雷鋒網(公衆號:雷鋒網) AI 科技評論按:基於深度學習的有監督語音分離在學術界和工業界越來越受到關注,也是深度學習在語音領域的應用中重要的一部分。作爲雷鋒網AI研習社近期組織的一系列語音領域應用的分享會之一,本次我們請到了來自搜狗的研究員文仕學對語音分離方面主要的研究課題和相關方法做一些介紹。
文仕學,過去學物理,後來學EE,現在從事Deep Learning工作,未來投身AI和CM事業。他的研究興趣在於語音信號處理和深度學習。在加入搜狗之前,曾在中國科學技術大學學習,在該領域的期刊和會議上發表了若干篇論文。現在在搜狗語音團隊任副研究員。
雷鋒網 AI 科技評論將本次分享的內容整理如下。

分享主題:基於深度學習的語音分離
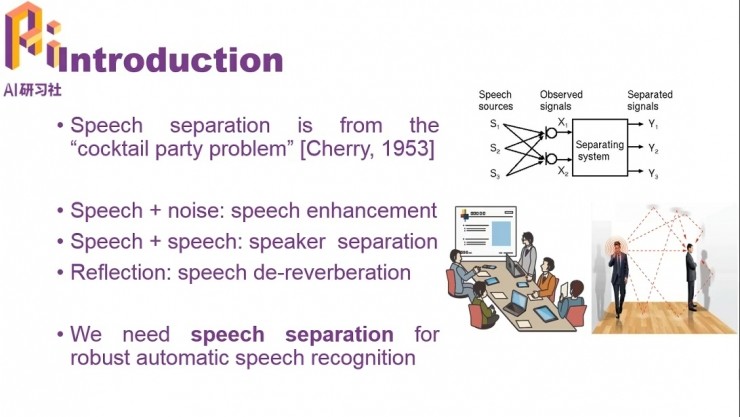
文仕學首先介紹了「語音分離」(Speech Separation)是怎麼樣的一種任務。這個問題來自於「雞尾酒會問題」,採集的音頻信號中除了主說話人之外,還有其他人說話聲的干擾和噪音干擾。語音分離的目標就是從這些干擾中分離出主說話人的語音。
根據干擾的不同,語音分離任務可以分爲三類:
當干擾爲噪聲信號時,可以稱爲「語音增強」(Speech Enhancement)
當干擾爲其他說話人時,可以稱爲「多說話人分離」(Speaker Separation)
當干擾爲目標說話人自己聲音的反射波時,可以稱爲「解混響」(De-reverberation)
由於麥克風採集到的聲音中可能包括噪聲、其他人說話的聲音、混響等干擾,不做語音分離、直接進行識別的話,會影響到識別的準確率。因此在語音識別的前端加上語音分離技術,把目標說話人的聲音和其它干擾分開就可以提高語音識別系統的魯棒性,這從而也成爲現代語音識別系統中不可或缺的一環。
