作者:張翱,李楠,浦劍,王駿,嚴駿馳,查宏遠
國際知名的人工智能學術會議 AAAI 2018 即將於 2 月份在美國新奧爾良舉辦,據瞭解,阿里巴巴共有 11 篇論文被接收。我們 AAAI 2018 論文專欄,將會對其中的數篇論文進行介紹,同時也歡迎讀者推薦更多優質的 AAAI 2018 接收論文。
本文介紹了阿里巴巴 iDST 與華東師大合作發佈的論文《τ-FPL: Tolerance-Constrained Learning in Linear Time》,該論文提出了一種出了一個新的排序-閾值方法τ-FP。
摘要
許多實際應用需要在滿足假陽性率上限約束的前提下學習一個二分類器。對於該問題,現存方法往往通過調整標準分類器的參數,或者引入基於領域知識的不平衡分類損失來達到目的。由於沒有顯式地將假陽性率上限融合到模型訓練中,這類方法的精度往往受到制約。本文提出了一個新的排序-閾值方法τ-FPL 解決這個問題。首先,我們設計了一個新的排序學習方法,其顯式地將假陽性率上限值納入考慮,並且展示瞭如何高效地在線性時間內求得該排序問題的全局最優解;而後將學到的排序函數轉化爲一個低假陽性率的分類器。通過理論誤差分析以及實驗,我們驗證了τ-FPL 對比傳統方法在性能及精度上的優越性。
研究背景
在疾病監測,風險決策控制,自動駕駛等高風險的分類任務中,誤報正樣本與負樣本所造成的損失往往是不同的。例如,在高死亡率疾病檢測的場景下,遺漏一名潛在病人的風險,要遠高於誤診一名正常人。另一方面,兩類錯誤的損失比也很難量化估計。在這種情況下,一個更加合理的學習目標是:我們希望可以在保證分類器假陽性率 (即錯誤地將負樣本分類爲正樣本的概率) 低於某個閾值 τ 的前提下,最小化其誤分正樣本的概率。可以看到,由於問題的轉換,傳統的基於精度 (Accuracy),曲線下面積 (AUC) 等目標的學習算法將不再適用。
假陽性率約束下的分類學習,在文獻中被稱爲 Neyman-Pearson 分類問題。現存的代表性方法主要有代價敏感學習 (Cost-sensitive learning),拉格朗日交替優化 (Lagragian Method), 排序-閾值法 (Ranking-Thresholding) 等。然而,這些方法通常面臨一些問題,限制了其在實際中的使用:
需要額外的超參數選擇過程,難以較好地匹配指定的假陽性率;
排序學習或者交替優化的訓練複雜度較高,難以大規模擴展;
通過代理函數或者罰函數來近似約束條件,可能導致其無法被滿足。
因此,如何針對現有方法存在的問題,給出新的解決方案,是本文的研究目標。
動機:從約束分類到排序學習
考慮經驗版本的 Neyman-Pearson 分類問題,其尋找最優的打分函數 f 與閾值 b,使得在滿足假陽性率約束的前提下,最小化正樣本的誤分概率:
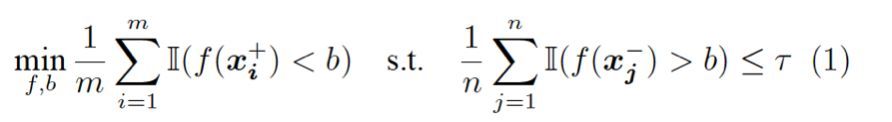
我們嘗試消除該問題中的約束。首先,我們闡述一個關鍵的結論:經驗 Neyman-Pearson 分類與如下的排序學習問題是等價的,即它們有相同的最優解 f 以及最優目標函數值:
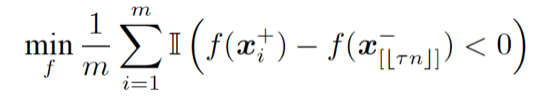
這裏, f(x[j]^-) 表示取負樣本中第 j 大的元素。直觀上講,該問題本身是一個 pairwise ranking 問題,其將所有的正樣本與負樣本中第τn 大的元素相比較。從優化 AUC 的角度,該問題也可看作一個部分 AUC 優化問題,如圖 1 所示,其嘗試最大化假陽性率τ附近的曲線下面積。
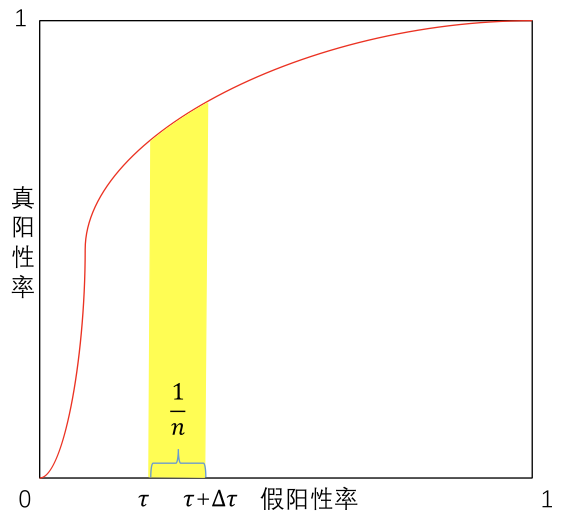
圖 1: Neyman-Pearson 分類等價於一個部分 AUC 優化問題
然而,由於引入了取序操作符 [.],可以證明,即使將 0-1 損失用連續函數替換,該優化問題本身也是 NP-hard 的。因此,我們考慮優化該問題的一個凸上界:
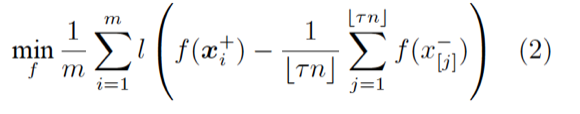
這裏 l 是任意 0-1 損失的凸代理函數 (convex surrogate function)。(2)仍然是一個排序問題,其嘗試最大化負樣本中得分最高的那部分的「質心」與正樣本之間的距離。這個新問題有一些良好的性質:
通過設計高效的學習算法,我們可以在線性時間內求得該問題的全局最優解,這使其非常適合於大規模數據下的場景;
形式上顯式地包含τ,無需引入額外的損失超參數 (cost-free);
最優解 f 有可理論保證的泛化誤差界。
我們也可以從對抗學習 (Adversarial learning) 的角度,給出排序問題 (2) 的一個直觀解釋。讀者可以驗證,(2)與如下的對抗學習問題是等價的:
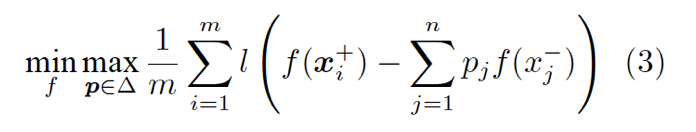
其中 k = τn,且
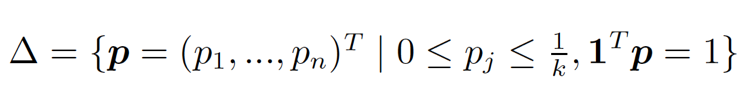
換句話說,排序學習問題 (2) 可以看作是在兩個玩家——打分函數 A 與樣本分佈 B 間進行的一個 min-max 遊戲。對於 A 給出的每個 f,B 嘗試從負樣本分佈的集合△中給出一個最壞的分佈 p,以最小化 A 的期望收益。該遊戲達到納什均衡 (Nash equilibrium) 時的穩點,也就是我們要求的最優解。
τ-FPL 算法總覽
如上所述,τ-FPL 的訓練分爲兩個部分,排序 (scoring) 與閾值 (thresholding)。在排序階段,算法學習一個排序函數,其嘗試將正樣本排在負樣本中得分最高的那部分的「質心」之前。閾值階段則選取合適的閾值,將學到的排序函數轉化爲二分類器。
排序學習優化算法
考慮與 (2) 等價的對抗學習問題 (3),其對偶問題如下:
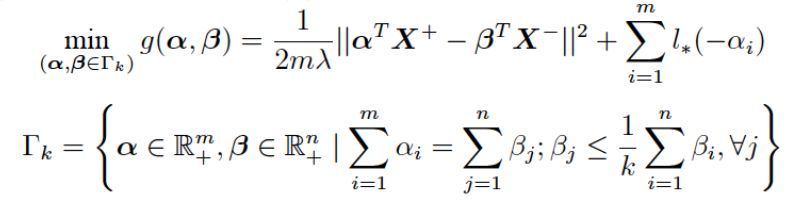
這個新問題不含任何不可導項,並且目標函數 g 是光滑的 (Smooth)。因此,我們可以使用投影梯度下降算法求解該問題,並利用加速梯度方法 (Nesterov) 獲得最優的收斂率。

線性時間的變上界歐式投影
排序學習算法的一個關鍵步驟,是將梯度下降的解投影到可行集 Gamma_k 上。我們注意到,這個投影問題是⼀⼤類被⼴泛研究的歐式投影問題的推⼴。然而傳統⽅法僅對一些特例可以⾼效求解,即便對於該問題的一個簡化版本,也僅能達到 O(nlogn +τn^2) 的超線性複雜度。
本文中,我們提出了一個算法,能夠在 O(n) 的線性時間內高效地求解該投影問題,且其性能不受τ增長所帶來的影響。該算法的核心是二分求根法與分治法的有效結合。根據 KKT 最優條件,我們將投影問題轉換爲一個求解分段線性方程組的問題,該方程組僅包含三個未知的對偶變量,且可以通過二分求根法獲得指定精度的解。進一步地,利用方程組分段線性的特殊結構,以及對偶變量間「同變」的單調性質,我們可以在二分過程中逐步減少每次迭代的計算消耗,最終顯著減少總的算法運行時間。實驗中,我們觀察到隨着 n 與τ的增長,我們的算法較現有的求解該類問題的方法有一至三個數量級的性能提升,見圖 2。
