
俞棟是語音識別和深度學習領域的著名專家。他於 1998 年加入微軟公司,此前任微軟研究院首席研究員,兼任浙江大學兼職教授和中科大客座教授。迄今爲止,他已經出版了兩本專著,發表了 160 多篇論文,是 60 餘項專利的發明人及深度學習開源軟件 CNTK 的發起人和主要作者之一。俞棟曾獲 2013 年 IEEE 信號處理協會最佳論文獎。現擔任 IEEE 語音語言處理專業委員會委員,之前他也曾擔任 IEEE/ACM 音頻、語音及語言處理彙刊、IEEE 信號處理雜誌等期刊的編委。
以下是俞棟演講的主要內容:
大家好,我是俞棟,現在騰訊 AI Lab,是西雅圖研究室的負責人,我的主要的研究方向是語音識別,所以今天我在這裏也給大家介紹一下最近的一些語音識別方向的研究前沿。
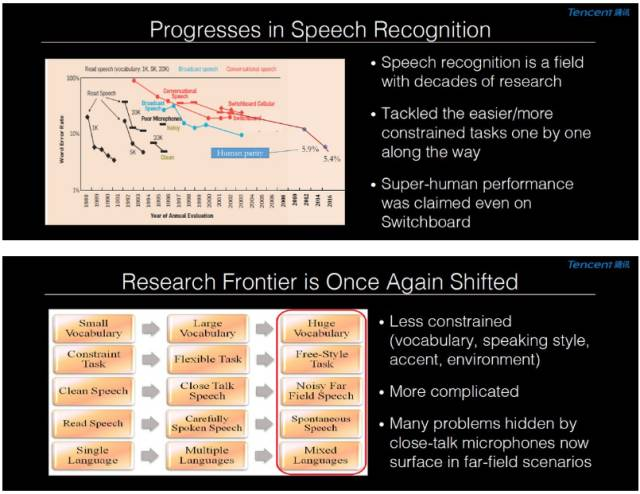
大家都知道語音識別領域有着悠久的研究歷史,在過去的幾十年裏面,研究人員從最簡單的非常小詞彙量的閱讀式的語音識別問題開始,逐漸轉向越來越複雜的問題。現在即便是在以前認爲非常難的自由對話形式的語音識別問題,機器也已經能夠達到甚至超過人的識別水準。不過我們要看到,雖然我們取得了這些進展,但是離真正非常自由的人機交流還有一定的距離。這也是爲什麼我們現在語音識別的研究前沿又往前推進了一步,現在我們研究的問題越來越多地是不對環境、說話的風格、口語做任何限定(不像以前有非常多的限制)。而這些非限定的環境,就使得語音識別難度有了大幅度的增加。尤其在最近的幾年裏面我們發現在真實的應用場景裏,很少有人會願意戴着麥克風,所以現在研究的前沿就從近場麥克風向遠場麥克風改變。
從近場到遠場麥克風的改變有一個很重要的區別,即遠場的情況下,當人的聲音傳達到麥克風的時候,聲音的能量衰減得很厲害。所以近場麥克風很難見到的一些困難,在遠場麥克風裏面就變得非常重要。最著名的就是雞尾酒會問題,本文稍後會對其做一個詳細的介紹。如果這些遠場問題不解決的話,在很多的應用場合,用戶仍然會覺得語音識別並不是很方便。

所以今天在這樣的背景下,我介紹一下最近在語音識別當中的一些前沿的研究方向,主要有四個:
- 研究方向一:更有效的序列到序列直接轉換模型
- 研究方向二:雞尾酒會問題
- 研究方向三:持續預測與適應的模型
- 研究方向四:前端與後端聯合優化
研究方向一:更有效的序列到序列直接轉換模型