基於深度學習的語音分離,主要是用基於深度學習的方法,從訓練數據中學習語音、說話人和噪音的特徵,從而實現語音分離的目標。

這次分享的內容有以下這5個部分:分離使用的模型、訓練目標的設置、訓練數據的生成、單通道語音分離算法的介紹和討論。
基於深度學習的語音分離方法使用的模型
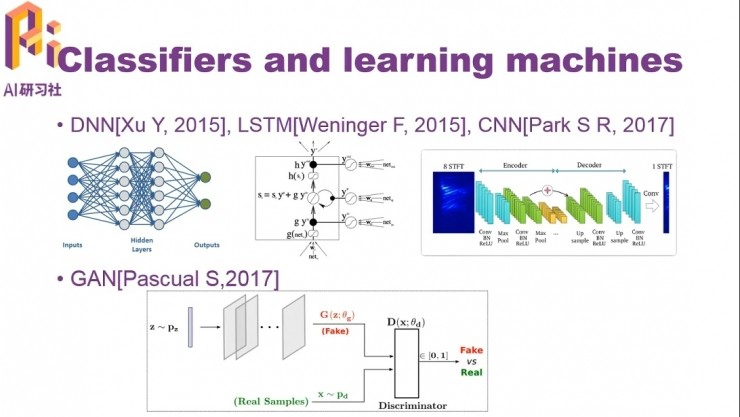
第一類模型是多層感知機,DNN,可以先做RBM預訓練,再做微調(fine-tune);不過文仕學介紹,他們團隊通過實驗發現,在大數據集上不需要預訓練也可以收斂。
LSTM(長短時記憶網絡)的方法中把語音作爲一個隨時間變化的序列進行建模,比較適合語音數據;CNN(卷積神經網絡)通過共享權值,可以在減少訓練參數的同時獲得比全連接的DNN更好的性能。
近些年也有人用GAN(對抗性生成式網絡)做語音增強。模型中通常會把生成器設置爲全部是卷積層,爲了減少訓練參數從而縮短訓練時間;判別器負責向生成器提供生成數據的真僞信息,幫助生成器向着「生成乾淨聲音」的方向微調。
訓練目標的設置
訓練目標包括兩類,一類是基於Mask的方法,另一類是基於頻譜映射的方法。
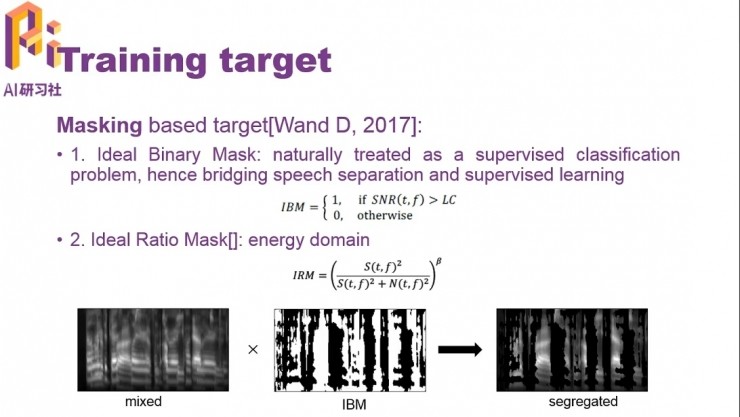
基於Mask的方法又可以分爲幾類
「理想二值掩蔽」(Ideal Binary Mask)中的分離任務就成爲了一個二分類問題。這類方法根據聽覺感知特性,把音頻信號分成不同的子帶,根據每個時頻單元上的信噪比,把對應的時頻單元的能量設爲0(噪音佔主導的情況下)或者保持原樣(目標語音佔主導的情況下)。
第二類基於Mask的方法是IRM(Ideal Ratio Mask),它同樣對每個時頻單元進行計算,但不同於IBM的「非零即一」,IRM中會計算語音信號和噪音之間的能量比,得到介於0到1之間的一個數,然後據此改變時頻單元的能量大小。IRM是對IBM的演進,反映了各個時頻單元上對噪聲的抑制程度,可以進一步提高分離後語音的質量和可懂度。

