選自Google Blog
作者:Jonathan Shen、Ruoming Pang
近日,谷歌在其官方博客上推出了新的語音合成系統 Tacotron 2,包括一個循環序列到序列特徵預測網絡和一個改良的 WaveNet 模型。Tacotron 2 是在過去研究成果 Tacotron 和 WaveNet 上的進一步提升,可直接從文本中生成類人語音,相較於專業錄音水準的 MOS 值 4.58,Tacotron 2 取得了 4.53 的 MOS 值。雖然結果不錯,但仍有一些問題,比如無法實時生成語音。我們對博客內容和論文摘要進行了編譯,原文鏈接請見文中。
幾十年來人們一直希望可以從文本生成聽感自然的語音系統(text-to-speech,TTS)。過去幾年來,TTS 研究取得了重大進展,完整 TTS 系統的各個獨立部分得到了很大的性能提升。通過結合過去的研究成果如 Tacotron 和 WaveNet,我們獲得了更大的性能提升,最終構建出了新系統 Tacotron2。我們的方法並沒有使用複雜的語言學或聲學特徵作爲輸入,而是使用神經網絡從文本生成類人的語音,其中輸入數據僅使用了語音樣本和相關的文本記錄。
可以在論文「Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions」中查看新系統的完整描述。簡單來說,該系統的工作方式是:優化一個序列到序列模型以將字母序列映射到編碼了錄音的特徵序列。這些擁有 80 個維度的聲譜(每 12.5 毫秒計算一個幀)不僅捕捉了單詞的發音,還有人類語音的微妙變化,包括音量、語速和語調。最後,這些特徵被一個類似 WaveNet 的架構轉換成 24kHz 的波形。
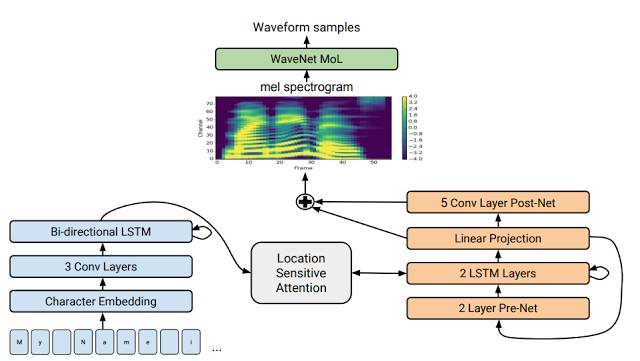
Tacotron2 模型架構的詳細結構。圖中的下半部分描述了將字母序列映射到聲譜的序列到序列模型的結構。更多技術細節請參見論文。
TTS 新系統取得了當前最佳的結果,可以在這裏試聽 Tacotron2 生成的語音樣本:https://google.github.io/tacotron/publications/tacotron2/index.html。我們讓人類聽者試聽生成的語音以評估其自然性(類人性),並取得了和專業錄音相當的分數。
