
「Deep Learning」這本書是機器學習領域的重磅書籍,三位作者分別是機器學習界名人、GAN的提出者、谷歌大腦研究科學家 Ian Goodfellow,神經網絡領域創始三位創始人之一的蒙特利爾大學教授 Yoshua Bengio(也是 Ian Goodfellow的老師)、同在蒙特利爾大學的神經網絡與數據挖掘教授 Aaron Courville。只看作者陣容就知道這本書肯定能夠從深度學習的基礎知識和原理一直講到最新的方法,而且在技術的應用方面也有許多具體介紹。這本書面向的對象也不僅是學習相關專業的高校學生,還能夠爲研究人員和業界的技術人員提供穩妥的指導意見、提供解決問題的新鮮思路。
面對着這樣一本內容精彩的好書,不管你有沒有入手開始閱讀,我們AI 研習社都希望藉此給大家提供一個共同討論、共同提高的機會。所以我們請來了曾在百度和阿里工作過的資深算法工程師王奇文與大家一起分享他的讀書感受。
分享人:王奇文,資深算法工程師,曾在百度和阿里工作,先後做過推薦系統、分佈式、數據挖掘、用戶建模、聊天機器人。「算法路上,砥礪前行」。
「Deep learning」讀書分享(一) —— 第一章 前言 Introduction

大家好,這次給大家講的是「Deep learning」這本比較有名的書。內容比較多,一共20章、600多頁。我們一步一步來,先講第一章前言。這一部分主要是深度學習的一些基本介紹、一些發展歷史。可以看一下這個封面,一幅漂亮的風景畫,紐約中央公園遍地盛開的杜鵑花,仔細看有點不太正常,對了,這就計算機生成的,確切的說,是Google deepmind團隊的傑作——夢幻公園。下面有個鏈接就是麻省理工的書籍的開源地址。第二個地址就是北大的張志華團隊貢獻的中文版,鏈接大家也可以自己去github上找。

關於我,我是11年碩士畢業,在BAT裏面工作了有六年多,是一個普通的工程師,也沒有多高的水平。我之前一直做數據挖掘、機器學習、大數據這一塊,去年接觸到深度學習,比較感興趣,轉崗到阿里雲,做過半年的聊天機器人。所以也是一個新手、一個菜鳥,然後實戰經驗也不是很多,能力也一般。這次分享不會保證會講的很好,但是我會盡力。
爲什麼要做這個分享?第一個是希望學習,第二個的話是希望借這個分享給我自己施加壓力,因爲我本身是在學習上也是有些惰性的(這本書打印版買了大半年,啃不動)。第三,這本書其實量挺大的,有600多頁,單憑我一個人的力量可能還不夠,所以希望有更多的人加入進來,一起分享。
另外再着重強調一點,現在是互聯網時代,信息氾濫,我們見到的各種資訊浩如煙海,看起來很多,但很容易碎片化,東一榔頭西一棒子,不成體系,導致消化不良。所以,真想的學好一門技術,最好還是要啃磚頭,這種方式是最笨,但是最紮實的。有個簡單的方法,可以驗證一門技術的掌握程度,那就是看多少書。啃的書越多,基礎就越紮實,視野就越廣。

先給大家介紹一張珍藏已久的圖,我把這張圖放在了自己的Github主頁上,時刻提醒自己,注意學習方法。這個圖說的是學習一門新技術,從剛開始接觸瞭解,到大概一週後,不同的傳遞方式下,知識的留存率分別是多少。
先看第一種:聽講,也就是大家現在的狀態,你們聽,我講。這個留存率大概只有5%,就是說你今天聽完以後,到下週我講了什麼你可能只記住5%,可能只是幾個概念「深度學習」,或者是我放了幾張圖片、放了一個gif比較好玩,或者說了一句比較有意思的話,你可能只記住這些,這個留存率才5%;如果你們聽完後,再接着看書、看其他的視頻資料、看別人演示,那麼這個留存率充其量只到30%;再到下面主動學習這一部分呢,如果你學完之後跟別人討論,就是50%;然後再動手去寫代碼的話,那就75%。最後也就是我現在處的位置90%,這一步,老實說,挺難的(從讀書,查資料,消化理解,到做ppt,平均每個章節花費我4-8小時,甚至更多時間)。就如果大家真的想學深度學習,建議自己嘗試着給別人講,當然最好能夠加入進來,一起分享(贈人玫瑰,手留餘香)。(笑)
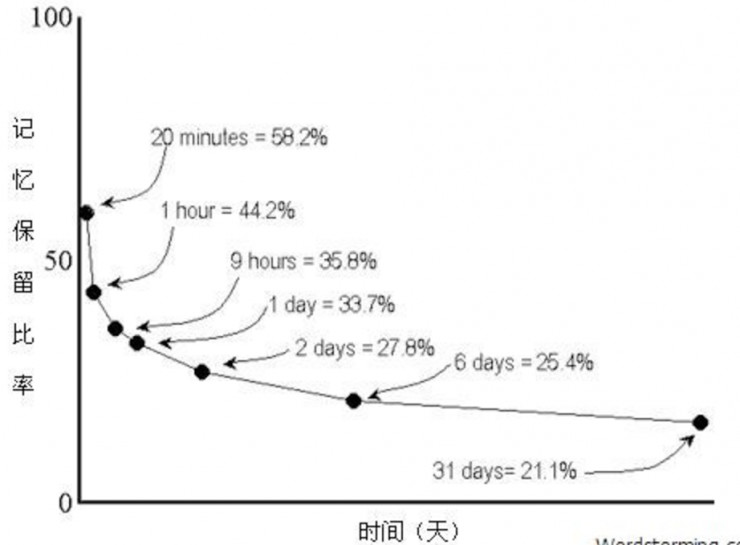
(注:另一個維度,艾賓浩斯遺忘曲線顯示接觸信息後,20min、1h會急劇下降到58%,一週後25%,感覺過高,細節大家可以去查查)