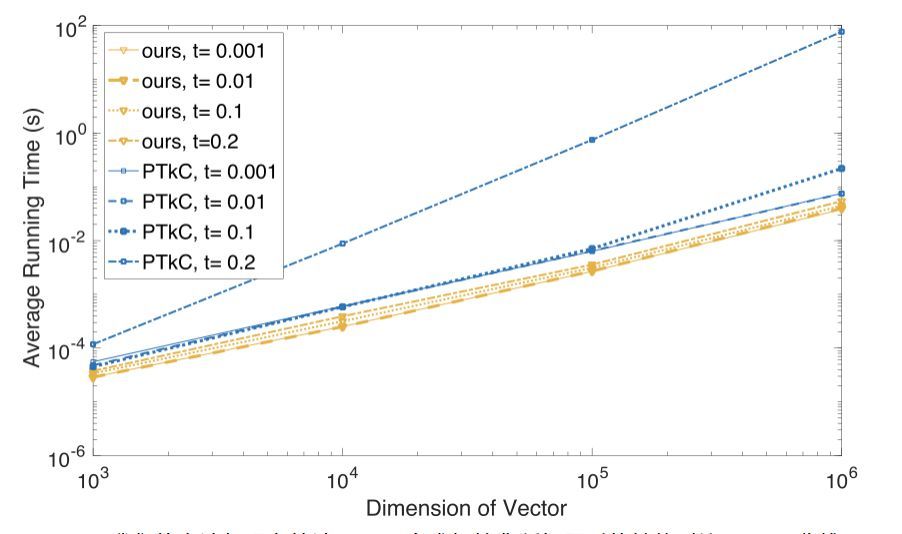
圖 2:我們的方法與現存算法 (PTkC) 在求解簡化版問題時的性能對比 (log-log 曲線)
閾值選擇
閾值選擇階段,算法每次將訓練集分爲兩份,⼀份訓練排序函數, 另⼀份用來選取閾值。該過程可以進⾏多次,以充分利⽤所有樣本,最終的閾值則是多輪閾值的平均。該方法結合了 out-of-bootstrap 與軟閾值技術分別控制偏差及方差的優點,也適於並行。
理論結果
收斂率與時間複雜度 通過結合加速梯度方法與線性時間投影算法,τ-FPL 可以確保每次迭代的線性時間消耗以及最優的收斂率。圖 3 將τ-FPL 與一些經典方法進行了對比,可以看到其同時具備最優的訓練及驗證複雜度。
泛化性能保證 我們也從理論上給出了τ-FPL 學得模型的泛化誤差界,證明了泛化誤差以很高的概率被經驗誤差所上界約束。這給予了我們設法求解排序問題(2)的理論支持。

圖 3:不同算法的訓練複雜度比較
實驗結果

圖 4 報告了不同算法優化部分 AUC 的效果,'N/A'代表該模型的訓練無法在一週內完成。可以看到,τ-FPL 對於不同τ值,在大部分實驗中都具有較好的表現。另外,其相比二分排序算法有明顯的性能優勢。
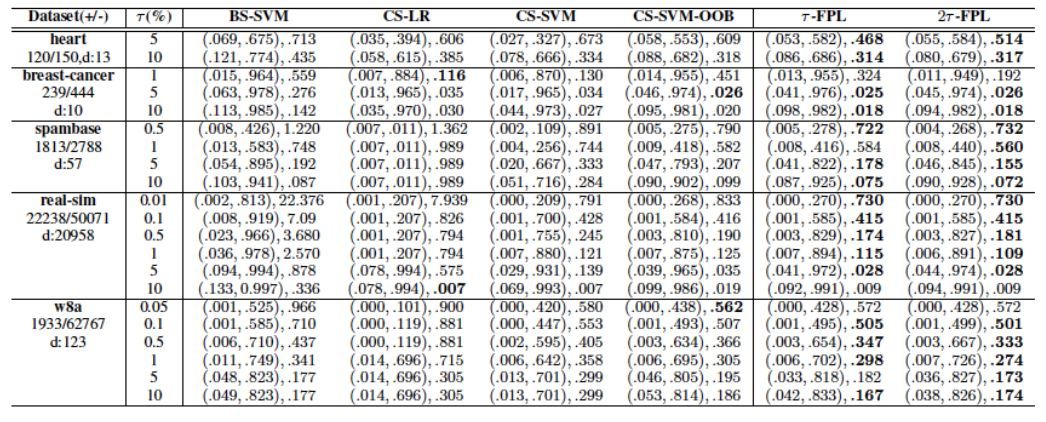
圖 5 比較了不同算法輸出的分類器的分類性能。這裏選取 NP-score 作爲評價標準,其綜合考慮了分類器間的精度差異與違背假陽性率約束的懲罰。可以看到,採用 OOB 閾值的算法在大部分情況下均可有效地抑制假陽性率在允許範圍內。另外,即使採用同樣的閾值選擇方法,τ-FPL 也可以獲得較代價敏感學習 (CS-SVM-OOB) 更好的精度。
總結
在高風險分類任務中控制假陽性率是重要的。本文中,我們主要研究在指定的假陽性率容忍度τ下學習二分類器。爲此,我們提出了一個新的排序學習問題,其顯式地最大化將正樣本排在 前 τ% 負樣本的質心之上的概率。通過結合加速梯度方法與線性時間投影,該排序問題可以在線性時間內被高效地解決。我們通過選取合適的閾值將學到的排序函數轉換爲低假陽性率的分類器,並從理論和實驗兩個角度驗證了所提出方法的有效性。