TBM與IRM類似,但不是對每個時頻單元計算其中語音和噪聲的信噪比,而是計算其中語音和一個固定噪聲的信噪比
SMM是IRM在幅度上的一種形式
PSM中加入了乾淨語音和帶噪語音中的相位差信息,有更高的自由度
雖然基於Mask的方法有這麼多,但最常用的還是開頭的IBM和IRM兩種
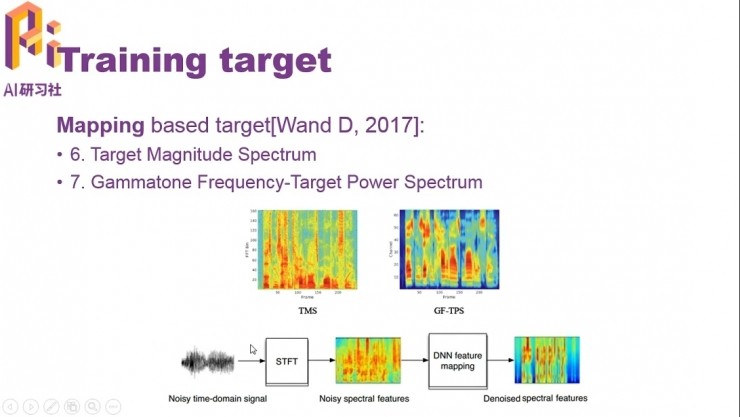
如果使用頻譜映射,分離問題就成爲了一個迴歸問題。
頻譜映射可以使用幅度譜、功率譜、梅爾譜以及Gammatone功率譜。Gammatone是模擬人耳耳蝸濾波後的特徵。爲了壓縮參數的動態範圍以及考慮人耳的聽覺效應,通常還會加上對數操作,比如對數功率譜。
基於頻譜映射的方法,是讓模型通過有監督學習,自己學習有干擾的頻譜到無干擾的頻譜(乾淨語音)之間的映射關係;模型可以是DNN、CNN、LSTM甚至GAN。
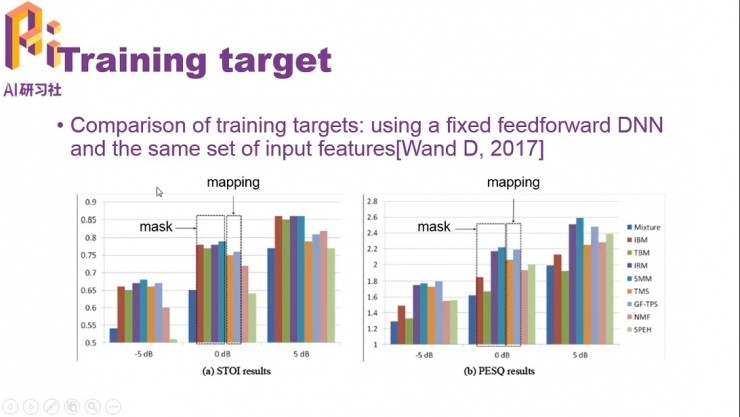
這一頁是使用相同的DNN模型、相同的輸入特徵、不同的訓練目標得到的結果。
左邊的STOI指語音的可懂度,得分在0到1之間,越高越好;右邊的PESQ是語音的聽覺質量、聽感,範圍爲-0.5到4.5,也是越高越好。
基於Mask的方法STOI表現較好,原因是有共振峯的能量得到了較好的保留,而相鄰共振峯之間波谷處的聲音雖然失真較大,但人耳對這類失真並不敏感;兩類方法在PESQ中表現相當。
訓練數據的生成
針對語音分離中的語音增強任務,首先可以通過人爲加噪的方法生成帶噪語音和乾淨語音對,分別作爲輸入和輸出(有標註數據),對有監督學習模型進行訓練。加入的噪聲可以是各種收集到的真實世界中的噪聲。
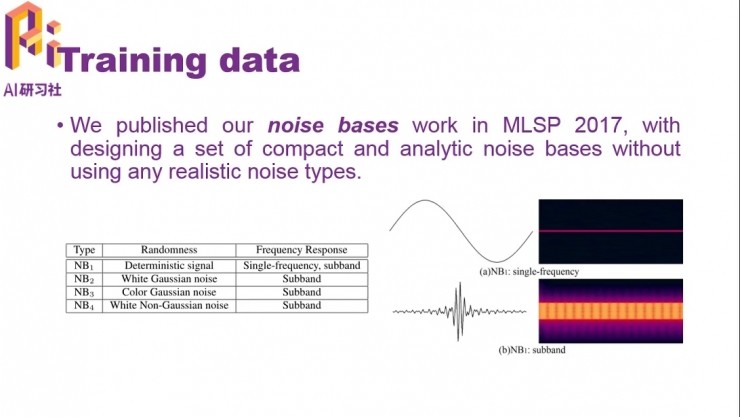