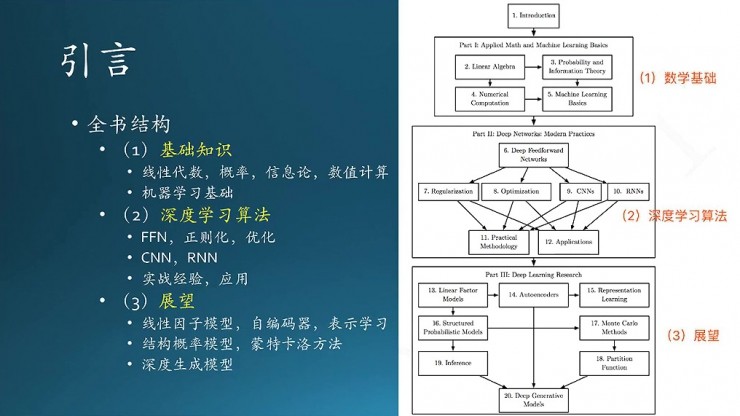
這個圖右邊是本書的結構圖。這本書跟其他書還不太一樣,剛開始就給出一張圖,總體的描述一下每個章節是什麼內容,章節和章節之間的關係,這個非常好,有利於我們形成全局觀。
圖裏面主要分成三部分,第一部分是數學基礎,涉及一些數學基礎和概念,還有機器學習基礎。數學涉及線性代數、概率論、信息論、數值分析,還有少量的最優化。
第二部分是深度學習基本算法。這個算法主要是幾種典型的神經網絡,從DFN,也就是深度前饋網絡,開始,接下來分別演化到了怎麼用正則、怎麼優化。還有下面一部分的CNN,它是前饋網絡的一種擴展,其實,RNN也是前饋網絡衍生出來的,當然CNN是絕對正宗的前饋網絡。接下來是實踐的方法論,就是作者平時總結出來的一些實踐經驗。
三部分就是更加深層次的內容,涉及線性因子模型,編碼器。這一部分非常重要,關係到Hinton的RBF,還有多個RBF堆疊形成的鼎鼎有名的DBN。接下來有表示學習、蒙特卡洛方法、結構概率模型、深度生成模型,也就是最近老出現的,那個叫GAN的,生成對抗網絡,很厲害的樣子。

右上角是這個章節的目錄。實際上書上的內容不多,我會加入自己的一些解釋,把書的結構做一下調整,相當於是重構,這樣大家理解起來更方便,這也算是一個本地化的過程。
新結構是這樣的,第一,介紹下什麼是深度學習;第二,跟機器學習什麼關係;第三,神經網絡的歷史;第四,深度學習爲什麼現在這麼火;第五,深度學習能做什麼。總體思路就是,只提一些感性的認識,而不會去講具體的細節。如果大家想進一步瞭解,請踏實看書,學知識不要偷懶,不要偷懶,不要偷懶(今天偷的懶,明天會加倍償還,這個時代在加劇懲罰不學習的人)。

什麼是深度學習?書裏面提到一句話「AI系統必須具備從原始數據提取模式的能力」,這個能力指的是機器學習。算法的性能在很大程度上是依賴於數據表示的,也就是「表示學習」,這是ML裏的一大方向。
傳統的機器學習是怎麼做的呢?主要是依賴於人工提取的特徵,比如,常用的方式有SIFT,還有HoG、Harr小波等等,都是人工經驗總結出來的。這幾個特徵挺強大,霸佔了圖像處理幾十年,但問題是,擴展起來很不方便。深度學習跟傳統機器學習相比,最明顯的區別就是,把這些人工提取的過程都自動化。
回過頭來想想,什麼是深度學習?這是我的理解,黃色字體的標記的部分,來源於傳統的神經網絡,也就是聯結主義(機器學習,它有很多方法,其中有聯結主義),傳統神經網絡就是屬於聯結主義,深度學習是傳統神經網絡方法的擴展,它是一種延伸,不同的是,用了深度結構,多個簡單的概念逐層抽象,構建複雜的概念,同時自動發現、提取分佈式特徵,注意,有個分佈式。最後學到一個好的模型。深度學習這個概念是Geoffery Hinton 2006年首次提出的。
深度學習的兩個重要特點,第一個是特徵自動提取,傳統信息學習裏面那一套非常複雜的特徵工程都不用了;第二,逐層抽象,主要通過深度結構來實現。
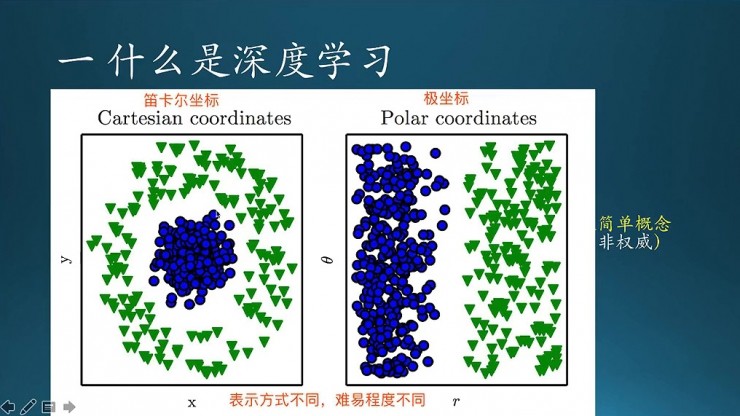
這個圖說的是什麼是表示學習,不同的表示學習會有什麼樣的表現。
圖中就是兩個分類,這個圓形的和倒三角的,分別對應兩種類別。如果採用簡單的線性模型,顯然是分不開的。但是隻要經過某種變換後,比如從笛卡爾座標系變到極座標系,畫一條垂直的直線就輕輕鬆鬆的分開了。所以說,數據集的表示方法不同,問題的難易程度也不同。

這張圖說的是,深度學習是怎麼通過深度結構解決問題的。底層的是一些像素,這裏是三個像素,只取了三種顏色。當然這張圖有點誤導,看起來好像就只用這三種顏色,就能完成圖像分類;實際上不是的。底層對應的是整張圖片,一層一層,由下往上,這是一個層級抽象的過程;第二層是根據底層像素連接起來組成一些線段,或者是複雜一點的邊緣,再到上面一層,形成局部的輪廓,就是一個角或者一些輪廓線。再往上層抽象,是變成了物體的一部分、或者整體,最後,就能看到近似是一個人了。
這個過程說的是,深度學習是通過一些深度結構進行逐層抽象,變相的把問題一步一步地簡化。
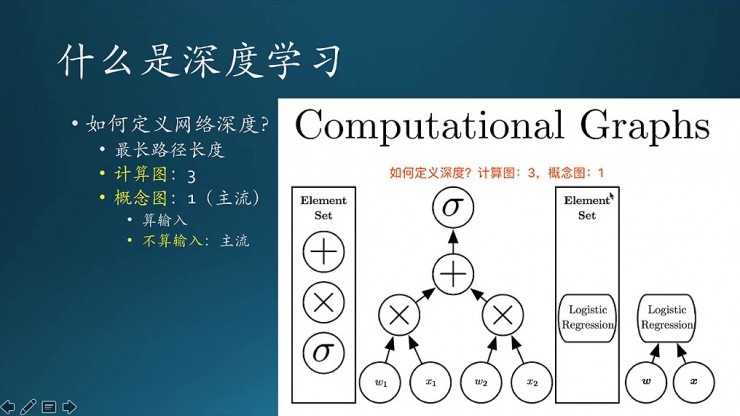
既然是深度學習,那麼首先就要問一句,到底什麼是深度,怎麼定義這個深度?