如果我們仔細想想語音識別這個問題的話,大家都會看到,語音識別其實就是一個從語音信號序列轉化爲文字或者詞序列的問題。這也就是爲什麼很多研究人員都一直認爲要解決這個問題其實只要找到一個非常有效的,從一個序列到另外一個序列轉換的模型就可以了。
在以前的所有的研究裏面,絕大部分的工作都是研究人員通過對問題做一些假設,然後根據這個假設從語音信號序列到詞信號之間,生成若干個組件,然後通過逐步地轉換,最後轉換成詞的序列。有許多假設在某些特定場合中是合理的,但是在很多真實的場景下還是有問題的。那麼直接轉換這樣序列模型的想法就是,如果我們能夠把這些可能有問題的假設去掉,然後通過數據驅動讓模型自己學習,就有可能找到一個更好的方法,使得這個序列的轉換更準確。這樣做還有另外一個好處,因爲所有的這些人工的 component 都可以去掉了,所以整個的訓練流程也就可以縮短。
序列到序列直接轉換、直接映射這樣的研究目前來講主要有兩個方向:
方向一: CTC(Connectionist Temporal Classification)模型
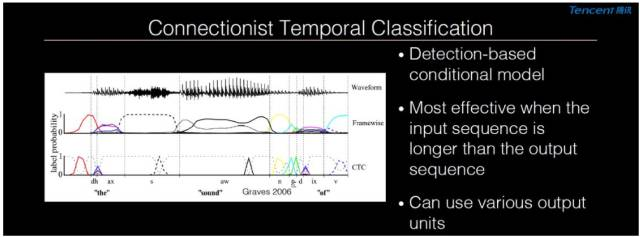
如上圖所示,方向一是 CTC(Connectionist Temporal Classification)模型,從上圖中最下面一行可以看到,在 CTC 模型裏面,系統會一直保留一個內部狀態,當這個內部的狀態提供足夠的信息可以做某一個決定的時候,它就會生成一個尖峯(spike)。其表明到某個位置的時候可以非常確定地推斷到底聽到了哪個字或者哪個詞。而在沒有聽到足夠的信息的時候,只會產生空信號以表明還不能有足夠的信息來判斷是不是聽到了某一個字或者詞。這樣的模型在語音識別問題上是非常合適的模型,因爲它要求輸出序列的長度比輸入序列的長度要短很多。
CTC 模型還有一個優勢,即傳統的深度神經網絡與混合模型一般來說建模單元非常小,但是在 CTC 模型可以相對自由地選擇建模單元,而且在某些場景下建模單元越長、越大,識別效果就越好。
最近 Google 有一項研究,他們在 YouTube 上採用幾十萬小時甚至上百萬小時的數據量訓練 CTC 的模型,發現可以不用再依賴額外的語言模型就能夠做到超過傳統模型的識別率。CTC 模型相對來說比傳統的模型仍會更難訓練,因爲其訓練穩定性還不是很好。
方向二:帶有注意力機制的序列到序列轉換模型
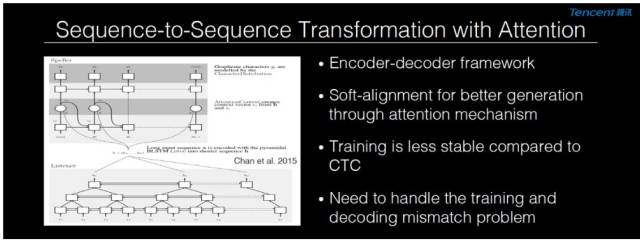
第二個比較有潛力的方向是帶有注意力機制的序列到序列轉換模型(Sequence-to-Sequence Transformation with Attention)。這個模型基本的想法是首先把輸入的序列、語音信號序列,轉換成一箇中間層的序列表達,然後基於中間層的序列表達提供足夠的信息給一個專門的、基於遞歸神經網絡的生成模型,並每次生成一個字、一個詞或者一個音符。現在這個方法在機器翻譯裏面成爲了主流方案,但是在語音識別裏面它還是一個非常不成熟的技術。它有如下幾個問題:
問題 1:訓練和識別過程有很大的不匹配性,在訓練過程中所依賴的信息是準確的、已知的,但是在識別過程中,信息卻是估算出來的,是不準確的。所以一旦錯誤產生以後,這個錯誤就可能會累加到下一個字或詞的生成,所以該方法比較適合只是一個短語的識別,對長的句子效果比較差。
問題 2:該模型和語音識別本身也有不匹配性,這個不匹配是其在進行注意力機制時產生的,因爲注意力可以在不同的位置上移動,但是對於語音識別,下一個詞的 attention 肯定是在前一個詞的 attention 的後面,其有一個持續固定的約束,這個約束在目前帶注意力機制的序列到序列模型裏是不存在的,所以這個模型目前在做語音識別的時候效果非常不穩定。

如何解決這樣的問題而得到更好的結果呢?目前最佳的解決方案就是把 CTC 模型跟 Attention 模型聯合在一起,最基本的想法是因爲 CTC 有持續信息,其詞的生成是根據後面那幾幀的語音信號信息而得出,因此它會幫助 Attention 模型生成更好的 embedding space 表達。結合這兩個方法所最終產生的結果既比 CTC 模型訓練的好,也比 Attention 模型訓練的好,所以這就變成了一個 1+1 大於 2 的結果。

