日常用語中的參考式表達可以幫助我們識別和定位周圍的實體。例如,我們可以用「踢球的人」和「守門的人」將兩個人區分開(圖 1)。在這兩個例子中,我們通過兩人與其他實體的關係來明確他們的具體身份 [24]。其中一個人在踢球,而另一個人在守門。我們的最終目標是建立計算模型,以明確其他詞彙與哪些實體相關 [ 36 ]。
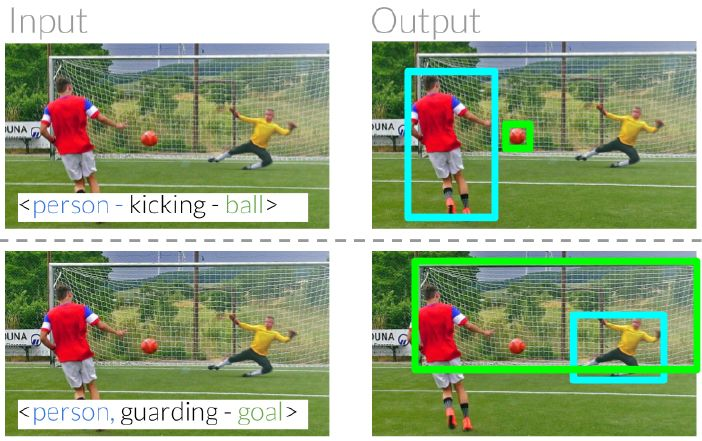
圖 1:參考關係可以通過利用同一類別中的物體與其他實體之間的相對關係來明確區分這些物體。給定
爲了實現這種交互,我們引入了參考關係(referring relationships),即在給定關係的情況下,模型應該清楚場景中的哪些實體在該關係中用作參考。從形式上講,該任務需要輸入帶有
參考關係在前期任務的核心保留並改善算法難題。在客體定位文獻中,一些實體 (如斑馬和人) 差別非常明顯,很容易被區分開來,而另一些客體(如玻璃和球)則較難區分 [ 30 ]。造成這些困難的原因包括某些成分尺寸小、不易區分。這種難度上的差異轉化爲參考關係任務。爲了應對這一挑戰,我們提出這樣一種思路:如果我們知道另一個實體在哪裏,那檢測一個實體就會變得更容易。換句話說,我們可以藉助踢球的人爲條件來發現球,反之亦然。我們通過展開模型及通過謂詞定義的運算符在主客體之間迭代傳遞消息來訓練這種循環依賴關係。
然而,對這個謂詞運算符建模並不簡單,這就引出了我們的第二個挑戰。傳統上,以前的視覺關係論文已經能爲每個謂詞訓練了一個基於外觀的模型 [21, 24, 27]。不幸的是,謂詞語義的急劇變化(取決於所涉及的實體)增加了學習謂詞模型的難度。例如,謂詞 carrying 的語義在以下兩種關係之間可能有很大差異:
總而言之,我們介紹了參考關係這一任務,它的結構化關係輸入使得我們可以評估識別圖片中同一類別實體的能力。我們在包含視覺關係的三個視覺數據集(CLEVR [13], VRD [24] 和 Visual Genome [18])上評估我們的模型。這些數據集中的 33 %、60.3 % 和 61 % 的關係涉及不明確的實體,即相同類別中的多個實例的實體。我們擴展我們的模型以使用屬於場景圖的關係來執行焦點掃視 [ 38 ]。最後,我們證明了在沒有主體或客體的情況下,這一新模型仍然可以明確各個實體,同時還可以辨別來自以前從未見過的新類別實體。
我們的模型使用帶有 TensorFlow 後端的 Keras 進行編寫。
模型地址:https://github.com/StanfordVL/ReferringRelationships。
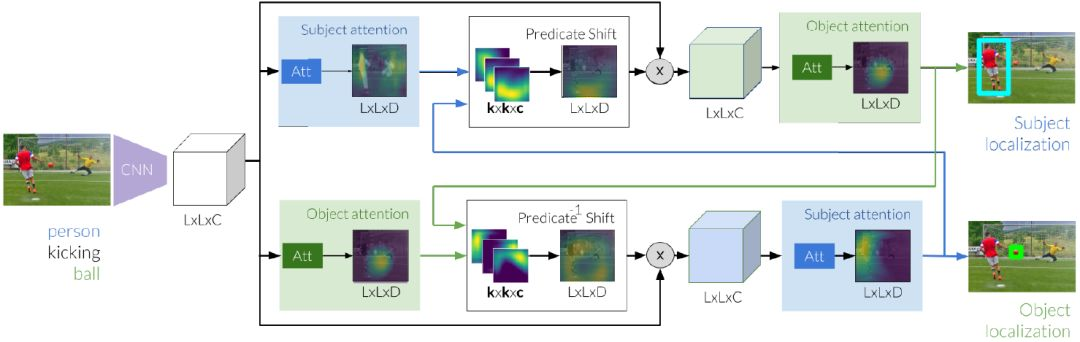