先看右邊這張圖,這是一個計算圖,也就是一個DAG圖,描述一個計算任務的前後經過。實際上這個任務是傳統機器學習裏面的一種方法,叫邏輯迴歸,比如說,輸入了一個樣本,有兩個特徵X1、X2,分別乘以裏面的權重W1、W2,乘起來,再累加求和,然後套一個sigmoid激勵函數,本質上就是一個變換。這個簡單的計算過程,可以用左邊的圖描述出來,這只是一種描述方法;右邊也是另一種描述方法。區別是,右邊是邏輯概念意義上的概念,而左邊是計算步驟上的描述。
左邊的描述方式,網絡的深度是3,注意,第一層不算。右邊這個描述方式,只有1層。書裏面說了,這兩種概念描述都是對的,就看你喜歡哪一種。通常情況下,我們是以右邊這種爲基準。按照邏輯概念劃分時,又可以繼續細分,標準就是要不要包含輸入層。

看這張圖,這個是input,就是傳統網絡,一提到神經網絡,基本都會提到這樣的結構,一個輸入,再加上隱含層,再加上一個輸出層。隱含層可以有多層。這個輸入,有的地方不算層級,有的算,通常情況下是輸入是不算的,這個就算是一個兩層的網絡
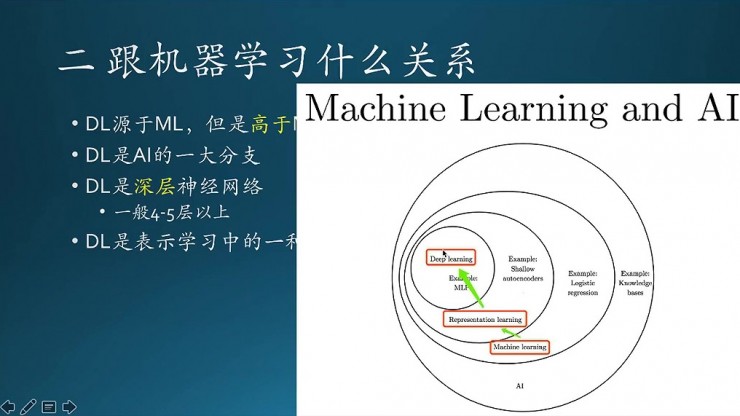
這塊就說一下深度學習跟機器學習之間有什麼關係。深度學習源於機器學習,但是高於機器學習。圖裏第二個是機器學習,DL是AI的一大分支,AI 還有其他的方法,這個只是其中的一個分支而已。
跟傳統神經網絡相比,深度學習的深度體現在複雜的網絡結構上。那麼怎樣才叫複雜呢,一般在4到5層以上,因爲傳統的神經網絡是在2到3層,比如BP網絡,兩到三層,超過的話就不好訓練,也訓練不出來,所以基本上只到4到5層左右,不會有太多。
這個是一張韋恩圖,描述的各個概念之間的一些邏輯關係。這個就看的相對直觀一些,最下面的紅框裏是機器學習,然後裏面有一個流派叫表示學習,表示學習裏面又有一個深度學習,就這麼個層層嵌套的關係。
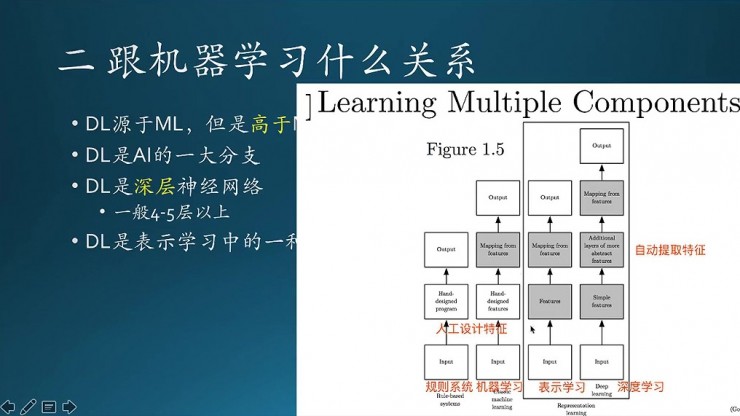
然後這張圖描述的是不同的學習方法,區別體現在組成結構上。最左邊是一個規則系統,希望通過一些邏輯推理去模擬學習的過程,這是最早的一版,人爲設計的一個程序,輸入數據,根據一定的規則,得到一個輸出。它比較簡單,中間實際上就兩個過程。
接着到下一步傳統的機器學習,有什麼區別呢,在上面它有一個特徵映射。
然後再到表示學習。表示學習的方法裏面分成兩部分,左邊一個,還有右邊一個。左邊一個跟之前相比的話,在特徵工程上會花了不少精力,特徵工程非常複雜,依賴經驗,人力投入大。深度學習是表示學習中的一種,在它的基礎上做了一些優化,也算是一個變革,區別是在於多了這一部分:自動提取特徵。
這是幾種歷史上的不同的學習模型在基本的流程上面的差別。

