ACL 2018 獲獎名單如下:
最佳長論文
1. Finding syntax in human encephalography with beam search(尚未公開)
作者:John Hale、Chris Dyer、Adhiguna Kuncoro、Jonathan Brennan
2. Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information
作者:Sudha Rao、Hal Daumé III 均來自於馬里蘭大學帕克分校。
3. Let’s do it 「again」: A First Computational Approach to Detecting Adverbial Presupposition Triggers
作者:Andre Cianflone、Yulan Feng、Jad Kabbara、Jackie Chi Kit Cheung,來自於麥吉爾大學和 MILA。
最佳短論文
1. Know What You Don’t Know: Unanswerable Questions for SQuAD.(尚未公開)
作者:Pranav Rajpurkar、Robin Jia、Percy Liang
目前,該論文尚未公開,但三位研究員都來自斯坦福大學。
2. ‘Lighter’ Can Still Be Dark: Modeling Comparative Color Descriptions.(尚未公開)
作者:Olivia Winn、Smaranda Muresan
該獲獎論文的兩位作者來自於哥倫比亞大學。
在本文中,機器之心對兩篇已公開的獲獎論文進行了編譯介紹,感興趣的同學可以查看原論文:
論文 1: Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information

論文地址:https://arxiv.org/abs/1805.04655
摘要:詢問對於交流而言是很基礎的,然而機器無法與人類進行高效協作,除非它們可以學會問問題。在這項研究中,我們爲給澄清性(clarification)提問排序的任務構建了一個神經網絡模型。該模型受完美信息期望值的思想啓發:一個問題好不好在於其期望的回答是否有用。我們使用了來自 StackExchange 的數據來研究這個問題,StackExchange 是一個豐富的在線資源,人們通常在帖子中詢問澄清性問題,從而他們可以更好地爲帖子樓主提供幫助。我們創建了一個由大約 77000 個澄清性問題帖子構成的數據集,其中每個帖子包含一個問答對,這些帖子來自 StackExchange 的三個領域:askubuntu、unix 和 superuser。我們在該數據集的 500 個樣本上通過和人類專家判斷對比對我們的模型進行了評估,並在受控基線上實現了顯著的提高。
提問的核心目標是填補信息鴻溝,該過程通常通過澄清性問題進行。我們認同好的問題是其答案最可能有用的問題。考慮到圖 1 中的信息交流,其中樓主(我們叫他 Terry)就配置環境變量提問。這個帖子不夠細化,一個回覆者(Parker)問了一個澄清性問題(如下 a),不過也可以問問題(b)或(c)。
(a)你使用的是哪個版本的 Ubuntu?
(b)你的無線網卡型號是什麼?
(c)你是在 x86 64 架構上運行 Ubuntu 14.10 kernel 4.4.0-59- generic 嗎?
