 和 s_name 長什麼樣子。

同樣,我們得到了匹配的對象。每次對字符串進行re.search() 操作, 都會生成匹配對象, 我們必須將其轉換爲字符串對象。
在轉換之前,回想一下如果沒有From: 字段,,sender 的值將會是None,那麼 s_email和s_name 的值也將爲None。因此,我們必須再次進行檢查,以便腳本不會意外中斷。先看看如何針對s_email 構造代碼。
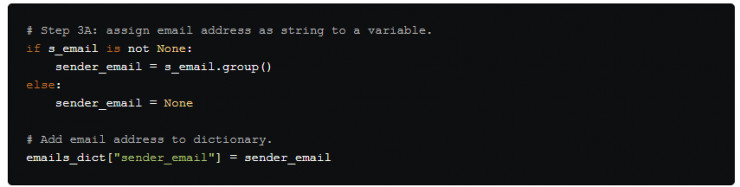
在步驟3A中,我們使用了if 語句來檢查s_email的值是否爲 None, 否則將拋出錯誤並中斷腳本。
然後,我們只需將s_email 匹配的對象轉換爲字符串並將其分配給變量sender_email 即可。將轉換完的字符串添加到 emails_dict 字典中,以便後續能極其方便地轉換爲pandas數據結構。
在步驟3B中,我們對 s_name 進行幾乎一致的操作.
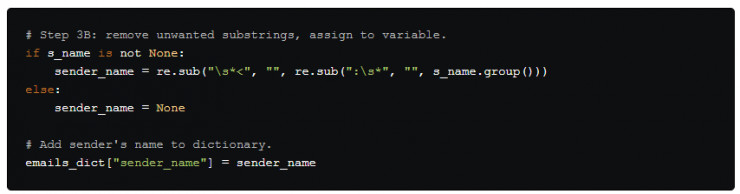
就像之前做的一樣,我們在步驟3B中首先檢查s_name 的值是否爲None 。
然後,在將字符串分配給變量前,我們調用兩次了 re 模塊中的re.sub() 函數。首先,通過用空字符「」代替:\s* ,刪除冒號及冒號與姓名之間的任何空格字符。然後刪除姓名另一側的空格字符和角括號,再次使用空字符進行替換。最終,將字符串分配給 sender_name並添加到字典中。
讓我們檢查下結果。

非常棒!我們已經分離了郵箱地址和發件人姓名, 還將它們都添加到了字典中,接下來很快就能用上。
既然我們已經得到了發件人的郵箱地址和姓名,通過同樣的步驟就能獲得收件人的郵箱地址和姓名並保存到字典中去。
首先,我們找到To: 字段。

接下來,我們將先發制人,避免recipient 爲None的情況發生。
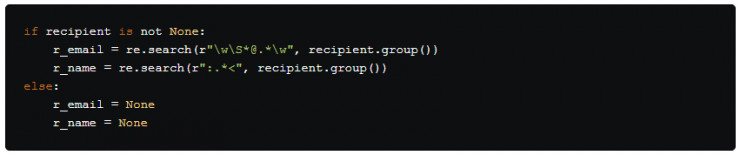
如果 recipient 不爲 None, 使用 re.search() 來查找包含發件人郵箱地址和姓名的匹配對象,否則,我們將傳遞None值給 r_email 和 r_name 。
然後我們將匹配對象轉換爲字符串並添加至字典中去。
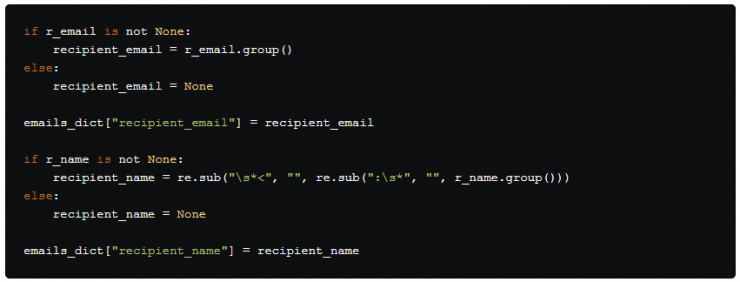
因爲From: 和 To: 字段具有相同的結構,因此我們可以對兩者使用相同的代碼,但對其他字段來說,我們需要定製稍微不同的代碼。
獲取郵件的日期
現在讓我們來獲取郵件的發送日期。