這一部分講下神經網絡的發展歷史。一言以蔽之,神經網絡命途多舛,先後經歷了三次浪潮,也叫三起兩落(鄧爺爺三起三落)。這個第三落現在還不清楚,有人可能會問,深度學習這麼火,怎麼可能衰落?這個真不一定,前兩次浪潮之巔上,大家也是這麼想的。第一次是在40年到60年左右,起源於控制論,主要是基於那些規則的方法來做。控制論時代,誕生了第一個人工神經元。神經元看着挺像現在的樣子,但就一個神經元,沒有什麼層級結構,就是多個輸入得到一個輸出,要求和、再sigmoid,產生一個輸出,就是個神經元而已。注意,當時,神經元裏面的權重是人工設置的。後來Hebb學習法則指出權重是可以學習出來的。於是感知器降臨,跟之前的神經元相比,除了有多層結構,還有權重從人工設置變成了自動化。感知器的網絡結構一般2到3層,也就是傳統的前饋網絡。不過,感知器誕生沒多久,麻省理工的AI 實驗室創始人Marvin Minsky就發現了這種結構的要害,專門寫了一本書叫「Perceptron」,直指感知器的兩個核心問題,第一個就是連簡單的非線性問題都解決不了,第二,非線性問題理論上可以通過多層網絡解決,但是難以訓練(在當時基本不可能)。這個非線性問題就是就是數字邏輯裏的異或門。他在書裏提到,異或門是神經網絡的命門。果然,由於這兩個問題直指感知器要害,再加上Marvin Minsky強大的影響力,許多研究者紛紛棄城而逃,放棄神經網絡這個方向,直接導致了第一次寒冬。這個寒冬持續時間很長,長達二三十年。
第二次是在86年左右,聯結主義時代。1974年,反向傳播算法第一次提出,但由於是寒冬,並沒有受人重視,直到1986年,Hinton重新發明了BP算法,效果還不錯,於是迎來了第二次興起,大家又開始研究神經網絡。緊接着,又出來一個新的模型,也就是Vpnik的支持向量機(PGM也誕生了。這名字看起來很奇怪,爲什麼帶個「機」字?因爲經常帶「機」的神經網絡太火,加這個字是爲了更好的發表)。跟近似黑盒的BP相比,SVM理論證明非常漂亮,更要命的是,支持向量機是全局最優解,而神經網絡它是局部最優,於是,BP被SVM打趴了(也算是SVM的復仇吧),神經網絡進入第二次寒冬了。
第三次是2006年,Hinton 坐了十多年冷板凳,潛心研究神經網絡,終於提出了自編碼和RBM,網絡初始權重不再隨機,而是有了更高的起點,再結合pre-training和fine-tune,解決了多層神經網絡的訓練問題,同時提出了深度學習這個概念,標記着深度學習的正式誕生(Hinton是當之無愧的祖師爺)。這股熱潮一直持續至到現在,大火到現在已經燒了十幾年,越來越旺,甚至要滅掉機器學習了。什麼時候會熄滅?這個真說不清楚。。。。
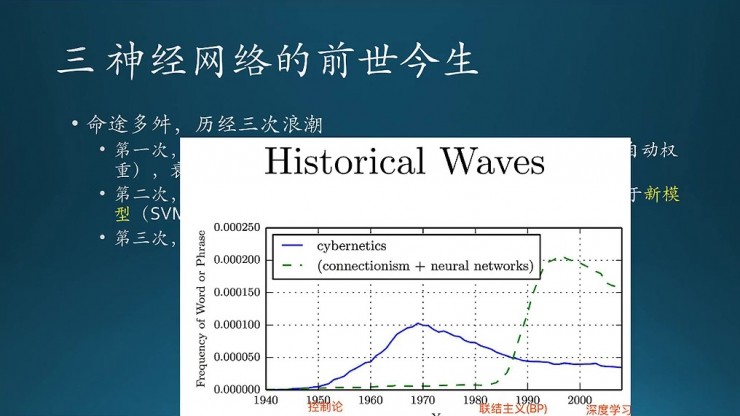
這部分歷史書裏面也有簡單介紹,看這張圖,大概是分成三個階段。我找了一些別的資料,讓大家看得更加直觀一些。
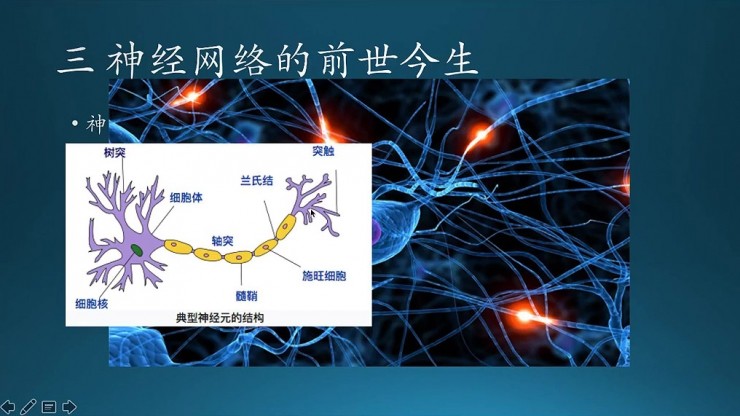