Parker 不應該問(b)因爲答案可能沒什麼用;也不應該問(c)因爲這個問題太具體了,「No」或「I do not know」這樣的答案也沒什麼用處。Parker 的問題(a)就好多了:答案有用的可能性高,且對於 Terry 來說是可以回答的。
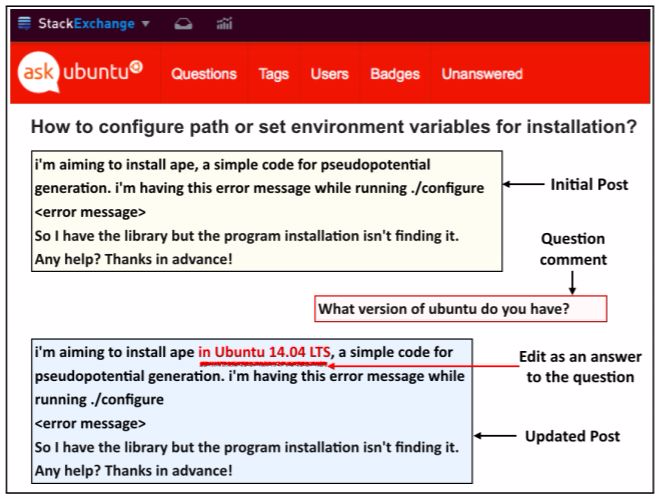
圖 1:更新在線問答論壇「askubuntu.com」上的帖子來補充評論中缺失的信息。
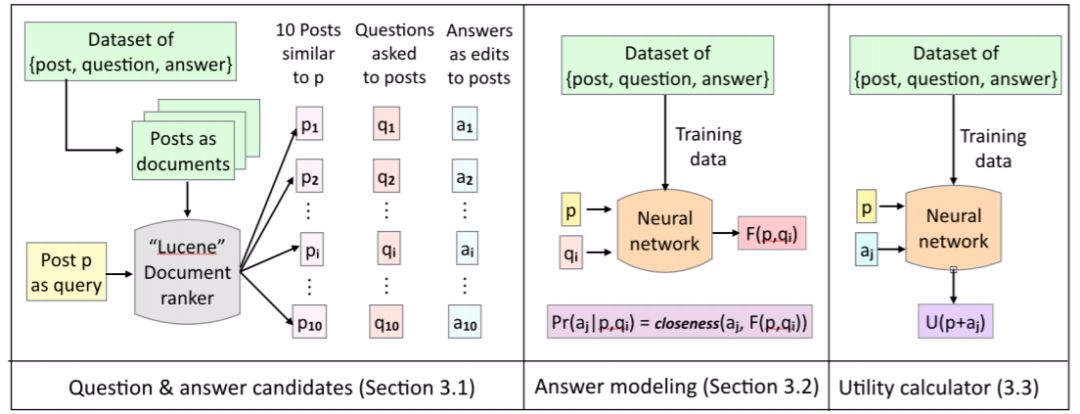
圖 2:我們的模型在測試過程中的行爲:給出帖子 p,我們使用 Lucene 檢索出 10 個與 p 類似的帖子。對這 10 個帖子提問的問題是我們的候選問題 Q,對這些問題的答覆是我們的候選答案 A。對於每個候選問題 q_i,我們生成答案表徵 F(p, q_i),並計算候選答案 a_j 與答案表徵 F(p, q_i) 之間的接近程度。然後我們計算帖子 p 的效用,並確定是否使用答案 a_j 對它進行更新。最後,我們根據公式 1,按照問題的期望效用對候選問題 Q 進行排序。
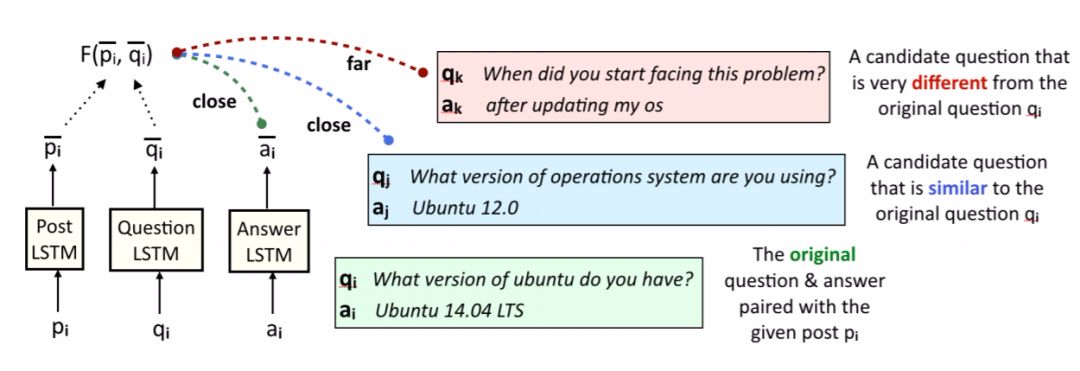
圖 3:答案生成器的訓練過程。給定一個帖子 p_i 和問題 q_i,我們生成答案表徵,其不僅與原始答案 a_i 很接近,而且在候選問題 q_j 與原始問題 q_i 接近的情況下答案表徵與候選答案 a_j 也很接近。
實驗結果
我們在實驗評估過程中使用的主要研究問題是:
1. 神經網絡架構是否比非神經網絡基線模型有所改善?