雖然結果很不錯,但還存在一些困難需要解決。例如,新系統很難對複雜單詞做出正確的發音(例如,decorum 和 merlot),在極端情況下它甚至會隨機生成奇怪的噪音。並且,我們的系統目前還不能實時生成語音。此外,我們還無法控制生成的語音,例如使聲音聽起來開心或悲傷。這些都是很有趣的研究方向。
論文:Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions

論文鏈接:https://arxiv.org/abs/1712.05884
摘要:本論文介紹了 Tacotron 2,一個用於直接從文本合成語音的神經網絡架構。該系統包括一個循環序列到序列特徵預測網絡(把字符嵌入映射到梅爾標度譜圖)以及一個改良的 WaveNet 模型(作爲聲碼器以從這些譜圖中合成時域波形)。相較於專業錄音水準的 MOS 值 4.58,我們的模型取得了 4.53 的 MOS 值。爲了驗證我們的設計選擇,我們展示了系統關鍵組件的消融研究,並評估了使用梅爾譜圖取代語言學、持續時間、F_0 特徵作爲 WaveNet 輸入的影響。我們進一步證明使用一個緊湊的聲學中間表徵能夠明顯簡化 WaveNet 的架構。
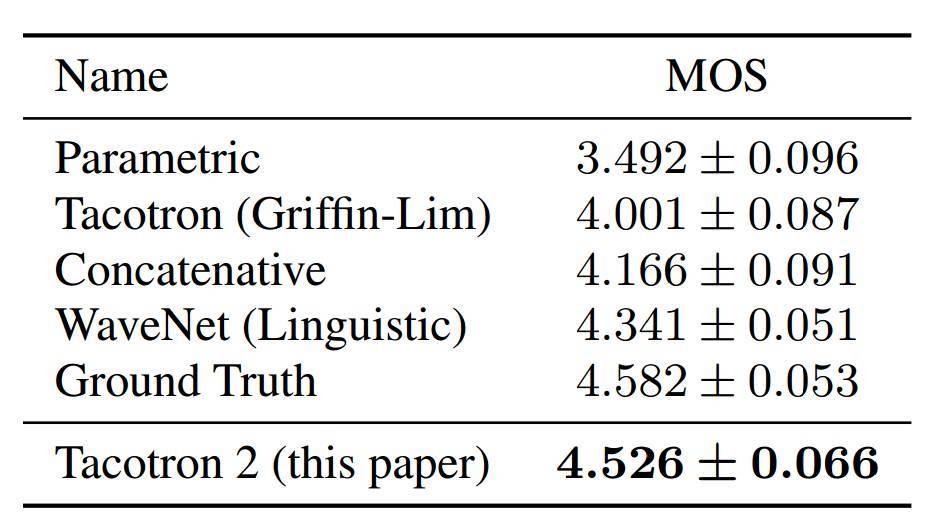
表 1:不同系統 95% 置信區間的 MOS 估值
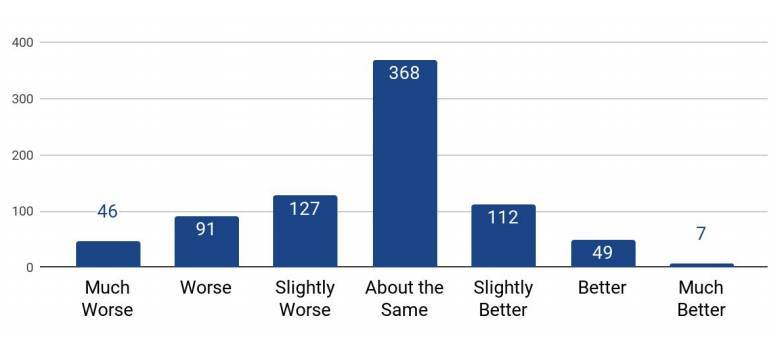
圖 2:合成值 vs. 真值:100 項上的 800 個評級
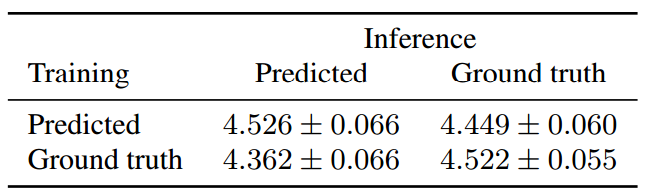
表 2:當已在預測/真值梅爾譜圖上訓練的 WaveNet 用於從預測/真值梅爾譜圖上進行合成之時,系統評估的 MOS 值的對比。
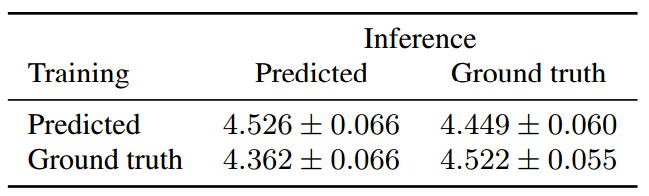
表 3:分別以 Griffin-Lim 和 WaveNet 爲聲碼器的 MOS 值比較,以及在 WaveNet 中分別使用 1025 維的線性譜圖和 80 維的梅爾譜圖作爲條件特徵的 MOS 值比較。
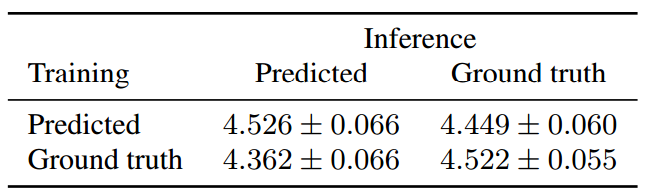
表 4:不同層設置和感受野大小的 WaveNet 的 MOS 值評估結果。
原文地址:https://research.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html