底圖的是神經網絡的一個電腦模擬圖,不同網絡連接起來,看起來就是很複雜很複雜。但是,再複雜也是有簡單的神經元組成。這是一個神經元,生物上一些術語,這些概念大家也都清楚。核心部分就在於神經元在突觸之間傳遞信息,從一個神經元到另外一個神經元。兩個神經元之間有電位差,超過一定閾值時,就釋放化學信號,神經遞質。信息傳遞的過程,從一個神經元到另外一個神經元。
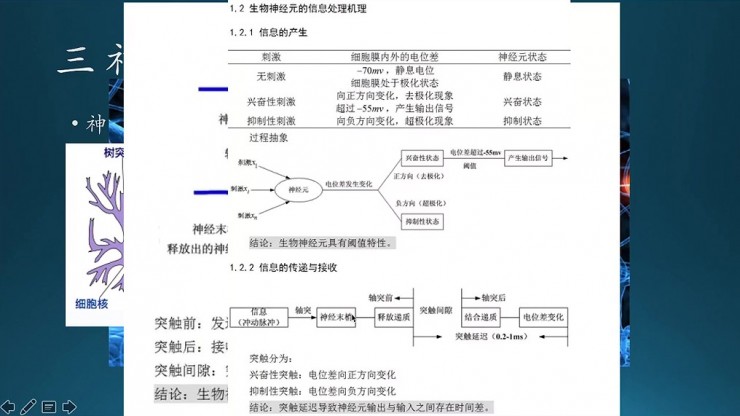
能不能用數學模型去模擬這個過程?這個是進一步的簡化,就是三個神經元刺激傳達到一個神經元,累加,電位差發生變化之後,然後出來兩種結果,一種是興奮,一種是抑制,它是兩種狀態。再往下看是信息的接收與傳遞過程,大家可以看一下。
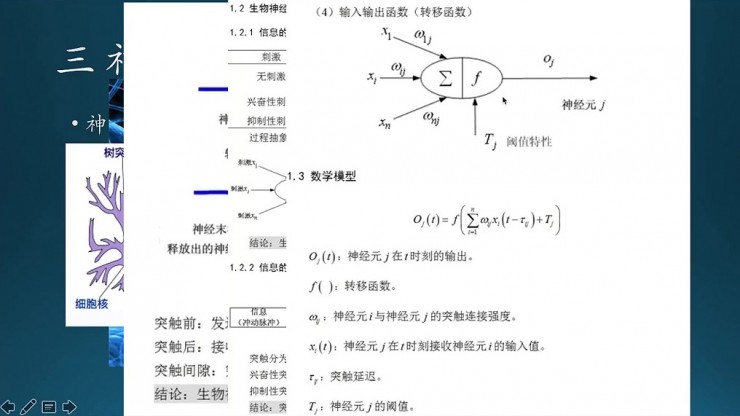
接下來就到了數學模型,模擬的就是神經元的結構。橢圓形的這一部分就是一個神經元,然後它跟上面有N個連接,每個連接的強度不同,對應於神經元的粗細;也就是這裏面的W1j到Wij的權重,然後再做一個累加求和,再加激勵函數處理,之後卡一個閾值,然後決定是不是要輸出。
這是數學模型上最根本的模擬,然後變過來就是這樣一個公式。
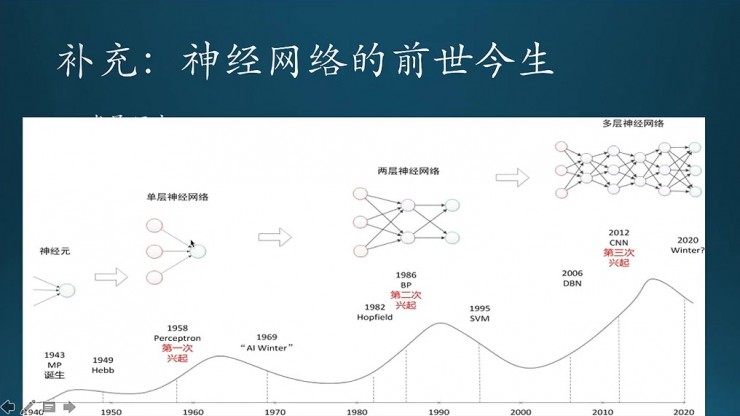
現在看一下他一些歷史。這張圖比書裏面那張圖更加詳細。
這三次熱潮,第一次是在58年,感知器誕生,這是第一次興起;第二次BP網絡誕生;第三次就是CNN和DBN的誕生,分別是Yann LeCun和Hinton兩個人提出來,就導致了第三次興起。它在網絡結構上的差別,第一個是單個神經元、到單層的神經網絡,中間還有一個BP,BP過程加上了2到3層,會比這個更加複雜一些,最後到深度學習,他的層數是很多的,遠不止前面的2到3層。
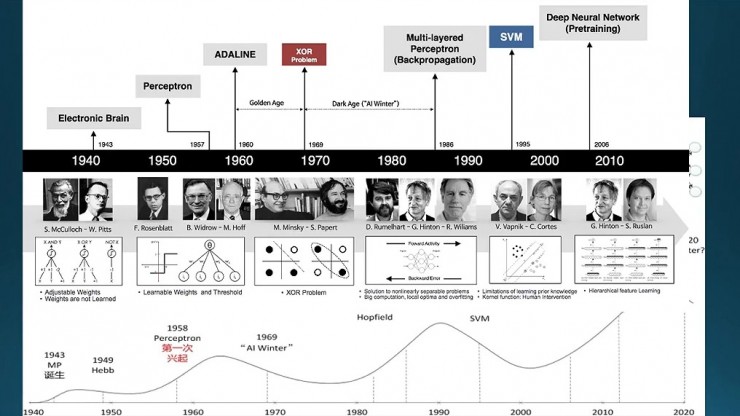
從這張圖上面我們可以對應到具體每個時期是哪個人。第一部分是基於一些邏輯推理的方法,最開始的一個神經元誕生是他們兩個人提出來的,MP模型(注意這不是multilayer perceptron,而是兩個人名的簡稱,叫M-P更準確),可以解決與或非問題,控制論流行下的電子大腦時代。再到57年左右是感知器誕生,MLP,它跟之前的區別是有多個神經元,W1和W2的權重是可以自動訓練的(基於Hebb學習法則)。這裏有個問題,叫異或,這就異或門,也就是異或運算,邏輯運算的一種,類似的有與或非,而異或是難以用線性模型解決的。這個異或門就是神經網絡的命門。圖上面靠左的人就是Marvin Minsky,他寫的書就直接導致了第一次寒冬。
然後是多層的感知機,也就是用了最開始的那個BP神經網絡。這是在74年左右,就是BP神經網絡誕生。那個時候美國和蘇聯撤走了神經網絡相關研究經費,好多雜誌甚至都不接收神經網絡的論文,所以BP網絡誕生的時候是沒有什麼影響力。