2. EVPI formalism 是否能影響有類似表徵力的前饋網絡?
3. 答案有助於識別正確的問題嗎?
4. 在候選問題(不包括原始問題)上評估模型時,模型性能如何?
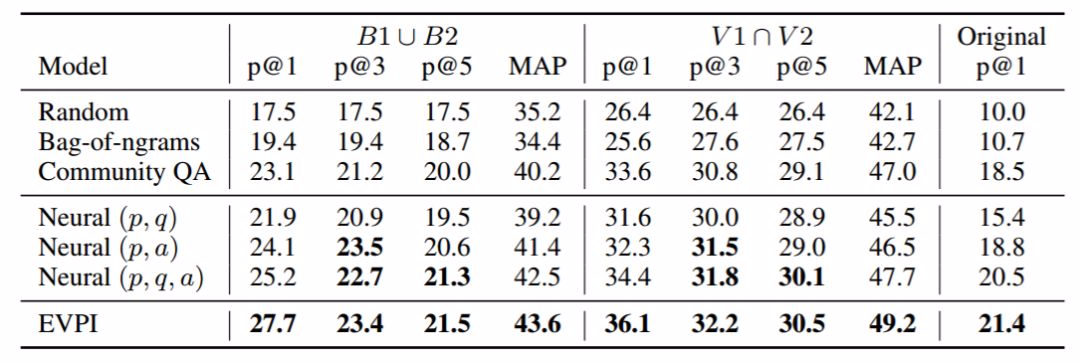
表 2:在 500 個樣本上評估的模型性能,包括「最佳」標註的並集(B1 ∪ B2)、「有效」標註的交集(V1 ∩ V2),以及數據集中和帖子配對的原始問題。加粗和非加粗數字的區別在於統計顯著性 p<0.05(使用自引導檢驗計算)。p@k 是模型排序最高的 k 個問題的精度,MAP 是模型預測排序的平均精度。
結論
我們爲學習給澄清性問題排序構建了一個新的數據集,併爲求解該任務提出了新的模型。該模型結合了著名的深度網絡架構和完美信息期望值的經典概念,可以從提問者的角度爲實用的選擇有效地建模:如果我問了這個問題,我應該如何設想對方的回答。這種實用原則近期被證明在其它任務中也有用(Golland et al., 2010; Smith et al., 2013; Orita et al., 2015; Andreas and Klein, 2016)。人們可以自然地將我們的 EVPI 方法擴展到完全的強化學習方法,以處理多回合的對話。實驗結果表明 EVPI 模型對於求解問題生成任務而言是有潛力的範式。
論文 2:Let’s do it 「again」: A First Computational Approach to Detecting Adverbial Presupposition Triggers

論文地址:https://www.cs.mcgill.ca/~jkabba/acl2018paper.pdf
