由於類別樣本不均衡,人臉檢測只在正臉識別上有優秀的表現,它們很難識別側臉樣本。近日,香港中文大學和商湯科技等研究者提出了一種在深度表示空間中通過等變映射在正臉和側臉間建立聯繫的方法,該方法的計算開銷較少,但可以大大提升側臉識別效果。
引言
深度學習的出現大大推動了人臉識別的發展。而人臉識別的焦點傾向於以正臉附近爲中心,然而在不受限的環境中進行人臉識別,並不能保證其結果。儘管人類從正面識別側面的表現只比從正面識別正面的表現差一點,可現存的算法在處理類似問題時準確率會下降 10% 以上。因此,姿勢的變化仍舊是人臉識別應用在現實世界的重大挑戰。

圖 1:在極具挑戰性的正面-側面面部數據集上對最先進的人臉識別模型進行測試。顯而易見,不同人的側臉很容易會被進行錯誤匹配(假正類),而同一個人的正臉可能沒法和他的側臉匹配到,從而導致了假負類。
我們在圖 1 中展示了最先進的人臉識別模型的錯誤模式。我們訓練了與 [34] 中提到的一樣的模型——ResNet-18 模型。這個模型在 LFW 基準數據集中的準確率高達 99.3%。儘管該模型很強大,但它還是會誤匹配不同人的正臉和側臉從而得到一些假正類結果。此外,該模型還會錯配相同個體的正臉和側臉,從而導致假負類結果。
爲什麼人臉識別技術在側臉上表現欠佳?深度學習系統很大程度上依靠數據驅動。一般而言,模型的泛化能力和數據量成正比。模型訓練使用的數據集正臉和側臉數據量不均衡,因此訓練出的模型更擅長分辨正面。目前我們還沒有涵蓋人類所有姿勢且分佈均勻的數據集,因此研究人員要用其他方法解決側臉識別問題。很多方法在識別前儘可能細緻地描述面部 3D 結構,使其歸一化爲只含正面的圖像;或採用另一個深度模型(或生成對抗網絡)將人臉轉正。這些方法會給整個系統增加負擔。此外,面部圖像,尤其是極側面的圖像很難轉化爲自然狀態。一般而言,合成的正面圖片有人工造成的遮擋或非嚴格表情,它們都會影響模型的性能。我們還可以採用分而治之的方法,也就是說,用獨立的模型來學習特定姿態的一致性特徵 [19]。但這些策略因爲使用多個模型而會增加計算成本。
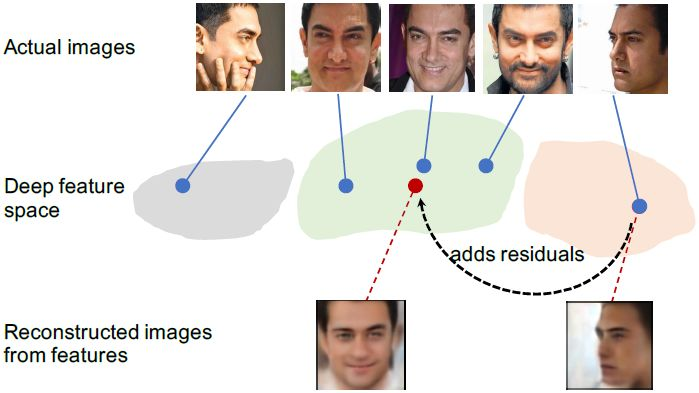
圖 2:該圖上部分表明個體不同姿勢嵌入的深度特徵。DREAM 模塊對側臉特徵添加殘差,還可以將其映射到正臉空間上。我們在圖片下部分展示了實際的側臉重構圖和其正面映射。
本研究假設在深度特徵空間中,側臉區域和正臉區域有關聯。圖 2 表明同一主體不同姿勢的面部的深度表示。輸入任意姿勢的圖像,我們可以將其特徵通過添加的殘差映射函數映射到正臉的特徵空間上。這一理論和特徵等變性的概念很接近,通過特徵等變性發現,可以通過轉換輸入圖得到深度學習層的表示。有趣的是,這樣的轉換可以通過基於數據的映射函數學習到,而映射函數之後還可以應用於控制輸入圖的表示,以達到想要的轉換。
我們由此受到啓發,開發了深度殘差等變映射(DREAM)模塊。該模塊可以在高層深度特徵空間中將正臉和側臉進行轉換。該模塊自適應地將殘差添加到輸入表示中,將側臉轉換爲標準姿勢使識別變得更爲簡單。爲了適應任意姿勢的面部輸入,我們引入軟門控機制(soft gate)自適應地控制殘差量,這樣在輸入正面姿勢的情況下,爲保結果不變,會給極側的姿勢加入更多殘差。
從概念上講,我們的這項工作與臉部正向化(frontalization)有關,因此我們的方法也可應用於除圖像空間的正向化的其他問題。我們從實驗中觀察到:從側臉特徵向正臉特徵轉化比圖像級的正向化效果更好,也就是說,在圖像合成問題上該方法對負影響更爲敏感。據我們所知,我們所做的這項研究,是第一次嘗試在深度特徵空間進行側面到正面的轉換。
DREAM 模塊的吸引力在以下方面:
該模塊實施簡單。具體來說,DREAM 模塊是一個簡單有效的門控殘差分支。它可以通過將這個模塊拼接到基礎網絡,集成到現有的卷積神經網絡架構中,無需改變面部表示的原始維度,還可以用標準反向傳播進行端到端的訓練。
該模塊權重較輕,它在基礎的模型上添加的參數很少,因此無須太多計算資源。以 ResNet-18 爲例,該模塊只增加了 0.3% 的參數和 1.6% 的時間成本。
基礎網絡識別近正面圖片效果很好,且該模塊能幫助基礎網絡在識別極端姿勢的面部時取得更好的表現。該方法並不需要更詳細的數據,面部數據的標準化也是以大多數現有的針對面部識別的研究爲基礎實現的。
深度殘差等變映射
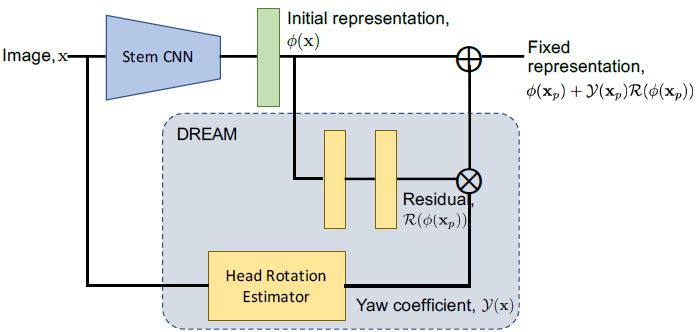
圖 3:DREAM 模塊的設計思路非常簡單,而且該模塊易於添加到已存的 CNN 中。該模塊可以輕鬆地將殘差添加到輸入表示中,將側臉轉換爲標準姿勢,使識別變得簡單。
我們描述了三種使用 DREAM 的方法。三種實驗的方法比較將在後面的實驗部分提出。
拼接。部署 DREAM 模塊最方便的辦法是直接將模塊「拼接」到訓練好的 CNN 中。特別是在給定基本網絡架構的時候,我們可以在不改變任何原始模型學習參數的情況下,將 DREAM 模塊拼在基礎網絡最後的特徵層中。