接下來是Hinton,他把BP重新設計了下。然後,接下來是支持向量機誕生,剛纔提到一個它是全局最優解,解決問題比BP看起來更加漂亮,所以到這個時候就第二次寒冬來了。就圖上這個過程,跟剛纔總體的經過是一樣的。
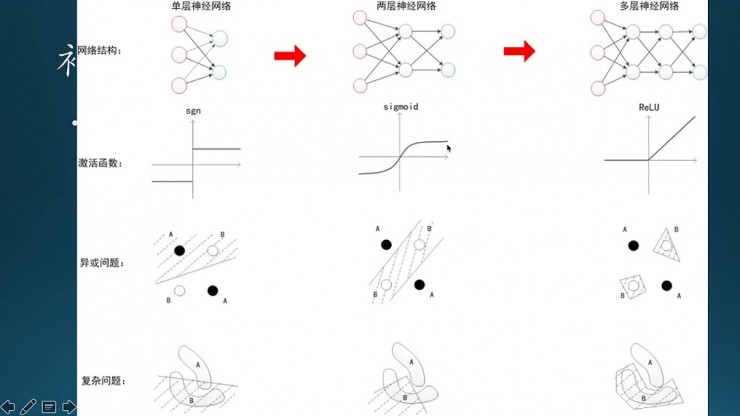
這是幾個階段,第一個是單層網絡,第二個兩層,第三個多層。這三層網絡在激活函數、異或問題和複雜問題上有所不同。像單層網絡因爲只有兩種狀態,一種激活或者抑制,所以是一個符號函數,函數值是1或者-1,異或函數解決不了,複雜問題也解決不了。
到了兩層網絡的時候,它的結構比之前複雜了,激活函數變了,不再是符號函數,中間是sigmoid。這個時候異或問題可以解決,但是複雜問題解決不了。到了多層網絡,也就是現在的深度學習,激活函數主要是ReLU,比之前的sigmoid要簡單,異或問題可以解決,複雜問題也可以解決。
所以現在深度學習模型中的激活函數主要是ReLU,而不是之前sigmoid。其實很早之前,大概是八九十年代,ReLU就已經出現了,只是當時人們選神經網絡激勵函數時,有一種偏執的迷信,sigmoid這樣的激勵函數,處處可導、連續、數學模型也漂亮,而ReLU很顯然在零這個點是一個突變,是有問題的,不可導,所以看起來不漂亮。儘管它出來比較早,但是不怎麼用它,直到後來,然後在深度學習裏面經過多次的訓練之後發現它的效果比sigmoid要好得多,因爲sigmoid存在一個大問題,飽和,往正無窮或者負無窮這兩個方向看,函數值趨近於1或者-1,沒什麼反應了,就只對就在0附近的值敏感,對非常大的或者非常小的點,淡定的很,不予理睬。這就是飽和問題。實際上,代價函數的梯度必須足夠大,而且具有足夠的預測性,指引學習方向,而飽和函數破壞了這一目標。sigmoid在小數據上表現較好,但是大數據集不佳,ReLU則由於提升系統識別性能和仿生的本質(神經元信號原理),在大數據集情形大顯神威,重要性甚至超過隱含層權重。
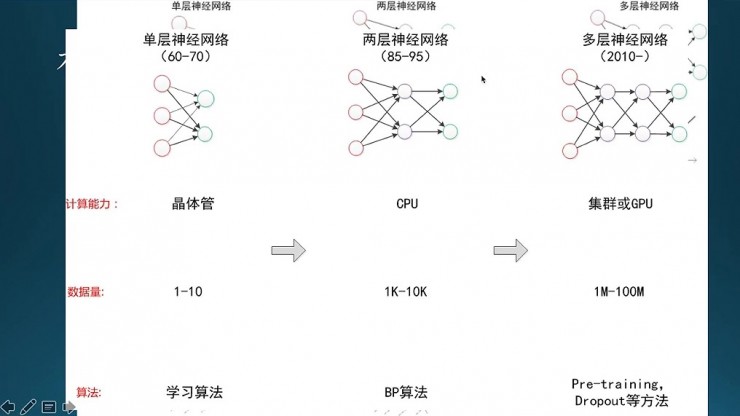
剛纔是網絡結構上變化,這個是在晶體管,就是在計算能力,還有數據、算法這三個因素,就直接導致深度學習的興起。
第一個因素計算能力。計算能力主要是硬件層的,單層神經網絡是在晶體管時代的,數據量也比較少,學習算法就是基本的一些簡單的推理;到了兩層神經網絡,主要是用CPU來算,它的數據量大概是一千到一萬,數據量是急劇增長的,算法主要用的BP。到了多層網絡時候是主要通過集羣或者GPU,甚至到現在還有更高級的TPU,數據量也是急劇的膨脹。它的訓練方法跟BP相比有不同,這裏面用的Pre-training,還有drop-out,主要防止過擬合的。
這三種不同階段,它的網絡結構、它的計算能力、數據量算法都是不同的。
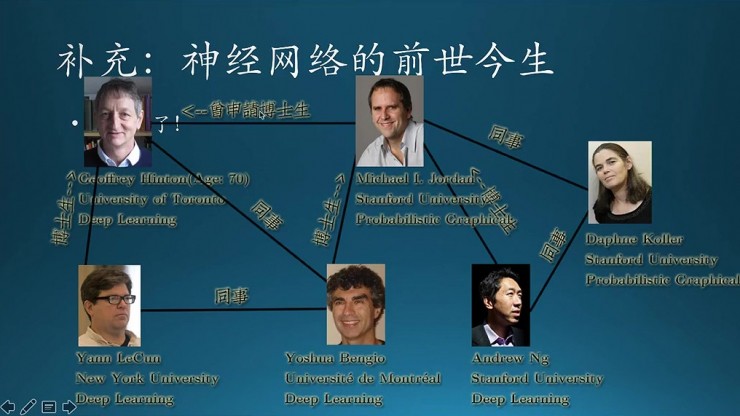