圖 2:參考關係的推理過程始於圖像特徵提取,然後使用這些圖像特徵獨立地生成主體和客體的初始標註。接下來,使用這些估計值將謂詞的焦點從主體轉移到我們期望客體的位置。在細化客體的新評估時,我們通過關注偏移區域來修改圖像特徵。同時,我們學習從初始客體到主體的逆向變換。我們通過兩個謂詞移位模塊以迭代的方式在主客體之間傳遞消息,以最終定位這兩個實體。
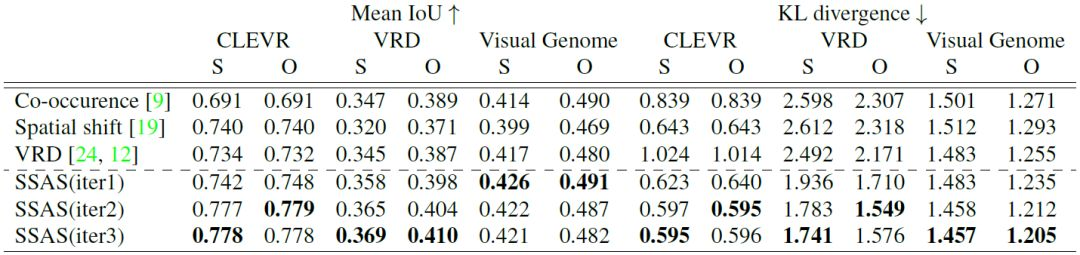
表 1:CLEVR[ 13 ]、VRD [ 24 ] 和 Visual Genome[ 18 ] 上對參考關係的測試結果。我們分別報告了主體和客體位置的 Mean IoU 和 KL 散度。
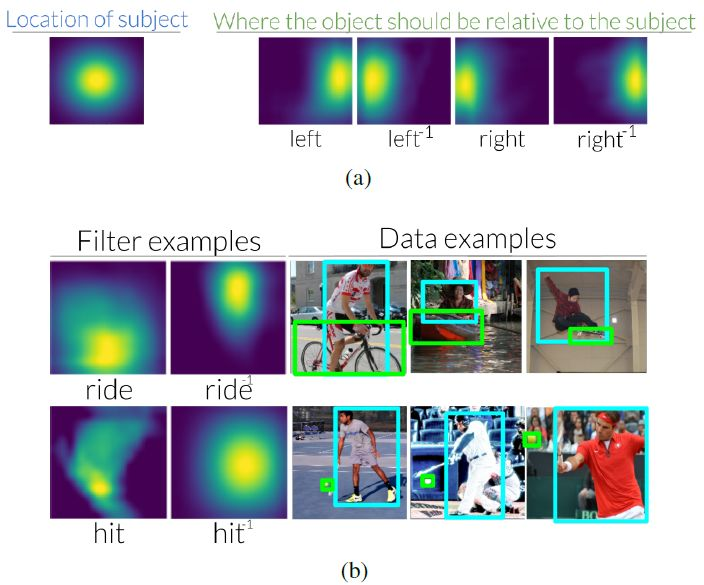
圖 3:( a ) 相對於圖像中間的主體,謂詞 left 在使用關係查找對象時將焦點轉移到右邊。相反,當用客體來尋找主體時,逆謂詞 left 會把焦點轉移到左邊。我們在附錄中將所有 70 個 VRD、6 個 CLEVR 和 70 個 Visual Genome 謂詞和逆謂詞移位進行可視化。( b ) 我們還發現,在查看用於學習這些變化的數據集時,這些變化是直觀的。例如,我們發現騎行通常對應於主體在客體的下方。

圖 4:焦點如何從 CLEVR 和 Visual Genome 數據集進行多次迭代轉移的可視化示例。在第一次迭代中,模型僅接收關於它試圖查找的實體信息,因此試圖定位這些類別的所有實例。在後面的迭代中,我們看到謂詞轉移了焦點,它允許我們的模型明確區分同一類別中的不同實例。
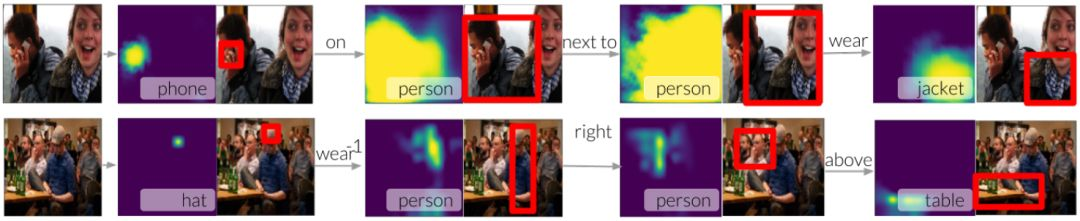
圖 5:我們可以將新模型分解爲焦點和移位模塊,並將其堆疊起來,以覆蓋場景圖的節點。本圖展示瞭如何使用我們的模型從一個節點(電話)開始根據關係遍歷場景圖,以連接它們並定位短語
論文:Referring Relationships

論文鏈接:https://arxiv.org/abs/1803.10362
摘要:圖像不僅僅是一組目標集合,同時每個圖像還代表一個相互關聯的關係網。實體之間的這些關係承載着語義功能,幫助觀察者區分一個實體中的實例。例如,一張足球比賽的圖片中可能不止一人,但每個人都處在不同的關係中:其中一人在踢球,另一人則在防守。在本文中,我們提出了利用這些「參考關係」明確區分同類實體的任務。我們引入了一個迭代模型,利用該模型區分參考關係中的兩個實體,二者互爲條件。我們通過謂詞建模來描述以上關係中實體之間的循環條件,這些謂詞將實體連接爲從一個實體到另一個實體的焦點移位。實驗結果表明,該模型不僅在 CLEVR、VRD 和 Visual Genome 三個數據集上均優於現有方法,而且能作爲可解釋神經網絡的一個實例。此外,它還能產生可視的有意義的謂詞移位。最後,我們提出,通過將謂詞建模爲注意轉移,我們甚至可以區分模型沒見過的類別中的實體,從而使我們的模型發現完全沒見過的類別。