圖 4:深度特徵可視化。第一行和第三行展示的是重構側臉原始特徵。第二行和第四行描繪的是通過 DREAM 模塊映射重構特徵。
端到端。我們提出的這個輕權重的模塊也可以端到端的方式和主幹 CNN 一起訓練。給定一個簡單的基礎網絡,我們將 DREAM 模塊插入該網絡,並直接用隨機初始參數訓練新網絡。如果這個 CNN 不夠簡單或是之前訓練過,我們可以使用現有的面部識別損失(例如,驗證損失(verification)、識別損失(identification)等)用端到端的方法訓練 DREAM 模塊時對 CNN 進行微調。我們將這種策略命名爲「end2end」。使用這種策略,模型在側臉識別方面的表現無法保證,因爲 DREAM 模塊可能無法分辨正面和側面,原因是在模塊訓練過程中沒有具體地將一張臉的正面和側面配對。
端到端+重新訓練。我們先將 CNN 和 DREAM 同時訓練,再用成對的正面側面的數據對 DREAM 模塊進行有針對性地訓練。

表 1:有正面側面設置的 CFP 數據訓練得到的結果。等錯誤率(EER)如表所示,EER 值更低表示結果更好,加粗的是每一行中最好的結果。
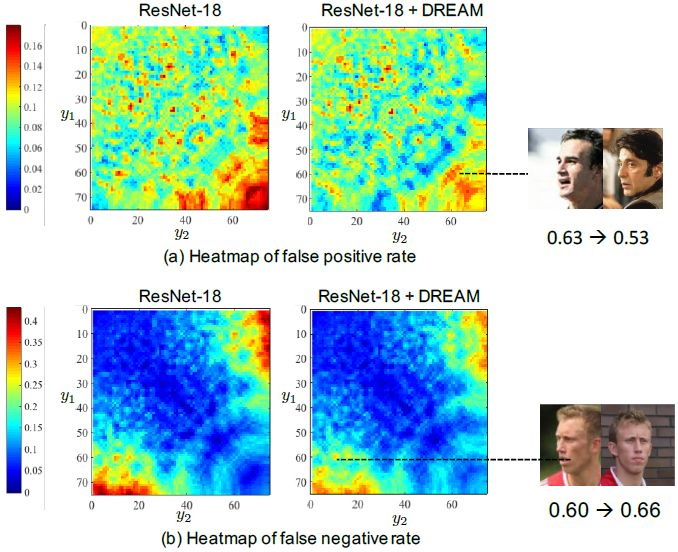
圖 6:在偏航空間用樸素 ResNet-18 和 ResNet-18+DREAM 預測得到的假正類率和假負類率間進行的比較。(a)和(b)表現了用不同偏航角(y_1,y_2)成對人臉數據預測得到的假正類率和假負類率的熱力圖。0.63→0.53 的意思是使用 DREAM 後,人臉偏轉角度的餘弦相似度從 0.63 降到了 0.53。
論文:Pose-Robust Face Recognition via Deep Residual Equivariant Mapping

論文鏈接:https://arxiv.org/abs/1803.00839
摘要:深度學習的發展使人臉識別取得了非凡的成就。然而,現在的許多人臉識別模型識別側面的性能,尤其相較於識別正面,表現仍有不足。主要原因之一在於訓練數據中正面數據和側面數據分佈不均勻——正臉數據比側臉數據要多得多。此外,由於存在姿態的大範圍變化,幾何學意義上的不可變也是模型學習深度特徵表示的難點之一。在本研究中,我們假設在正臉和側臉間存在固有的映射關係,因此,在深度表示空間中可以通過等變映射在正臉和側臉間建立聯繫。在構建映射的過程中,我們建立了新的深度殘差等變映射(DREAM)模塊,該模塊可以自適應地在輸入深度特徵表示中添加殘差連接,使側臉表示轉換爲標準姿勢,以簡化識別。對許多強大的深度網絡而言,包括 ResNet 模型,DREAM 模塊在無需增強數據中側臉部分的情況下,大大增強了模型在側臉識別方面的表現。該模塊易於使用,而且運行中計算開銷較少。