摘要:我們介紹了預測狀語預設觸發語(如 also、again)的任務。解決這樣的任務需要檢測語篇中的重複或類似事件,並且在自然語言生成任務中有應用,例如摘要和對話系統。我們爲這項任務創建了兩個新的數據集,分別來自賓州樹庫(Penn Treebank)和 Annotated English Gigaword 語料庫,併爲其定製了一個新的注意力機制。我們的注意力機制增強了基線循環神經網絡,而不需要額外的可訓練參數,從而使注意力機制的額外計算成本最小化。我們已證實,根據統計數據,該模型優於許多基線模型,包括基於 LSTM 的語言模型。
在本文中,我們的重點是如 again、also、still 這樣的狀語預設觸發語。狀語預設觸發語指出了語篇中事件的重複、延續或終止,或者類似事件的存在。
本論文的主要貢獻如下:
介紹了預測狀語預設觸發語的任務;
提出了用於檢測狀語預設觸發語的新數據集,以及一種可應用於其它類似預處理任務的數據提取方法;
在 RNN 架構中使用一種新的注意力機制,可用於預測狀語預設觸發語任務。這種注意力機制無需引入額外的參數,但預測效果優於很多基線模型。
3 數據集
我們從兩個語料庫中提取了數據集,即賓州樹庫(PTB)語料庫(Marcuset al.,1993)和第三版 English Gigaword 語料庫(Graff et al.,2007)的子集(sections 000-760)。

圖 1:我們的數據集中一個包含預設觸發語的實例。
4 學習模型
本章介紹了我們基於注意力的模型。該模型計算每一時間步上隱藏狀態之間的相關性,然後再在這些相關性上應用注意力機制,從而擴展雙向 LSTM 模型。我們提出的加權池化(WP)神經網絡架構如圖 2 所示。