我們稍後會看到,即便把兩種成本函數和模型結構聯合在一起,它的效果與傳統的混合模型相比並沒有太大的長進。所以我們仍然需要解決一些問題。
問題一:在這樣的架構下面,有沒有更好的模型結構或訓練準則,能夠比現有的 CTC 或者 Attention 模型更好。
問題二:我們看到 YouTube 用 CTC 模型訓練的時候,它的效果比用語言模型的傳統方法更好,很大的原因就在於它的訓練集有很多的訓練語料,因此我們可以在裏面訓練非常好的語言模型,所以語言模型和聲學模型是緊密結合在一起的。那麼當我們沒有這麼多的數據時,有沒有辦法也建造一個結構,使得這個語言模型和聲學模型緊密結合在一起。但是當訓練數據不夠多的時候,如果有足夠的文本數據,我們也可以用它來加強語言模型的訓練,使兩個部分能夠相輔相成。
問題三:到底有沒有辦法結合各種語料的數據,因爲一種語料可能數據量不夠多,所以到底有沒有辦法在模型的各個層次上都做遷移學習,這樣的話我們就有辦法可以利用各種語料的數據,整合起來訓練一個更好的序列到序列的轉換模型。
研究方向二:雞尾酒會問題

衆所周知,在非常嘈雜或者多人同時說話的環境中,人有一個非常好的特點,即能夠把注意力集中在某一個人的聲音上,屏蔽掉周圍的說話聲或者噪音,非常好地聽懂所需關注之人的說話聲音。現在,絕大多數語音識別系統無法做到這一點。如果不做特殊處理,你會發現只要旁邊有人說話,語音識別系統的性能就急劇下降。
由於人的信噪比非常大,這個問題在近場麥克風時並不明顯;但在遠場情況下,信噪比下降很厲害,問題也就變得很突出,進而成爲了一個難以解決的關鍵問題。

雞尾酒會中一個相對簡單的問題是語音加上噪聲(或者語音加上音樂、語音加上其他的東西)。因爲你已經知道要關注的語音部分,可以忽略掉其他,所以這個問題就可以從之前的非監督學習盲分類問題,轉換到人爲定製的 supervision 信息的有監督學習問題。
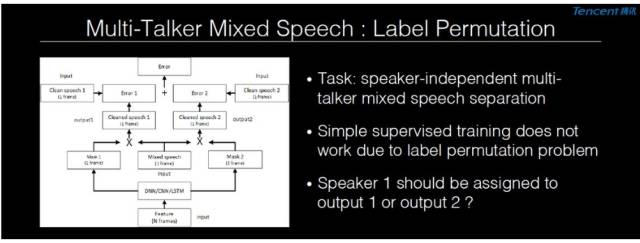
但是有監督學習會在多人說話時碰到困難,這個困難就在於這時你無法輕易地提供 supervision 信息,因爲當麥克風收到信息時,它收到了兩個或者多個麥克風的混合語音,但並不能知道這個混合語音是 A+B 還是 B+A(因爲兩者結果是一樣的)。所以在訓練過程當中,你無法預先知道是把說話人 A 的聲音作爲輸出 1 的 supervision 還是輸出 2 的 supervision。這個問題有一個專門的術語叫做標籤排列問題(Label Permutation Problem),目前它有兩個比較好的解決方案:
方案一:Deep Clustering