不過收集噪聲需要成本,而且人工能夠收集到的噪音總是有限的,最好能夠有一套完備、合理的方案,用仿真的方式生成任意需要的噪聲。 在今年的MLSP(信號處理機器學習)會議上,搜狗語音團隊就發表了一項關於噪聲基的工作,通過構造一個噪聲基模型,在不使用任何真實噪音數據的情況下,生成帶噪語音對語音增強模型進行訓練,達到了與使用50種真實噪音的情況下相當的性能(下圖)。
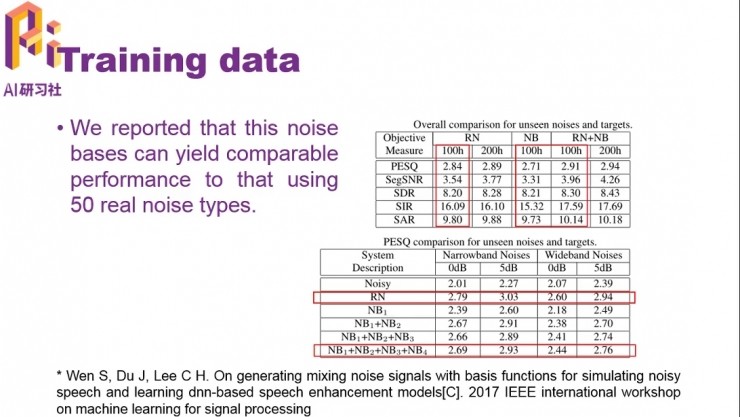
如果將這50種真實噪聲和噪聲基產生的數據混合在一起,性能可以比單獨使用真實噪音的情況得到進一步提高。這也說明噪聲基生成的噪聲和真實噪聲數據之間有着互補性,在實際應用中也可以解開一些真實噪聲數據不足帶來的限制。
單通道語音分離算法
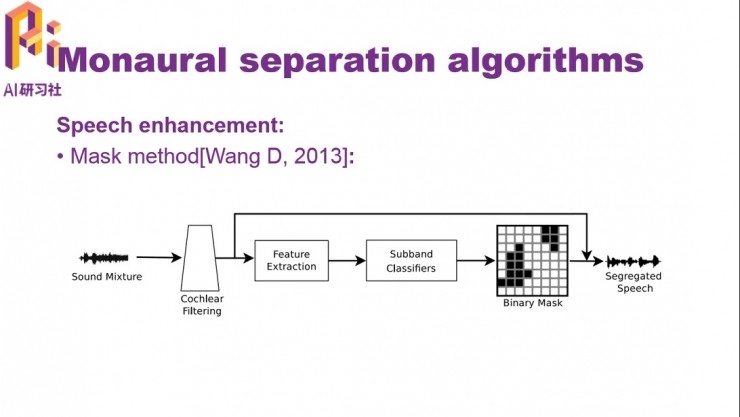
如開頭所說,語音分離任務可以分爲三類,語音增強、多說話人分離和解混響。不同任務的處理方法也有所不同。
對於語音增強,基於Mask的方法首先進行耳蝸濾波,然後特徵提取、時頻單元分類、二值掩蔽、後處理,就可以得到增強後的語音了。
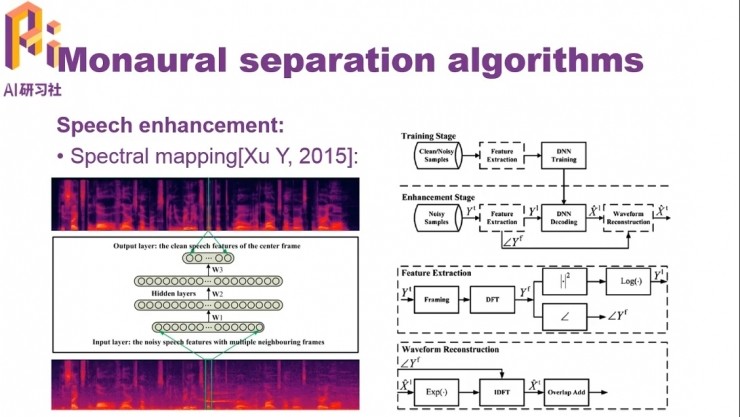
語音增強的另一類基於頻譜映射的方法中,先特徵提取,用深度神經網絡學習帶噪語音和乾淨語音的對數功率譜之間映射關係,再加上波形重建,就可以得到增強後的語音。

基於有監督學習的算法都存在推廣性(generalization)的問題,語音增強這裏也不例外。針對噪音類型、信噪比和說話人的推廣性都還有提升的空間。
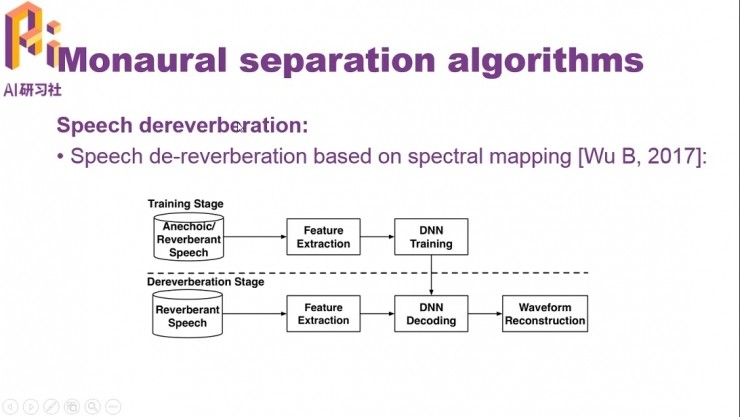
對於解混響,同樣可以使用基於頻譜映射的方法。解混響中也需要生成訓練數據,但不同於帶噪語音生成時做時域的相加,帶混響的語音是在時域上進行卷積;同樣都把乾淨語音作爲帶標註數據。