這個說一下現在深度學習裏面比較厲害的大神,Hinton絕對是這個領域的祖師爺;Yann LeCun主要在CNN上面貢獻非常多;Bengio主要是在RNN這一塊。這裏面還提到一個人是Jordan,最近好像加入阿里了吧,右邊這個女的是專門研究概率圖的(跟支持向量機一起興起)。還有吳恩達,主要這四個人(不一定準確,只是四王天王叫起來比較順口,O(∩_∩)O哈哈~)。
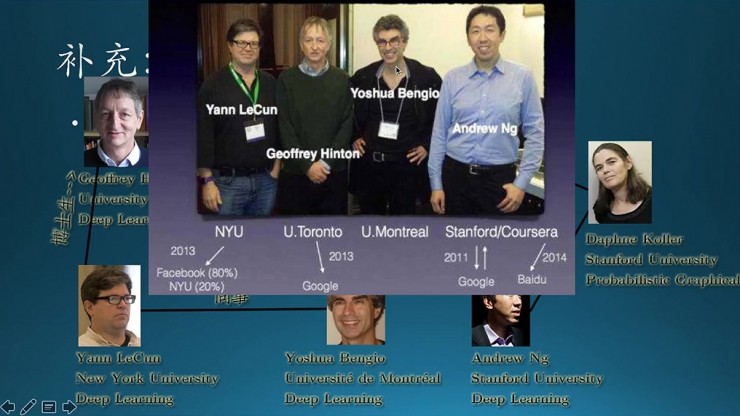
隨着深度學習的大紅大紫,工業界一直在想辦法爭奪人才,把報得上名字的大神都找了個遍,圖上這些大神一個一個的也落水了,到工業界去研究了,只有這個Bengio還一直處於中立狀態,不過最近的消息好像他也加入了工業界。本書的作者是 Ian Goodfellow,GAN的發明人,Bengio是他的老師。
還有大神們的衆多門生,相繼發明了word2vec和fasttext,李飛飛及高徒andrej karpathy。。。
關係錯綜複雜,但數來數去也就那麼幾個人,「近親繁殖」現象嚴重。

這一部分是簡單介紹一下前饋網絡的一些基本結構。它每一種網絡實際上是模擬某一個複雜的函數,它的目標是要學習每一層連接裏面那個權重。權重達到了一個比較好的狀態,就相當於這個函數已經達到了一個比較好的近似。書裏面強調了一點:神經網絡並不是目的,它不是爲了完美的模擬大腦,而只是實現一種統計的泛化,類似於一種函數的近似機。因爲人腦是非常複雜的,現在的網絡結構遠遠達不到人腦的這種狀態。
知名的網絡結構主要兩種,第一種是前饋,也就是說信息從一層一層往下流動,一路向前不回頭(不算誤差反向傳播)。以CNN爲例;第二種是反饋,就把上一次訓練的狀態留下來,作爲本次的一個輸入,它是前饋的一種擴展,特點是訓練時會把上一次訓練結果拿過來用,再決定下一步的訓練。典型例子就是RNN,一邊走一邊回眸一笑,繼續往前走。

深度學習之所以興起有三個因素:海量的數據、計算能力、算法的突破。算法裏面主要有幾個RBM、BP,這是優化版的BP,還有一些訓練方法pre-train,加上一些激活函數的變化。
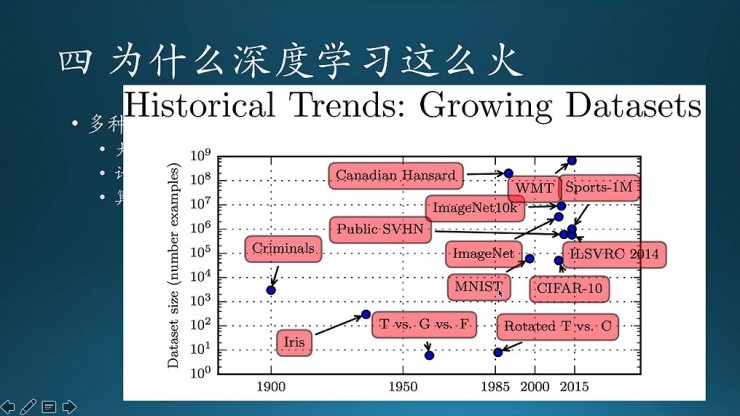
這個圖說的是數據。最開始的機器學習經常提到的Iris數據集,量級纔在這個地方很小;後來到MNIST,量級在10的4次方左右;然後到ImageNet,到最後越來越大,就是說現在深度學習面臨的問題會比之前複雜的多,數據也複雜得多。
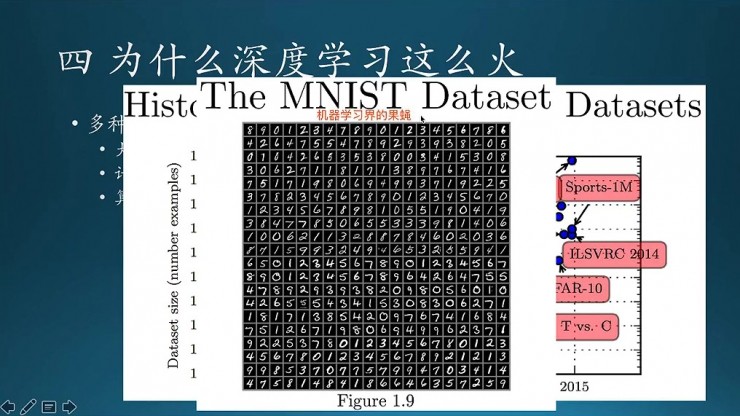
這個是MNIST的一個示例。Hinton給它的一個形容是機器學習界的果蠅,就像生物實驗裏面動不動研究一些遺傳實驗,犧牲了無數的果蠅。CNN裏面也會經常拿它做練手,這是CNN裏面入門的一個helloword(前饋神經網絡的helloworld是異或問題)。
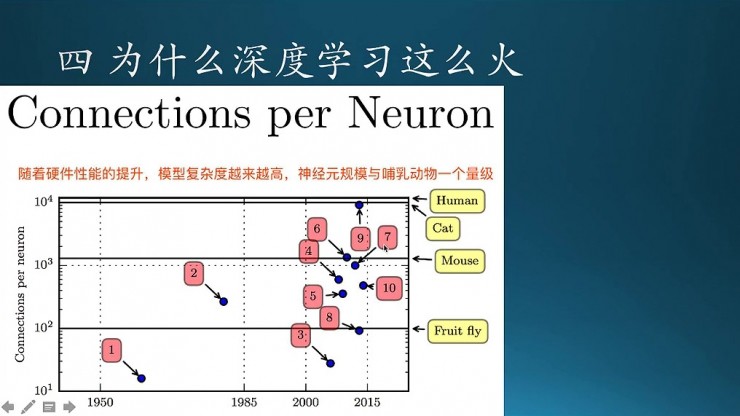