我們獲取的Date:字段的代碼與From:及To:字段的代碼相同。就像保證這兩個字段的值不是None一樣,我們同樣要檢查被賦值到變量date_field的值是否爲 None。
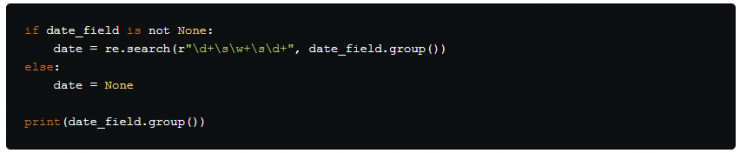
我們已經輸出 date_field.group(),因此可以更清楚地看到這一字符串的結構,它包含了郵件發送當天的具體日期並以「日-月-年」 的格式呈現,同時還包含了時間,但我們只想知道日期。 得到日期的代碼與得到姓名和郵件地址的代碼非常相似,但更簡單一些,可能這兒唯一的疑惑點是正則表達式:\d+\s\w+\s\d+。
日期是以數字開始的,因此我們可以用 \d 來解析它,就像日期格式中具體天數部分一樣,它可能是由一位或者兩位數字組成,所以在此+ 就變得非常重要了。在正則表達式裏, 在+ 的左側來匹配一個或多個模式實例。用\d+ 來匹配可以不用考慮日期的具體天數是一位還是兩位數字。
之後的一個空格可以通過尋找空白字符的 \s 來解析。月份是由三個字母組成的,因此使用\w+ 來解析,再接另一個空格,所以繼續用 \s 解析。因爲年份是由多個數字組成,所以我們需要再用一次\d+ 。
表達式 \d+\s\w+\s\d+之所以能起作用,是因爲精確的模式匹配約束着空格之間的內容。
接下來,我們做和之前相同的 None 值檢查。
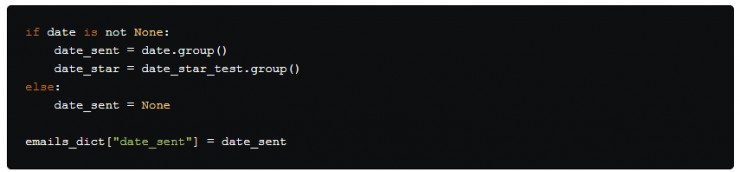
如果 date 不爲 None ,我們就把它從這個匹配對象轉換成一個字符串,然後賦值給變量 date_sent,再將其鍵值添加到字典中。
進行下一步前,我們應特別注意的是+ 和 * 看起來很相似,但是它們差異很大。用日期字符串來舉例:
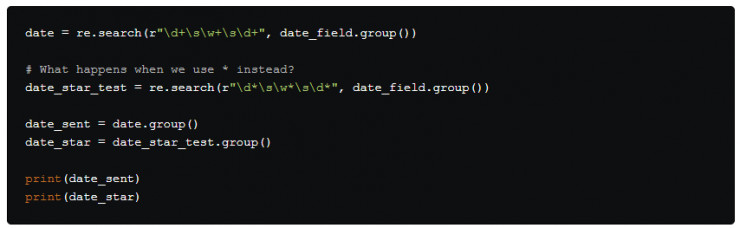
如果使用 * 我們將匹配到大於等於零個的結果,而 + 匹配大於等於一個的結果。參照以上示例,我們輸出了兩種不同的結果,它們之間存在非常大的差異。正如所見, + 可以解析出整個日期而*只解析出一個空格和數字1。
接下來講解郵件的標題。
獲得郵件的標題
我們可以像之前一樣,用相同的代碼架構來獲取我們需要的信息。
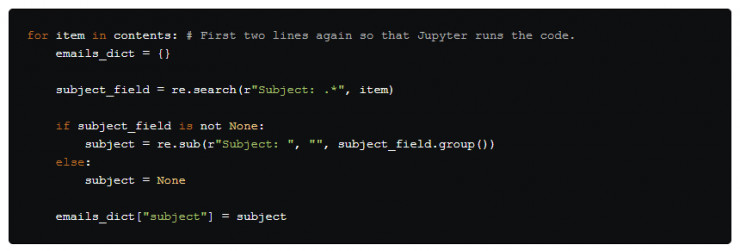
現在我們對正則表達式的格式已經很熟悉了對吧?這個代碼與之前的類似,爲獲得標題,我們可以用一個空的字符串來代替"Subject: " 。
獲取郵件的內容
最後要添加到字典裏的一項就是郵件的內容了。