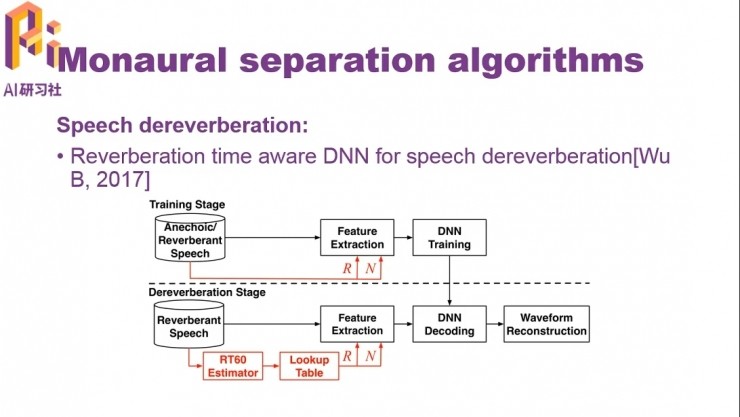
在基於頻譜映射的方法基礎上還可以加以改進。對於不同的混響時間,深度神經網絡需要學習的時間窗口長度是不一樣的,因而改進方法中加入了告知混響時間的功能,根據幀移R和擴幀數目N提特徵後解碼,可以獲得更好的解混響效果。

多說話人分離分爲三種情況
目標說話人和干擾說話人都固定,Speaker dependent,有監督分離
目標說話人固定,訓練階段和測試階段的干擾說話人可變,Target dependent,半監督分離
目標說話人和干擾說話人都可變,Speaker independent,無監督分離
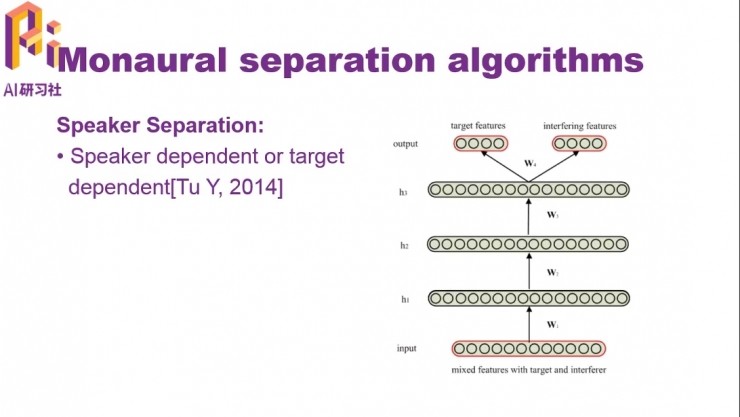
對於有監督和半監督分離,可以使用基於頻譜映射的方法,與前面使用基於頻譜映射的方法做語音增強類似。
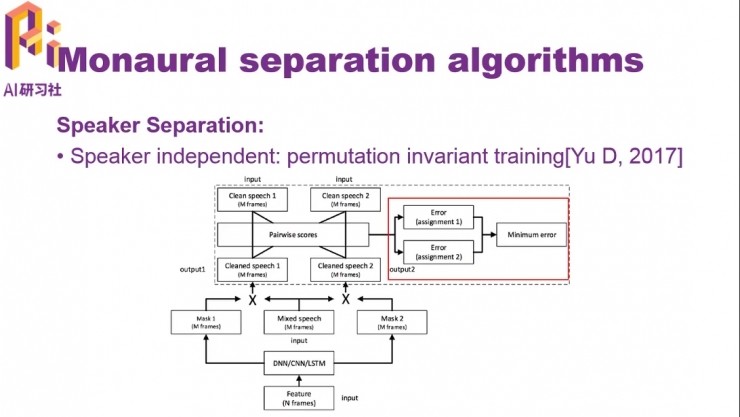
對於無監督分類,有無監督聚類、深度聚類以及最近的序列不變訓練(PIT)方法。PIT方法的核心是紅框中標出的部分,在誤差回傳的時候,分別計算輸出序列和標註序列間各種組合的均方誤差,然後從這些均方誤差中找到最小的那個作爲回傳誤差,也就是根據自動找到的聲源間的最佳匹配進行優化,避免出現序列模糊的問題。
討論兩個問題

最後,文仕學給大家留了兩個思考題,歡迎大家在評論區給出自己的見解。
第一個問題是語音分離任務中,是按傳統思路先變換到頻域,然後在頻域上進行處理,還是直接在時域上處理比較好?後者的好處是端到端訓練,不用考慮頻域方法做傅立葉反變換時相位的問題。
第二個問題是對於語音增強任務,應該使用真實噪聲加噪還是使用人工仿真生成的噪聲進行降噪?
感謝文仕學此次的分享以及對文本的指正,也歡迎大家關注雷鋒網 AI 研習社未來的更多分享活動!