這個是,隨着硬件性能的提升,模型的複雜度也越來越高。這個模型的複雜度就類似於大腦的複雜度,像果蠅的大腦其實相對於哺乳動物來說,沒有那麼複雜。所以大腦越複雜,它的連接的數目就越多。果蠅它的量級就比較小,但哺乳動物會比較高,當然人是最高的,也有可能有比人更高級的生物,只是我們不知道而已(比如普羅米修斯?)。
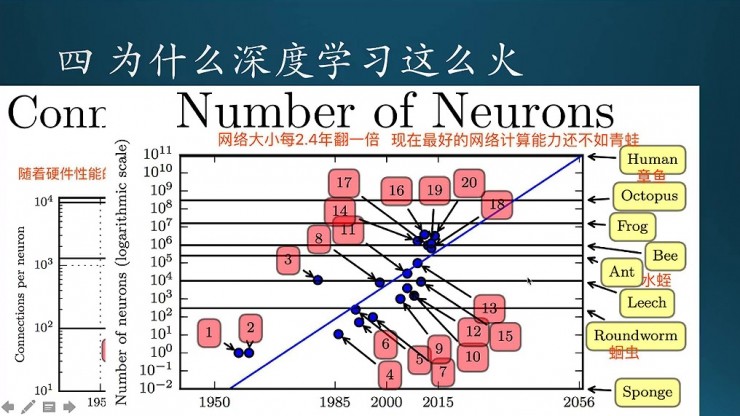
現在隨着時間推移的話,神經網絡也就會不斷的升級,基本上是每隔2.4年就會翻一倍。即便是現在最強的神經網絡,他的計算能力還比不上一隻青蛙。(據說百度大腦達到2-3歲嬰兒的水平)

接下來就是神經網絡能做什麼,它現在的應用面已經非常廣了,主要分爲圖像、語音、文字、遊戲、無人駕駛等等,大家也都聽的很多了。

圖像領域的,比如給一張圖像,讓機器識別圖像裏面的內容,比如人、自行車、石頭等等,每個結果都給出一定的置信度。圖像領域是深度學習威力最大的領域,傳統方法基本都敗北,翻天覆地。語音其次,NLP最難,NLU不好解,尚在改變過程中。

再比如好玩一點的,國民老公和「先定一個小目標一個億」王健林,能夠根據圖片識別出來是哪個人。還有明星的,經過整容以後臉都長的一個樣,但是機器識別就能辨別出來,比如這是王珞丹和白百合。
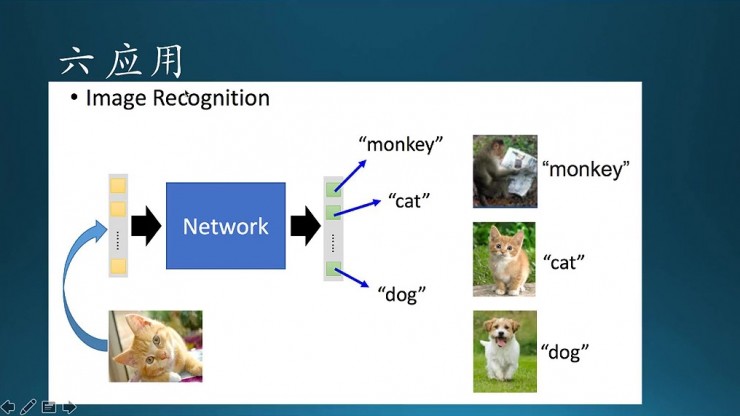
這裏着重提一下圖像領域的應用進展。這是最開始的一版深度學習用於貓狗識別的例子,這個地方是一個多分類。
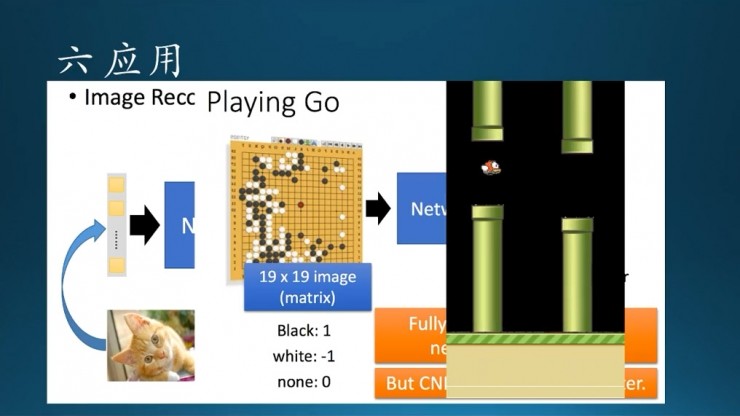
還有AlphaGo,和用CNN實現的玩遊戲Flappy Bird。

圖像識別的發展歷史。沿着時間順序從右往左,2010年以來識別錯誤率是逐步下降的,在2012年左右有非常大的下降。它的原因是谷歌首次使用了深度學習(CNN),直接導致了接近10個點的下降。到了2014年也是谷歌的新一版的CNN,把錯誤率降到了6.7%。再到2015年微軟的殘差網絡,錯誤率降到了3.57%。從數字上看好像沒多大差別,但一方面越往上提升的空間越小,難度越大;第二個,裏面有一個標誌性的里程碑,人的錯誤率是5.1%,而這個時候機器是3.57%,已經超過了,所以這是里程碑式的事件。裏面用的數據集是李飛飛的開源數據集 ImageNet,在2016年的 ImageNet比賽裏面中國團隊就拿下了全部冠軍,今年又拿下了一些冠軍。在圖像識別領域提升的空間不大了,所以今年以後這個比賽已經停止了,或許是已經沒啥提升的空間了。
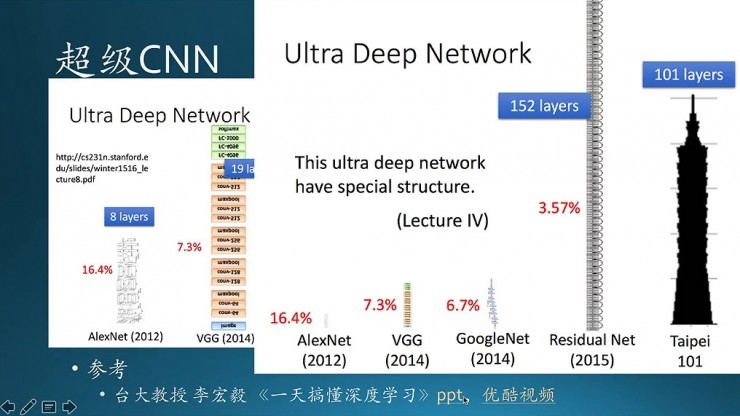
這是一些超級網絡的圖示,最早的是8層網絡,到了19層,再到22層,已經眼花繚亂看不清了。這個PPT是來自臺大的李宏毅,大家可以找一下。
我今天的分享就到這裏,謝謝!
(完)