將標題從郵件內容中分離出來是非常複雜的任務,尤其當文中有很多不同形式的標題。在原始混亂的數據中是很難找到一致性的規律,但是幸運的是這個工作有人幫我們解決了——Python的email 模塊包非常適用這項任務。
我們之前已經導入了email模塊. 現在,我們將 message_from_string()方法應用於item, 將整個email轉換成 email消息對象. 一個消息對象由消息頭和消息體組成, 分別對應於email的頭部和主體.
接下來, 我們對email消息對象使用 get_payload()方法. 提取email內容. 並將內容傳遞給變量 body, 稍後我們會將其存儲在字典 emails_dict 的鍵 "email_body"下.
在處理郵件正文時爲什麼選擇email包而非正則表達式
你可能會疑惑, 爲什麼使用 email 包而不是正則表達式呢? 因爲在不需要大量的清理工作時,正則表達式並不是最好的方法。我們需要爲這段代碼做詳細解釋。
我們值得探討爲何會作出這個選擇。但在開始之前,我們需要先理解方括號[ ] 在正則表達式中的含義, .
[ ] 用於匹配所有被它括起來的內容. 比如, 如果需要在字符串中查找 "a", "b", 或 "c" , 可以使用 [abc] 作爲模式. 上文提到過的模式也適用。[\w\s] 用於查找字母、數字或空格。不同之處在於,它匹配的是方括號中的文字部分。
現在,可以更好的理解我們爲何會決定選擇email模塊了。
仔細留意下數據就會發現email頭部採用字符串 "Status: 0" 或 "Status: R0"作爲結束,並在下一封郵件的 From r 字符串前結束,我們可以使用 Status:\s*\w*\n*[\s\S]*From\sr* 來獲取email內容. [\s\S]* 用來查找空格或非空格字符,所以用於大段的文本、數字,以及標點符號。
不幸的是一封 email 不止一個「Status: 」 字符串,也並不一定都包含 "From r",即郵件拆分之後的數目可能會比郵件列表的字典數目多 也可能會比它少 ,但它們不會和已有的其他類別相匹配。如果使用 pandas 包來解決這個問題的話 會遇到問題 ,因此,我們選擇使用 email 包。
創建字典列表
最後,添加字典emails_dict到 emails 列表:

此時可以打印emails列表。執行 print(len(emails_dict)) 函數,查看列表中有多少字典和email 。如前述,全部語料庫包含 3977個email。我們的小型測試文件中只有7個。全部代碼如下:
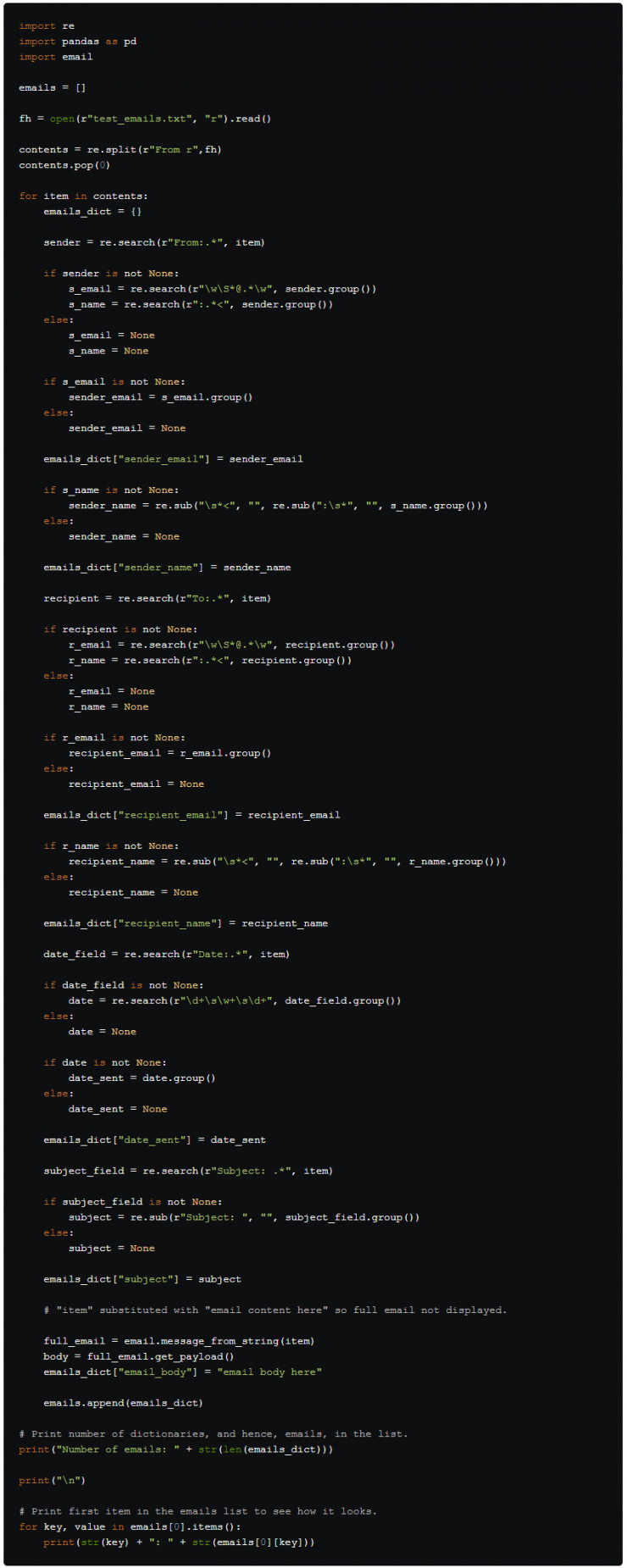
我們已經打印出了emails 列表的第一項, 它是由鍵和鍵值對組成的字典. 由於使用了 for 循環,因此每個字典擁有相同的鍵,但鍵值不同。
我們爲每個 item 賦值 "email content here" ,所以不需要打印所有的email來佔據電腦屏幕. 如果你在家應用時打印email,你將會看到實際的email內容。
使用pandas處理數據
如果使用 pandas 庫處理列表中的字典 那將非常簡單。每個鍵會變成列名, 而鍵值變成行的內容。
我們需要做的就是使用如下代碼:

通過上面這行代碼,使用pandas的DataFrame() 函數,我們將字典組成的 emails 轉換成數據幀,並賦給變量emails_df.
就這麼簡單。我們已經擁有了一個精緻的Pandas數據幀,實際上它是一個簡潔的表格,包含了從email中提取的所有信息。
請看下數據幀的前幾行:

The dataframe.head() 函數顯示了數據序列的前幾行。該函數接受1個參數。一個可選的參數用於定義需要顯示的行數, n=3 表示前3行。
也可以精確地查找。例如,查找從特定域名發來的郵件。但是,我們需要先學習一種新的正則表達式來完成精確查詢工作。
管道符號, |, 用於查找位於它兩邊的任意字符。 如, a|b查找 a 或 b。
| 有點類似 [ ], 但二者有區別。假設我們需要查找"crab", "lobster", 或 "isopod"。 使用 crab|lobster|isopod 會比 [crablobsterisopod] 更精確,前者會匹配完整單詞,而後者只匹配單個字符。
現在我們可以使用 | 符號查找從特定域名發送來的email。

這裏我們使用了一行超長的代碼。由內及外剖析它。
emails_df['sender_email'] 選擇了標記爲 sender_email的列,接下來,如果在該列中匹配到 子字符串 "maktoob" 或 "spinfinder" ,則str.contains(maktoob|spinfinder) 返回 True . 最後, 最外面的emails_df[] 返回 sender_email 列視圖,該列包含需要匹配的目標字符串。乾的漂亮!
我們也可以單個檢視郵件。 只需要以下4步。 第1步,查找包含字符串"@maktoob"的列 "sender_email" 對應的行索引。請留意我們是如何使用正則表達式來完成這項任務的。

第2步,使用索引查找email地址, loc[] 方法返回一系列不同屬性的對象. 並將其打印出來,以便查看。

第3步,從這一系列對象中提取email地址,並羅列出來,現在你會發現他的類型是now類。

第4步將展示提取到的email正文

在第四步中 emails_df['sender_email'] == "james_ngola2002@maktoob.com" 是用來查找包含 "james_ngola2002@maktoob.com" 的郵件發送者列,接下來 ['email_body'].values 用來查找郵件正文的相同行的列值,最後輸出該列值。
如你所見,我們可以多種方式應用正則表達式,正則表達式也能與pandas完美配合。
其他資源
自從應用範圍從生物學擴展到工程領域,過去這些年正則表達式發展速度驚人 。今天,正則表達式已可在多種變成語言中應用,除基本模式外,有適當變化。在這份教程中,我們使用Python練習使用正則表達式,但如果你喜歡,也可以使用 Stack Overflow 發掘它的其他特點。維基百科用一張表格比較了不同正則表達式引擎的特點。
正則表達式還有很多特性本教程不能一一列舉,完整的文檔可以參考Python文檔中的 re 模塊. 谷歌也有一份快速參考手冊。
如果需要一系列數據進行實驗的話, Kaggle 和 StatsModels 將對你有所幫助。
這裏是正則表達式的速查表,但對大多數來說也是有幫助的。
如果這篇教程對你有用的話,你也會喜歡Dataquest的正則表達式課程。
原文鏈接:https://www.dataquest.io/blog/regular-expressions-data-scientists/