假設當兩個人說話時,每一個時頻點都會被一個說話人掌控;在這個情況下,它可以把整個語譜圖分割成兩個集羣,一個屬於說話人 A,一個屬於說話人 B,進而訓練一個嵌入空間表達。如果兩個時頻點同屬一個說話人,它們在嵌入空間裏的距離則比較近;如果屬於不同的說話人,距離則比較遠。所以訓練準則是基於集羣的距離來定義的,在識別的時候,它首先將語音信號映射到嵌入空間,然後在上面訓練一個相對簡單的集羣,比如用 k-means 這樣的方法。這個想法非常有意思,但是同時聚類算法的引入也帶來了一些問題,使得訓練和識別變得相對複雜,也不易於與其他方法融合。
方案二:Permutation Invariant Training
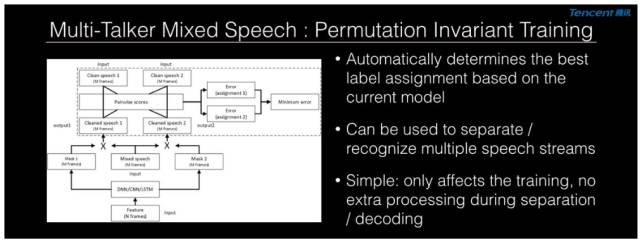
這個想法是因爲我們真正做分離的時候,其實並不在乎它是 A+B 還是 B+A,而只關注兩個信號分離的水準是不是好。在真正做判定的時候,我們其實會專門比較音頻信號,並選擇成本最小的作爲最後判別的分類。這也提醒我們在訓練時也可以這樣做。所以訓練時怎麼做呢?
每次我拿到新的混合語音時,並不預先設定它的 supervision 標籤什麼樣,而是針對當前模型動態地決定當下我的 supervision 應該是什麼樣。由於取 supervision 的最小錯誤率,所以我又在其上進一步優化,它的錯誤率也進一步減小,這是其基本想法。它唯一需要改變的就是訓練的標註分配,其他部分則不用變。所以識別相對簡單,也很容易與其他方法做融合。
那麼我放幾個聲音大家聽一下:
三個說話人:三個人混合的聲音是比較難分離。這個方法的另外一個好處是不需要預先知道有幾個人說話,所以當有兩個人說話的時候,它也能做得很好。
兩個說話人:當有兩個說話者時,第三個數據就沒有輸出,只有保留沉默,所以它有一個非常好的特性:不需要你做特殊處理,輸出結果即分離結果。

但是目前爲止,我們所使用的一些信息只來自單麥克風。衆所周知,麥克風陣列可以提供很多信息,所以:
第一個很重要的問題是如何有效地利用多麥克風信息來繼續加強它的能力;
第二個問題是說我們有沒有辦法找到一個更好的分離模型,因爲現在大家使用的依然是 LSTM,但是其不見得是最佳模型。
第三個問題是我們有沒有辦法利用其他的信息作爲約束進一步提升它的性能。
研究方向三:持續預測與適應的模型
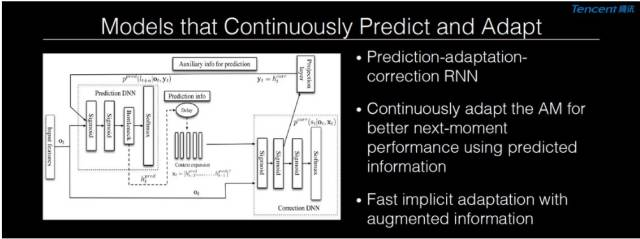
第三個大家關注的研究熱點是能否建造一個持續地做預測(prediction)和適應(adaptation)的系統。我們之前做了一個模型,如上圖所示;它的優勢是能夠非常快地做適應,持續地做預測,然後改進下一幀的識別結果。但是由於目前這個模型迴路比較大,所以性能上還是很難訓練,這和 CTC 模型情況相似。所以我們現在的問題是如何建造一個更好的模型能夠持續地做預測。這種模型需要有哪些特性呢?
一是模型能夠非常快地做適應;
二是可以發現一些一致的規律性,並將其變爲長遠記憶裏面的信息,使得下一次再做識別時會變成穩定的狀態,其他狀態則變成需要適應的狀態;
三是我們有沒有辦法把類似說話者的信息,用更好的方式壓縮在其模型之中,所以當見到一個新說話者時,可以很快地做 適應。
研究方向四:前端與後端聯合優化

第四個研究前沿是出於遠場識別的需要,即如何更好地做前端和後端的聯合優化。這其中包含幾個問題,因爲傳統來講,處理前端信號使用的是信號處理技術,其一般只用到當前狀態下的語音信號信息,比如訓練集信息;而機器學習方法,則用到很多訓練器裏的信息,並很少用到當前幀的信息,也不會對它進行數據建模,所以我們能否把這兩種方法更好地融合在一起,是目前很多研究組織正在繼續努力的一個方向。
另外,我們是否有辦法更好地聯合優化前端的信號處理與後端的語音識別引擎。因爲前端信號處理有可能丟失信息,且丟失的信息很可能無法在後端恢復,所以我們能否做一個自動系統以分配這些信息的信號處理,使得前端更少地丟失信息,後端則這些信息更好地利用起來。
今天的演講就到這,謝謝大家。