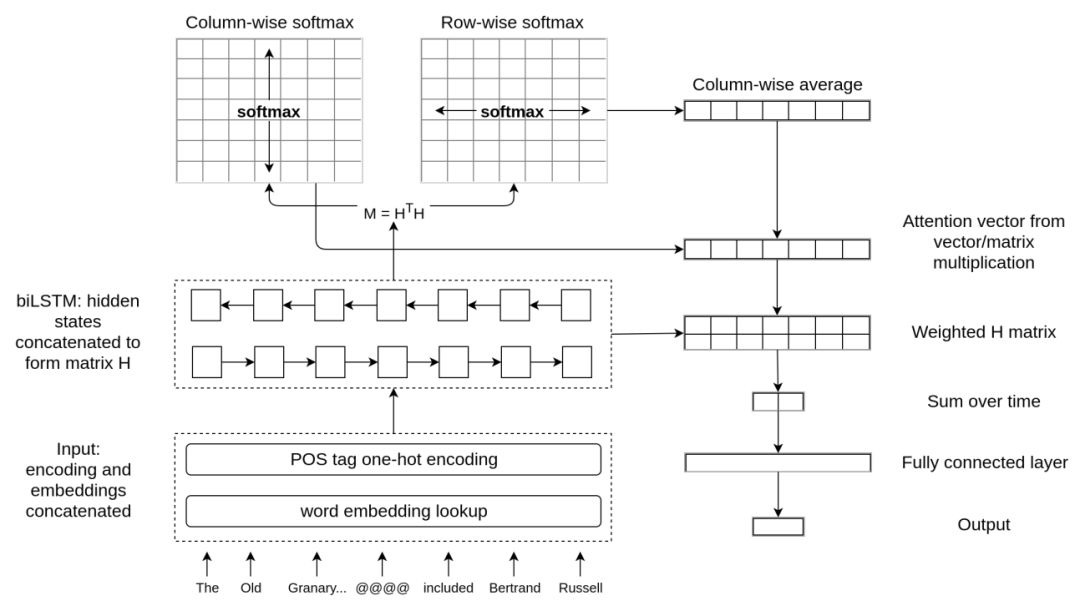
圖 2:我們提出的加權池化神經網絡架構(WP)。分詞後的輸入將嵌入到預訓練詞嵌入中,並可能與經過 one-hot 編碼的 POS 標籤相級聯。輸入序列隨後會通過雙向 LSTM 進行編碼,並饋送到注意力機制內。計算得出的注意力權重隨後可用於編碼狀態的加權平均運算,依次連接到全連接層以預測預設觸發語。
6 結果
表 2 顯示了具有 POS 標籤和沒有該標籤的不同模型的表現。總體而言,在結合不同數據集以及是否使用 POS 標籤的所有 14 個場景裏,我們的注意力模型 WP 在 10 個場景中優於所有其它模型。重要的是,該模型在未引入額外參數的情況下,超越了常規 LSTM 模型,這突出了 WP 基於注意力的池化方法的優勢。
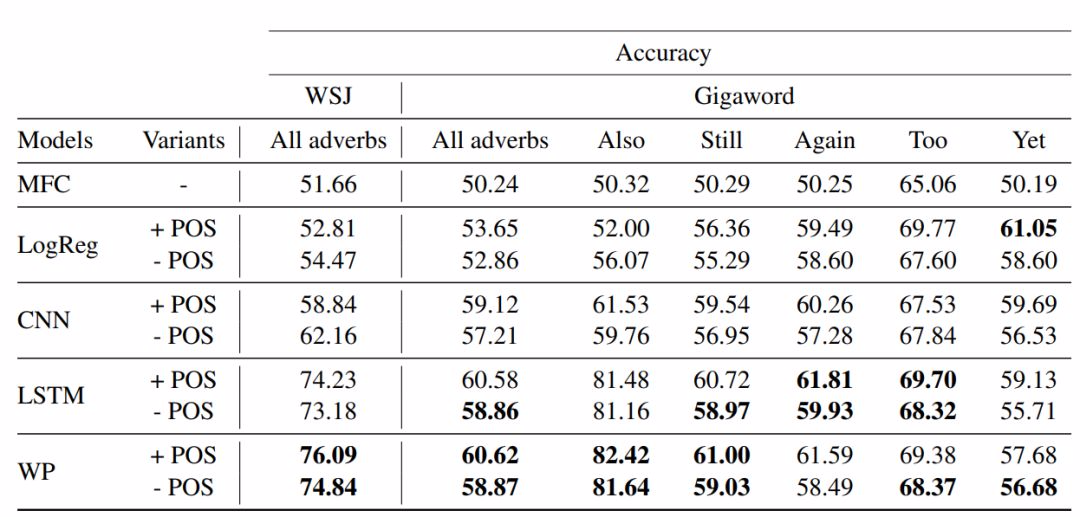
表 2:各種模型的性能,包括加權池化的 LSTM(WP)模型。MFC 指最常見的基線,LogReg 是 logistic 迴歸基線。LSTM 和 CNN 對應強大的神經網絡基線模型。請注意,我們把每個「+ POS」案例和「- POS」案例中最佳模型的性能數字加粗顯示了。
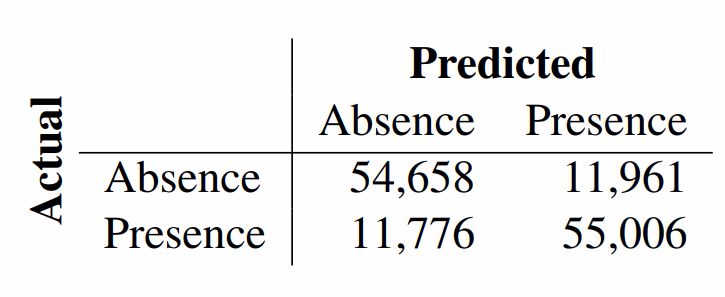
表 3:最佳模型的混淆矩陣,預測預設觸發語是否存在。
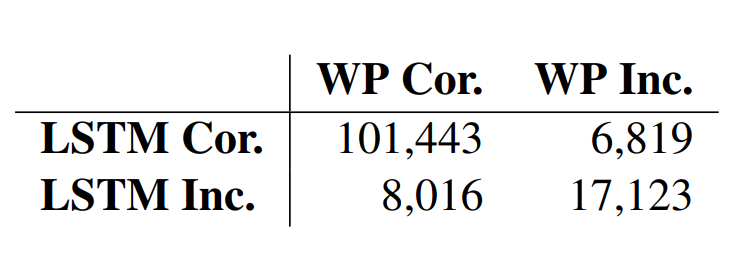
表 4:在 Giga_also 數據集上 LSTM 基線模型與注意力模型(WP)正確預測(cor.)和錯誤預測(inc.)的列聯表。
參考內容:https://acl2018.org/2018/06/10/best-papers/